 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the One-sided Convergence of Adam-type Algorithms in Non-convex Non-concave Min-max Optimization
Sep 29, 2021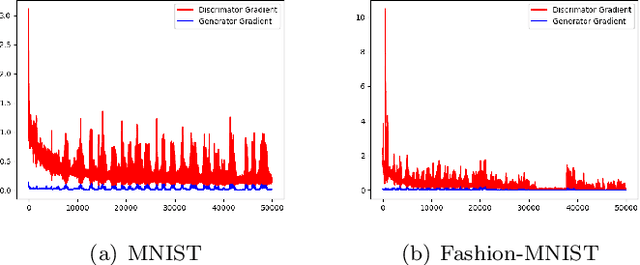
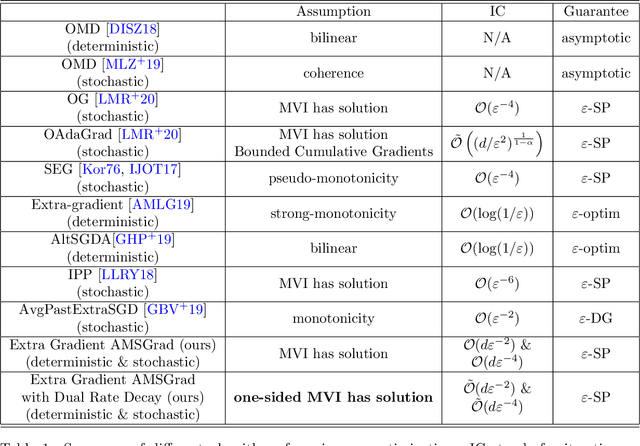

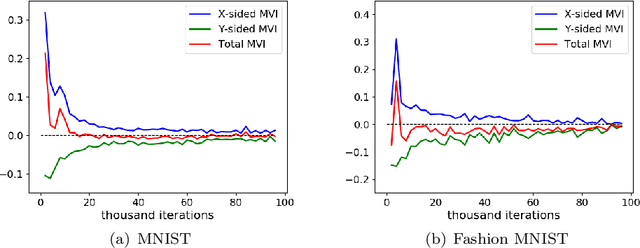
Adam-type methods, the extension of adaptive gradient methods, have shown great performance in the training of both supervised and unsupervised machine learning models. In particular, Adam-type optimizers have been widely used empirically as the default tool for training generative adversarial networks (GANs). On the theory side, however, despite the existence of theoretical results showing the efficiency of Adam-type methods in minimization problems, the reason of their wonderful performance still remains absent in GAN's training. In existing works, the fast convergence has long been considered as one of the most important reasons and multiple works have been proposed to give a theoretical guarantee of the convergence to a critical point of min-max optimization algorithms under certain assumptions. In this paper, we firstly argue empirically that in GAN's training, Adam does not converge to a critical point even upon successful training: Only the generator is converging while the discriminator's gradient norm remains high throughout the training. We name this one-sided convergence. Then we bridge the gap between experiments and theory by showing that Adam-type algorithms provably converge to a one-sided first order stationary points in min-max optimization problems under the one-sided MVI condition. We also empirically verify that such one-sided MVI condition is satisfied for standard GANs after trained over standard data sets. To the best of our knowledge, this is the very first result which provides an empirical observation and a strict theoretical guarantee on the one-sided convergence of Adam-type algorithms in min-max optimization.
Understanding the Generalization of Adam in Learning Neural Networks with Proper Regularization
Aug 25, 2021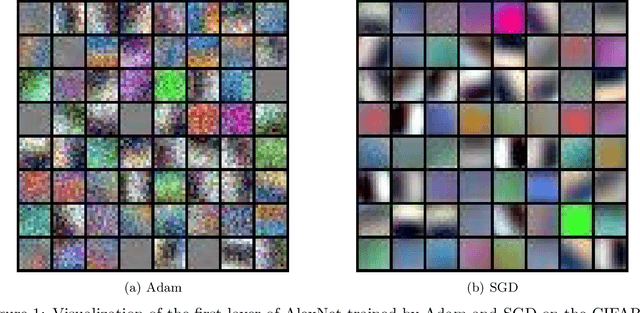
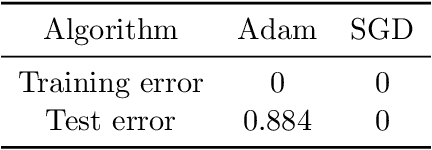
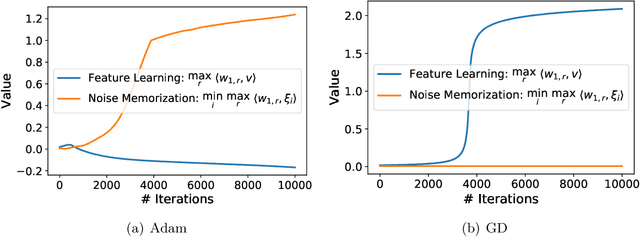
Adaptive gradient methods such as Adam have gained increasing popularity in deep learning optimization. However, it has been observed that compared with (stochastic) gradient descent, Adam can converge to a different solution with a significantly worse test error in many deep learning applications such as image classification, even with a fine-tuned regularization. In this paper, we provide a theoretical explanation for this phenomenon: we show that in the nonconvex setting of learning over-parameterized two-layer convolutional neural networks starting from the same random initialization, for a class of data distributions (inspired from image data), Adam and gradient descent (GD) can converge to different global solutions of the training objective with provably different generalization errors, even with weight decay regularization. In contrast, we show that if the training objective is convex, and the weight decay regularization is employed, any optimization algorithms including Adam and GD will converge to the same solution if the training is successful. This suggests that the inferior generalization performance of Adam is fundamentally tied to the nonconvex landscape of deep learning optimization.
LoRA: Low-Rank Adaptation of Large Language Models
Jun 17, 2021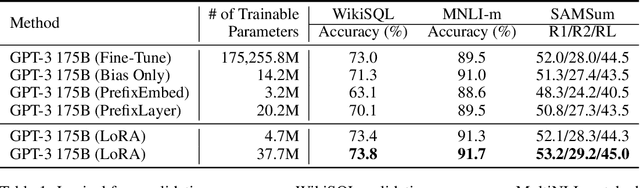
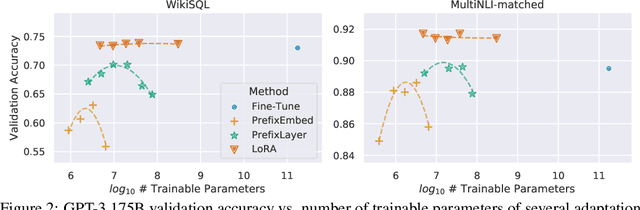
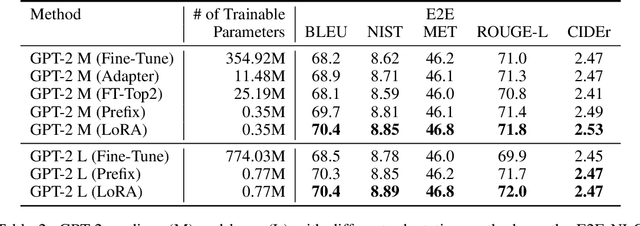
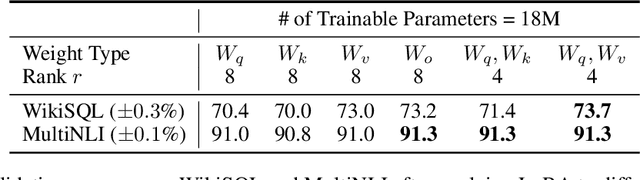
The dominant paradigm of natural language processing consists of large-scale pre-training on general domain data and adaptation to particular tasks or domains. As we pre-train larger models, conventional fine-tuning, which retrains all model parameters, becomes less feasible. Using GPT-3 175B as an example, deploying many independent instances of fine-tuned models, each with 175B parameters, is extremely expensive. We propose Low-Rank Adaptation, or LoRA, which freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks. For GPT-3, LoRA can reduce the number of trainable parameters by 10,000 times and the computation hardware requirement by 3 times compared to full fine-tuning. LoRA performs on-par or better than fine-tuning in model quality on both GPT-3 and GPT-2, despite having fewer trainable parameters, a higher training throughput, and no additional inference latency. We also provide an empirical investigation into rank-deficiency in language model adaptations, which sheds light on the efficacy of LoRA. We release our implementation in GPT-2 at https://github.com/microsoft/LoRA .
Sample Efficient Reinforcement Learning In Continuous State Spaces: A Perspective Beyond Linearity
Jun 15, 2021
Reinforcement learning (RL) is empirically successful in complex nonlinear Markov decision processes (MDPs) with continuous state spaces. By contrast, the majority of theoretical RL literature requires the MDP to satisfy some form of linear structure, in order to guarantee sample efficient RL. Such efforts typically assume the transition dynamics or value function of the MDP are described by linear functions of the state features. To resolve this discrepancy between theory and practice, we introduce the Effective Planning Window (EPW) condition, a structural condition on MDPs that makes no linearity assumptions. We demonstrate that the EPW condition permits sample efficient RL, by providing an algorithm which provably solves MDPs satisfying this condition. Our algorithm requires minimal assumptions on the policy class, which can include multi-layer neural networks with nonlinear activation functions. Notably, the EPW condition is directly motivated by popular gaming benchmarks, and we show that many classic Atari games satisfy this condition. We additionally show the necessity of conditions like EPW, by demonstrating that simple MDPs with slight nonlinearities cannot be solved sample efficiently.
Toward Understanding the Feature Learning Process of Self-supervised Contrastive Learning
Jun 12, 2021

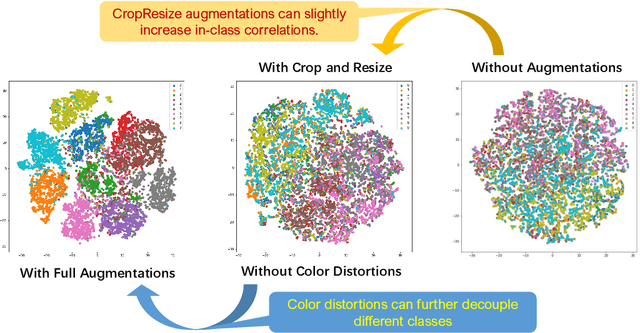
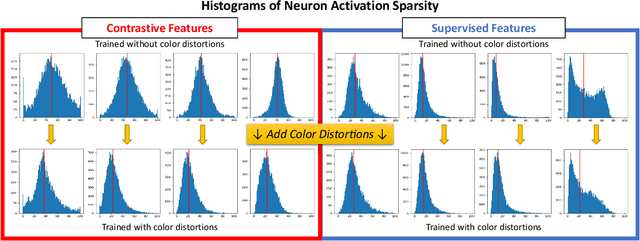
How can neural networks trained by contrastive learning extract features from the unlabeled data? Why does contrastive learning usually need much stronger data augmentations than supervised learning to ensure good representations? These questions involve both the optimization and statistical aspects of deep learning, but can hardly be answered by analyzing supervised learning, where the target functions are the highest pursuit. Indeed, in self-supervised learning, it is inevitable to relate to the optimization/generalization of neural networks to how they can encode the latent structures in the data, which we refer to as the feature learning process. In this work, we formally study how contrastive learning learns the feature representations for neural networks by analyzing its feature learning process. We consider the case where our data are comprised of two types of features: the more semantically aligned sparse features which we want to learn from, and the other dense features we want to avoid. Theoretically, we prove that contrastive learning using $\mathbf{ReLU}$ networks provably learns the desired sparse features if proper augmentations are adopted. We present an underlying principle called $\textbf{feature decoupling}$ to explain the effects of augmentations, where we theoretically characterize how augmentations can reduce the correlations of dense features between positive samples while keeping the correlations of sparse features intact, thereby forcing the neural networks to learn from the self-supervision of sparse features. Empirically, we verified that the feature decoupling principle matches the underlying mechanism of contrastive learning in practice.
Forward Super-Resolution: How Can GANs Learn Hierarchical Generative Models for Real-World Distributions
Jun 04, 2021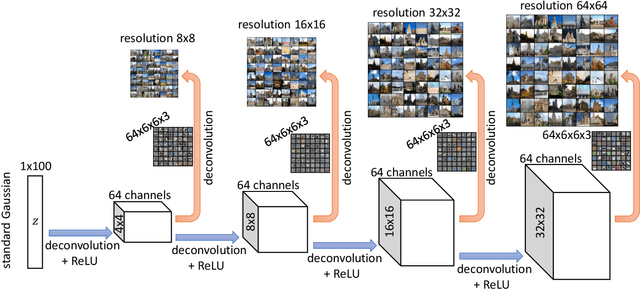

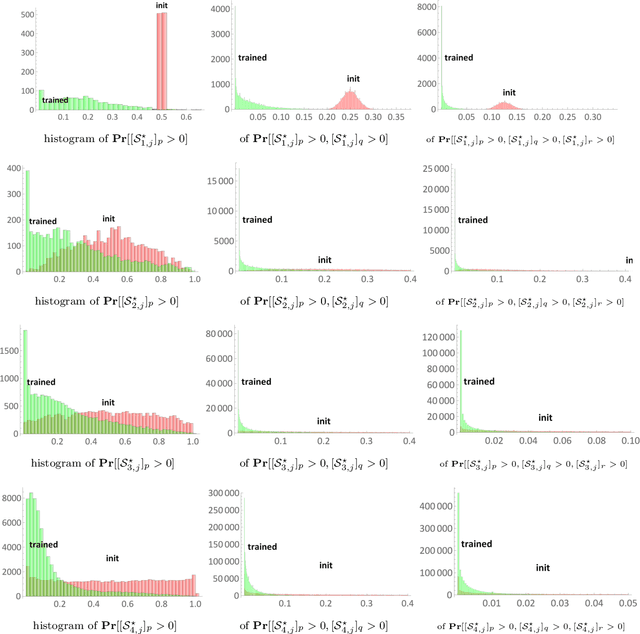
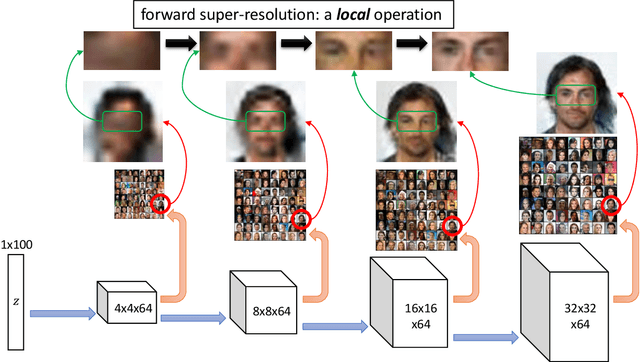
Generative adversarial networks (GANs) are among the most successful models for learning high-complexity, real-world distributions. However, in theory, due to the highly non-convex, non-concave landscape of the minmax training objective, GAN remains one of the least understood deep learning models. In this work, we formally study how GANs can efficiently learn certain hierarchically generated distributions that are close to the distribution of images in practice. We prove that when a distribution has a structure that we refer to as Forward Super-Resolution, then simply training generative adversarial networks using gradient descent ascent (GDA) can indeed learn this distribution efficiently, both in terms of sample and time complexities. We also provide concrete empirical evidence that not only our assumption "forward super-resolution" is very natural in practice, but also the underlying learning mechanisms that we study in this paper (to allow us efficiently train GAN via GDA in theory) simulates the actual learning process of GANs in practice on real-world problems.
Gradient Descent on Neural Networks Typically Occurs at the Edge of Stability
Feb 26, 2021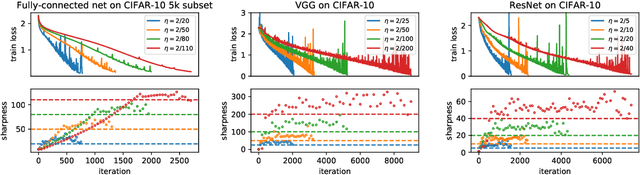
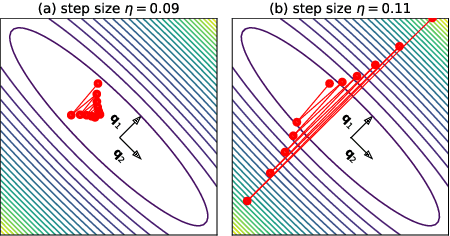

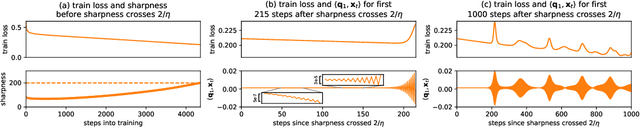
We empirically demonstrate that full-batch gradient descent on neural network training objectives typically operates in a regime we call the Edge of Stability. In this regime, the maximum eigenvalue of the training loss Hessian hovers just above the numerical value $2 / \text{(step size)}$, and the training loss behaves non-monotonically over short timescales, yet consistently decreases over long timescales. Since this behavior is inconsistent with several widespread presumptions in the field of optimization, our findings raise questions as to whether these presumptions are relevant to neural network training. We hope that our findings will inspire future efforts aimed at rigorously understanding optimization at the Edge of Stability. Code is available at https://github.com/locuslab/edge-of-stability.
When Is Generalizable Reinforcement Learning Tractable?
Jan 01, 2021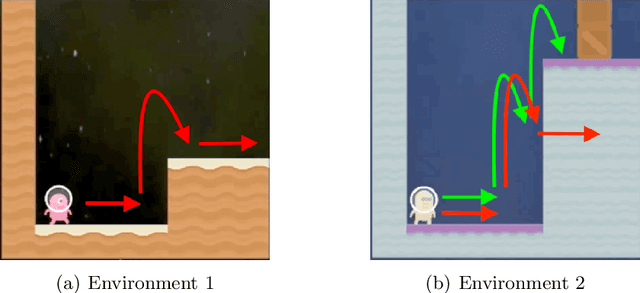
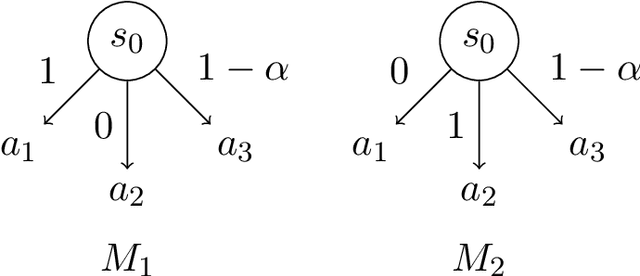
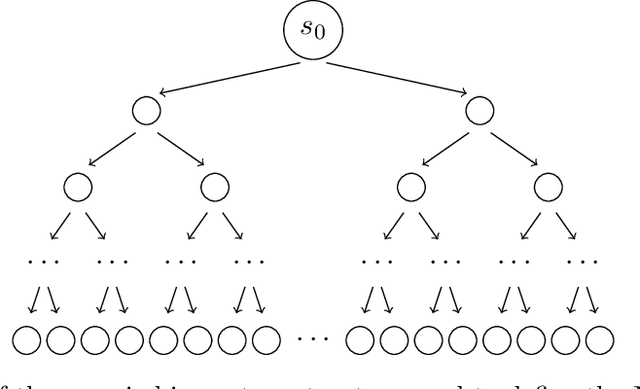
Agents trained by reinforcement learning (RL) often fail to generalize beyond the environment they were trained in, even when presented with new scenarios that seem very similar to the training environment. We study the query complexity required to train RL agents that can generalize to multiple environments. Intuitively, tractable generalization is only possible when the environments are similar or close in some sense. To capture this, we introduce Strong Proximity, a structural condition which precisely characterizes the relative closeness of different environments. We provide an algorithm which exploits Strong Proximity to provably and efficiently generalize. We also show that under a natural weakening of this condition, which we call Weak Proximity, RL can require query complexity that is exponential in the horizon to generalize. A key consequence of our theory is that even when the environments share optimal trajectories, and have highly similar reward and transition functions (as measured by classical metrics), tractable generalization is impossible.
Towards Understanding Ensemble, Knowledge Distillation and Self-Distillation in Deep Learning
Dec 17, 2020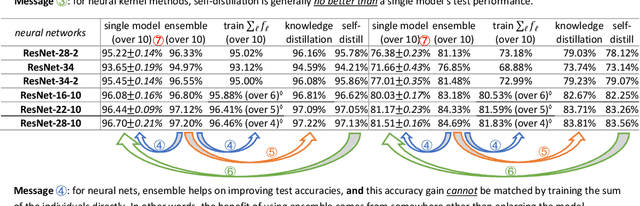
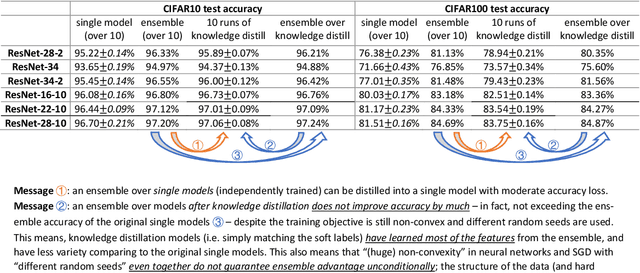

We formally study how Ensemble of deep learning models can improve test accuracy, and how the superior performance of ensemble can be distilled into a single model using Knowledge Distillation. We consider the challenging case where the ensemble is simply an average of the outputs of a few independently trained neural networks with the SAME architecture, trained using the SAME algorithm on the SAME data set, and they only differ by the random seeds used in the initialization. We empirically show that ensemble/knowledge distillation in deep learning works very differently from traditional learning theory, especially differently from ensemble of random feature mappings or the neural-tangent-kernel feature mappings, and is potentially out of the scope of existing theorems. Thus, to properly understand ensemble and knowledge distillation in deep learning, we develop a theory showing that when data has a structure we refer to as "multi-view", then ensemble of independently trained neural networks can provably improve test accuracy, and such superior test accuracy can also be provably distilled into a single model by training a single model to match the output of the ensemble instead of the true label. Our result sheds light on how ensemble works in deep learning in a way that is completely different from traditional theorems, and how the "dark knowledge" is hidden in the outputs of the ensemble -- that can be used in knowledge distillation -- comparing to the true data labels. In the end, we prove that self-distillation can also be viewed as implicitly combining ensemble and knowledge distillation to improve test accuracy.
A law of robustness for two-layers neural networks
Sep 30, 2020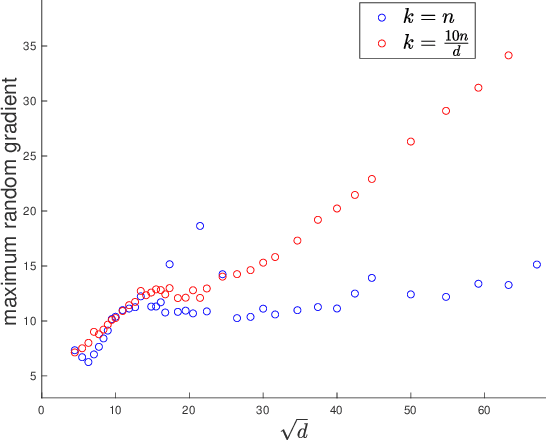
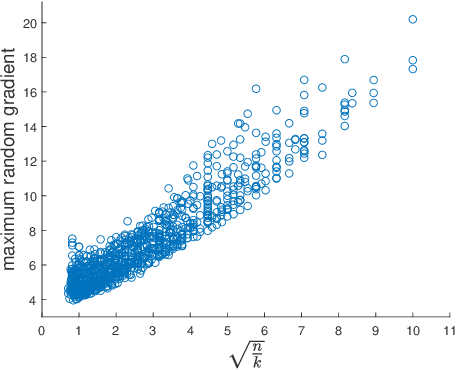
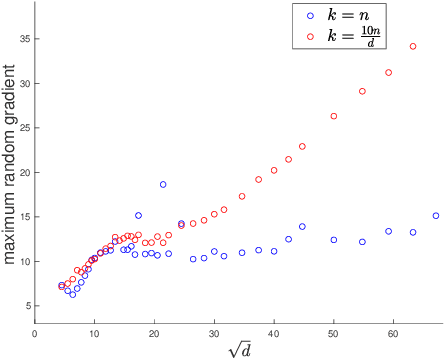
We initiate the study of the inherent tradeoffs between the size of a neural network and its robustness, as measured by its Lipschitz constant. We make a precise conjecture that, for any Lipschitz activation function and for most datasets, any two-layers neural network with $k$ neurons that perfectly fit the data must have its Lipschitz constant larger (up to a constant) than $\sqrt{n/k}$ where $n$ is the number of datapoints. In particular, this conjecture implies that overparametrization is necessary for robustness, since it means that one needs roughly one neuron per datapoint to ensure a $O(1)$-Lipschitz network, while mere data fitting of $d$-dimensional data requires only one neuron per $d$ datapoints. We prove a weaker version of this conjecture when the Lipschitz constant is replaced by an upper bound on it based on the spectral norm of the weight matrix. We also prove the conjecture for the ReLU activation function in the high-dimensional regime $n \approx d$, and for a polynomial activation function of degree $p$ when $n \approx d^p$. We complement these findings with experimental evidence supporting the conjecture.