 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Multi-Interest Learning for Candidate Matching in Recommender Systems
Feb 28, 2023Existing research efforts for multi-interest candidate matching in recommender systems mainly focus on improving model architecture or incorporating additional information, neglecting the importance of training schemes. This work revisits the training framework and uncovers two major problems hindering the expressiveness of learned multi-interest representations. First, the current training objective (i.e., uniformly sampled softmax) fails to effectively train discriminative representations in a multi-interest learning scenario due to the severe increase in easy negative samples. Second, a routing collapse problem is observed where each learned interest may collapse to express information only from a single item, resulting in information loss. To address these issues, we propose the REMI framework, consisting of an Interest-aware Hard Negative mining strategy (IHN) and a Routing Regularization (RR) method. IHN emphasizes interest-aware hard negatives by proposing an ideal sampling distribution and developing a Monte-Carlo strategy for efficient approximation. RR prevents routing collapse by introducing a novel regularization term on the item-to-interest routing matrices. These two components enhance the learned multi-interest representations from both the optimization objective and the composition information. REMI is a general framework that can be readily applied to various existing multi-interest candidate matching methods. Experiments on three real-world datasets show our method can significantly improve state-of-the-art methods with easy implementation and negligible computational overhead. The source code will be released.
Robust Federated Learning against both Data Heterogeneity and Poisoning Attack via Aggregation Optimization
Nov 20, 2022Non-IID data distribution across clients and poisoning attacks are two main challenges in real-world federated learning (FL) systems. While both of them have attracted great research interest with specific strategies developed, no known solution manages to address them in a unified framework. To universally overcome both challenges, we propose SmartFL, a generic approach that optimizes the server-side aggregation process with a small amount of proxy data collected by the service provider itself via a subspace training technique. Specifically, the aggregation weight of each participating client at each round is optimized using the server-collected proxy data, which is essentially the optimization of the global model in the convex hull spanned by client models. Since at each round, the number of tunable parameters optimized on the server side equals the number of participating clients (thus independent of the model size), we are able to train a global model with massive parameters using only a small amount of proxy data (e.g., around one hundred samples). With optimized aggregation, SmartFL ensures robustness against both heterogeneous and malicious clients, which is desirable in real-world FL where either or both problems may occur. We provide theoretical analyses of the convergence and generalization capacity for SmartFL. Empirically, SmartFL achieves state-of-the-art performance on both FL with non-IID data distribution and FL with malicious clients. The source code will be released.
DYNAFED: Tackling Client Data Heterogeneity with Global Dynamics
Nov 20, 2022The Federated Learning (FL) paradigm is known to face challenges under heterogeneous client data. Local training on non-iid distributed data results in deflected local optimum, which causes the client models drift further away from each other and degrades the aggregated global model's performance. A natural solution is to gather all client data onto the server, such that the server has a global view of the entire data distribution. Unfortunately, this reduces to regular training, which compromises clients' privacy and conflicts with the purpose of FL. In this paper, we put forth an idea to collect and leverage global knowledge on the server without hindering data privacy. We unearth such knowledge from the dynamics of the global model's trajectory. Specifically, we first reserve a short trajectory of global model snapshots on the server. Then, we synthesize a small pseudo dataset such that the model trained on it mimics the dynamics of the reserved global model trajectory. Afterward, the synthesized data is used to help aggregate the deflected clients into the global model. We name our method Dynafed, which enjoys the following advantages: 1) we do not rely on any external on-server dataset, which requires no additional cost for data collection; 2) the pseudo data can be synthesized in early communication rounds, which enables Dynafed to take effect early for boosting the convergence and stabilizing training; 3) the pseudo data only needs to be synthesized once and can be directly utilized on the server to help aggregation in subsequent rounds. Experiments across extensive benchmarks are conducted to showcase the effectiveness of Dynafed. We also provide insights and understanding of the underlying mechanism of our method.
Equivariant Contrastive Learning for Sequential Recommendation
Nov 18, 2022Contrastive learning (CL) benefits the training of sequential recommendation models with informative self-supervision signals. Existing solutions apply general sequential data augmentation strategies to generate positive pairs and encourage their representations to be invariant. However, due to the inherent properties of user behavior sequences, some augmentation strategies, such as item substitution, can lead to changes in user intent. Learning indiscriminately invariant representations for all augmentation strategies might be sub-optimal. Therefore, we propose Equivariant Contrastive Learning for Sequential Recommendation (ECL-SR), which endows SR models with great discriminative power, making the learned user behavior representations sensitive to invasive augmentations (e.g., item substitution) and insensitive to mild augmentations (e.g., feature-level dropout masking). In detail, we use the conditional discriminator to capture differences in behavior due to item substitution, which encourages the user behavior encoder to be equivariant to invasive augmentations. Comprehensive experiments on four benchmark datasets show that the proposed ECL-SR framework achieves competitive performance compared to state-of-the-art SR models. The source code will be released.
Optimizing Image Compression via Joint Learning with Denoising
Jul 22, 2022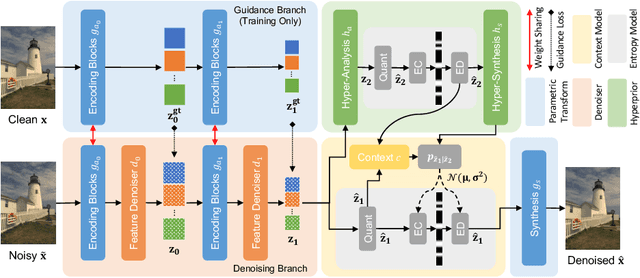
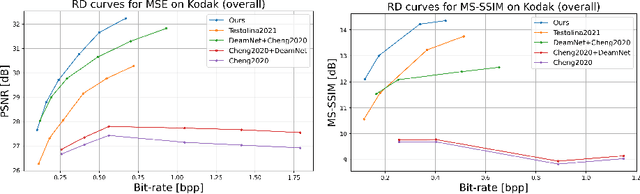
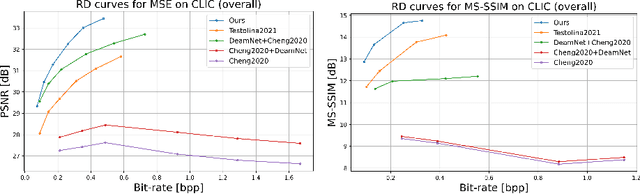
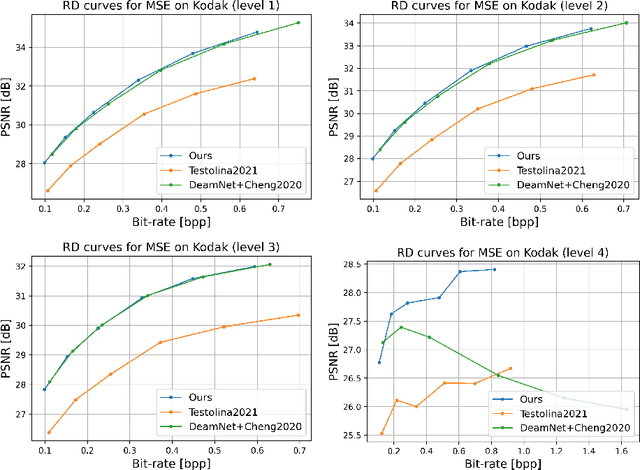
High levels of noise usually exist in today's captured images due to the relatively small sensors equipped in the smartphone cameras, where the noise brings extra challenges to lossy image compression algorithms. Without the capacity to tell the difference between image details and noise, general image compression methods allocate additional bits to explicitly store the undesired image noise during compression and restore the unpleasant noisy image during decompression. Based on the observations, we optimize the image compression algorithm to be noise-aware as joint denoising and compression to resolve the bits misallocation problem. The key is to transform the original noisy images to noise-free bits by eliminating the undesired noise during compression, where the bits are later decompressed as clean images. Specifically, we propose a novel two-branch, weight-sharing architecture with plug-in feature denoisers to allow a simple and effective realization of the goal with little computational cost. Experimental results show that our method gains a significant improvement over the existing baseline methods on both the synthetic and real-world datasets. Our source code is available at https://github.com/felixcheng97/DenoiseCompression.
Efficiently Leveraging Multi-level User Intent for Session-based Recommendation via Atten-Mixer Network
Jun 26, 2022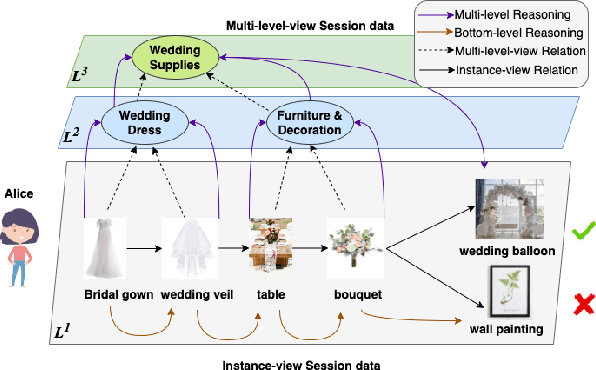
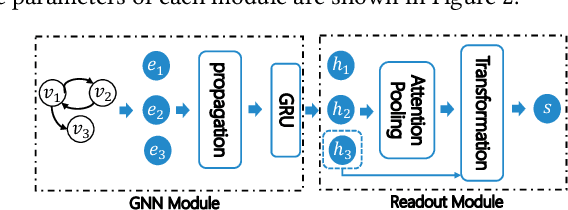
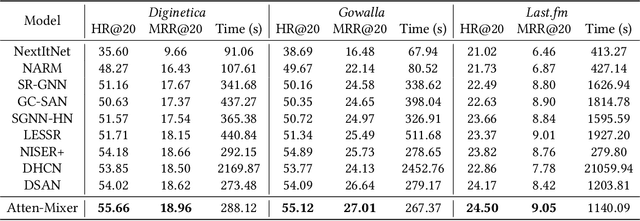
Session-based recommendation (SBR) aims to predict the user next action based on short and dynamic sessions. Recently, there has been an increasing interest in utilizing various elaborately designed graph neural networks (GNNs) to capture the pair-wise relationships among items, seemingly suggesting the design of more complicated models is the panacea for improving the empirical performance. However, these models achieve relatively marginal improvements with exponential growth in model complexity. In this paper, we dissect the classical GNN-based SBR models and empirically find that some sophisticated GNN propagations are redundant, given the readout module plays a significant role in GNN-based models. Based on this observation, we intuitively propose to remove the GNN propagation part, while the readout module will take on more responsibility in the model reasoning process. To this end, we propose the Multi-Level Attention Mixture Network (Atten-Mixer), which leverages both concept-view and instance-view readouts to achieve multi-level reasoning over item transitions. As simply enumerating all possible high-level concepts is infeasible for large real-world recommender systems, we further incorporate SBR-related inductive biases, i.e., local invariance and inherent priority to prune the search space. Experiments on three benchmarks demonstrate the effectiveness and efficiency of our proposal.
Decoupled Side Information Fusion for Sequential Recommendation
Apr 23, 2022
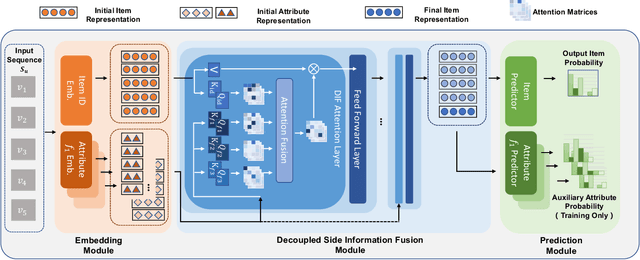
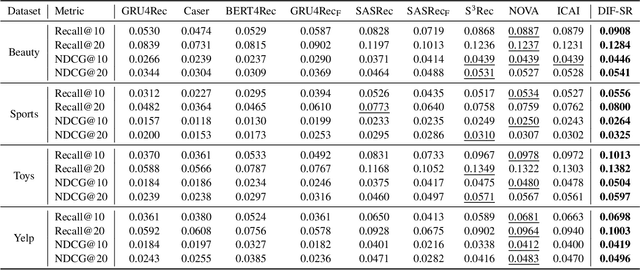
Side information fusion for sequential recommendation (SR) aims to effectively leverage various side information to enhance the performance of next-item prediction. Most state-of-the-art methods build on self-attention networks and focus on exploring various solutions to integrate the item embedding and side information embeddings before the attention layer. However, our analysis shows that the early integration of various types of embeddings limits the expressiveness of attention matrices due to a rank bottleneck and constrains the flexibility of gradients. Also, it involves mixed correlations among the different heterogeneous information resources, which brings extra disturbance to attention calculation. Motivated by this, we propose Decoupled Side Information Fusion for Sequential Recommendation (DIF-SR), which moves the side information from the input to the attention layer and decouples the attention calculation of various side information and item representation. We theoretically and empirically show that the proposed solution allows higher-rank attention matrices and flexible gradients to enhance the modeling capacity of side information fusion. Also, auxiliary attribute predictors are proposed to further activate the beneficial interaction between side information and item representation learning. Extensive experiments on four real-world datasets demonstrate that our proposed solution stably outperforms state-of-the-art SR models. Further studies show that our proposed solution can be readily incorporated into current attention-based SR models and significantly boost performance. Our source code is available at https://github.com/AIM-SE/DIF-SR.
IICNet: A Generic Framework for Reversible Image Conversion
Sep 09, 2021
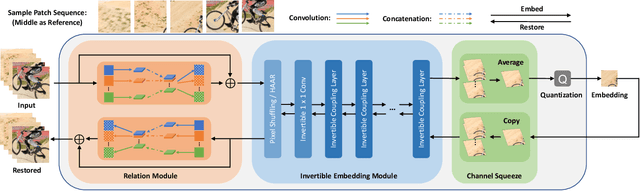
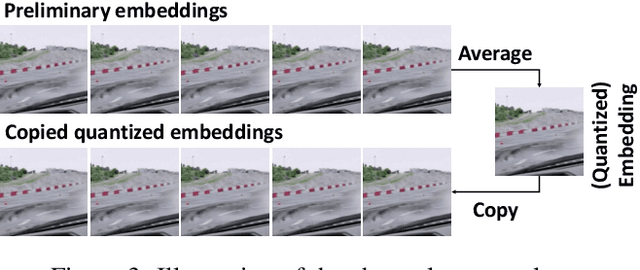
Reversible image conversion (RIC) aims to build a reversible transformation between specific visual content (e.g., short videos) and an embedding image, where the original content can be restored from the embedding when necessary. This work develops Invertible Image Conversion Net (IICNet) as a generic solution to various RIC tasks due to its strong capacity and task-independent design. Unlike previous encoder-decoder based methods, IICNet maintains a highly invertible structure based on invertible neural networks (INNs) to better preserve the information during conversion. We use a relation module and a channel squeeze layer to improve the INN nonlinearity to extract cross-image relations and the network flexibility, respectively. Experimental results demonstrate that IICNet outperforms the specifically-designed methods on existing RIC tasks and can generalize well to various newly-explored tasks. With our generic IICNet, we no longer need to hand-engineer task-specific embedding networks for rapidly occurring visual content. Our source codes are available at: https://github.com/felixcheng97/IICNet.
Enhanced Invertible Encoding for Learned Image Compression
Aug 08, 2021

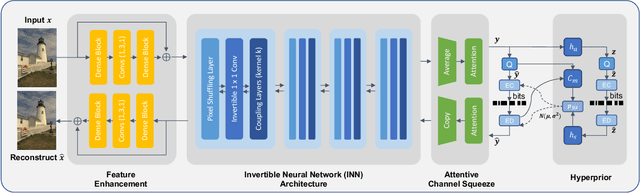
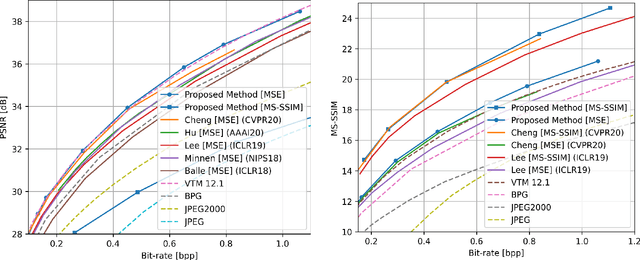
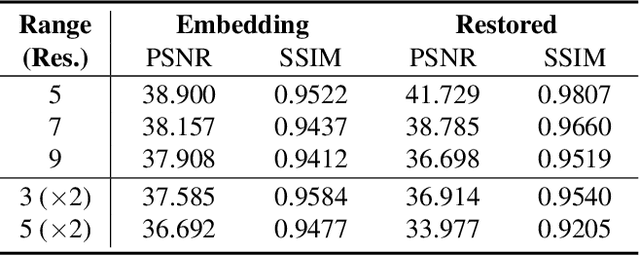
Although deep learning based image compression methods have achieved promising progress these days, the performance of these methods still cannot match the latest compression standard Versatile Video Coding (VVC). Most of the recent developments focus on designing a more accurate and flexible entropy model that can better parameterize the distributions of the latent features. However, few efforts are devoted to structuring a better transformation between the image space and the latent feature space. In this paper, instead of employing previous autoencoder style networks to build this transformation, we propose an enhanced Invertible Encoding Network with invertible neural networks (INNs) to largely mitigate the information loss problem for better compression. Experimental results on the Kodak, CLIC, and Tecnick datasets show that our method outperforms the existing learned image compression methods and compression standards, including VVC (VTM 12.1), especially for high-resolution images. Our source code is available at https://github.com/xyq7/InvCompress.
Predict Future Sales using Ensembled Random Forests
Apr 17, 2019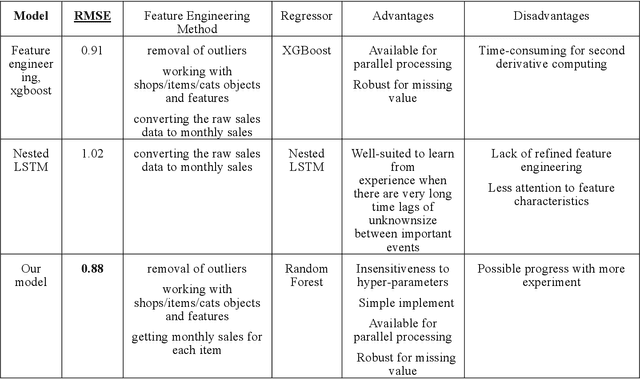
This is a method report for the Kaggle data competition 'Predict future sales'. In this paper, we propose a rather simple approach to future sales predicting based on feature engineering, Random Forest Regressor and ensemble learning. Its performance turned out to exceed many of the conventional methods and get final score 0.88186, representing root mean squared error. As of this writing, our model ranked 5th on the leaderboard. (till 8.5.2018)