 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoDFT: A Closed-Loop Multi-Agent Framework for Autonomous DFT Calculations
May 25, 2026Density functional theory (DFT) serves as the basis for computational discovery in materials science and chemistry, yet each calculation demands extensive human effort: adjusting algorithms when convergence stalls, revising plans when unexpected physics emerges, and inserting steps as intermediate results reshape the problem. Existing LLM-based agents automate only the initial planning stage, producing a full execution plan upfront and leaving all subsequent adaptation to hand-crafted rules. As a result, these workflows remain fragile, do not generalize well beyond pre-planned scenarios, and often require expert intervention when failures or unexpected intermediate results require changes to the calculation path. Here, we introduce AutoDFT, a closed-loop multi-agent framework that embeds LLM reasoning into every stage of the DFT lifecycle, where a strategic planner produces a skeletal plan of step objectives; a step planner generates numerical parameters just in time from preceding results; and a monitor-recover-reflect cycle diagnoses failures, repairs them, and revises the plan when the evidence justifies it. We demonstrate both breadth and depth: breadth on VASPBench, a purpose-built benchmark spanning 34 tasks and 9 DFT calculation types, where AutoDFT achieves 94.1% task-level success with GPT-5.2; and depth on established materials databases, where AutoDFT produces quantitatively reliable property predictions across electronic, magnetic, and energetic properties. By closing the loop between planning and execution, AutoDFT enables experimentalists without deep computational expertise to obtain reliable first-principles results.
MATAI: A Generalist Machine Learning Framework for Property Prediction and Inverse Design of Advanced Alloys
Nov 13, 2025



The discovery of advanced metallic alloys is hindered by vast composition spaces, competing property objectives, and real-world constraints on manufacturability. Here we introduce MATAI, a generalist machine learning framework for property prediction and inverse design of as-cast alloys. MATAI integrates a curated alloy database, deep neural network-based property predictors, a constraint-aware optimization engine, and an iterative AI-experiment feedback loop. The framework estimates key mechanical propertie, sincluding density, yield strength, ultimate tensile strength, and elongation, directly from composition, using multi-task learning and physics-informed inductive biases. Alloy design is framed as a constrained optimization problem and solved using a bi-level approach that combines local search with symbolic constraint programming. We demonstrate MATAI's capabilities on the Ti-based alloy system, a canonical class of lightweight structural materials, where it rapidly identifies candidates that simultaneously achieve lower density (<4.45 g/cm3), higher strength (>1000 MPa) and appreciable ductility (>5%) through only seven iterations. Experimental validation confirms that MATAI-designed alloys outperform commercial references such as TC4, highlighting the framework's potential to accelerate the discovery of lightweight, high-performance materials under real-world design constraints.
VL-Grasp: a 6-Dof Interactive Grasp Policy for Language-Oriented Objects in Cluttered Indoor Scenes
Aug 01, 2023Robotic grasping faces new challenges in human-robot-interaction scenarios. We consider the task that the robot grasps a target object designated by human's language directives. The robot not only needs to locate a target based on vision-and-language information, but also needs to predict the reasonable grasp pose candidate at various views and postures. In this work, we propose a novel interactive grasp policy, named Visual-Lingual-Grasp (VL-Grasp), to grasp the target specified by human language. First, we build a new challenging visual grounding dataset to provide functional training data for robotic interactive perception in indoor environments. Second, we propose a 6-Dof interactive grasp policy combined with visual grounding and 6-Dof grasp pose detection to extend the universality of interactive grasping. Third, we design a grasp pose filter module to enhance the performance of the policy. Experiments demonstrate the effectiveness and extendibility of the VL-Grasp in real world. The VL-Grasp achieves a success rate of 72.5\% in different indoor scenes. The code and dataset is available at https://github.com/luyh20/VL-Grasp.
Hybrid Physical Metric For 6-DoF Grasp Pose Detection
Jun 22, 2022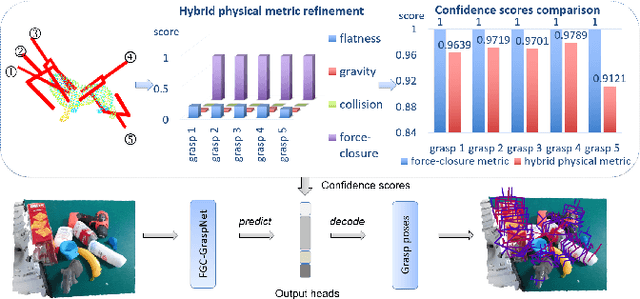
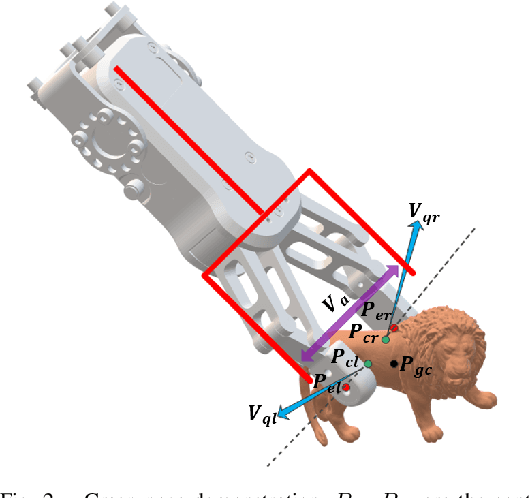
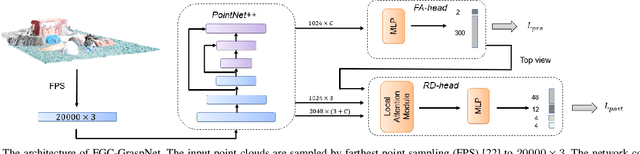
6-DoF grasp pose detection of multi-grasp and multi-object is a challenge task in the field of intelligent robot. To imitate human reasoning ability for grasping objects, data driven methods are widely studied. With the introduction of large-scale datasets, we discover that a single physical metric usually generates several discrete levels of grasp confidence scores, which cannot finely distinguish millions of grasp poses and leads to inaccurate prediction results. In this paper, we propose a hybrid physical metric to solve this evaluation insufficiency. First, we define a novel metric is based on the force-closure metric, supplemented by the measurement of the object flatness, gravity and collision. Second, we leverage this hybrid physical metric to generate elaborate confidence scores. Third, to learn the new confidence scores effectively, we design a multi-resolution network called Flatness Gravity Collision GraspNet (FGC-GraspNet). FGC-GraspNet proposes a multi-resolution features learning architecture for multiple tasks and introduces a new joint loss function that enhances the average precision of the grasp detection. The network evaluation and adequate real robot experiments demonstrate the effectiveness of our hybrid physical metric and FGC-GraspNet. Our method achieves 90.5\% success rate in real-world cluttered scenes. Our code is available at https://github.com/luyh20/FGC-GraspNet.
Machine learning driven synthesis of few-layered WTe2
Oct 10, 2019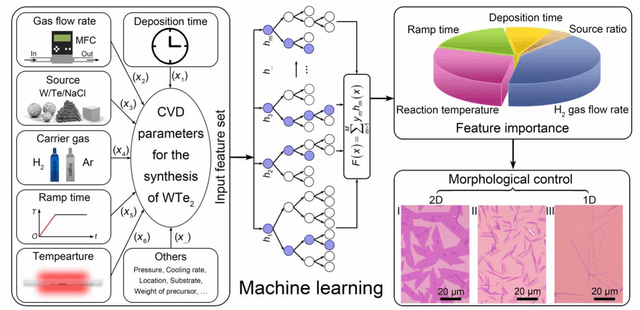
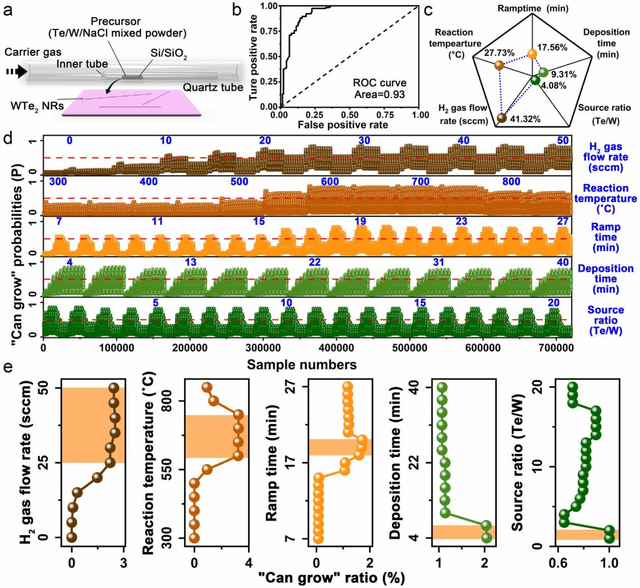
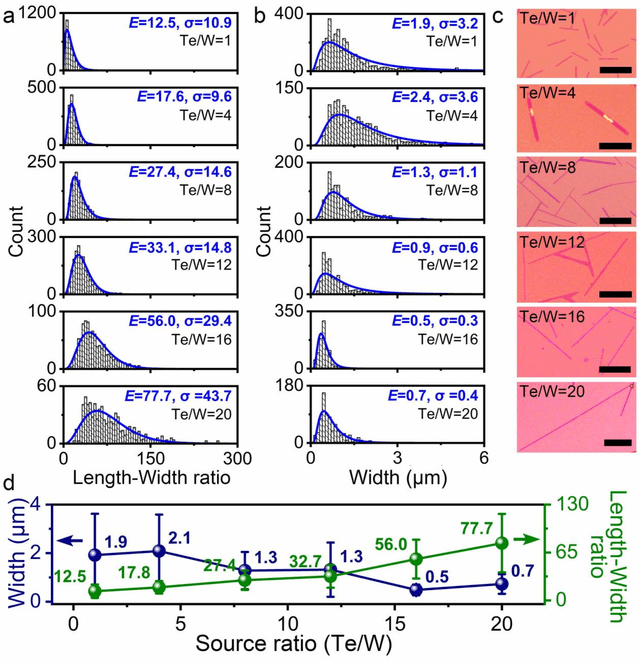
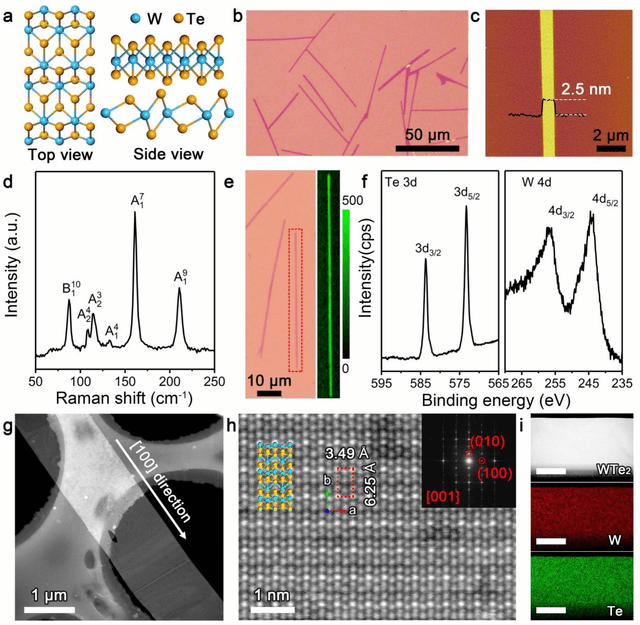
Reducing the lateral scale of two-dimensional (2D) materials to one-dimensional (1D) has attracted substantial research interest not only to achieve competitive electronic device applications but also for the exploration of fundamental physical properties. Controllable synthesis of high-quality 1D nanoribbons (NRs) is thus highly desirable and essential for the further study. Traditional exploration of the optimal synthesis conditions of novel materials is based on the trial-and-error approach, which is time consuming, costly and laborious. Recently, machine learning (ML) has demonstrated promising capability in guiding material synthesis through effectively learning from the past data and then making recommendations. Here, we report the implementation of supervised ML for the chemical vapor deposition (CVD) synthesis of high-quality 1D few-layered WTe2 nanoribbons (NRs). The synthesis parameters of the WTe2 NRs are optimized by the trained ML model. On top of that, the growth mechanism of as-synthesized 1T' few-layered WTe2 NRs is further proposed, which may inspire the growth strategies for other 1D nanostructures. Our findings suggest that ML is a powerful and efficient approach to aid the synthesis of 1D nanostructures, opening up new opportunities for intelligent material development.
Machine learning-guided synthesis of advanced inorganic materials
May 10, 2019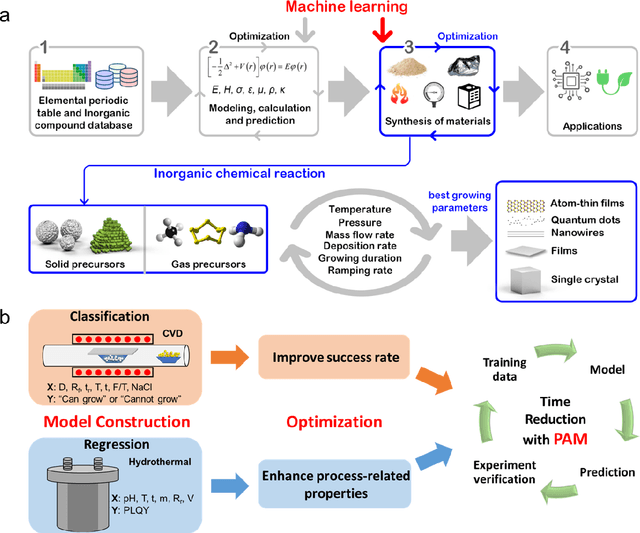
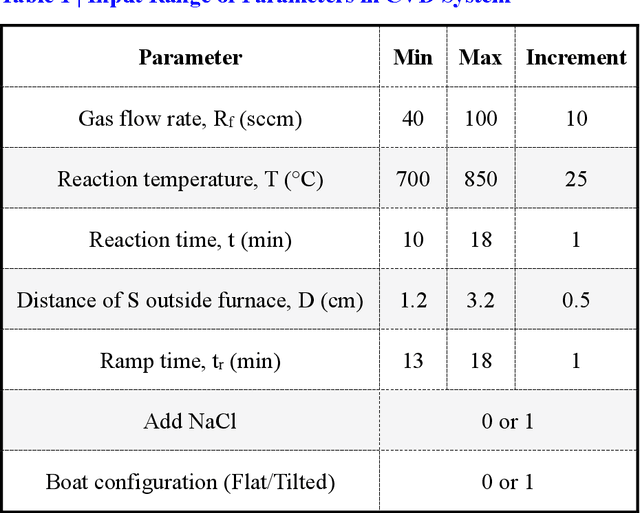
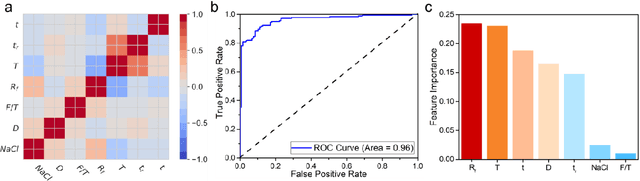
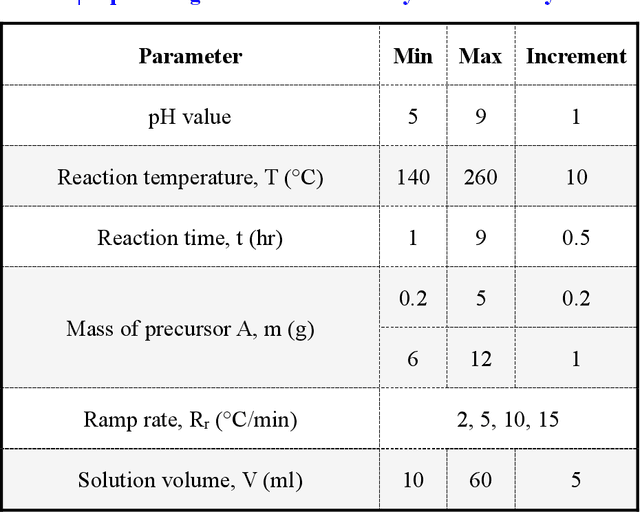
Synthesis of advanced inorganic materials with minimum number of trials is of paramount importance towards the acceleration of inorganic materials development. The enormous complexity involved in existing multi-variable synthesis methods leads to high uncertainty, numerous trials and exorbitant cost. Recently, machine learning (ML) has demonstrated tremendous potential for material research. Here, we report the application of ML to optimize and accelerate material synthesis process in two representative multi-variable systems. A classification ML model on chemical vapor deposition-grown MoS2 is established, capable of optimizing the synthesis conditions to achieve higher success rate. While a regression model is constructed on the hydrothermal-synthesized carbon quantum dots, to enhance the process-related properties such as the photoluminescence quantum yield. Progressive adaptive model is further developed, aiming to involve ML at the beginning stage of new material synthesis. Optimization of the experimental outcome with minimized number of trials can be achieved with the effective feedback loops. This work serves as proof of concept revealing the feasibility and remarkable capability of ML to facilitate the synthesis of inorganic materials, and opens up a new window for accelerating material development.
FPUAS : Fully Parallel UFANS-based End-to-End Acoustic System with 10x Speed Up
Dec 18, 2018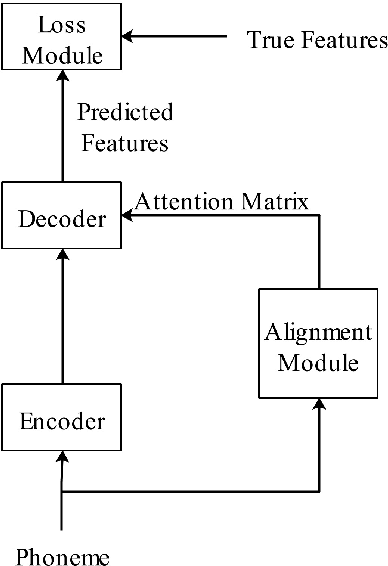
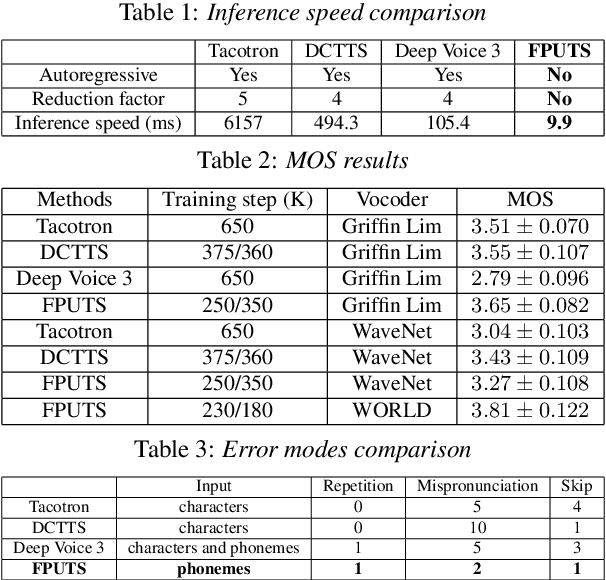
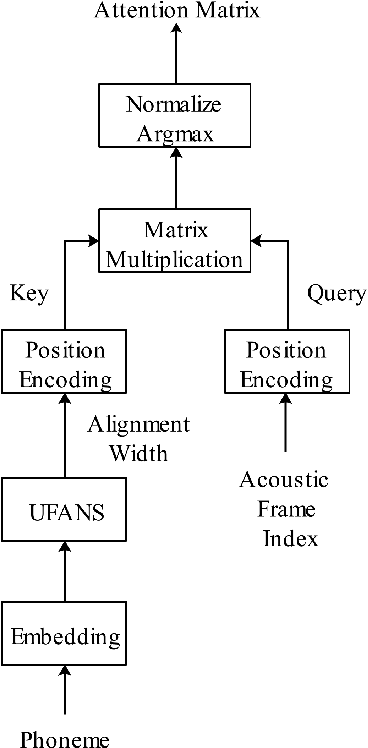
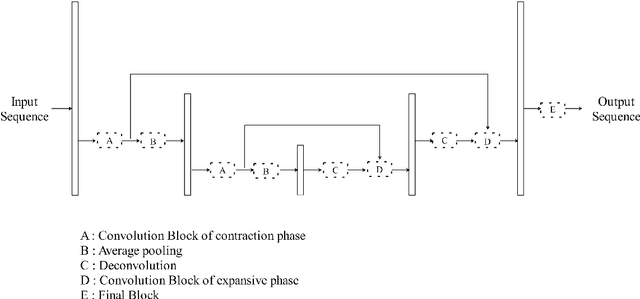
A lightweight end-to-end acoustic system is crucial in the deployment of text-to-speech tasks. Finding one that produces good audios with small time latency and fewer errors remains a problem. In this paper, we propose a new non-autoregressive, fully parallel acoustic system that utilizes a new attention structure and a recently proposed convolutional structure. Compared with the most popular end-to-end text-to-speech systems, our acoustic system can produce equal or better quality audios with fewer errors and reach at least 10 times speed up of inference.