 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Two-student Learning Framework for Mixed Supervised Target Sound Detection
Apr 05, 2022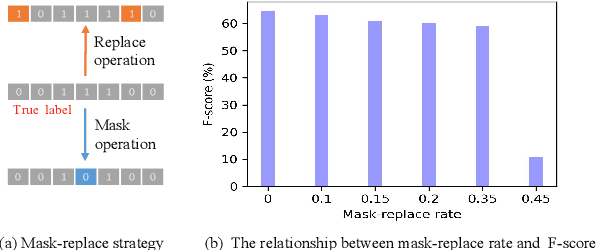
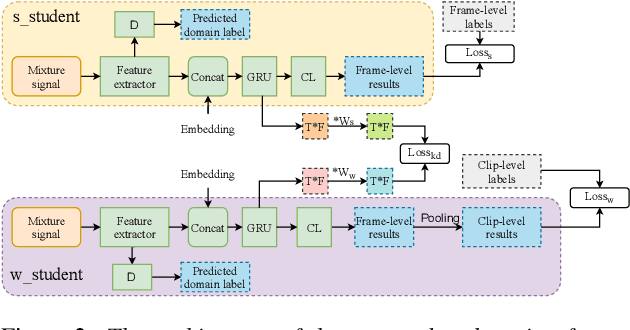
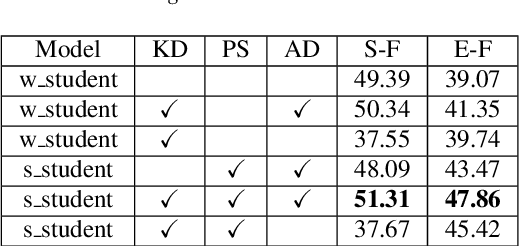
Target sound detection (TSD) aims to detect the target sound from mixture audio given the reference information. Previous work shows that a good detection performance relies on fully-annotated data. However, collecting fully-annotated data is labor-extensive. Therefore, we consider TSD with mixed supervision, which learns novel categories (target domain) using weak annotations with the help of full annotations of existing base categories (source domain). We propose a novel two-student learning framework, which contains two mutual helping student models ($\mathit{s\_student}$ and $\mathit{w\_student}$) that learn from fully- and weakly-annotated datasets, respectively. Specifically, we first propose a frame-level knowledge distillation strategy to transfer the class-agnostic knowledge from $\mathit{s\_student}$ to $\mathit{w\_student}$. After that, a pseudo supervised (PS) training is designed to transfer the knowledge from $\mathit{w\_student}$ to $\mathit{s\_student}$. Lastly, an adversarial training strategy is proposed, which aims to align the data distribution between source and target domains. To evaluate our method, we build three TSD datasets based on UrbanSound and Audioset. Experimental results show that our methods offer about 8\% improvement in event-based F score.
Target Confusion in End-to-end Speaker Extraction: Analysis and Approaches
Apr 04, 2022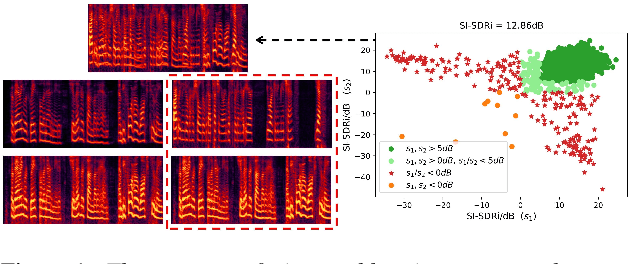
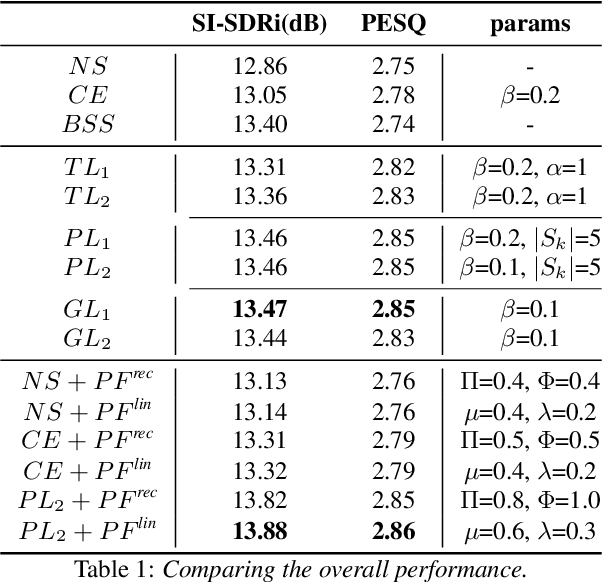

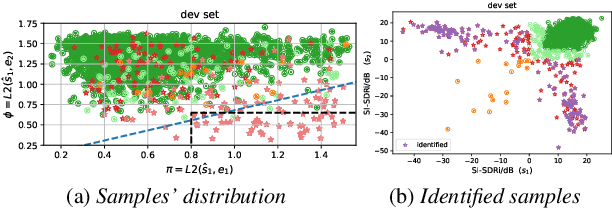
Recently, end-to-end speaker extraction has attracted increasing attention and shown promising results. However, its performance is often inferior to that of a blind source separation (BSS) counterpart with a similar network architecture, due to the auxiliary speaker encoder may sometimes generate ambiguous speaker embeddings. Such ambiguous guidance information may confuse the separation network and hence lead to wrong extraction results, which deteriorates the overall performance. We refer to this as the target confusion problem. In this paper, we conduct an analysis of such an issue and solve it in two stages. In the training phase, we propose to integrate metric learning methods to improve the distinguishability of embeddings produced by the speaker encoder. While for inference, a novel post-filtering strategy is designed to revise the wrong results. Specifically, we first identify these confusion samples by measuring the similarities between output estimates and enrollment utterances, after which the true target sources are recovered by a subtraction operation. Experiments show that performance improvement of more than 1dB SI-SDRi can be brought, which validates the effectiveness of our methods and emphasizes the impact of the target confusion problem.
Improving Target Sound Extraction with Timestamp Information
Apr 02, 2022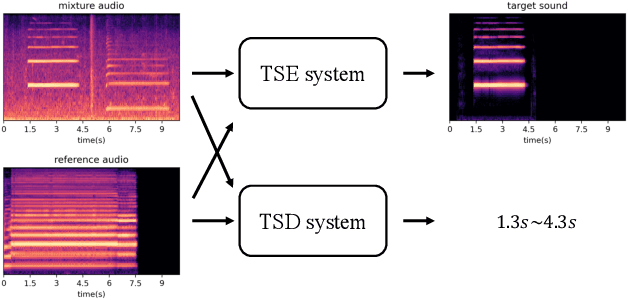
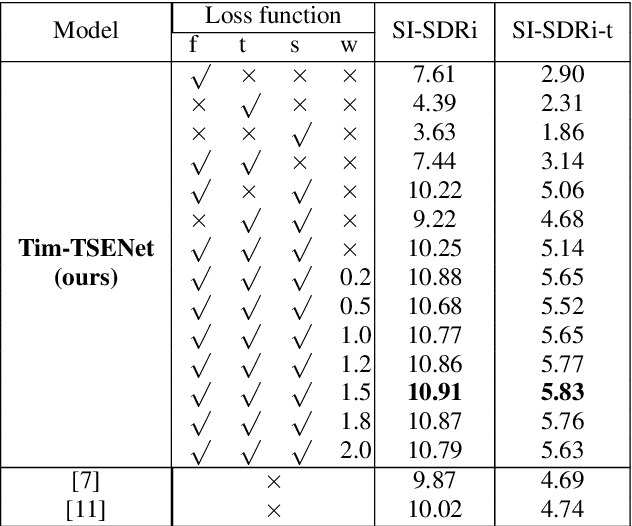
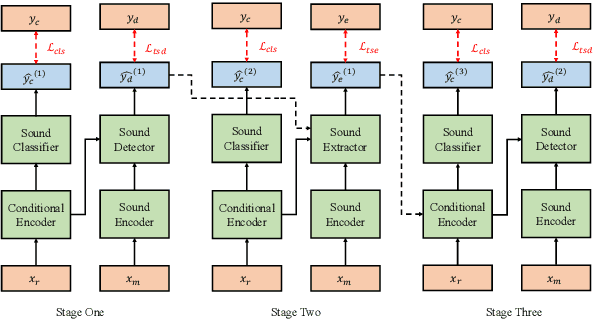
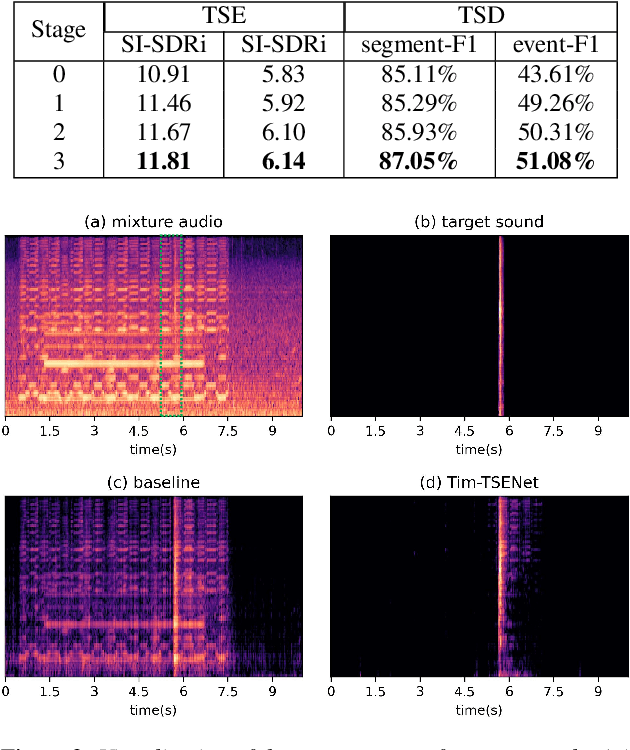
Target sound extraction (TSE) aims to extract the sound part of a target sound event class from a mixture audio with multiple sound events. The previous works mainly focus on the problems of weakly-labelled data, jointly learning and new classes, however, no one cares about the onset and offset times of the target sound event, which has been emphasized in the auditory scene analysis. In this paper, we study to utilize such timestamp information to help extract the target sound via a target sound detection network and a target-weighted time-frequency loss function. More specifically, we use the detection result of a target sound detection (TSD) network as the additional information to guide the learning of target sound extraction network. We also find that the result of TSE can further improve the performance of the TSD network, so that a mutual learning framework of the target sound detection and extraction is proposed. In addition, a target-weighted time-frequency loss function is designed to pay more attention to the temporal regions of the target sound during training. Experimental results on the synthesized data generated from the Freesound Datasets show that our proposed method can significantly improve the performance of TSE.
Integrate Lattice-Free MMI into End-to-End Speech Recognition
Apr 02, 2022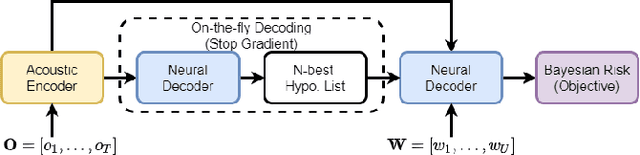
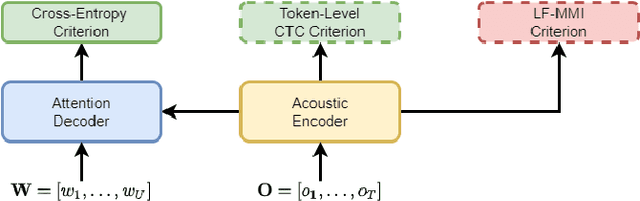
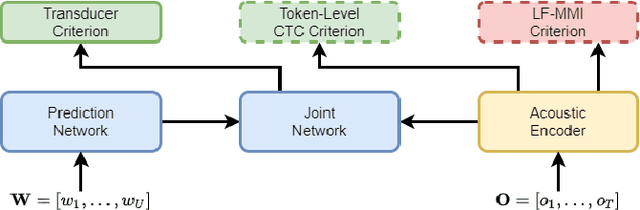
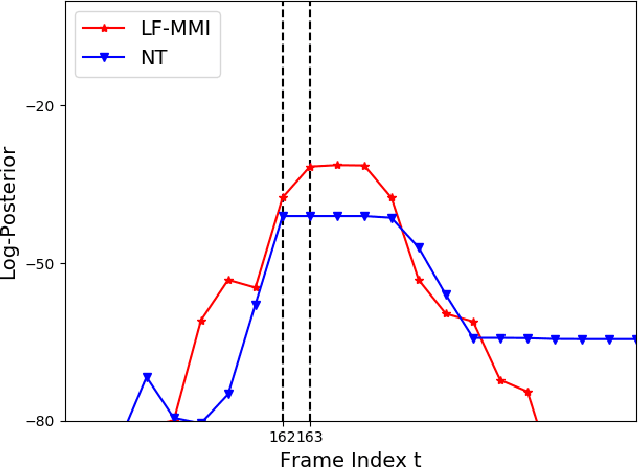
In automatic speech recognition (ASR) research, discriminative criteria have achieved superior performance in DNN-HMM systems. Given this success, the adoption of discriminative criteria is promising to boost the performance of end-to-end (E2E) ASR systems. With this motivation, previous works have introduced the minimum Bayesian risk (MBR, one of the discriminative criteria) into E2E ASR systems. However, the effectiveness and efficiency of the MBR-based methods are compromised: the MBR criterion is only used in system training, which creates a mismatch between training and decoding; the on-the-fly decoding process in MBR-based methods results in the need for pre-trained models and slow training speeds. To this end, novel algorithms are proposed in this work to integrate another widely used discriminative criterion, lattice-free maximum mutual information (LF-MMI), into E2E ASR systems not only in the training stage but also in the decoding process. The proposed LF-MMI training and decoding methods show their effectiveness on two widely used E2E frameworks: Attention-Based Encoder-Decoders (AEDs) and Neural Transducers (NTs). Compared with MBR-based methods, the proposed LF-MMI method: maintains the consistency between training and decoding; eschews the on-the-fly decoding process; trains from randomly initialized models with superior training efficiency. Experiments suggest that the LF-MMI method outperforms its MBR counterparts and consistently leads to statistically significant performance improvements on various frameworks and datasets from 30 hours to 14.3k hours. The proposed method achieves state-of-the-art (SOTA) results on Aishell-1 (CER 4.10%) and Aishell-2 (CER 5.02%) datasets. Code is released.
Learning Decoupling Features Through Orthogonality Regularization
Mar 31, 2022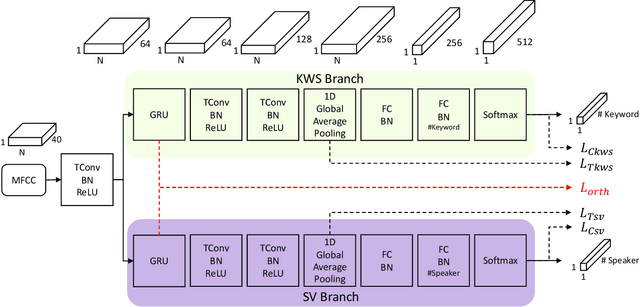
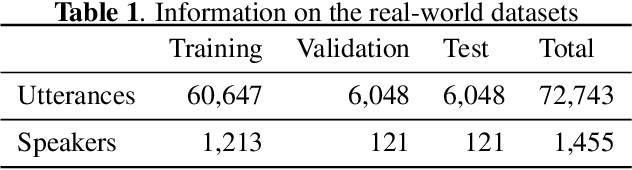
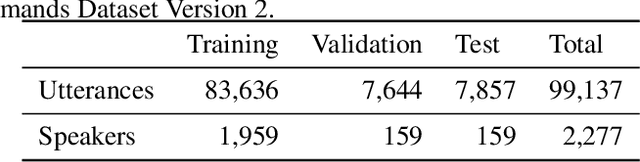
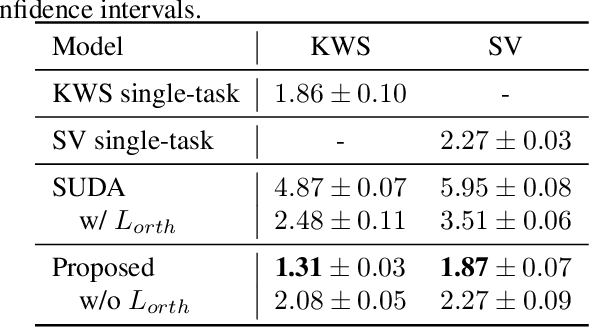
Keyword spotting (KWS) and speaker verification (SV) are two important tasks in speech applications. Research shows that the state-of-art KWS and SV models are trained independently using different datasets since they expect to learn distinctive acoustic features. However, humans can distinguish language content and the speaker identity simultaneously. Motivated by this, we believe it is important to explore a method that can effectively extract common features while decoupling task-specific features. Bearing this in mind, a two-branch deep network (KWS branch and SV branch) with the same network structure is developed and a novel decoupling feature learning method is proposed to push up the performance of KWS and SV simultaneously where speaker-invariant keyword representations and keyword-invariant speaker representations are expected respectively. Experiments are conducted on Google Speech Commands Dataset (GSCD). The results demonstrate that the orthogonality regularization helps the network to achieve SOTA EER of 1.31% and 1.87% on KWS and SV, respectively.
SpatioTemporal Focus for Skeleton-based Action Recognition
Mar 31, 2022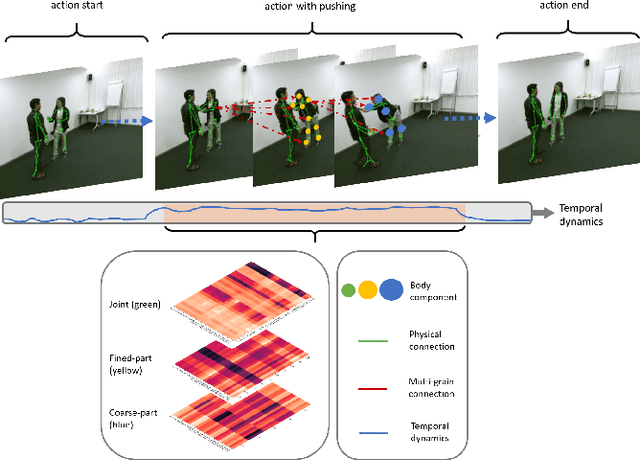
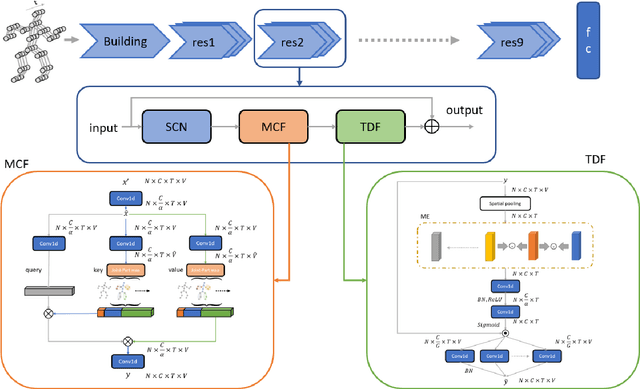
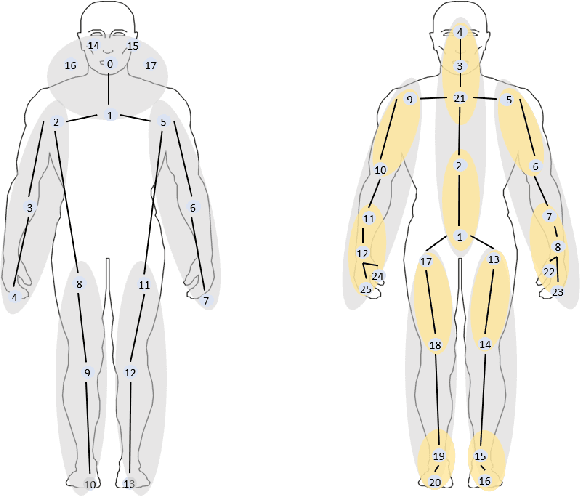
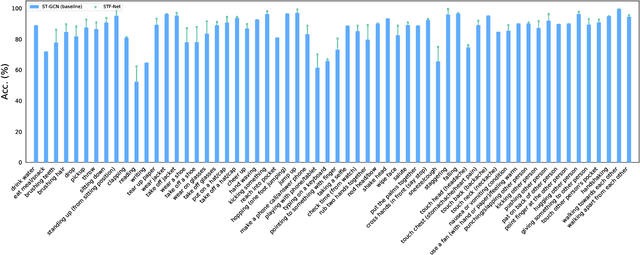
Graph convolutional networks (GCNs) are widely adopted in skeleton-based action recognition due to their powerful ability to model data topology. We argue that the performance of recent proposed skeleton-based action recognition methods is limited by the following factors. First, the predefined graph structures are shared throughout the network, lacking the flexibility and capacity to model the multi-grain semantic information. Second, the relations among the global joints are not fully exploited by the graph local convolution, which may lose the implicit joint relevance. For instance, actions such as running and waving are performed by the co-movement of body parts and joints, e.g., legs and arms, however, they are located far away in physical connection. Inspired by the recent attention mechanism, we propose a multi-grain contextual focus module, termed MCF, to capture the action associated relation information from the body joints and parts. As a result, more explainable representations for different skeleton action sequences can be obtained by MCF. In this study, we follow the common practice that the dense sample strategy of the input skeleton sequences is adopted and this brings much redundancy since number of instances has nothing to do with actions. To reduce the redundancy, a temporal discrimination focus module, termed TDF, is developed to capture the local sensitive points of the temporal dynamics. MCF and TDF are integrated into the standard GCN network to form a unified architecture, named STF-Net. It is noted that STF-Net provides the capability to capture robust movement patterns from these skeleton topology structures, based on multi-grain context aggregation and temporal dependency. Extensive experimental results show that our STF-Net significantly achieves state-of-the-art results on three challenging benchmarks NTU RGB+D 60, NTU RGB+D 120, and Kinetics-skeleton.
Unsupervised Pre-training for Temporal Action Localization Tasks
Mar 25, 2022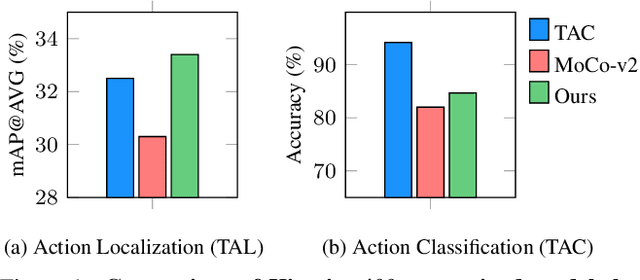
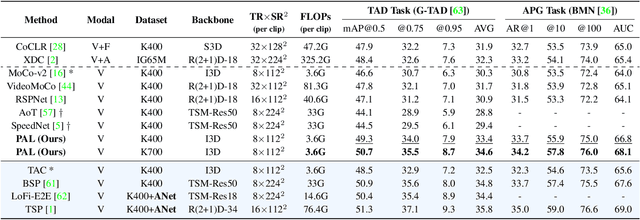
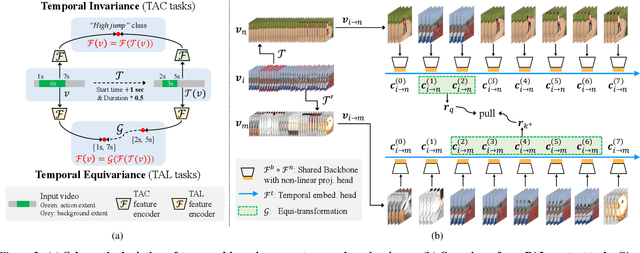
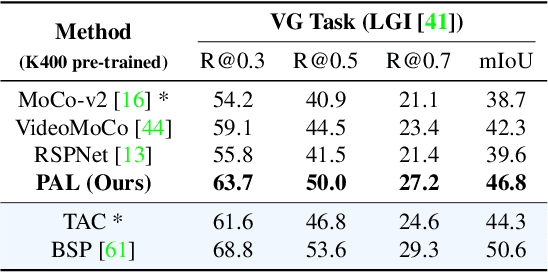
Unsupervised video representation learning has made remarkable achievements in recent years. However, most existing methods are designed and optimized for video classification. These pre-trained models can be sub-optimal for temporal localization tasks due to the inherent discrepancy between video-level classification and clip-level localization. To bridge this gap, we make the first attempt to propose a self-supervised pretext task, coined as Pseudo Action Localization (PAL) to Unsupervisedly Pre-train feature encoders for Temporal Action Localization tasks (UP-TAL). Specifically, we first randomly select temporal regions, each of which contains multiple clips, from one video as pseudo actions and then paste them onto different temporal positions of the other two videos. The pretext task is to align the features of pasted pseudo action regions from two synthetic videos and maximize the agreement between them. Compared to the existing unsupervised video representation learning approaches, our PAL adapts better to downstream TAL tasks by introducing a temporal equivariant contrastive learning paradigm in a temporally dense and scale-aware manner. Extensive experiments show that PAL can utilize large-scale unlabeled video data to significantly boost the performance of existing TAL methods. Our codes and models will be made publicly available at https://github.com/zhang-can/UP-TAL.
Improving Mandarin End-to-End Speech Recognition with Word N-gram Language Model
Jan 06, 2022
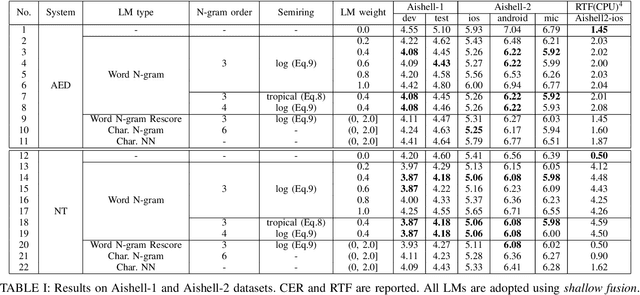
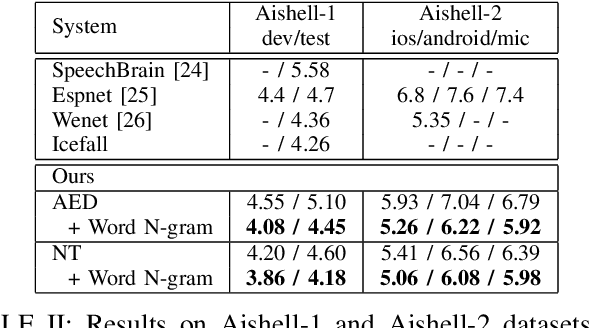
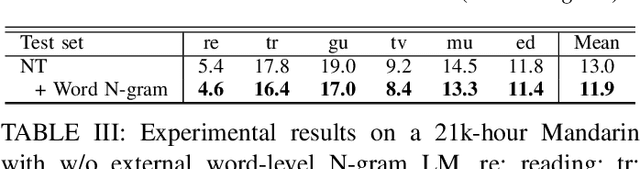
Despite the rapid progress of end-to-end (E2E) automatic speech recognition (ASR), it has been shown that incorporating external language models (LMs) into the decoding can further improve the recognition performance of E2E ASR systems. To align with the modeling units adopted in E2E ASR systems, subword-level (e.g., characters, BPE) LMs are usually used to cooperate with current E2E ASR systems. However, the use of subword-level LMs will ignore the word-level information, which may limit the strength of the external LMs in E2E ASR. Although several methods have been proposed to incorporate word-level external LMs in E2E ASR, these methods are mainly designed for languages with clear word boundaries such as English and cannot be directly applied to languages like Mandarin, in which each character sequence can have multiple corresponding word sequences. To this end, we propose a novel decoding algorithm where a word-level lattice is constructed on-the-fly to consider all possible word sequences for each partial hypothesis. Then, the LM score of the hypothesis is obtained by intersecting the generated lattice with an external word N-gram LM. The proposed method is examined on both Attention-based Encoder-Decoder (AED) and Neural Transducer (NT) frameworks. Experiments suggest that our method consistently outperforms subword-level LMs, including N-gram LM and neural network LM. We achieve state-of-the-art results on both Aishell-1 (CER 4.18%) and Aishell-2 (CER 5.06%) datasets and reduce CER by 14.8% relatively on a 21K-hour Mandarin dataset.
Consistent Training and Decoding For End-to-end Speech Recognition Using Lattice-free MMI
Dec 30, 2021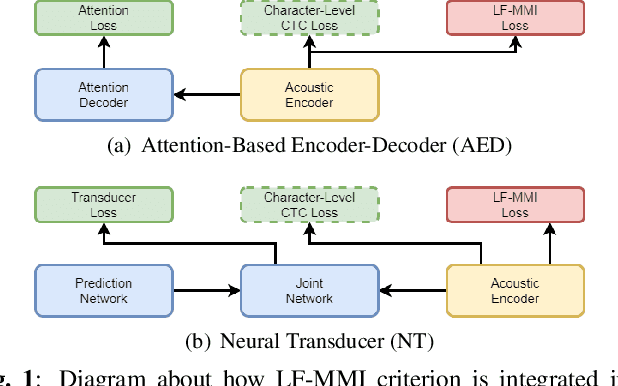
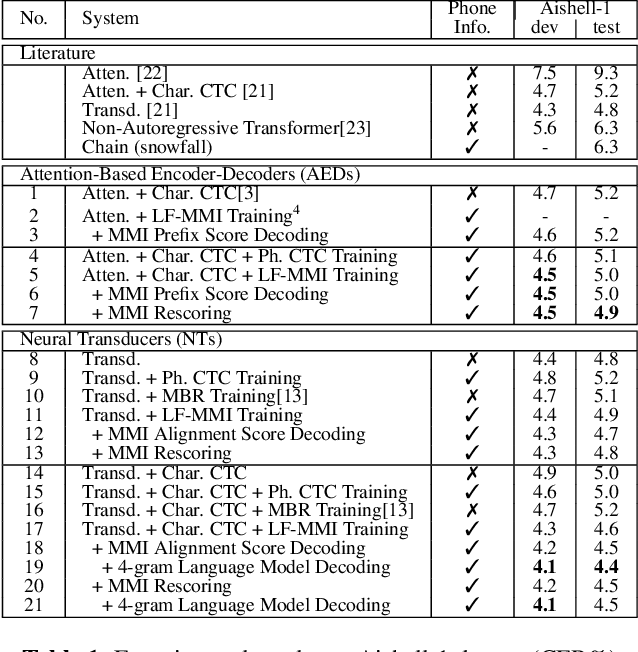
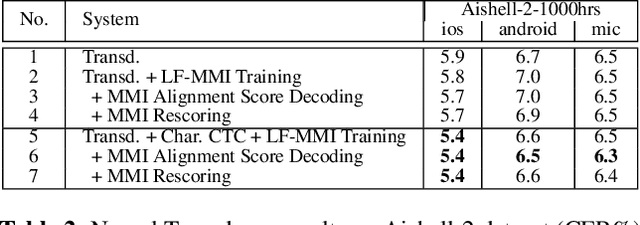
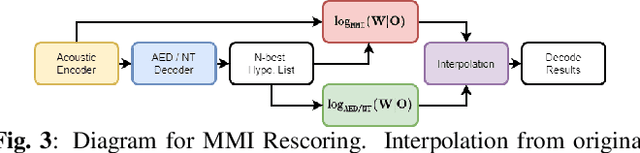
Recently, End-to-End (E2E) frameworks have achieved remarkable results on various Automatic Speech Recognition (ASR) tasks. However, Lattice-Free Maximum Mutual Information (LF-MMI), as one of the discriminative training criteria that show superior performance in hybrid ASR systems, is rarely adopted in E2E ASR frameworks. In this work, we propose a novel approach to integrate LF-MMI criterion into E2E ASR frameworks in both training and decoding stages. The proposed approach shows its effectiveness on two of the most widely used E2E frameworks including Attention-Based Encoder-Decoders (AEDs) and Neural Transducers (NTs). Experiments suggest that the introduction of the LF-MMI criterion consistently leads to significant performance improvements on various datasets and different E2E ASR frameworks. The best of our models achieves competitive CER of 4.1\% / 4.4\% on Aishell-1 dev/test set; we also achieve significant error reduction on Aishell-2 and Librispeech datasets over strong baselines.
Detect what you want: Target Sound Detection
Dec 19, 2021
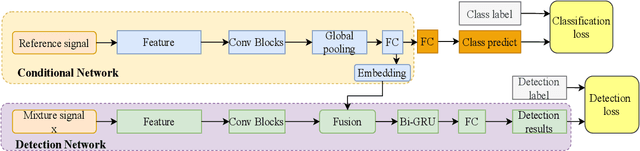
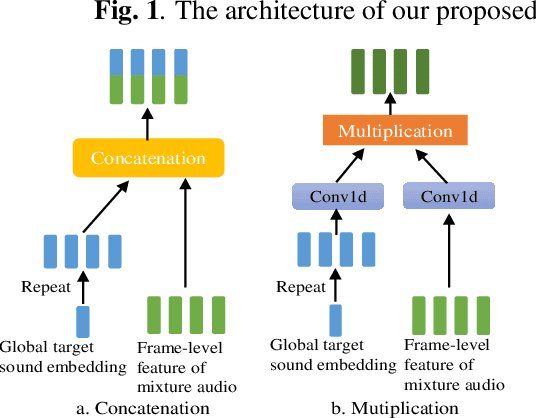
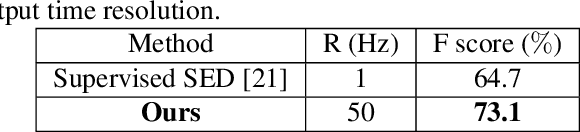
Human beings can perceive a target sound that we are interested in from a multi-source environment by the selective auditory attention, however, such functionality was hardly ever explored in machine hearing.This paper address the target sound detection (TSD), which aims to detect the target sound signal from a mixture audio when a target sound's reference audio is given.We present a novel target sound detection network (TSDNet) which consists of two main parts: A conditional and a detection network. The former aims at generating a sound-discriminative conditional embedding vector representing the global information of the target sound. The latter takes both the mixture audio and the conditional embedding vector as inputs, and produces the detection result. These two networks can be jointly optimized with a multi-task learning approach to further improve the performance. In addition, we study both supervised and weakly supervised strategies to train TSDNet.To evaluate our methods, we build a target sound detection dataset (TSD Dataset) based on URBAN-SED and URBAN-SOUND8K datasets. Experimental results indicate our system can get better performance than universal sound event detection.