 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight Gated Recurrent Units for Speech Recognition
Mar 26, 2018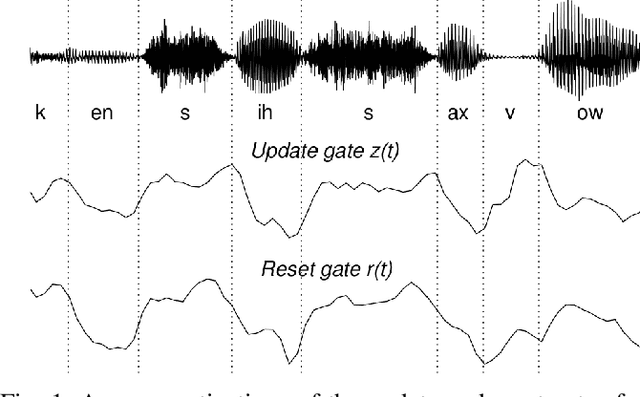
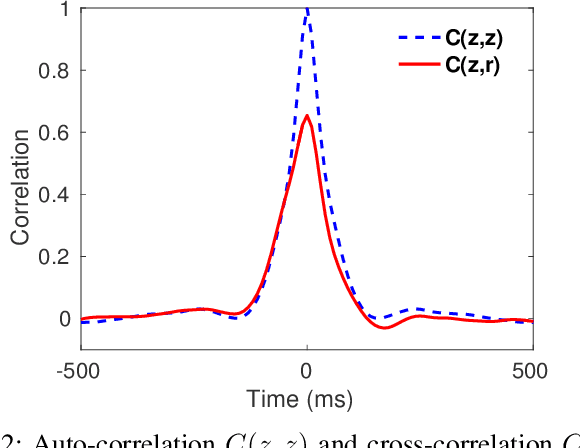
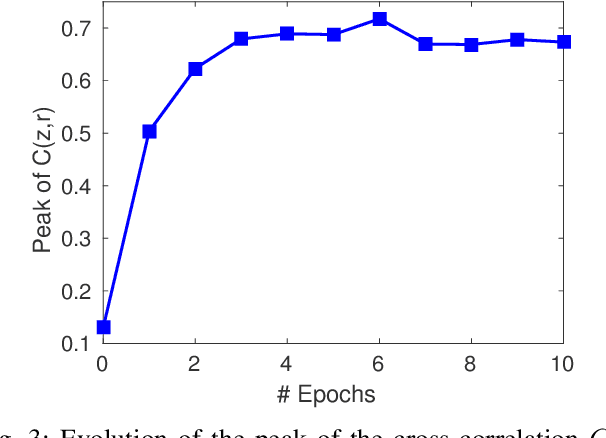
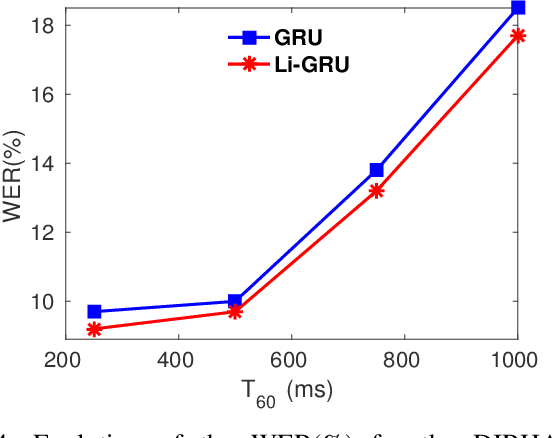
A field that has directly benefited from the recent advances in deep learning is Automatic Speech Recognition (ASR). Despite the great achievements of the past decades, however, a natural and robust human-machine speech interaction still appears to be out of reach, especially in challenging environments characterized by significant noise and reverberation. To improve robustness, modern speech recognizers often employ acoustic models based on Recurrent Neural Networks (RNNs), that are naturally able to exploit large time contexts and long-term speech modulations. It is thus of great interest to continue the study of proper techniques for improving the effectiveness of RNNs in processing speech signals. In this paper, we revise one of the most popular RNN models, namely Gated Recurrent Units (GRUs), and propose a simplified architecture that turned out to be very effective for ASR. The contribution of this work is two-fold: First, we analyze the role played by the reset gate, showing that a significant redundancy with the update gate occurs. As a result, we propose to remove the former from the GRU design, leading to a more efficient and compact single-gate model. Second, we propose to replace hyperbolic tangent with ReLU activations. This variation couples well with batch normalization and could help the model learn long-term dependencies without numerical issues. Results show that the proposed architecture, called Light GRU (Li-GRU), not only reduces the per-epoch training time by more than 30% over a standard GRU, but also consistently improves the recognition accuracy across different tasks, input features, noisy conditions, as well as across different ASR paradigms, ranging from standard DNN-HMM speech recognizers to end-to-end CTC models.
* Copyright 2018 IEEE
Residual Connections Encourage Iterative Inference
Mar 08, 2018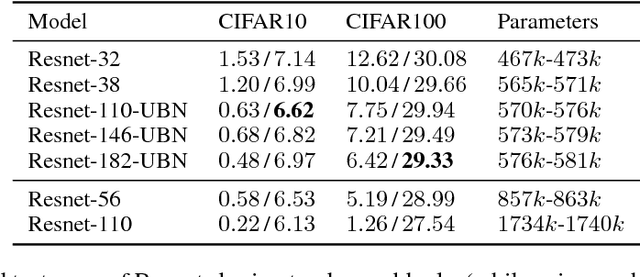



Residual networks (Resnets) have become a prominent architecture in deep learning. However, a comprehensive understanding of Resnets is still a topic of ongoing research. A recent view argues that Resnets perform iterative refinement of features. We attempt to further expose properties of this aspect. To this end, we study Resnets both analytically and empirically. We formalize the notion of iterative refinement in Resnets by showing that residual connections naturally encourage features of residual blocks to move along the negative gradient of loss as we go from one block to the next. In addition, our empirical analysis suggests that Resnets are able to perform both representation learning and iterative refinement. In general, a Resnet block tends to concentrate representation learning behavior in the first few layers while higher layers perform iterative refinement of features. Finally we observe that sharing residual layers naively leads to representation explosion and counterintuitively, overfitting, and we show that simple existing strategies can help alleviating this problem.
Learning to Compute Word Embeddings On the Fly
Mar 07, 2018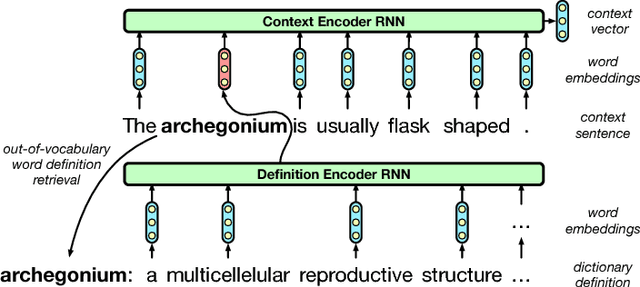
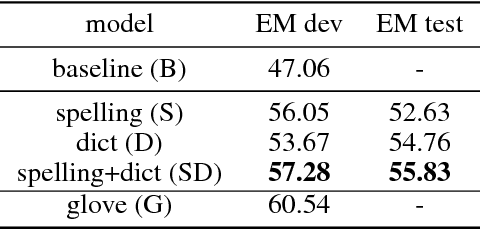
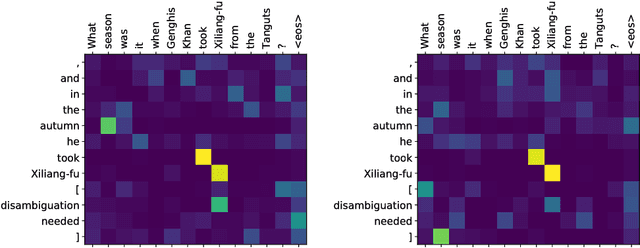
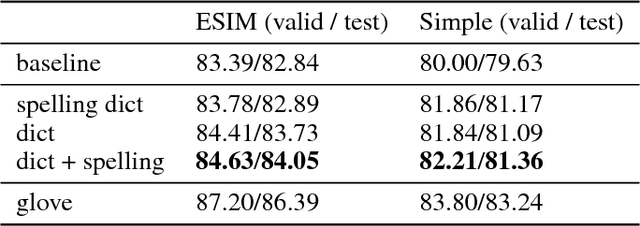
Words in natural language follow a Zipfian distribution whereby some words are frequent but most are rare. Learning representations for words in the "long tail" of this distribution requires enormous amounts of data. Representations of rare words trained directly on end tasks are usually poor, requiring us to pre-train embeddings on external data, or treat all rare words as out-of-vocabulary words with a unique representation. We provide a method for predicting embeddings of rare words on the fly from small amounts of auxiliary data with a network trained end-to-end for the downstream task. We show that this improves results against baselines where embeddings are trained on the end task for reading comprehension, recognizing textual entailment and language modeling.
Disentangling the independently controllable factors of variation by interacting with the world
Feb 26, 2018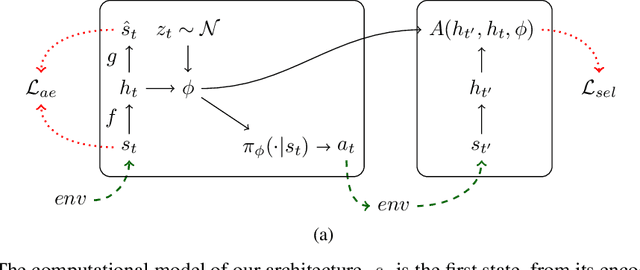
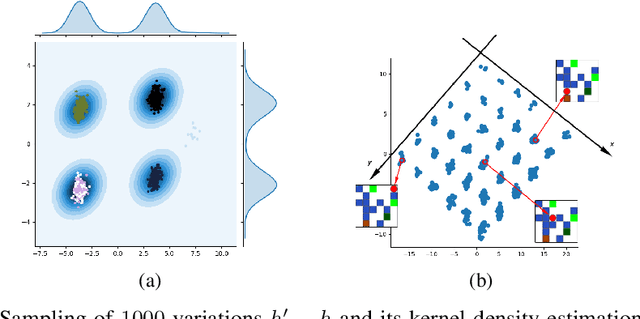
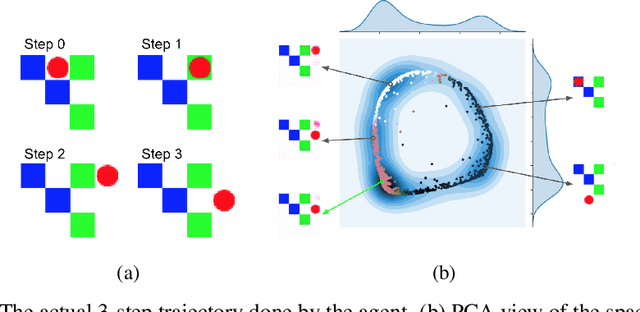
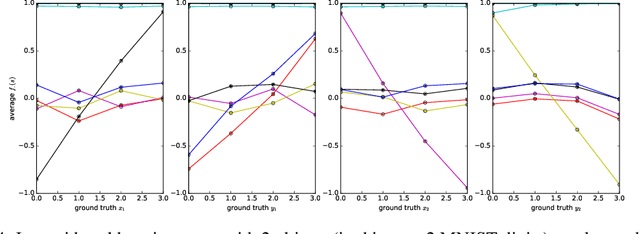
It has been postulated that a good representation is one that disentangles the underlying explanatory factors of variation. However, it remains an open question what kind of training framework could potentially achieve that. Whereas most previous work focuses on the static setting (e.g., with images), we postulate that some of the causal factors could be discovered if the learner is allowed to interact with its environment. The agent can experiment with different actions and observe their effects. More specifically, we hypothesize that some of these factors correspond to aspects of the environment which are independently controllable, i.e., that there exists a policy and a learnable feature for each such aspect of the environment, such that this policy can yield changes in that feature with minimal changes to other features that explain the statistical variations in the observed data. We propose a specific objective function to find such factors, and verify experimentally that it can indeed disentangle independently controllable aspects of the environment without any extrinsic reward signal.
Learning Anonymized Representations with Adversarial Neural Networks
Feb 26, 2018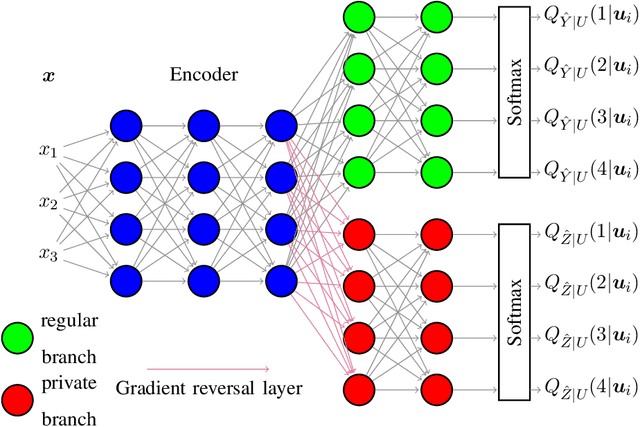

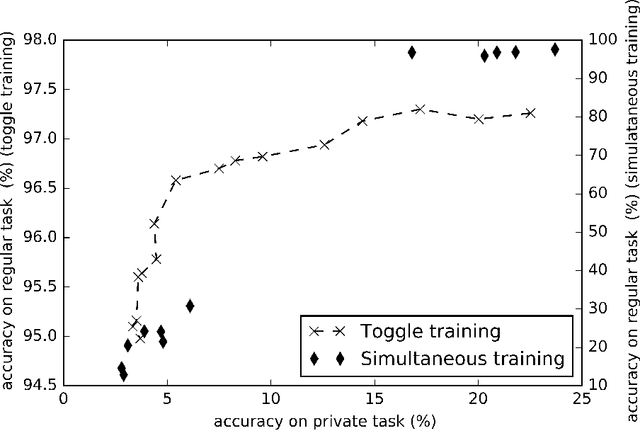
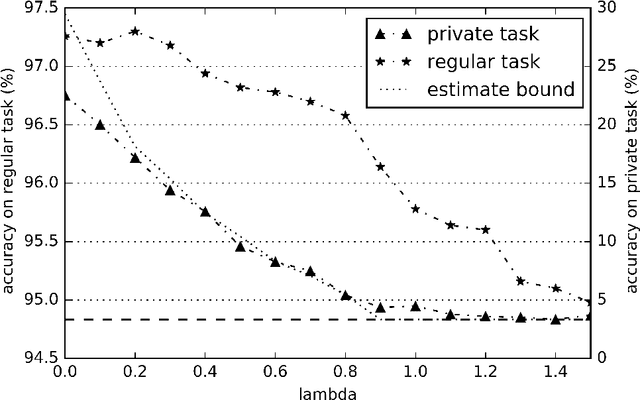
Statistical methods protecting sensitive information or the identity of the data owner have become critical to ensure privacy of individuals as well as of organizations. This paper investigates anonymization methods based on representation learning and deep neural networks, and motivated by novel information theoretical bounds. We introduce a novel training objective for simultaneously training a predictor over target variables of interest (the regular labels) while preventing an intermediate representation to be predictive of the private labels. The architecture is based on three sub-networks: one going from input to representation, one from representation to predicted regular labels, and one from representation to predicted private labels. The training procedure aims at learning representations that preserve the relevant part of the information (about regular labels) while dismissing information about the private labels which correspond to the identity of a person. We demonstrate the success of this approach for two distinct classification versus anonymization tasks (handwritten digits and sentiment analysis).
Deep Complex Networks
Feb 25, 2018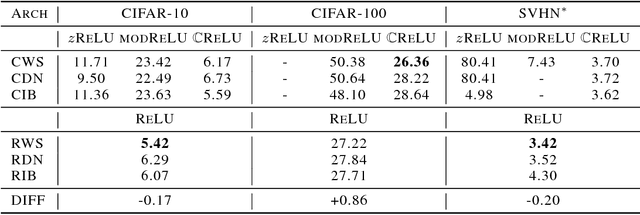
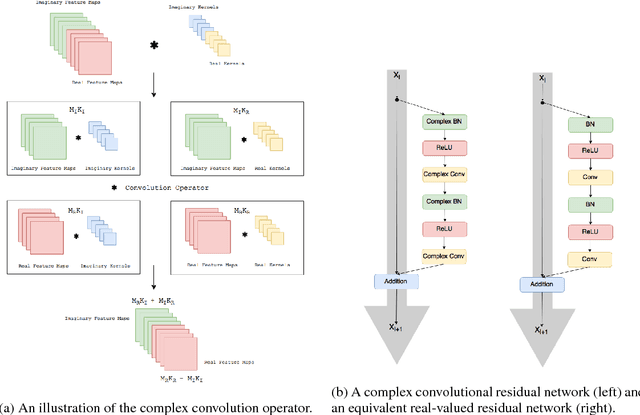

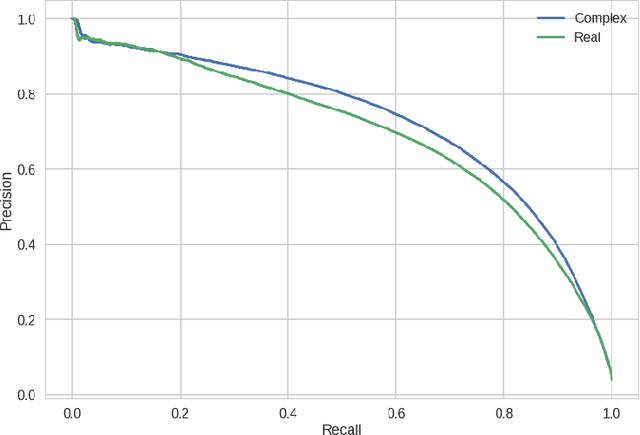
At present, the vast majority of building blocks, techniques, and architectures for deep learning are based on real-valued operations and representations. However, recent work on recurrent neural networks and older fundamental theoretical analysis suggests that complex numbers could have a richer representational capacity and could also facilitate noise-robust memory retrieval mechanisms. Despite their attractive properties and potential for opening up entirely new neural architectures, complex-valued deep neural networks have been marginalized due to the absence of the building blocks required to design such models. In this work, we provide the key atomic components for complex-valued deep neural networks and apply them to convolutional feed-forward networks and convolutional LSTMs. More precisely, we rely on complex convolutions and present algorithms for complex batch-normalization, complex weight initialization strategies for complex-valued neural nets and we use them in experiments with end-to-end training schemes. We demonstrate that such complex-valued models are competitive with their real-valued counterparts. We test deep complex models on several computer vision tasks, on music transcription using the MusicNet dataset and on Speech Spectrum Prediction using the TIMIT dataset. We achieve state-of-the-art performance on these audio-related tasks.
Twin Networks: Matching the Future for Sequence Generation
Feb 23, 2018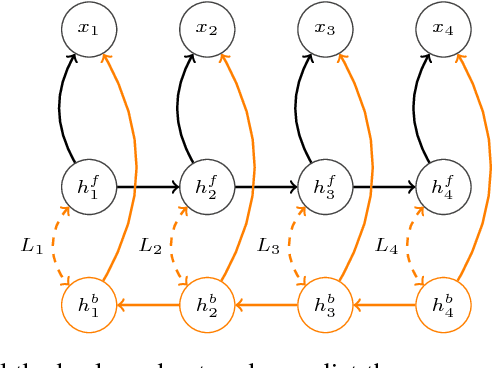

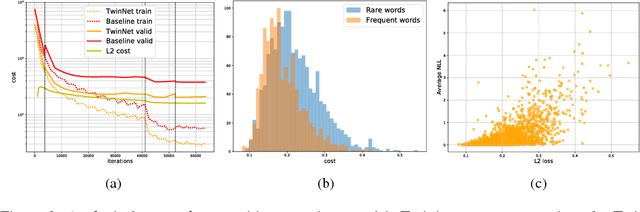
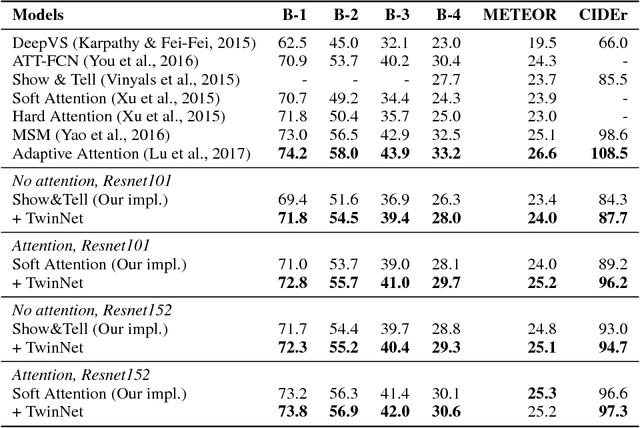
We propose a simple technique for encouraging generative RNNs to plan ahead. We train a "backward" recurrent network to generate a given sequence in reverse order, and we encourage states of the forward model to predict cotemporal states of the backward model. The backward network is used only during training, and plays no role during sampling or inference. We hypothesize that our approach eases modeling of long-term dependencies by implicitly forcing the forward states to hold information about the longer-term future (as contained in the backward states). We show empirically that our approach achieves 9% relative improvement for a speech recognition task, and achieves significant improvement on a COCO caption generation task.
Towards end-to-end spoken language understanding
Feb 23, 2018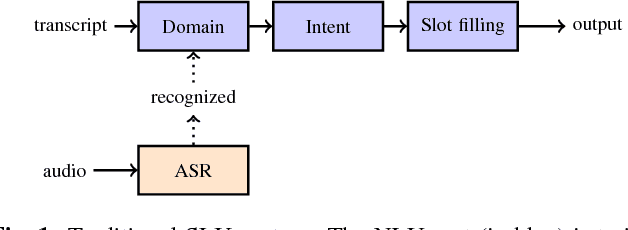

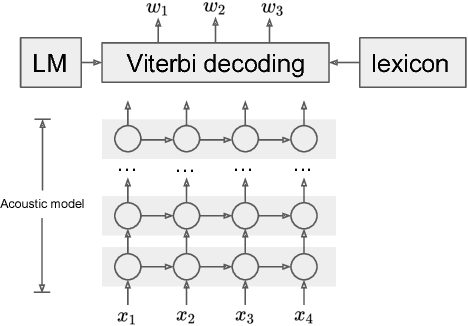
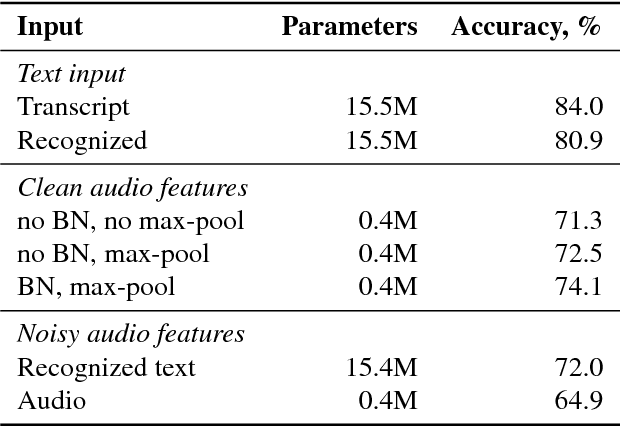
Spoken language understanding system is traditionally designed as a pipeline of a number of components. First, the audio signal is processed by an automatic speech recognizer for transcription or n-best hypotheses. With the recognition results, a natural language understanding system classifies the text to structured data as domain, intent and slots for down-streaming consumers, such as dialog system, hands-free applications. These components are usually developed and optimized independently. In this paper, we present our study on an end-to-end learning system for spoken language understanding. With this unified approach, we can infer the semantic meaning directly from audio features without the intermediate text representation. This study showed that the trained model can achieve reasonable good result and demonstrated that the model can capture the semantic attention directly from the audio features.
Generalization in Deep Learning
Feb 22, 2018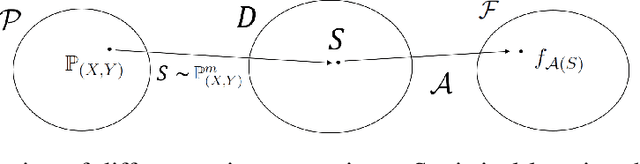
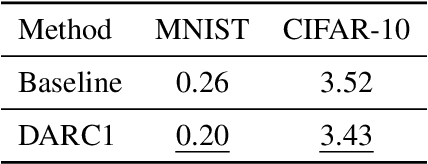
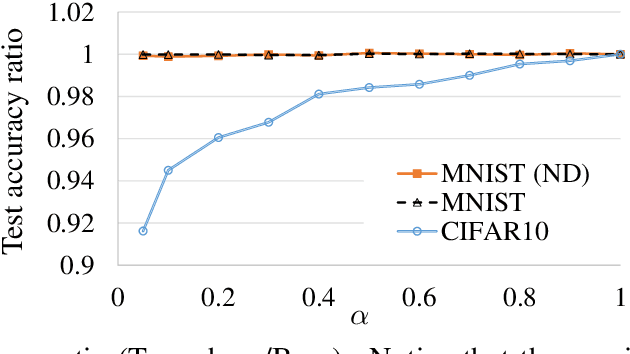

With a direct analysis of neural networks, this paper presents a mathematically tight generalization theory to partially address an open problem regarding the generalization of deep learning. Unlike previous bound-based theory, our main theory is quantitatively as tight as possible for every dataset individually, while producing qualitative insights competitively. Our results give insight into why and how deep learning can generalize well, despite its large capacity, complexity, possible algorithmic instability, nonrobustness, and sharp minima, answering to an open question in the literature. We also discuss limitations of our results and propose additional open problems.
FigureQA: An Annotated Figure Dataset for Visual Reasoning
Feb 22, 2018


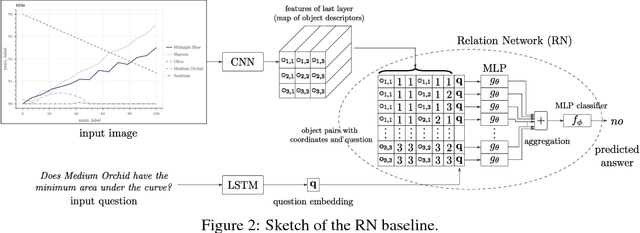
We introduce FigureQA, a visual reasoning corpus of over one million question-answer pairs grounded in over 100,000 images. The images are synthetic, scientific-style figures from five classes: line plots, dot-line plots, vertical and horizontal bar graphs, and pie charts. We formulate our reasoning task by generating questions from 15 templates; questions concern various relationships between plot elements and examine characteristics like the maximum, the minimum, area-under-the-curve, smoothness, and intersection. To resolve, such questions often require reference to multiple plot elements and synthesis of information distributed spatially throughout a figure. To facilitate the training of machine learning systems, the corpus also includes side data that can be used to formulate auxiliary objectives. In particular, we provide the numerical data used to generate each figure as well as bounding-box annotations for all plot elements. We study the proposed visual reasoning task by training several models, including the recently proposed Relation Network as a strong baseline. Preliminary results indicate that the task poses a significant machine learning challenge. We envision FigureQA as a first step towards developing models that can intuitively recognize patterns from visual representations of data.