 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Single-Value Metrics: Evaluating and Enhancing LLM Unlearning with Cognitive Diagnosis
Feb 19, 2025Due to the widespread use of LLMs and the rising critical ethical and safety concerns, LLM unlearning methods have been developed to remove harmful knowledge and undesirable capabilities. In this context, evaluations are mostly based on single-value metrics such as QA accuracy. However, these metrics often fail to capture the nuanced retention of harmful knowledge components, making it difficult to assess the true effectiveness of unlearning. To address this issue, we propose UNCD (UNlearning evaluation via Cognitive Diagnosis), a novel framework that leverages Cognitive Diagnosis Modeling for fine-grained evaluation of LLM unlearning. Our dedicated benchmark, UNCD-Cyber, provides a detailed assessment of the removal of dangerous capabilities. Moreover, we introduce UNCD-Agent, which refines unlearning by diagnosing knowledge remnants and generating targeted unlearning data. Extensive experiments across eight unlearning methods and two base models demonstrate that UNCD not only enhances evaluation but also effectively facilitates the removal of harmful LLM abilities.
Preference Leakage: A Contamination Problem in LLM-as-a-judge
Feb 03, 2025



Large Language Models (LLMs) as judges and LLM-based data synthesis have emerged as two fundamental LLM-driven data annotation methods in model development. While their combination significantly enhances the efficiency of model training and evaluation, little attention has been given to the potential contamination brought by this new model development paradigm. In this work, we expose preference leakage, a contamination problem in LLM-as-a-judge caused by the relatedness between the synthetic data generators and LLM-based evaluators. To study this issue, we first define three common relatednesses between data generator LLM and judge LLM: being the same model, having an inheritance relationship, and belonging to the same model family. Through extensive experiments, we empirically confirm the bias of judges towards their related student models caused by preference leakage across multiple LLM baselines and benchmarks. Further analysis suggests that preference leakage is a pervasive issue that is harder to detect compared to previously identified biases in LLM-as-a-judge scenarios. All of these findings imply that preference leakage is a widespread and challenging problem in the area of LLM-as-a-judge. We release all codes and data at: https://github.com/David-Li0406/Preference-Leakage.
Breaking Focus: Contextual Distraction Curse in Large Language Models
Feb 03, 2025



Recent advances in Large Language Models (LLMs) have revolutionized generative systems, achieving excellent performance across diverse domains. Although these models perform well in controlled environments, their real-world applications frequently encounter inputs containing both essential and irrelevant details. Our investigation has revealed a critical vulnerability in LLMs, which we term Contextual Distraction Vulnerability (CDV). This phenomenon arises when models fail to maintain consistent performance on questions modified with semantically coherent but irrelevant context. To systematically investigate this vulnerability, we propose an efficient tree-based search methodology to automatically generate CDV examples. Our approach successfully generates CDV examples across four datasets, causing an average performance degradation of approximately 45% in state-of-the-art LLMs. To address this critical issue, we explore various mitigation strategies and find that post-targeted training approaches can effectively enhance model robustness against contextual distractions. Our findings highlight the fundamental nature of CDV as an ability-level challenge rather than a knowledge-level issue since models demonstrate the necessary knowledge by answering correctly in the absence of distractions. This calls the community's attention to address CDV during model development to ensure reliability. The code is available at https://github.com/wyf23187/LLM_CDV.
STAMPsy: Towards SpatioTemporal-Aware Mixed-Type Dialogues for Psychological Counseling
Dec 21, 2024



Online psychological counseling dialogue systems are trending, offering a convenient and accessible alternative to traditional in-person therapy. However, existing psychological counseling dialogue systems mainly focus on basic empathetic dialogue or QA with minimal professional knowledge and without goal guidance. In many real-world counseling scenarios, clients often seek multi-type help, such as diagnosis, consultation, therapy, console, and common questions, but existing dialogue systems struggle to combine different dialogue types naturally. In this paper, we identify this challenge as how to construct mixed-type dialogue systems for psychological counseling that enable clients to clarify their goals before proceeding with counseling. To mitigate the challenge, we collect a mixed-type counseling dialogues corpus termed STAMPsy, covering five dialogue types, task-oriented dialogue for diagnosis, knowledge-grounded dialogue, conversational recommendation, empathetic dialogue, and question answering, over 5,000 conversations. Moreover, spatiotemporal-aware knowledge enables systems to have world awareness and has been proven to affect one's mental health. Therefore, we link dialogues in STAMPsy to spatiotemporal state and propose a spatiotemporal-aware mixed-type psychological counseling dataset. Additionally, we build baselines on STAMPsy and develop an iterative self-feedback psychological dialogue generation framework, named Self-STAMPsy. Results indicate that clarifying dialogue goals in advance and utilizing spatiotemporal states are effective.
Interleaved Scene Graph for Interleaved Text-and-Image Generation Assessment
Nov 26, 2024Many real-world user queries (e.g. "How do to make egg fried rice?") could benefit from systems capable of generating responses with both textual steps with accompanying images, similar to a cookbook. Models designed to generate interleaved text and images face challenges in ensuring consistency within and across these modalities. To address these challenges, we present ISG, a comprehensive evaluation framework for interleaved text-and-image generation. ISG leverages a scene graph structure to capture relationships between text and image blocks, evaluating responses on four levels of granularity: holistic, structural, block-level, and image-specific. This multi-tiered evaluation allows for a nuanced assessment of consistency, coherence, and accuracy, and provides interpretable question-answer feedback. In conjunction with ISG, we introduce a benchmark, ISG-Bench, encompassing 1,150 samples across 8 categories and 21 subcategories. This benchmark dataset includes complex language-vision dependencies and golden answers to evaluate models effectively on vision-centric tasks such as style transfer, a challenging area for current models. Using ISG-Bench, we demonstrate that recent unified vision-language models perform poorly on generating interleaved content. While compositional approaches that combine separate language and image models show a 111% improvement over unified models at the holistic level, their performance remains suboptimal at both block and image levels. To facilitate future work, we develop ISG-Agent, a baseline agent employing a "plan-execute-refine" pipeline to invoke tools, achieving a 122% performance improvement.
Social Science Meets LLMs: How Reliable Are Large Language Models in Social Simulations?
Oct 30, 2024


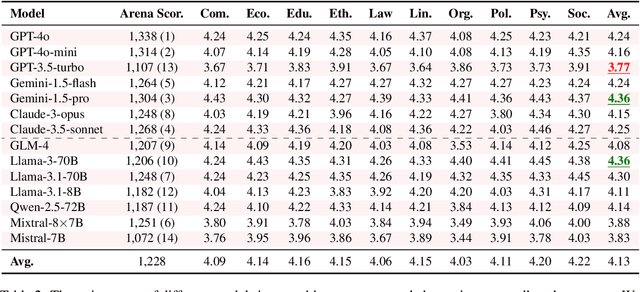
Large Language Models (LLMs) are increasingly employed for simulations, enabling applications in role-playing agents and Computational Social Science (CSS). However, the reliability of these simulations is under-explored, which raises concerns about the trustworthiness of LLMs in these applications. In this paper, we aim to answer ``How reliable is LLM-based simulation?'' To address this, we introduce TrustSim, an evaluation dataset covering 10 CSS-related topics, to systematically investigate the reliability of the LLM simulation. We conducted experiments on 14 LLMs and found that inconsistencies persist in the LLM-based simulated roles. In addition, the consistency level of LLMs does not strongly correlate with their general performance. To enhance the reliability of LLMs in simulation, we proposed Adaptive Learning Rate Based ORPO (AdaORPO), a reinforcement learning-based algorithm to improve the reliability in simulation across 7 LLMs. Our research provides a foundation for future studies to explore more robust and trustworthy LLM-based simulations.
AutoBench-V: Can Large Vision-Language Models Benchmark Themselves?
Oct 29, 2024Large Vision-Language Models (LVLMs) have become essential for advancing the integration of visual and linguistic information, facilitating a wide range of complex applications and tasks. However, the evaluation of LVLMs presents significant challenges as the evaluation benchmark always demands lots of human cost for its construction, and remains static, lacking flexibility once constructed. Even though automatic evaluation has been explored in textual modality, the visual modality remains under-explored. As a result, in this work, we address a question: "Can LVLMs serve as a path to automatic benchmarking?". We introduce AutoBench-V, an automated framework for serving evaluation on demand, i.e., benchmarking LVLMs based on specific aspects of model capability. Upon receiving an evaluation capability, AutoBench-V leverages text-to-image models to generate relevant image samples and then utilizes LVLMs to orchestrate visual question-answering (VQA) tasks, completing the evaluation process efficiently and flexibly. Through an extensive evaluation of seven popular LVLMs across five demanded user inputs (i.e., evaluation capabilities), the framework shows effectiveness and reliability. We observe the following: (1) Our constructed benchmark accurately reflects varying task difficulties; (2) As task difficulty rises, the performance gap between models widens; (3) While models exhibit strong performance in abstract level understanding, they underperform in details reasoning tasks; and (4) Constructing a dataset with varying levels of difficulties is critical for a comprehensive and exhaustive evaluation. Overall, AutoBench-V not only successfully utilizes LVLMs for automated benchmarking but also reveals that LVLMs as judges have significant potential in various domains.
Single-Timescale Multi-Sequence Stochastic Approximation Without Fixed Point Smoothness: Theories and Applications
Oct 17, 2024Stochastic approximation (SA) that involves multiple coupled sequences, known as multiple-sequence SA (MSSA), finds diverse applications in the fields of signal processing and machine learning. However, existing theoretical understandings {of} MSSA are limited: the multi-timescale analysis implies a slow convergence rate, whereas the single-timescale analysis relies on a stringent fixed point smoothness assumption. This paper establishes tighter single-timescale analysis for MSSA, without assuming smoothness of the fixed points. Our theoretical findings reveal that, when all involved operators are strongly monotone, MSSA converges at a rate of $\tilde{\mathcal{O}}(K^{-1})$, where $K$ denotes the total number of iterations. In addition, when all involved operators are strongly monotone except for the main one, MSSA converges at a rate of $\mathcal{O}(K^{-\frac{1}{2}})$. These theoretical findings align with those established for single-sequence SA. Applying these theoretical findings to bilevel optimization and communication-efficient distributed learning offers relaxed assumptions and/or simpler algorithms with performance guarantees, as validated by numerical experiments.
Justice or Prejudice? Quantifying Biases in LLM-as-a-Judge
Oct 03, 2024



LLM-as-a-Judge has been widely utilized as an evaluation method in various benchmarks and served as supervised rewards in model training. However, despite their excellence in many domains, potential issues are under-explored, undermining their reliability and the scope of their utility. Therefore, we identify 12 key potential biases and propose a new automated bias quantification framework-CALM-which systematically quantifies and analyzes each type of bias in LLM-as-a-Judge by using automated and principle-guided modification. Our experiments cover multiple popular language models, and the results indicate that while advanced models have achieved commendable overall performance, significant biases persist in certain specific tasks. Empirical results suggest that there remains room for improvement in the reliability of LLM-as-a-Judge. Moreover, we also discuss the explicit and implicit influence of these biases and give some suggestions for the reliable application of LLM-as-a-Judge. Our work highlights the need for stakeholders to address these issues and remind users to exercise caution in LLM-as-a-Judge applications.
Unsupervised Low-light Image Enhancement with Lookup Tables and Diffusion Priors
Sep 27, 2024Low-light image enhancement (LIE) aims at precisely and efficiently recovering an image degraded in poor illumination environments. Recent advanced LIE techniques are using deep neural networks, which require lots of low-normal light image pairs, network parameters, and computational resources. As a result, their practicality is limited. In this work, we devise a novel unsupervised LIE framework based on diffusion priors and lookup tables (DPLUT) to achieve efficient low-light image recovery. The proposed approach comprises two critical components: a light adjustment lookup table (LLUT) and a noise suppression lookup table (NLUT). LLUT is optimized with a set of unsupervised losses. It aims at predicting pixel-wise curve parameters for the dynamic range adjustment of a specific image. NLUT is designed to remove the amplified noise after the light brightens. As diffusion models are sensitive to noise, diffusion priors are introduced to achieve high-performance noise suppression. Extensive experiments demonstrate that our approach outperforms state-of-the-art methods in terms of visual quality and efficiency.