 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRUBRIC-ARROW: Alternating Pointwise Rubric Reward Modeling for LLM Post-training in Non-verifiable Domains
May 27, 2026Pointwise reward modeling offers critical signals for LLM post-training, yet struggles with absolute scoring in subjective, non-verifiable settings. Rubric-based methods address this by decomposing evaluation into explicit criteria, but existing approaches typically depend on frontier LLMs and suffer from ties caused by hard Boolean aggregation. We present RUBRIC-ARROW, an alternating framework that jointly trains a rubric generator and a rubric-conditioned judge, with its RL stage using only pairwise preference data. Our method couples a probability-based scoring rule that reduces ties with phase-specific preference-based rewards and an alternating GRPO scheme that together train the pointwise evaluator. Extensive experiments show that RUBRIC-ARROW achieves competitive reward-modeling accuracy and yields consistent gains for downstream policy post-training.
TALENT: Table VQA via Augmented Language-Enhanced Natural-text Transcription
Oct 08, 2025Table Visual Question Answering (Table VQA) is typically addressed by large vision-language models (VLMs). While such models can answer directly from images, they often miss fine-grained details unless scaled to very large sizes, which are computationally prohibitive, especially for mobile deployment. A lighter alternative is to have a small VLM perform OCR and then use a large language model (LLM) to reason over structured outputs such as Markdown tables. However, these representations are not naturally optimized for LLMs and still introduce substantial errors. We propose TALENT (Table VQA via Augmented Language-Enhanced Natural-text Transcription), a lightweight framework that leverages dual representations of tables. TALENT prompts a small VLM to produce both OCR text and natural language narration, then combines them with the question for reasoning by an LLM. This reframes Table VQA as an LLM-centric multimodal reasoning task, where the VLM serves as a perception-narration module rather than a monolithic solver. Additionally, we construct ReTabVQA, a more challenging Table VQA dataset requiring multi-step quantitative reasoning over table images. Experiments show that TALENT enables a small VLM-LLM combination to match or surpass a single large VLM at significantly lower computational cost on both public datasets and ReTabVQA.
Revisiting Benchmark and Assessment: An Agent-based Exploratory Dynamic Evaluation Framework for LLMs
Oct 15, 2024



While various vertical domain large language models (LLMs) have been developed, the challenge of automatically evaluating their performance across different domains remains significant in addressing real-world user needs. Current benchmark-based evaluation methods exhibit rigid, purposeless interactions and rely on pre-collected static datasets that are costly to build, inflexible across domains, and misaligned with practical user needs. To address this, we revisit the evaluation components and introduce two definitions: **Benchmark+**, which extends traditional QA benchmarks into a more flexible ``strategy-criterion'' format; and **Assessment+**, which enhances the interaction process for greater exploration and enables both quantitative metrics and qualitative insights that capture nuanced target LLM behaviors from richer multi-turn interactions. We propose an agent-based evaluation framework called *TestAgent*, which implements these two concepts through retrieval augmented generation and reinforcement learning. Experiments on tasks ranging from building vertical domain evaluation from scratch to activating existing benchmarks demonstrate the effectiveness of *TestAgent* across various scenarios. We believe this work offers an interesting perspective on automatic evaluation for LLMs.
Visual Robotic Manipulation with Depth-Aware Pretraining
Jan 17, 2024



Recent work on visual representation learning has shown to be efficient for robotic manipulation tasks. However, most existing works pretrained the visual backbone solely on 2D images or egocentric videos, ignoring the fact that robots learn to act in 3D space, which is hard to learn from 2D observation. In this paper, we examine the effectiveness of pretraining for vision backbone with public-available large-scale 3D data to improve manipulation policy learning. Our method, namely Depth-aware Pretraining for Robotics (DPR), enables an RGB-only backbone to learn 3D scene representations from self-supervised contrastive learning, where depth information serves as auxiliary knowledge. No 3D information is necessary during manipulation policy learning and inference, making our model enjoy both efficiency and effectiveness in 3D space manipulation. Furthermore, we introduce a new way to inject robots' proprioception into the policy networks that makes the manipulation model robust and generalizable. We demonstrate in experiments that our proposed framework improves performance on unseen objects and visual environments for various robotics tasks on both simulated and real robots.
Exploring Gradient Explosion in Generative Adversarial Imitation Learning: A Probabilistic Perspective
Dec 18, 2023


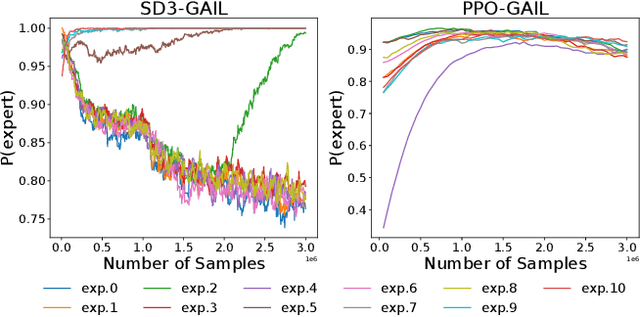
Generative Adversarial Imitation Learning (GAIL) stands as a cornerstone approach in imitation learning. This paper investigates the gradient explosion in two types of GAIL: GAIL with deterministic policy (DE-GAIL) and GAIL with stochastic policy (ST-GAIL). We begin with the observation that the training can be highly unstable for DE-GAIL at the beginning of the training phase and end up divergence. Conversely, the ST-GAIL training trajectory remains consistent, reliably converging. To shed light on these disparities, we provide an explanation from a theoretical perspective. By establishing a probabilistic lower bound for GAIL, we demonstrate that gradient explosion is an inevitable outcome for DE-GAIL due to occasionally large expert-imitator policy disparity, whereas ST-GAIL does not have the issue with it. To substantiate our assertion, we illustrate how modifications in the reward function can mitigate the gradient explosion challenge. Finally, we propose CREDO, a simple yet effective strategy that clips the reward function during the training phase, allowing the GAIL to enjoy high data efficiency and stable trainability.