 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTALENT: Table VQA via Augmented Language-Enhanced Natural-text Transcription
Oct 08, 2025Table Visual Question Answering (Table VQA) is typically addressed by large vision-language models (VLMs). While such models can answer directly from images, they often miss fine-grained details unless scaled to very large sizes, which are computationally prohibitive, especially for mobile deployment. A lighter alternative is to have a small VLM perform OCR and then use a large language model (LLM) to reason over structured outputs such as Markdown tables. However, these representations are not naturally optimized for LLMs and still introduce substantial errors. We propose TALENT (Table VQA via Augmented Language-Enhanced Natural-text Transcription), a lightweight framework that leverages dual representations of tables. TALENT prompts a small VLM to produce both OCR text and natural language narration, then combines them with the question for reasoning by an LLM. This reframes Table VQA as an LLM-centric multimodal reasoning task, where the VLM serves as a perception-narration module rather than a monolithic solver. Additionally, we construct ReTabVQA, a more challenging Table VQA dataset requiring multi-step quantitative reasoning over table images. Experiments show that TALENT enables a small VLM-LLM combination to match or surpass a single large VLM at significantly lower computational cost on both public datasets and ReTabVQA.
Interference Alignment for Multi-cluster Over-the-Air Computation
Oct 06, 2025One of the main challenges facing Internet of Things (IoT) networks is managing interference caused by the large number of devices communicating simultaneously, particularly in multi-cluster networks where multiple devices simultaneously transmit to their respective receiver. Over-the-Air Computation (AirComp) has emerged as a promising solution for efficient real-time data aggregation, yet its performance suffers in dense, interference-limited environments. To address this, we propose a novel Interference Alignment (IA) scheme tailored for up-link AirComp systems. Unlike previous approaches, the proposed method scales to an arbitrary number $\sf K$ of clusters and enables each cluster to exploit half of the available channels, instead of only $\tfrac{1}{\sf K}$ as in time-sharing. In addition, we develop schemes tailored to scenarios where users are shared between adjacent clusters.
FastAvatar: Towards Unified Fast High-Fidelity 3D Avatar Reconstruction with Large Gaussian Reconstruction Transformers
Aug 27, 2025Despite significant progress in 3D avatar reconstruction, it still faces challenges such as high time complexity, sensitivity to data quality, and low data utilization. We propose FastAvatar, a feedforward 3D avatar framework capable of flexibly leveraging diverse daily recordings (e.g., a single image, multi-view observations, or monocular video) to reconstruct a high-quality 3D Gaussian Splatting (3DGS) model within seconds, using only a single unified model. FastAvatar's core is a Large Gaussian Reconstruction Transformer featuring three key designs: First, a variant VGGT-style transformer architecture aggregating multi-frame cues while injecting initial 3D prompt to predict an aggregatable canonical 3DGS representation; Second, multi-granular guidance encoding (camera pose, FLAME expression, head pose) mitigating animation-induced misalignment for variable-length inputs; Third, incremental Gaussian aggregation via landmark tracking and sliced fusion losses. Integrating these features, FastAvatar enables incremental reconstruction, i.e., improving quality with more observations, unlike prior work wasting input data. This yields a quality-speed-tunable paradigm for highly usable avatar modeling. Extensive experiments show that FastAvatar has higher quality and highly competitive speed compared to existing methods.
VRBench: A Benchmark for Multi-Step Reasoning in Long Narrative Videos
Jun 12, 2025We present VRBench, the first long narrative video benchmark crafted for evaluating large models' multi-step reasoning capabilities, addressing limitations in existing evaluations that overlook temporal reasoning and procedural validity. It comprises 1,010 long videos (with an average duration of 1.6 hours), along with 9,468 human-labeled multi-step question-answering pairs and 30,292 reasoning steps with timestamps. These videos are curated via a multi-stage filtering process including expert inter-rater reviewing to prioritize plot coherence. We develop a human-AI collaborative framework that generates coherent reasoning chains, each requiring multiple temporally grounded steps, spanning seven types (e.g., event attribution, implicit inference). VRBench designs a multi-phase evaluation pipeline that assesses models at both the outcome and process levels. Apart from the MCQs for the final results, we propose a progress-level LLM-guided scoring metric to evaluate the quality of the reasoning chain from multiple dimensions comprehensively. Through extensive evaluations of 12 LLMs and 16 VLMs on VRBench, we undertake a thorough analysis and provide valuable insights that advance the field of multi-step reasoning.
Tensor-to-Tensor Models with Fast Iterated Sum Features
Jun 06, 2025Data in the form of images or higher-order tensors is ubiquitous in modern deep learning applications. Owing to their inherent high dimensionality, the need for subquadratic layers processing such data is even more pressing than for sequence data. We propose a novel tensor-to-tensor layer with linear cost in the input size, utilizing the mathematical gadget of ``corner trees'' from the field of permutation counting. In particular, for order-two tensors, we provide an image-to-image layer that can be plugged into image processing pipelines. On the one hand, our method can be seen as a higher-order generalization of state-space models. On the other hand, it is based on a multiparameter generalization of the signature of iterated integrals (or sums). The proposed tensor-to-tensor concept is used to build a neural network layer called the Fast Iterated Sums (FIS) layer which integrates seamlessly with other layer types. We demonstrate the usability of the FIS layer with both classification and anomaly detection tasks. By replacing some layers of a smaller ResNet architecture with FIS, a similar accuracy (with a difference of only 0.1\%) was achieved in comparison to a larger ResNet while reducing the number of trainable parameters and multi-add operations. The FIS layer was also used to build an anomaly detection model that achieved an average AUROC of 97.3\% on the texture images of the popular MVTec AD dataset. The processing and modelling codes are publicly available at https://github.com/diehlj/fast-iterated-sums.
Alita: Generalist Agent Enabling Scalable Agentic Reasoning with Minimal Predefinition and Maximal Self-Evolution
May 26, 2025



Recent advances in large language models (LLMs) have enabled agents to autonomously perform complex, open-ended tasks. However, many existing frameworks depend heavily on manually predefined tools and workflows, which hinder their adaptability, scalability, and generalization across domains. In this work, we introduce Alita--a generalist agent designed with the principle of "Simplicity is the ultimate sophistication," enabling scalable agentic reasoning through minimal predefinition and maximal self-evolution. For minimal predefinition, Alita is equipped with only one component for direct problem-solving, making it much simpler and neater than previous approaches that relied heavily on hand-crafted, elaborate tools and workflows. This clean design enhances its potential to generalize to challenging questions, without being limited by tools. For Maximal self-evolution, we enable the creativity of Alita by providing a suite of general-purpose components to autonomously construct, refine, and reuse external capabilities by generating task-related model context protocols (MCPs) from open source, which contributes to scalable agentic reasoning. Notably, Alita achieves 75.15% pass@1 and 87.27% pass@3 accuracy, which is top-ranking among general-purpose agents, on the GAIA benchmark validation dataset, 74.00% and 52.00% pass@1, respectively, on Mathvista and PathVQA, outperforming many agent systems with far greater complexity. More details will be updated at $\href{https://github.com/CharlesQ9/Alita}{https://github.com/CharlesQ9/Alita}$.
Shallow Preference Signals: Large Language Model Aligns Even Better with Truncated Data?
May 21, 2025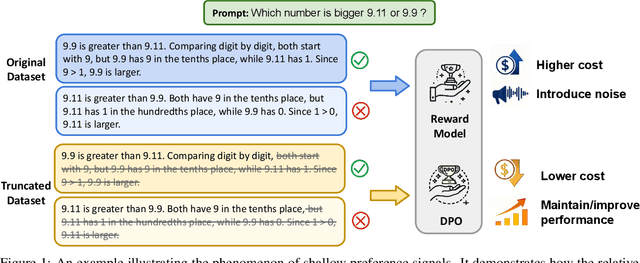
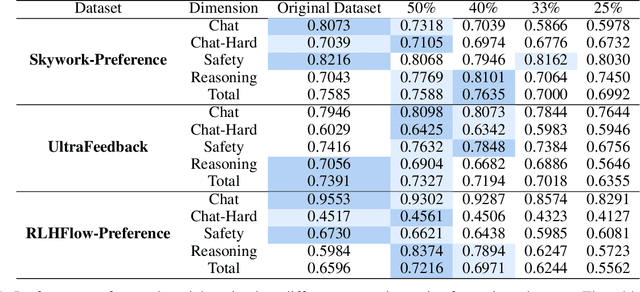
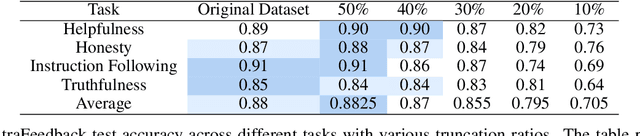
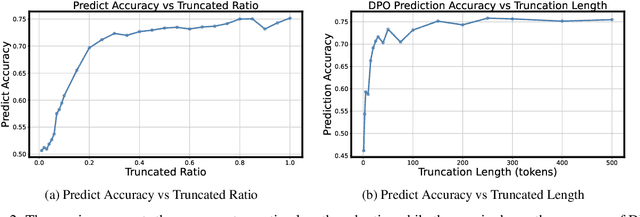
Aligning large language models (LLMs) with human preferences remains a key challenge in AI. Preference-based optimization methods, such as Reinforcement Learning with Human Feedback (RLHF) and Direct Preference Optimization (DPO), rely on human-annotated datasets to improve alignment. In this work, we identify a crucial property of the existing learning method: the distinguishing signal obtained in preferred responses is often concentrated in the early tokens. We refer to this as shallow preference signals. To explore this property, we systematically truncate preference datasets at various points and train both reward models and DPO models on the truncated data. Surprisingly, models trained on truncated datasets, retaining only the first half or fewer tokens, achieve comparable or even superior performance to those trained on full datasets. For example, a reward model trained on the Skywork-Reward-Preference-80K-v0.2 dataset outperforms the full dataset when trained on a 40\% truncated dataset. This pattern is consistent across multiple datasets, suggesting the widespread presence of shallow preference signals. We further investigate the distribution of the reward signal through decoding strategies. We consider two simple decoding strategies motivated by the shallow reward signal observation, namely Length Control Decoding and KL Threshold Control Decoding, which leverage shallow preference signals to optimize the trade-off between alignment and computational efficiency. The performance is even better, which again validates our hypothesis. The phenomenon of shallow preference signals highlights potential issues in LLM alignment: existing alignment methods often focus on aligning only the initial tokens of responses, rather than considering the full response. This could lead to discrepancies with real-world human preferences, resulting in suboptimal alignment performance.
Granular Loco-Manipulation: Repositioning Rocks Through Strategic Sand Avalanche
May 19, 2025Legged robots have the potential to leverage obstacles to climb steep sand slopes. However, efficiently repositioning these obstacles to desired locations is challenging. Here we present DiffusiveGRAIN, a learning-based method that enables a multi-legged robot to strategically induce localized sand avalanches during locomotion and indirectly manipulate obstacles. We conducted 375 trials, systematically varying obstacle spacing, robot orientation, and leg actions in 75 of them. Results show that the movement of closely-spaced obstacles exhibits significant interference, requiring joint modeling. In addition, different multi-leg excavation actions could cause distinct robot state changes, necessitating integrated planning of manipulation and locomotion. To address these challenges, DiffusiveGRAIN includes a diffusion-based environment predictor to capture multi-obstacle movements under granular flow interferences and a robot state predictor to estimate changes in robot state from multi-leg action patterns. Deployment experiments (90 trials) demonstrate that by integrating the environment and robot state predictors, the robot can autonomously plan its movements based on loco-manipulation goals, successfully shifting closely located rocks to desired locations in over 65% of trials. Our study showcases the potential for a locomoting robot to strategically manipulate obstacles to achieve improved mobility on challenging terrains.
A High-Performance Thermal Infrared Object Detection Framework with Centralized Regulation
May 16, 2025Thermal Infrared (TIR) technology involves the use of sensors to detect and measure infrared radiation emitted by objects, and it is widely utilized across a broad spectrum of applications. The advancements in object detection methods utilizing TIR images have sparked significant research interest. However, most traditional methods lack the capability to effectively extract and fuse local-global information, which is crucial for TIR-domain feature attention. In this study, we present a novel and efficient thermal infrared object detection framework, known as CRT-YOLO, that is based on centralized feature regulation, enabling the establishment of global-range interaction on TIR information. Our proposed model integrates efficient multi-scale attention (EMA) modules, which adeptly capture long-range dependencies while incurring minimal computational overhead. Additionally, it leverages the Centralized Feature Pyramid (CFP) network, which offers global regulation of TIR features. Extensive experiments conducted on two benchmark datasets demonstrate that our CRT-YOLO model significantly outperforms conventional methods for TIR image object detection. Furthermore, the ablation study provides compelling evidence of the effectiveness of our proposed modules, reinforcing the potential impact of our approach on advancing the field of thermal infrared object detection.
* This manuscript has been accepted for publication in the International Journal for Housing Science and Its Applications (IJHSA), 2025
AI-powered virtual eye: perspective, challenges and opportunities
May 07, 2025We envision the "virtual eye" as a next-generation, AI-powered platform that uses interconnected foundation models to simulate the eye's intricate structure and biological function across all scales. Advances in AI, imaging, and multiomics provide a fertile ground for constructing a universal, high-fidelity digital replica of the human eye. This perspective traces the evolution from early mechanistic and rule-based models to contemporary AI-driven approaches, integrating in a unified model with multimodal, multiscale, dynamic predictive capabilities and embedded feedback mechanisms. We propose a development roadmap emphasizing the roles of large-scale multimodal datasets, generative AI, foundation models, agent-based architectures, and interactive interfaces. Despite challenges in interpretability, ethics, data processing and evaluation, the virtual eye holds the potential to revolutionize personalized ophthalmic care and accelerate research into ocular health and disease.