 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting adaptive methods in GANs
Oct 09, 2022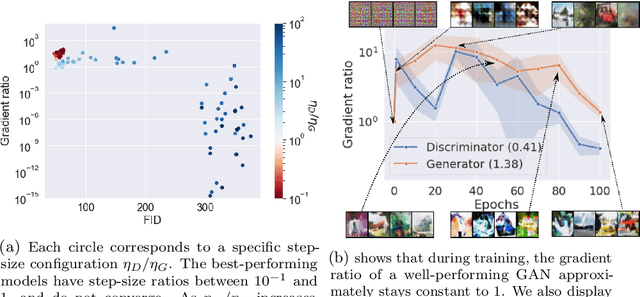
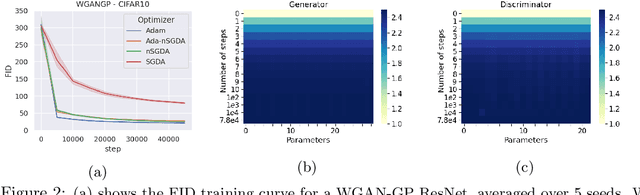
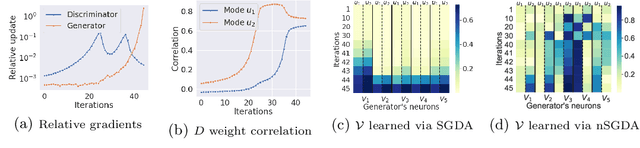
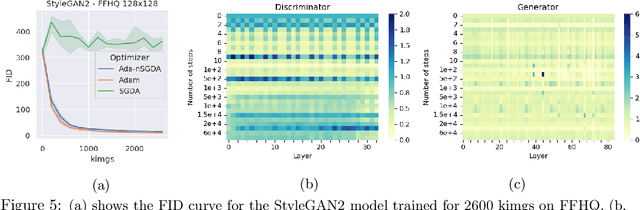
Adaptive methods are a crucial component widely used for training generative adversarial networks (GANs). While there has been some work to pinpoint the "marginal value of adaptive methods" in standard tasks, it remains unclear why they are still critical for GAN training. In this paper, we formally study how adaptive methods help train GANs; inspired by the grafting method proposed in arXiv:2002.11803 [cs.LG], we separate the magnitude and direction components of the Adam updates, and graft them to the direction and magnitude of SGDA updates respectively. By considering an update rule with the magnitude of the Adam update and the normalized direction of SGD, we empirically show that the adaptive magnitude of Adam is key for GAN training. This motivates us to have a closer look at the class of normalized stochastic gradient descent ascent (nSGDA) methods in the context of GAN training. We propose a synthetic theoretical framework to compare the performance of nSGDA and SGDA for GAN training with neural networks. We prove that in that setting, GANs trained with nSGDA recover all the modes of the true distribution, whereas the same networks trained with SGDA (and any learning rate configuration) suffer from mode collapse. The critical insight in our analysis is that normalizing the gradients forces the discriminator and generator to be updated at the same pace. We also experimentally show that for several datasets, Adam's performance can be recovered with nSGDA methods.
Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions
Oct 04, 2022We provide theoretical convergence guarantees for score-based generative models (SGMs) such as denoising diffusion probabilistic models (DDPMs), which constitute the backbone of large-scale real-world generative models such as DALL$\cdot$E 2. Our main result is that, assuming accurate score estimates, such SGMs can efficiently sample from essentially any realistic data distribution. In contrast to prior works, our results (1) hold for an $L^2$-accurate score estimate (rather than $L^\infty$-accurate); (2) do not require restrictive functional inequality conditions that preclude substantial non-log-concavity; (3) scale polynomially in all relevant problem parameters; and (4) match state-of-the-art complexity guarantees for discretization of the Langevin diffusion, provided that the score error is sufficiently small. We view this as strong theoretical justification for the empirical success of SGMs. We also examine SGMs based on the critically damped Langevin diffusion (CLD). Contrary to conventional wisdom, we provide evidence that the use of the CLD does not reduce the complexity of SGMs.
Towards Understanding Mixture of Experts in Deep Learning
Aug 04, 2022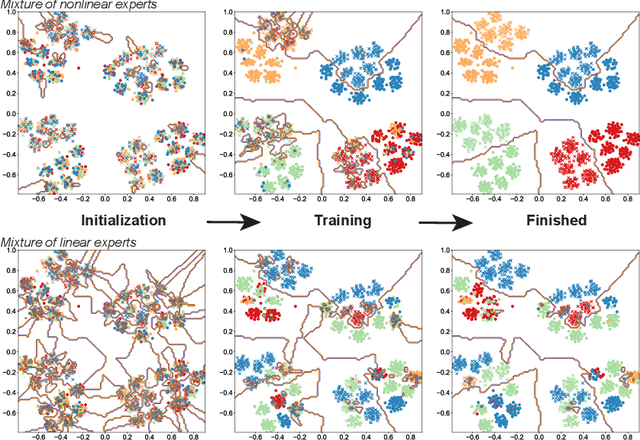

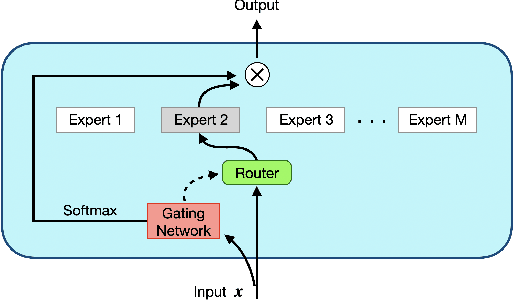
The Mixture-of-Experts (MoE) layer, a sparsely-activated model controlled by a router, has achieved great success in deep learning. However, the understanding of such architecture remains elusive. In this paper, we formally study how the MoE layer improves the performance of neural network learning and why the mixture model will not collapse into a single model. Our empirical results suggest that the cluster structure of the underlying problem and the non-linearity of the expert are pivotal to the success of MoE. To further understand this, we consider a challenging classification problem with intrinsic cluster structures, which is hard to learn using a single expert. Yet with the MoE layer, by choosing the experts as two-layer nonlinear convolutional neural networks (CNNs), we show that the problem can be learned successfully. Furthermore, our theory shows that the router can learn the cluster-center features, which helps divide the input complex problem into simpler linear classification sub-problems that individual experts can conquer. To our knowledge, this is the first result towards formally understanding the mechanism of the MoE layer for deep learning.
Towards understanding how momentum improves generalization in deep learning
Jul 13, 2022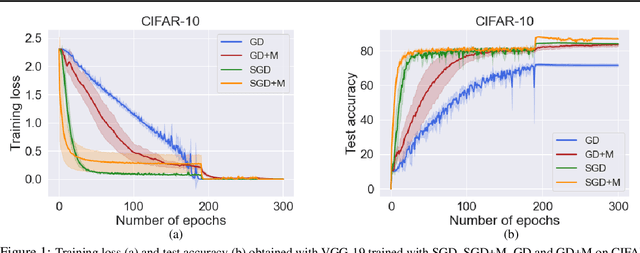
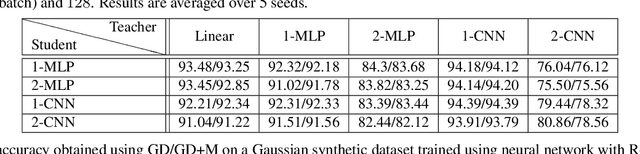
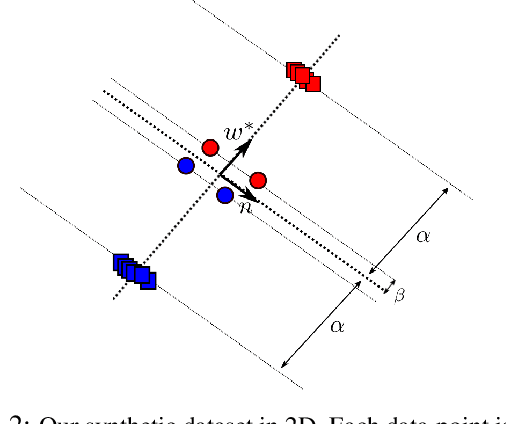
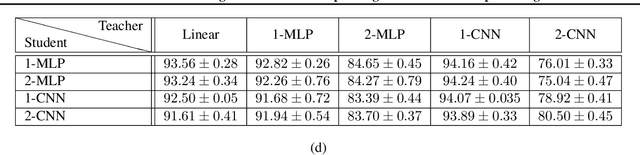
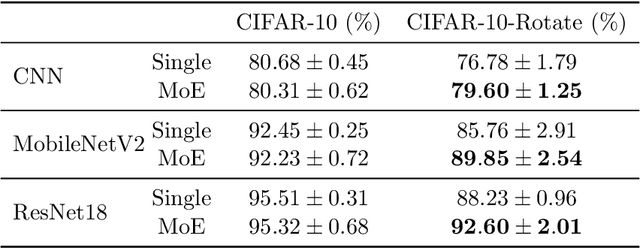
Stochastic gradient descent (SGD) with momentum is widely used for training modern deep learning architectures. While it is well-understood that using momentum can lead to faster convergence rate in various settings, it has also been observed that momentum yields higher generalization. Prior work argue that momentum stabilizes the SGD noise during training and this leads to higher generalization. In this paper, we adopt another perspective and first empirically show that gradient descent with momentum (GD+M) significantly improves generalization compared to gradient descent (GD) in some deep learning problems. From this observation, we formally study how momentum improves generalization. We devise a binary classification setting where a one-hidden layer (over-parameterized) convolutional neural network trained with GD+M provably generalizes better than the same network trained with GD, when both algorithms are similarly initialized. The key insight in our analysis is that momentum is beneficial in datasets where the examples share some feature but differ in their margin. Contrary to GD that memorizes the small margin data, GD+M still learns the feature in these data thanks to its historical gradients. Lastly, we empirically validate our theoretical findings.
Learning (Very) Simple Generative Models Is Hard
May 31, 2022

Motivated by the recent empirical successes of deep generative models, we study the computational complexity of the following unsupervised learning problem. For an unknown neural network $F:\mathbb{R}^d\to\mathbb{R}^{d'}$, let $D$ be the distribution over $\mathbb{R}^{d'}$ given by pushing the standard Gaussian $\mathcal{N}(0,\textrm{Id}_d)$ through $F$. Given i.i.d. samples from $D$, the goal is to output any distribution close to $D$ in statistical distance. We show under the statistical query (SQ) model that no polynomial-time algorithm can solve this problem even when the output coordinates of $F$ are one-hidden-layer ReLU networks with $\log(d)$ neurons. Previously, the best lower bounds for this problem simply followed from lower bounds for supervised learning and required at least two hidden layers and $\mathrm{poly}(d)$ neurons [Daniely-Vardi '21, Chen-Gollakota-Klivans-Meka '22]. The key ingredient in our proof is an ODE-based construction of a compactly supported, piecewise-linear function $f$ with polynomially-bounded slopes such that the pushforward of $\mathcal{N}(0,1)$ under $f$ matches all low-degree moments of $\mathcal{N}(0,1)$.
The Mechanism of Prediction Head in Non-contrastive Self-supervised Learning
May 14, 2022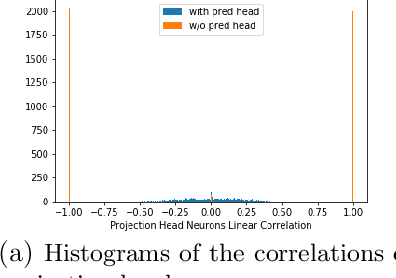
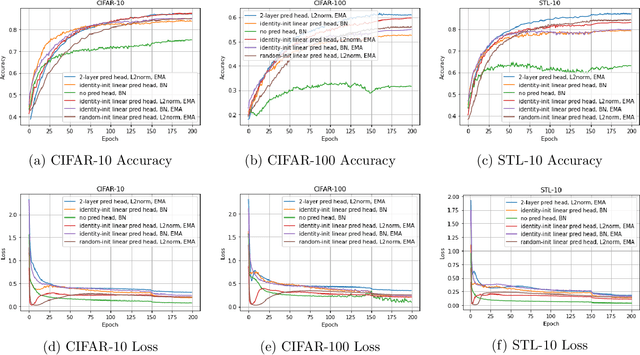
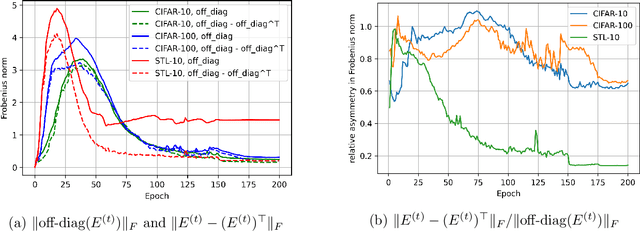
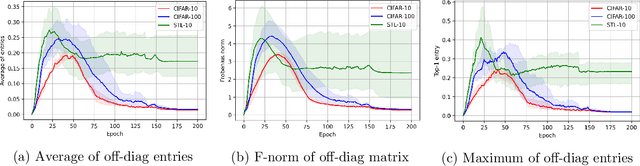
Recently the surprising discovery of the Bootstrap Your Own Latent (BYOL) method by Grill et al. shows the negative term in contrastive loss can be removed if we add the so-called prediction head to the network. This initiated the research of non-contrastive self-supervised learning. It is mysterious why even when there exist trivial collapsed global optimal solutions, neural networks trained by (stochastic) gradient descent can still learn competitive representations. This phenomenon is a typical example of implicit bias in deep learning and remains little understood. In this work, we present our empirical and theoretical discoveries on non-contrastive self-supervised learning. Empirically, we find that when the prediction head is initialized as an identity matrix with only its off-diagonal entries being trainable, the network can learn competitive representations even though the trivial optima still exist in the training objective. Theoretically, we present a framework to understand the behavior of the trainable, but identity-initialized prediction head. Under a simple setting, we characterized the substitution effect and acceleration effect of the prediction head. The substitution effect happens when learning the stronger features in some neurons can substitute for learning these features in other neurons through updating the prediction head. And the acceleration effect happens when the substituted features can accelerate the learning of other weaker features to prevent them from being ignored. These two effects enable the neural networks to learn all the features rather than focus only on learning the stronger features, which is likely the cause of the dimensional collapse phenomenon. To the best of our knowledge, this is also the first end-to-end optimization guarantee for non-contrastive methods using nonlinear neural networks with a trainable prediction head and normalization.
Complete Policy Regret Bounds for Tallying Bandits
Apr 24, 2022Policy regret is a well established notion of measuring the performance of an online learning algorithm against an adaptive adversary. We study restrictions on the adversary that enable efficient minimization of the \emph{complete policy regret}, which is the strongest possible version of policy regret. We identify a gap in the current theoretical understanding of what sorts of restrictions permit tractability in this challenging setting. To resolve this gap, we consider a generalization of the stochastic multi armed bandit, which we call the \emph{tallying bandit}. This is an online learning setting with an $m$-memory bounded adversary, where the average loss for playing an action is an unknown function of the number (or tally) of times that the action was played in the last $m$ timesteps. For tallying bandit problems with $K$ actions and time horizon $T$, we provide an algorithm that w.h.p achieves a complete policy regret guarantee of $\tilde{\mathcal{O}}(mK\sqrt{T})$, where the $\tilde{\mathcal{O}}$ notation hides only logarithmic factors. We additionally prove an $\tilde\Omega(\sqrt{m K T})$ lower bound on the expected complete policy regret of any tallying bandit algorithm, demonstrating the near optimality of our method.
Learning Polynomial Transformations
Apr 08, 2022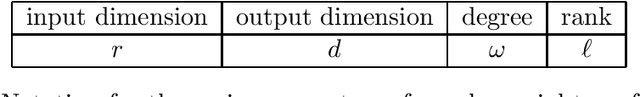
We consider the problem of learning high dimensional polynomial transformations of Gaussians. Given samples of the form $p(x)$, where $x\sim N(0, \mathrm{Id}_r)$ is hidden and $p: \mathbb{R}^r \to \mathbb{R}^d$ is a function where every output coordinate is a low-degree polynomial, the goal is to learn the distribution over $p(x)$. This problem is natural in its own right, but is also an important special case of learning deep generative models, namely pushforwards of Gaussians under two-layer neural networks with polynomial activations. Understanding the learnability of such generative models is crucial to understanding why they perform so well in practice. Our first main result is a polynomial-time algorithm for learning quadratic transformations of Gaussians in a smoothed setting. Our second main result is a polynomial-time algorithm for learning constant-degree polynomial transformations of Gaussian in a smoothed setting, when the rank of the associated tensors is small. In fact our results extend to any rotation-invariant input distribution, not just Gaussian. These are the first end-to-end guarantees for learning a pushforward under a neural network with more than one layer. Along the way, we also give the first polynomial-time algorithms with provable guarantees for tensor ring decomposition, a popular generalization of tensor decomposition that is used in practice to implicitly store large tensors.
Minimax Optimality (Probably) Doesn't Imply Distribution Learning for GANs
Jan 18, 2022
Arguably the most fundamental question in the theory of generative adversarial networks (GANs) is to understand to what extent GANs can actually learn the underlying distribution. Theoretical and empirical evidence suggests local optimality of the empirical training objective is insufficient. Yet, it does not rule out the possibility that achieving a true population minimax optimal solution might imply distribution learning. In this paper, we show that standard cryptographic assumptions imply that this stronger condition is still insufficient. Namely, we show that if local pseudorandom generators (PRGs) exist, then for a large family of natural continuous target distributions, there are ReLU network generators of constant depth and polynomial size which take Gaussian random seeds so that (i) the output is far in Wasserstein distance from the target distribution, but (ii) no polynomially large Lipschitz discriminator ReLU network can detect this. This implies that even achieving a population minimax optimal solution to the Wasserstein GAN objective is likely insufficient for distribution learning in the usual statistical sense. Our techniques reveal a deep connection between GANs and PRGs, which we believe will lead to further insights into the computational landscape of GANs.
Settling the Horizon-Dependence of Sample Complexity in Reinforcement Learning
Nov 01, 2021Recently there is a surge of interest in understanding the horizon-dependence of the sample complexity in reinforcement learning (RL). Notably, for an RL environment with horizon length $H$, previous work have shown that there is a probably approximately correct (PAC) algorithm that learns an $O(1)$-optimal policy using $\mathrm{polylog}(H)$ episodes of environment interactions when the number of states and actions is fixed. It is yet unknown whether the $\mathrm{polylog}(H)$ dependence is necessary or not. In this work, we resolve this question by developing an algorithm that achieves the same PAC guarantee while using only $O(1)$ episodes of environment interactions, completely settling the horizon-dependence of the sample complexity in RL. We achieve this bound by (i) establishing a connection between value functions in discounted and finite-horizon Markov decision processes (MDPs) and (ii) a novel perturbation analysis in MDPs. We believe our new techniques are of independent interest and could be applied in related questions in RL.