 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Generalization by Learning and Removing Domain-specific Features
Dec 14, 2022



Deep Neural Networks (DNNs) suffer from domain shift when the test dataset follows a distribution different from the training dataset. Domain generalization aims to tackle this issue by learning a model that can generalize to unseen domains. In this paper, we propose a new approach that aims to explicitly remove domain-specific features for domain generalization. Following this approach, we propose a novel framework called Learning and Removing Domain-specific features for Generalization (LRDG) that learns a domain-invariant model by tactically removing domain-specific features from the input images. Specifically, we design a classifier to effectively learn the domain-specific features for each source domain, respectively. We then develop an encoder-decoder network to map each input image into a new image space where the learned domain-specific features are removed. With the images output by the encoder-decoder network, another classifier is designed to learn the domain-invariant features to conduct image classification. Extensive experiments demonstrate that our framework achieves superior performance compared with state-of-the-art methods.
FlowFace: Semantic Flow-guided Shape-aware Face Swapping
Dec 06, 2022In this work, we propose a semantic flow-guided two-stage framework for shape-aware face swapping, namely FlowFace. Unlike most previous methods that focus on transferring the source inner facial features but neglect facial contours, our FlowFace can transfer both of them to a target face, thus leading to more realistic face swapping. Concretely, our FlowFace consists of a face reshaping network and a face swapping network. The face reshaping network addresses the shape outline differences between the source and target faces. It first estimates a semantic flow (i.e., face shape differences) between the source and the target face, and then explicitly warps the target face shape with the estimated semantic flow. After reshaping, the face swapping network generates inner facial features that exhibit the identity of the source face. We employ a pre-trained face masked autoencoder (MAE) to extract facial features from both the source face and the target face. In contrast to previous methods that use identity embedding to preserve identity information, the features extracted by our encoder can better capture facial appearances and identity information. Then, we develop a cross-attention fusion module to adaptively fuse inner facial features from the source face with the target facial attributes, thus leading to better identity preservation. Extensive quantitative and qualitative experiments on in-the-wild faces demonstrate that our FlowFace outperforms the state-of-the-art significantly.
Facial Action Unit Detection and Intensity Estimation from Self-supervised Representation
Oct 28, 2022



As a fine-grained and local expression behavior measurement, facial action unit (FAU) analysis (e.g., detection and intensity estimation) has been documented for its time-consuming, labor-intensive, and error-prone annotation. Thus a long-standing challenge of FAU analysis arises from the data scarcity of manual annotations, limiting the generalization ability of trained models to a large extent. Amounts of previous works have made efforts to alleviate this issue via semi/weakly supervised methods and extra auxiliary information. However, these methods still require domain knowledge and have not yet avoided the high dependency on data annotation. This paper introduces a robust facial representation model MAE-Face for AU analysis. Using masked autoencoding as the self-supervised pre-training approach, MAE-Face first learns a high-capacity model from a feasible collection of face images without additional data annotations. Then after being fine-tuned on AU datasets, MAE-Face exhibits convincing performance for both AU detection and AU intensity estimation, achieving a new state-of-the-art on nearly all the evaluation results. Further investigation shows that MAE-Face achieves decent performance even when fine-tuned on only 1\% of the AU training set, strongly proving its robustness and generalization performance.
Global-to-local Expression-aware Embeddings for Facial Action Unit Detection
Oct 28, 2022



Expressions and facial action units (AUs) are two levels of facial behavior descriptors. Expression auxiliary information has been widely used to improve the AU detection performance. However, most existing expression representations can only describe pre-determined discrete categories (e.g., Angry, Disgust, Happy, Sad, etc.) and cannot capture subtle expression transformations like AUs. In this paper, we propose a novel fine-grained \textsl{Global Expression representation Encoder} to capture subtle and continuous facial movements, to promote AU detection. To obtain such a global expression representation, we propose to train an expression embedding model on a large-scale expression dataset according to global expression similarity. Moreover, considering the local definition of AUs, it is essential to extract local AU features. Therefore, we design a \textsl{Local AU Features Module} to generate local facial features for each AU. Specifically, it consists of an AU feature map extractor and a corresponding AU mask extractor. First, the two extractors transform the global expression representation into AU feature maps and masks, respectively. Then, AU feature maps and their corresponding AU masks are multiplied to generate AU masked features focusing on local facial region. Finally, the AU masked features are fed into an AU classifier for judging the AU occurrence. Extensive experiment results demonstrate the superiority of our proposed method. Our method validly outperforms previous works and achieves state-of-the-art performances on widely-used face datasets, including BP4D, DISFA, and BP4D+.
Facial Action Units Detection Aided by Global-Local Expression Embedding
Oct 25, 2022Since Facial Action Unit (AU) annotations require domain expertise, common AU datasets only contain a limited number of subjects. As a result, a crucial challenge for AU detection is addressing identity overfitting. We find that AUs and facial expressions are highly associated, and existing facial expression datasets often contain a large number of identities. In this paper, we aim to utilize the expression datasets without AU labels to facilitate AU detection. Specifically, we develop a novel AU detection framework aided by the Global-Local facial Expressions Embedding, dubbed GLEE-Net. Our GLEE-Net consists of three branches to extract identity-independent expression features for AU detection. We introduce a global branch for modeling the overall facial expression while eliminating the impacts of identities. We also design a local branch focusing on specific local face regions. The combined output of global and local branches is firstly pre-trained on an expression dataset as an identity-independent expression embedding, and then finetuned on AU datasets. Therefore, we significantly alleviate the issue of limited identities. Furthermore, we introduce a 3D global branch that extracts expression coefficients through 3D face reconstruction to consolidate 2D AU descriptions. Finally, a Transformer-based multi-label classifier is employed to fuse all the representations for AU detection. Extensive experiments demonstrate that our method significantly outperforms the state-of-the-art on the widely-used DISFA, BP4D and BP4D+ datasets.
Transformer-based Multimodal Information Fusion for Facial Expression Analysis
Mar 23, 2022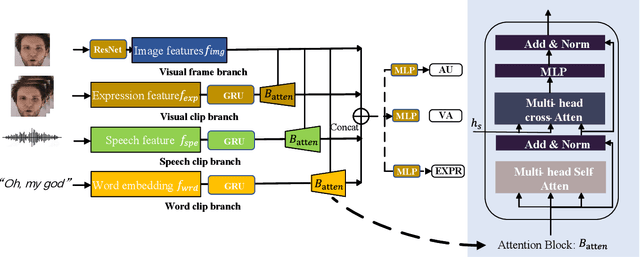
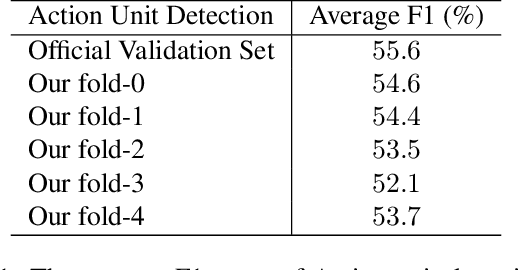
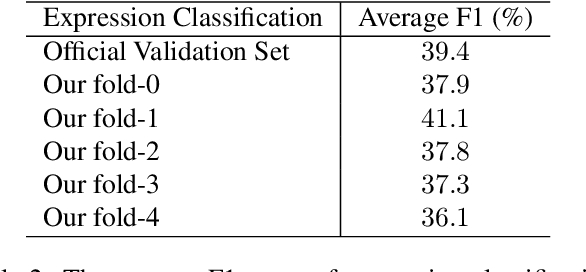
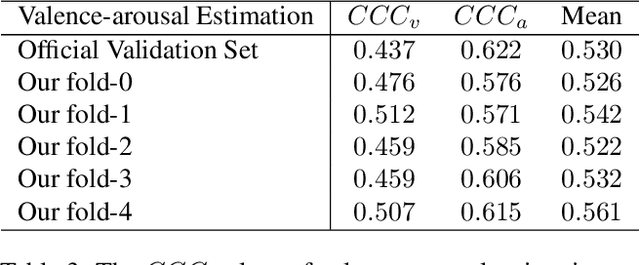
Facial expression analysis has been a crucial research problem in the computer vision area. With the recent development of deep learning techniques and large-scale in-the-wild annotated datasets, facial expression analysis is now aimed at challenges in real world settings. In this paper, we introduce our submission to CVPR2022 Competition on Affective Behavior Analysis in-the-wild (ABAW) that defines four competition tasks, including expression classification, action unit detection, valence-arousal estimation, and a multi-task-learning. The available multimodal information consist of spoken words, speech prosody, and visual expression in videos. Our work proposes four unified transformer-based network frameworks to create the fusion of the above multimodal information. The preliminary results on the official Aff-Wild2 dataset are reported and demonstrate the effectiveness of our proposed method.
TAKDE: Temporal Adaptive Kernel Density Estimator for Real-Time Dynamic Density Estimation
Mar 15, 2022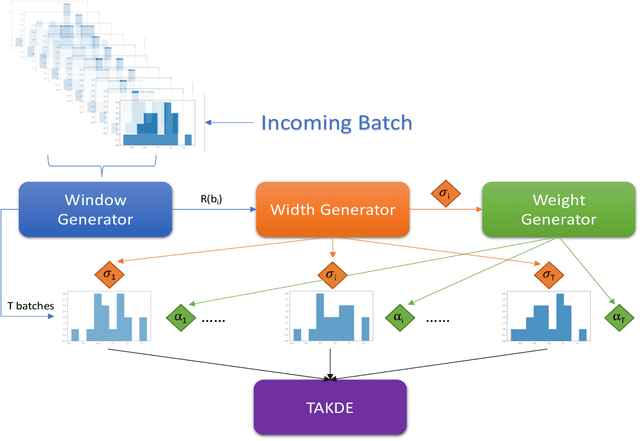
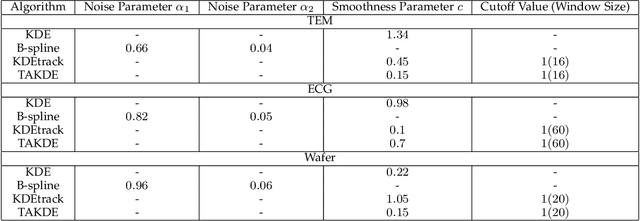
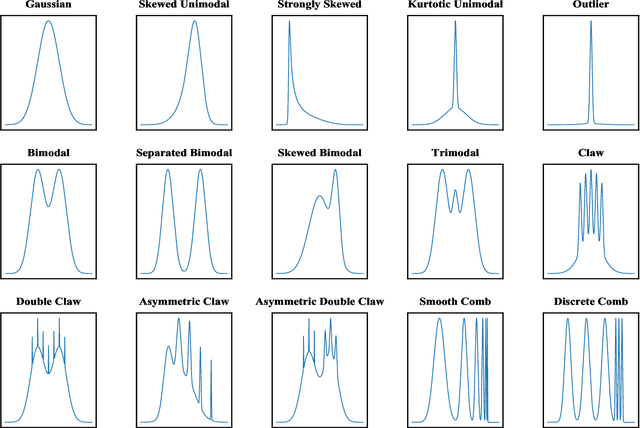
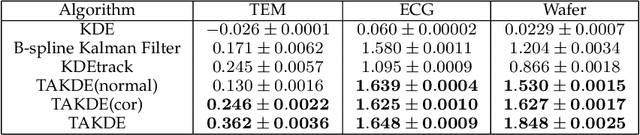
Real-time density estimation is ubiquitous in many applications, including computer vision and signal processing. Kernel density estimation is arguably one of the most commonly used density estimation techniques, and the use of "sliding window" mechanism adapts kernel density estimators to dynamic processes. In this paper, we derive the asymptotic mean integrated squared error (AMISE) upper bound for the "sliding window" kernel density estimator. This upper bound provides a principled guide to devise a novel estimator, which we name the temporal adaptive kernel density estimator (TAKDE). Compared to heuristic approaches for "sliding window" kernel density estimator, TAKDE is theoretically optimal in terms of the worst-case AMISE. We provide numerical experiments using synthetic and real-world datasets, showing that TAKDE outperforms other state-of-the-art dynamic density estimators (including those outside of kernel family). In particular, TAKDE achieves a superior test log-likelihood with a smaller runtime.
One-shot Talking Face Generation from Single-speaker Audio-Visual Correlation Learning
Dec 06, 2021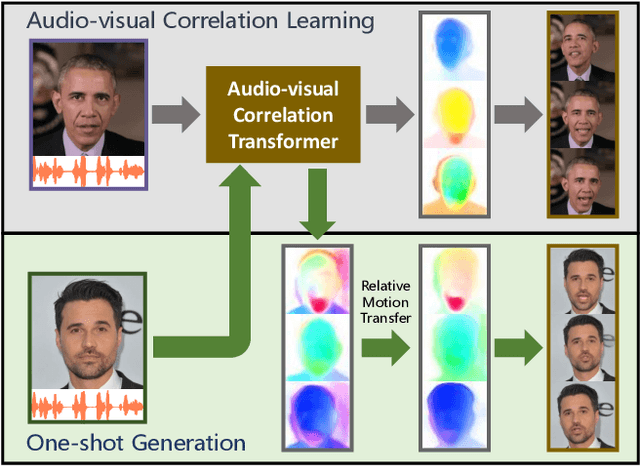
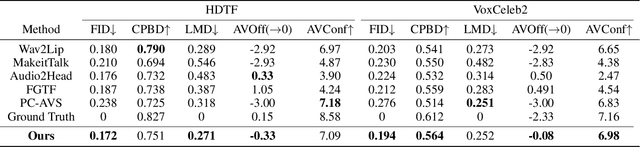
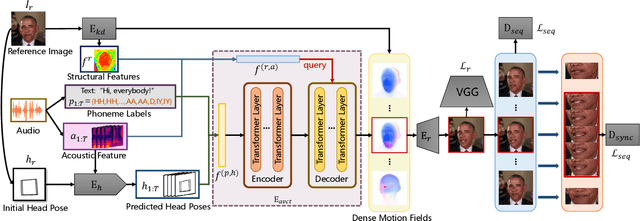
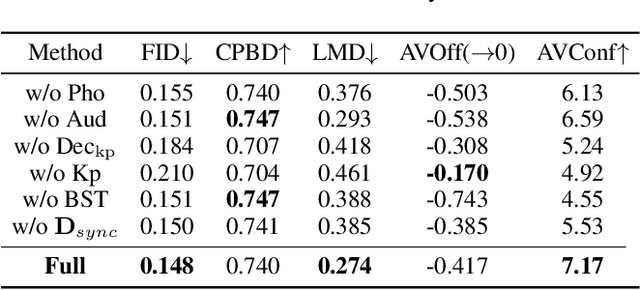
Audio-driven one-shot talking face generation methods are usually trained on video resources of various persons. However, their created videos often suffer unnatural mouth shapes and asynchronous lips because those methods struggle to learn a consistent speech style from different speakers. We observe that it would be much easier to learn a consistent speech style from a specific speaker, which leads to authentic mouth movements. Hence, we propose a novel one-shot talking face generation framework by exploring consistent correlations between audio and visual motions from a specific speaker and then transferring audio-driven motion fields to a reference image. Specifically, we develop an Audio-Visual Correlation Transformer (AVCT) that aims to infer talking motions represented by keypoint based dense motion fields from an input audio. In particular, considering audio may come from different identities in deployment, we incorporate phonemes to represent audio signals. In this manner, our AVCT can inherently generalize to audio spoken by other identities. Moreover, as face keypoints are used to represent speakers, AVCT is agnostic against appearances of the training speaker, and thus allows us to manipulate face images of different identities readily. Considering different face shapes lead to different motions, a motion field transfer module is exploited to reduce the audio-driven dense motion field gap between the training identity and the one-shot reference. Once we obtained the dense motion field of the reference image, we employ an image renderer to generate its talking face videos from an audio clip. Thanks to our learned consistent speaking style, our method generates authentic mouth shapes and vivid movements. Extensive experiments demonstrate that our synthesized videos outperform the state-of-the-art in terms of visual quality and lip-sync.
* Accepted by AAAI 2022
Towards Futuristic Autonomous Experimentation--A Surprise-Reacting Sequential Experiment Policy
Dec 01, 2021



An autonomous experimentation platform in manufacturing is supposedly capable of conducting a sequential search for finding suitable manufacturing conditions for advanced materials by itself or even for discovering new materials with minimal human intervention. The core of the intelligent control of such platforms is the policy directing sequential experiments, namely, to decide where to conduct the next experiment based on what has been done thus far. Such policy inevitably trades off exploitation versus exploration and the current practice is under the Bayesian optimization framework using the expected improvement criterion or its variants. We discuss whether it is beneficial to trade off exploitation versus exploration by measuring the element and degree of surprise associated with the immediate past observation. We devise a surprise-reacting policy using two existing surprise metrics, known as the Shannon surprise and Bayesian surprise. Our analysis shows that the surprise-reacting policy appears to be better suited for quickly characterizing the overall landscape of a response surface or a design place under resource constraints. We argue that such capability is much needed for futuristic autonomous experimentation platforms. We do not claim that we have a fully autonomous experimentation platform, but believe that our current effort sheds new lights or provides a different view angle as researchers are racing to elevate the autonomy of various primitive autonomous experimentation systems.
Audio2Head: Audio-driven One-shot Talking-head Generation with Natural Head Motion
Jul 20, 2021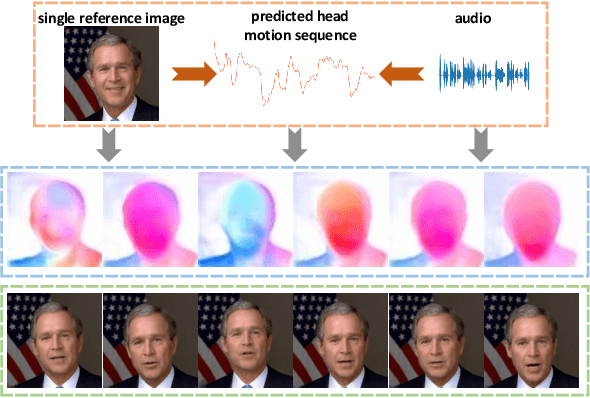
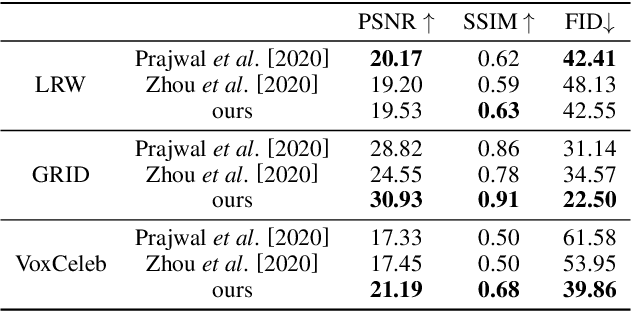
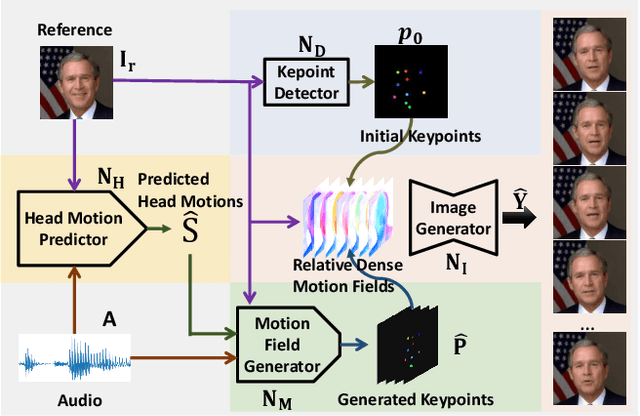

We propose an audio-driven talking-head method to generate photo-realistic talking-head videos from a single reference image. In this work, we tackle two key challenges: (i) producing natural head motions that match speech prosody, and (ii) maintaining the appearance of a speaker in a large head motion while stabilizing the non-face regions. We first design a head pose predictor by modeling rigid 6D head movements with a motion-aware recurrent neural network (RNN). In this way, the predicted head poses act as the low-frequency holistic movements of a talking head, thus allowing our latter network to focus on detailed facial movement generation. To depict the entire image motions arising from audio, we exploit a keypoint based dense motion field representation. Then, we develop a motion field generator to produce the dense motion fields from input audio, head poses, and a reference image. As this keypoint based representation models the motions of facial regions, head, and backgrounds integrally, our method can better constrain the spatial and temporal consistency of the generated videos. Finally, an image generation network is employed to render photo-realistic talking-head videos from the estimated keypoint based motion fields and the input reference image. Extensive experiments demonstrate that our method produces videos with plausible head motions, synchronized facial expressions, and stable backgrounds and outperforms the state-of-the-art.