 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Multiscale Recurrent Neural Networks
Mar 09, 2017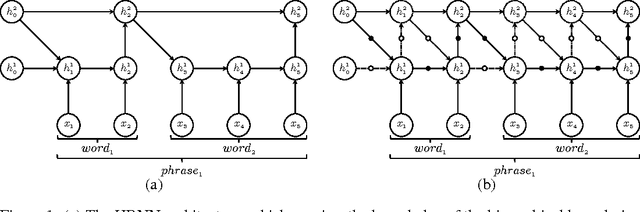
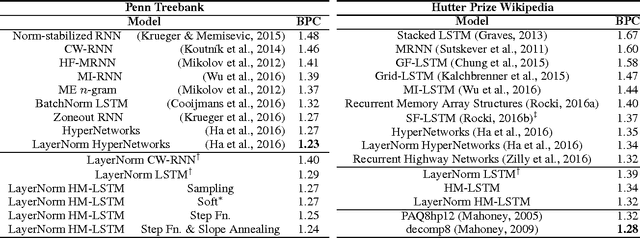


Learning both hierarchical and temporal representation has been among the long-standing challenges of recurrent neural networks. Multiscale recurrent neural networks have been considered as a promising approach to resolve this issue, yet there has been a lack of empirical evidence showing that this type of models can actually capture the temporal dependencies by discovering the latent hierarchical structure of the sequence. In this paper, we propose a novel multiscale approach, called the hierarchical multiscale recurrent neural networks, which can capture the latent hierarchical structure in the sequence by encoding the temporal dependencies with different timescales using a novel update mechanism. We show some evidence that our proposed multiscale architecture can discover underlying hierarchical structure in the sequences without using explicit boundary information. We evaluate our proposed model on character-level language modelling and handwriting sequence modelling.
A Structured Self-attentive Sentence Embedding
Mar 09, 2017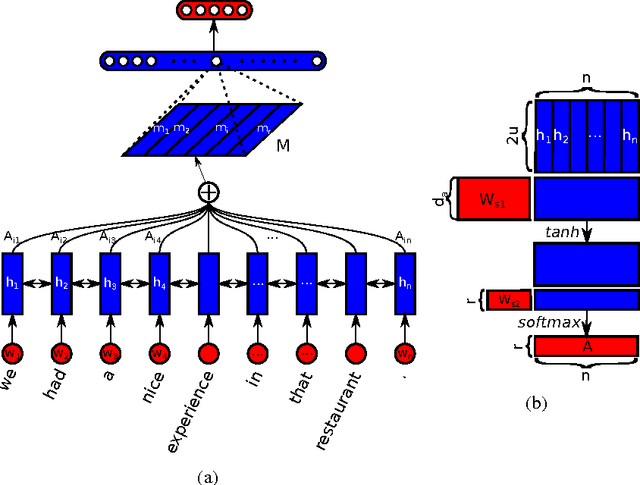

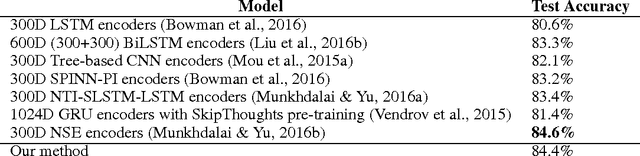

This paper proposes a new model for extracting an interpretable sentence embedding by introducing self-attention. Instead of using a vector, we use a 2-D matrix to represent the embedding, with each row of the matrix attending on a different part of the sentence. We also propose a self-attention mechanism and a special regularization term for the model. As a side effect, the embedding comes with an easy way of visualizing what specific parts of the sentence are encoded into the embedding. We evaluate our model on 3 different tasks: author profiling, sentiment classification, and textual entailment. Results show that our model yields a significant performance gain compared to other sentence embedding methods in all of the 3 tasks.
An Actor-Critic Algorithm for Sequence Prediction
Mar 03, 2017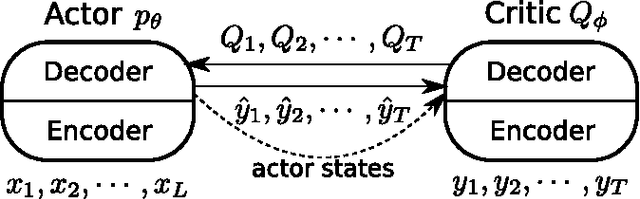
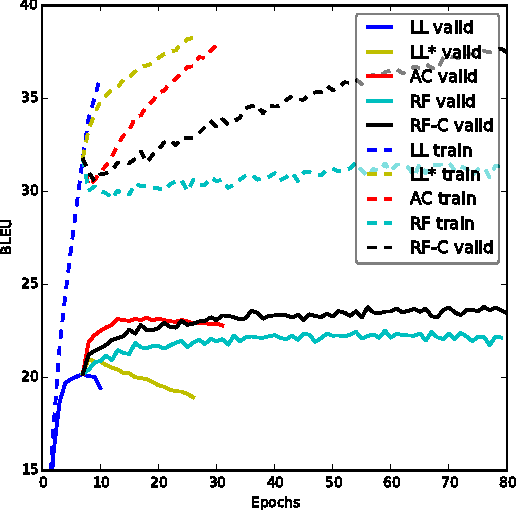
We present an approach to training neural networks to generate sequences using actor-critic methods from reinforcement learning (RL). Current log-likelihood training methods are limited by the discrepancy between their training and testing modes, as models must generate tokens conditioned on their previous guesses rather than the ground-truth tokens. We address this problem by introducing a \textit{critic} network that is trained to predict the value of an output token, given the policy of an \textit{actor} network. This results in a training procedure that is much closer to the test phase, and allows us to directly optimize for a task-specific score such as BLEU. Crucially, since we leverage these techniques in the supervised learning setting rather than the traditional RL setting, we condition the critic network on the ground-truth output. We show that our method leads to improved performance on both a synthetic task, and for German-English machine translation. Our analysis paves the way for such methods to be applied in natural language generation tasks, such as machine translation, caption generation, and dialogue modelling.
A Neural Knowledge Language Model
Mar 02, 2017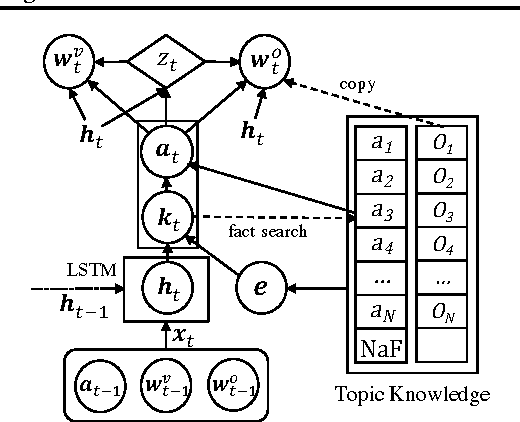
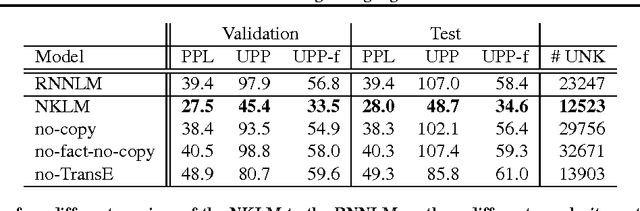
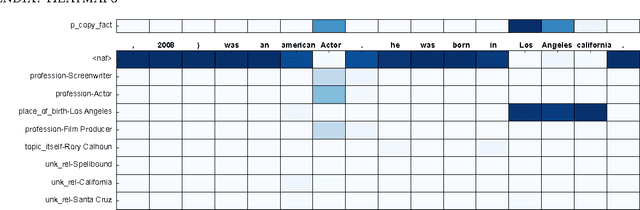
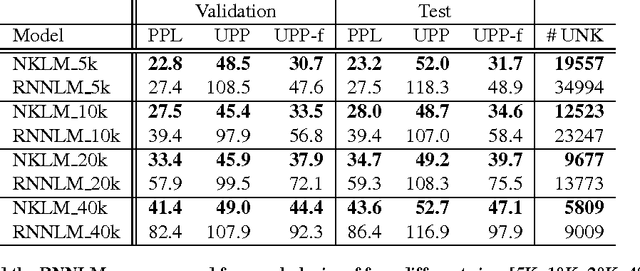
Current language models have a significant limitation in the ability to encode and decode factual knowledge. This is mainly because they acquire such knowledge from statistical co-occurrences although most of the knowledge words are rarely observed. In this paper, we propose a Neural Knowledge Language Model (NKLM) which combines symbolic knowledge provided by the knowledge graph with the RNN language model. By predicting whether the word to generate has an underlying fact or not, the model can generate such knowledge-related words by copying from the description of the predicted fact. In experiments, we show that the NKLM significantly improves the performance while generating a much smaller number of unknown words.
A Robust Adaptive Stochastic Gradient Method for Deep Learning
Mar 02, 2017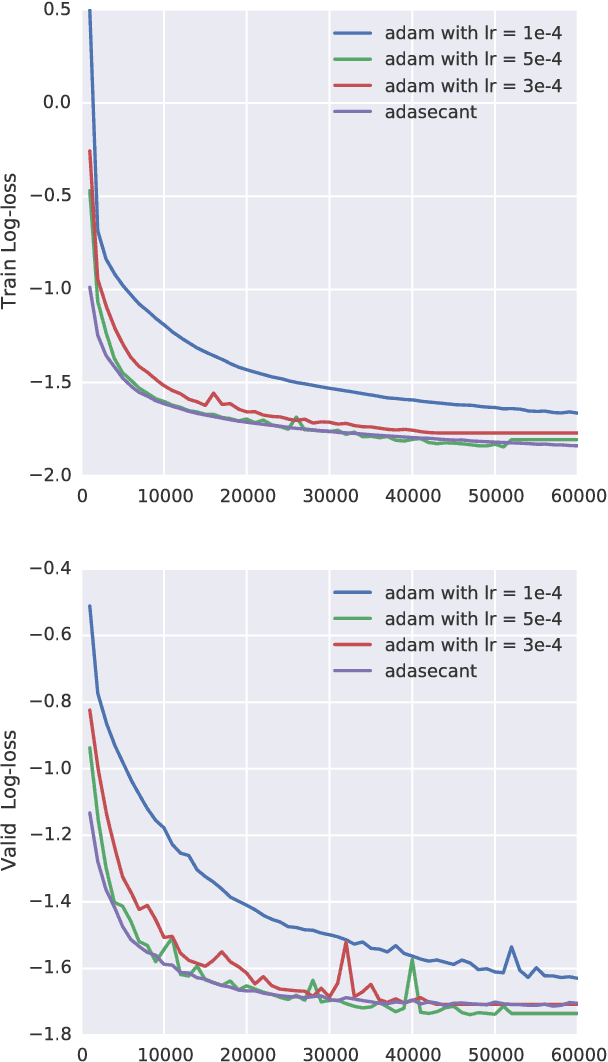
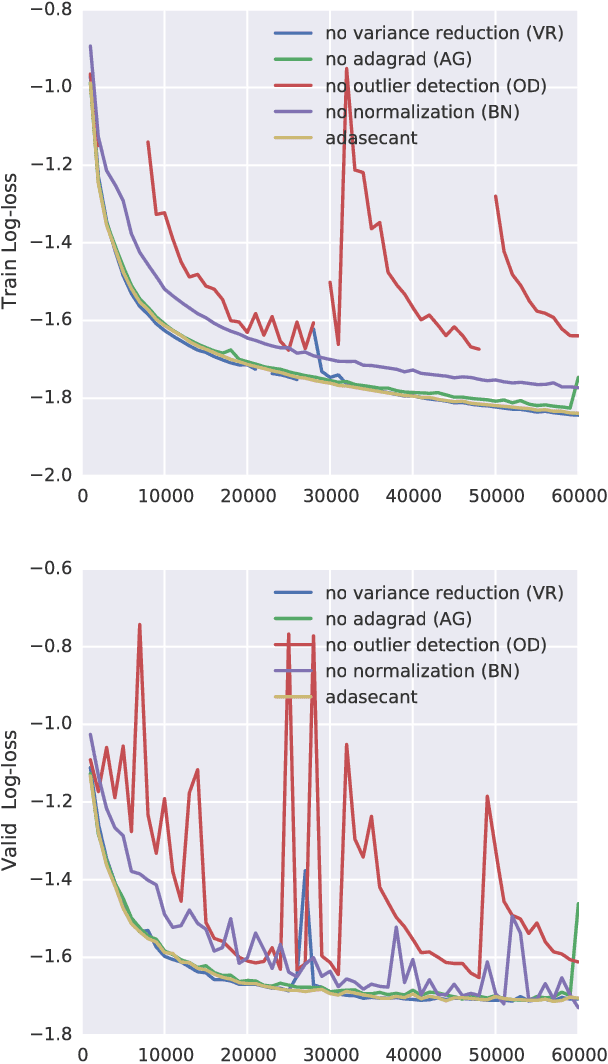
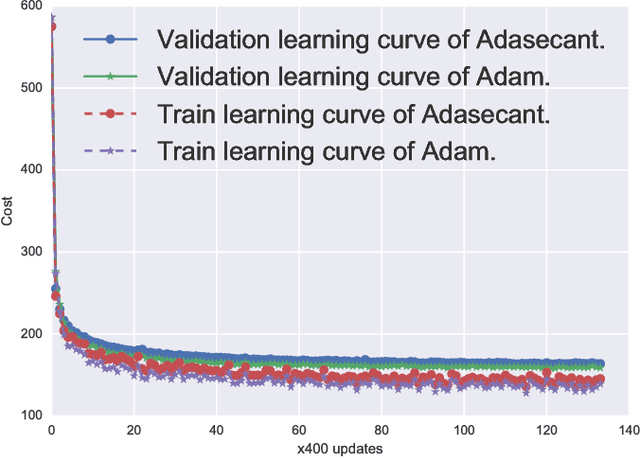
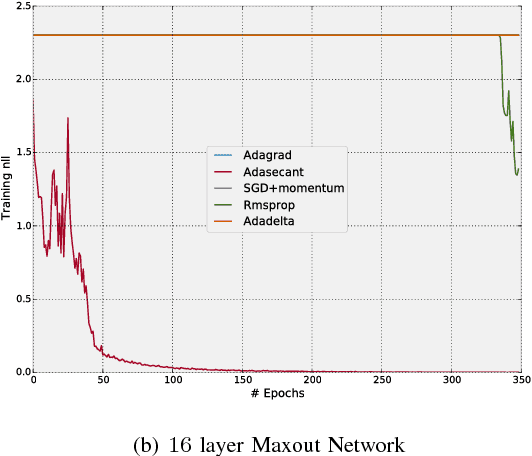
Stochastic gradient algorithms are the main focus of large-scale optimization problems and led to important successes in the recent advancement of the deep learning algorithms. The convergence of SGD depends on the careful choice of learning rate and the amount of the noise in stochastic estimates of the gradients. In this paper, we propose an adaptive learning rate algorithm, which utilizes stochastic curvature information of the loss function for automatically tuning the learning rates. The information about the element-wise curvature of the loss function is estimated from the local statistics of the stochastic first order gradients. We further propose a new variance reduction technique to speed up the convergence. In our experiments with deep neural networks, we obtained better performance compared to the popular stochastic gradient algorithms.
Mode Regularized Generative Adversarial Networks
Mar 02, 2017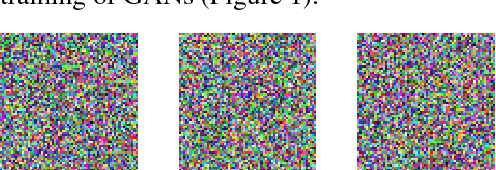
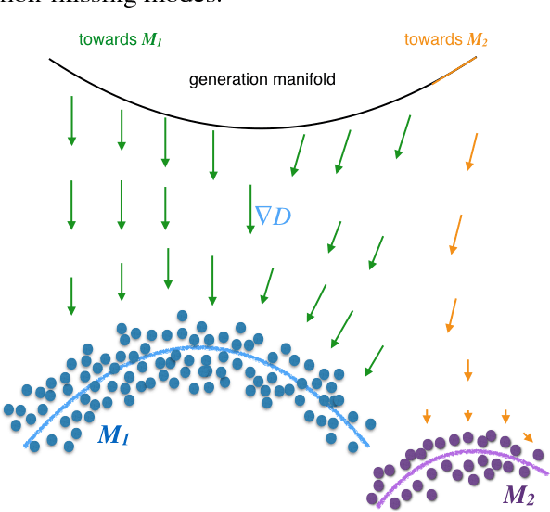
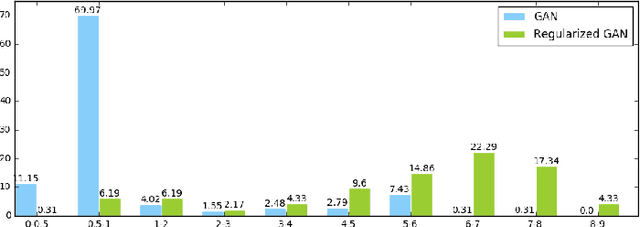

Although Generative Adversarial Networks achieve state-of-the-art results on a variety of generative tasks, they are regarded as highly unstable and prone to miss modes. We argue that these bad behaviors of GANs are due to the very particular functional shape of the trained discriminators in high dimensional spaces, which can easily make training stuck or push probability mass in the wrong direction, towards that of higher concentration than that of the data generating distribution. We introduce several ways of regularizing the objective, which can dramatically stabilize the training of GAN models. We also show that our regularizers can help the fair distribution of probability mass across the modes of the data generating distribution, during the early phases of training and thus providing a unified solution to the missing modes problem.
Recurrent Neural Networks With Limited Numerical Precision
Feb 26, 2017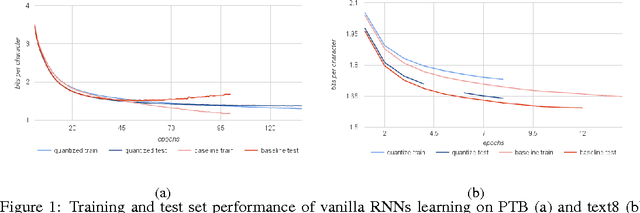

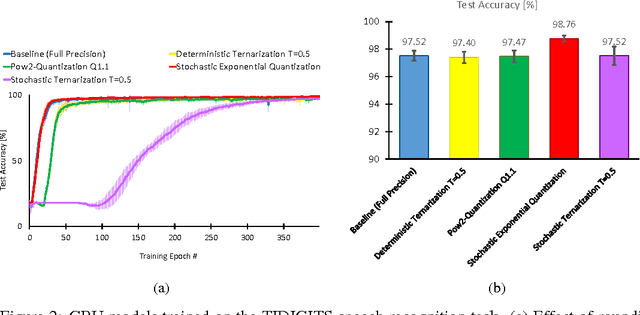
Recurrent Neural Networks (RNNs) produce state-of-art performance on many machine learning tasks but their demand on resources in terms of memory and computational power are often high. Therefore, there is a great interest in optimizing the computations performed with these models especially when considering development of specialized low-power hardware for deep networks. One way of reducing the computational needs is to limit the numerical precision of the network weights and biases, and this will be addressed for the case of RNNs. We present results from the use of different stochastic and deterministic reduced precision training methods applied to two major RNN types, which are then tested on three datasets. The results show that the stochastic and deterministic ternarization, pow2- ternarization, and exponential quantization methods gave rise to low-precision RNNs that produce similar and even higher accuracy on certain datasets, therefore providing a path towards training more efficient implementations of RNNs in specialized hardware.
Maximum-Likelihood Augmented Discrete Generative Adversarial Networks
Feb 26, 2017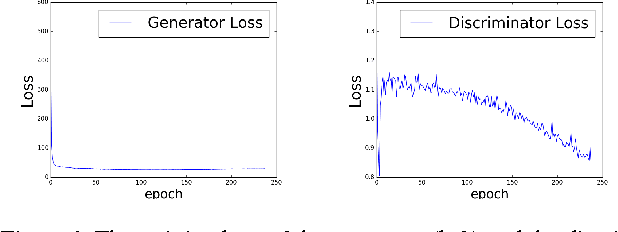


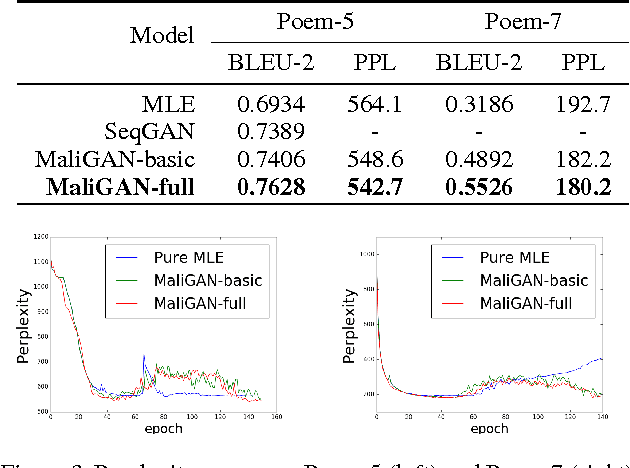
Despite the successes in capturing continuous distributions, the application of generative adversarial networks (GANs) to discrete settings, like natural language tasks, is rather restricted. The fundamental reason is the difficulty of back-propagation through discrete random variables combined with the inherent instability of the GAN training objective. To address these problems, we propose Maximum-Likelihood Augmented Discrete Generative Adversarial Networks. Instead of directly optimizing the GAN objective, we derive a novel and low-variance objective using the discriminator's output that follows corresponds to the log-likelihood. Compared with the original, the new objective is proved to be consistent in theory and beneficial in practice. The experimental results on various discrete datasets demonstrate the effectiveness of the proposed approach.
Learning Normalized Inputs for Iterative Estimation in Medical Image Segmentation
Feb 16, 2017
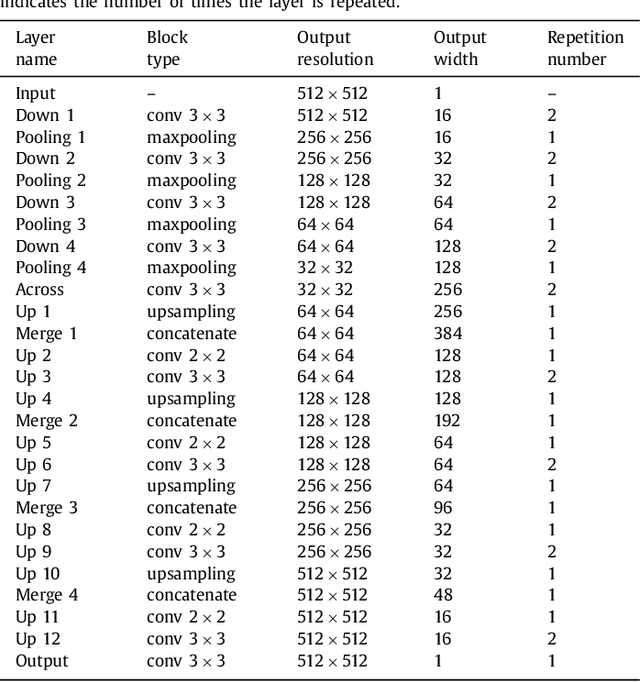
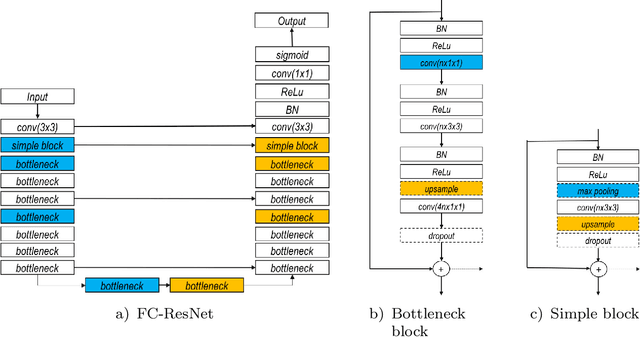
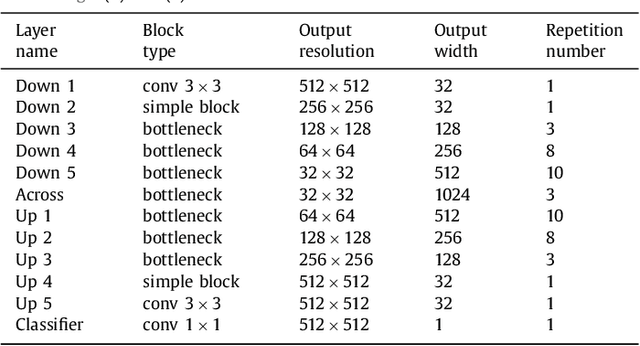
In this paper, we introduce a simple, yet powerful pipeline for medical image segmentation that combines Fully Convolutional Networks (FCNs) with Fully Convolutional Residual Networks (FC-ResNets). We propose and examine a design that takes particular advantage of recent advances in the understanding of both Convolutional Neural Networks as well as ResNets. Our approach focuses upon the importance of a trainable pre-processing when using FC-ResNets and we show that a low-capacity FCN model can serve as a pre-processor to normalize medical input data. In our image segmentation pipeline, we use FCNs to obtain normalized images, which are then iteratively refined by means of a FC-ResNet to generate a segmentation prediction. As in other fully convolutional approaches, our pipeline can be used off-the-shelf on different image modalities. We show that using this pipeline, we exhibit state-of-the-art performance on the challenging Electron Microscopy benchmark, when compared to other 2D methods. We improve segmentation results on CT images of liver lesions, when contrasting with standard FCN methods. Moreover, when applying our 2D pipeline on a challenging 3D MRI prostate segmentation challenge we reach results that are competitive even when compared to 3D methods. The obtained results illustrate the strong potential and versatility of the pipeline by achieving highly accurate results on multi-modality images from different anatomical regions and organs.
SampleRNN: An Unconditional End-to-End Neural Audio Generation Model
Feb 11, 2017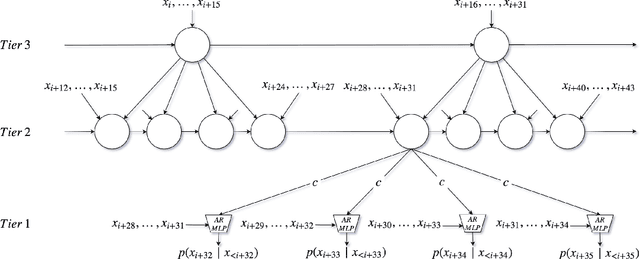

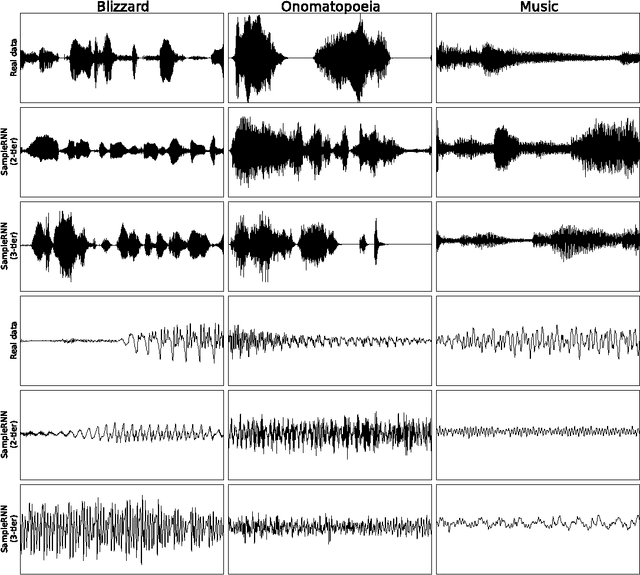
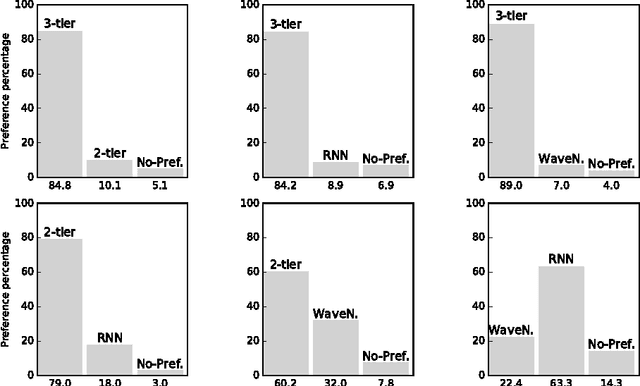
In this paper we propose a novel model for unconditional audio generation based on generating one audio sample at a time. We show that our model, which profits from combining memory-less modules, namely autoregressive multilayer perceptrons, and stateful recurrent neural networks in a hierarchical structure is able to capture underlying sources of variations in the temporal sequences over very long time spans, on three datasets of different nature. Human evaluation on the generated samples indicate that our model is preferred over competing models. We also show how each component of the model contributes to the exhibited performance.