 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquivalence of Equilibrium Propagation and Recurrent Backpropagation
May 22, 2018Recurrent Backpropagation and Equilibrium Propagation are supervised learning algorithms for fixed point recurrent neural networks which differ in their second phase. In the first phase, both algorithms converge to a fixed point which corresponds to the configuration where the prediction is made. In the second phase, Equilibrium Propagation relaxes to another nearby fixed point corresponding to smaller prediction error, whereas Recurrent Backpropagation uses a side network to compute error derivatives iteratively. In this work we establish a close connection between these two algorithms. We show that, at every moment in the second phase, the temporal derivatives of the neural activities in Equilibrium Propagation are equal to the error derivatives computed iteratively by Recurrent Backpropagation in the side network. This work shows that it is not required to have a side network for the computation of error derivatives, and supports the hypothesis that, in biological neural networks, temporal derivatives of neural activities may code for error signals.
On the iterative refinement of densely connected representation levels for semantic segmentation
Apr 30, 2018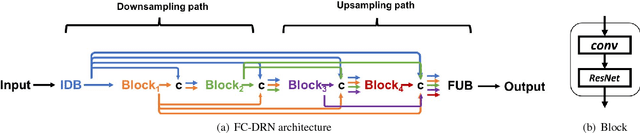


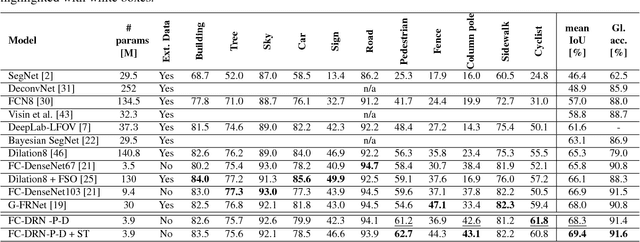
State-of-the-art semantic segmentation approaches increase the receptive field of their models by using either a downsampling path composed of poolings/strided convolutions or successive dilated convolutions. However, it is not clear which operation leads to best results. In this paper, we systematically study the differences introduced by distinct receptive field enlargement methods and their impact on the performance of a novel architecture, called Fully Convolutional DenseResNet (FC-DRN). FC-DRN has a densely connected backbone composed of residual networks. Following standard image segmentation architectures, receptive field enlargement operations that change the representation level are interleaved among residual networks. This allows the model to exploit the benefits of both residual and dense connectivity patterns, namely: gradient flow, iterative refinement of representations, multi-scale feature combination and deep supervision. In order to highlight the potential of our model, we test it on the challenging CamVid urban scene understanding benchmark and make the following observations: 1) downsampling operations outperform dilations when the model is trained from scratch, 2) dilations are useful during the finetuning step of the model, 3) coarser representations require less refinement steps, and 4) ResNets (by model construction) are good regularizers, since they can reduce the model capacity when needed. Finally, we compare our architecture to alternative methods and report state-of-the-art result on the Camvid dataset, with at least twice fewer parameters.
Low-memory convolutional neural networks through incremental depth-first processing
Apr 28, 2018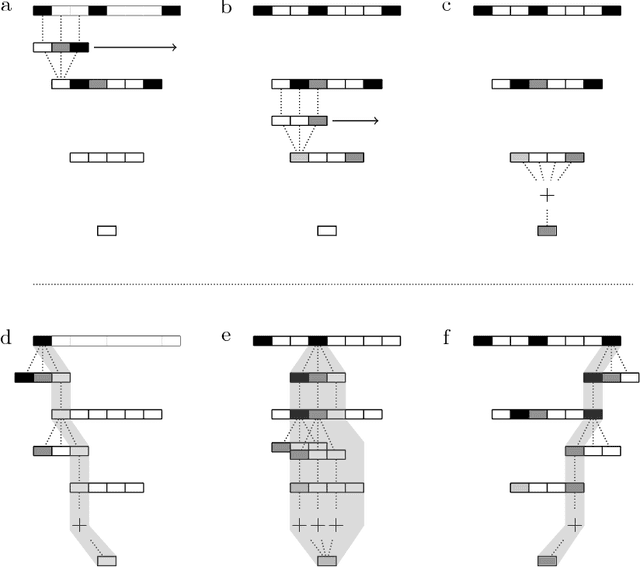
We introduce an incremental processing scheme for convolutional neural network (CNN) inference, targeted at embedded applications with limited memory budgets. Instead of processing layers one by one, individual input pixels are propagated through all parts of the network they can influence under the given structural constraints. This depth-first updating scheme comes with hard bounds on the memory footprint: the memory required is constant in the case of 1D input and proportional to the square root of the input dimension in the case of 2D input.
Commonsense mining as knowledge base completion? A study on the impact of novelty
Apr 24, 2018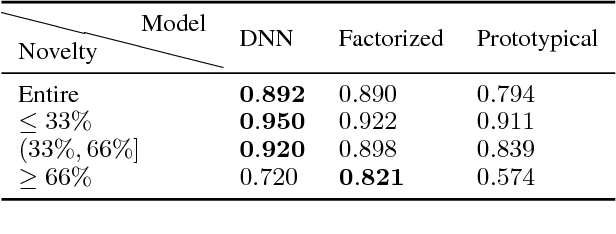
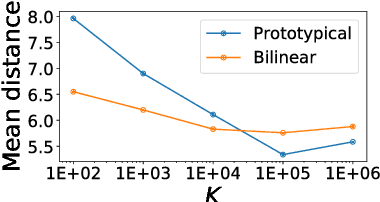


Commonsense knowledge bases such as ConceptNet represent knowledge in the form of relational triples. Inspired by the recent work by Li et al., we analyse if knowledge base completion models can be used to mine commonsense knowledge from raw text. We propose novelty of predicted triples with respect to the training set as an important factor in interpreting results. We critically analyse the difficulty of mining novel commonsense knowledge, and show that a simple baseline method outperforms the previous state of the art on predicting more novel.
Universal Successor Representations for Transfer Reinforcement Learning
Apr 11, 2018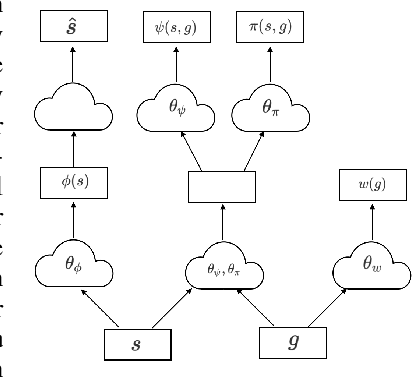
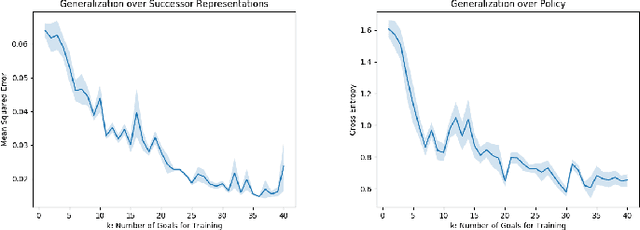
The objective of transfer reinforcement learning is to generalize from a set of previous tasks to unseen new tasks. In this work, we focus on the transfer scenario where the dynamics among tasks are the same, but their goals differ. Although general value function (Sutton et al., 2011) has been shown to be useful for knowledge transfer, learning a universal value function can be challenging in practice. To attack this, we propose (1) to use universal successor representations (USR) to represent the transferable knowledge and (2) a USR approximator (USRA) that can be trained by interacting with the environment. Our experiments show that USR can be effectively applied to new tasks, and the agent initialized by the trained USRA can achieve the goal considerably faster than random initialization.
Fortified Networks: Improving the Robustness of Deep Networks by Modeling the Manifold of Hidden Representations
Apr 07, 2018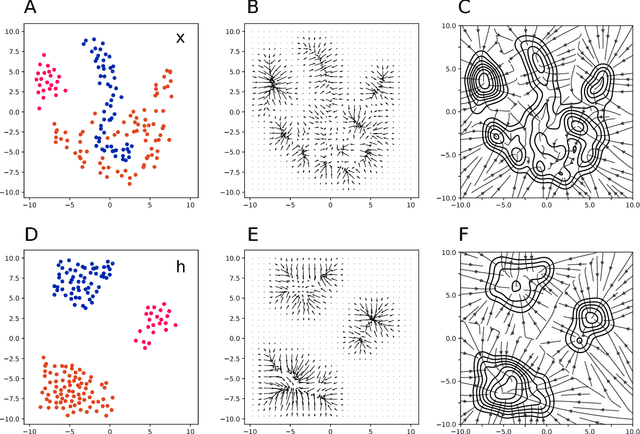
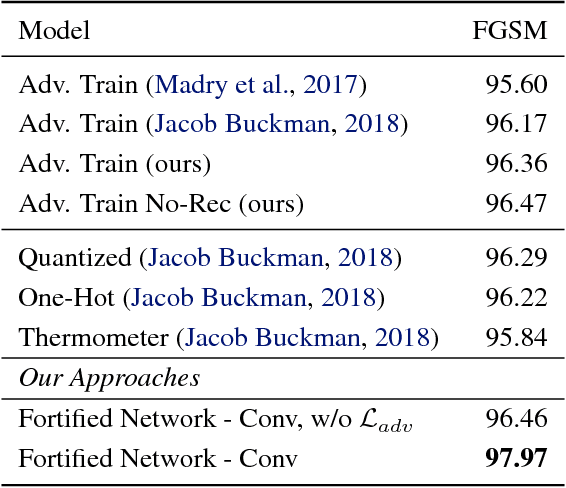
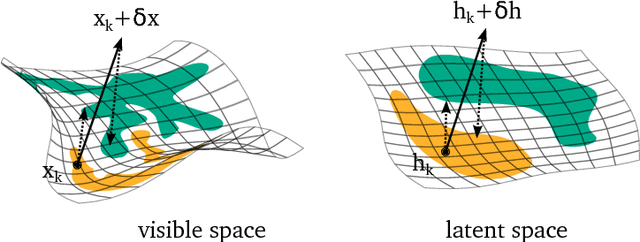

Deep networks have achieved impressive results across a variety of important tasks. However a known weakness is a failure to perform well when evaluated on data which differ from the training distribution, even if these differences are very small, as is the case with adversarial examples. We propose Fortified Networks, a simple transformation of existing networks, which fortifies the hidden layers in a deep network by identifying when the hidden states are off of the data manifold, and maps these hidden states back to parts of the data manifold where the network performs well. Our principal contribution is to show that fortifying these hidden states improves the robustness of deep networks and our experiments (i) demonstrate improved robustness to standard adversarial attacks in both black-box and white-box threat models; (ii) suggest that our improvements are not primarily due to the gradient masking problem and (iii) show the advantage of doing this fortification in the hidden layers instead of the input space.
Fine-Grained Attention Mechanism for Neural Machine Translation
Apr 03, 2018
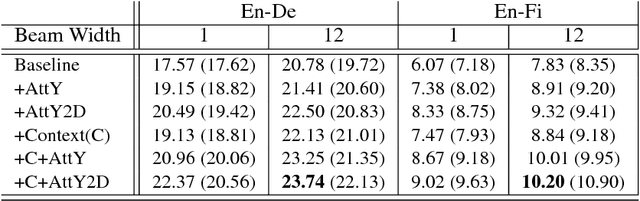
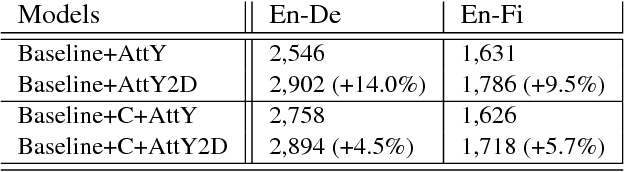
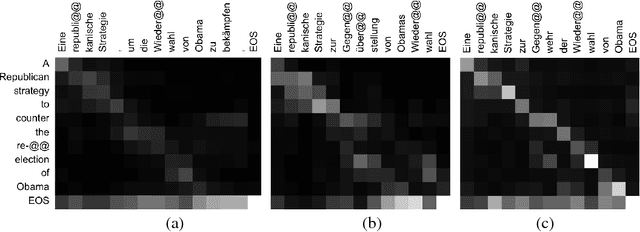
Neural machine translation (NMT) has been a new paradigm in machine translation, and the attention mechanism has become the dominant approach with the state-of-the-art records in many language pairs. While there are variants of the attention mechanism, all of them use only temporal attention where one scalar value is assigned to one context vector corresponding to a source word. In this paper, we propose a fine-grained (or 2D) attention mechanism where each dimension of a context vector will receive a separate attention score. In experiments with the task of En-De and En-Fi translation, the fine-grained attention method improves the translation quality in terms of BLEU score. In addition, our alignment analysis reveals how the fine-grained attention mechanism exploits the internal structure of context vectors.
* 9 pages, 4 figures
Recall Traces: Backtracking Models for Efficient Reinforcement Learning
Apr 02, 2018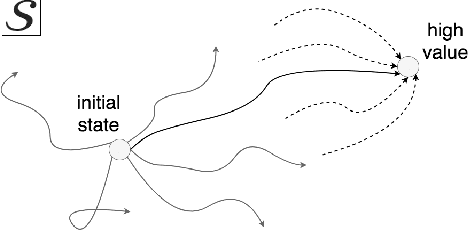

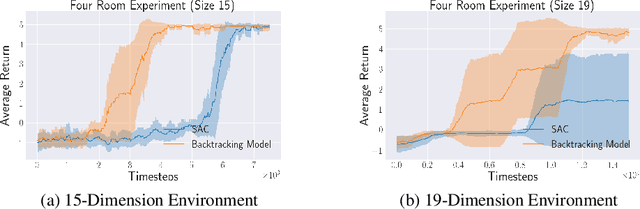

In many environments only a tiny subset of all states yield high reward. In these cases, few of the interactions with the environment provide a relevant learning signal. Hence, we may want to preferentially train on those high-reward states and the probable trajectories leading to them. To this end, we advocate for the use of a backtracking model that predicts the preceding states that terminate at a given high-reward state. We can train a model which, starting from a high value state (or one that is estimated to have high value), predicts and sample for which the (state, action)-tuples may have led to that high value state. These traces of (state, action) pairs, which we refer to as Recall Traces, sampled from this backtracking model starting from a high value state, are informative as they terminate in good states, and hence we can use these traces to improve a policy. We provide a variational interpretation for this idea and a practical algorithm in which the backtracking model samples from an approximate posterior distribution over trajectories which lead to large rewards. Our method improves the sample efficiency of both on- and off-policy RL algorithms across several environments and tasks.
Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning
Mar 30, 2018
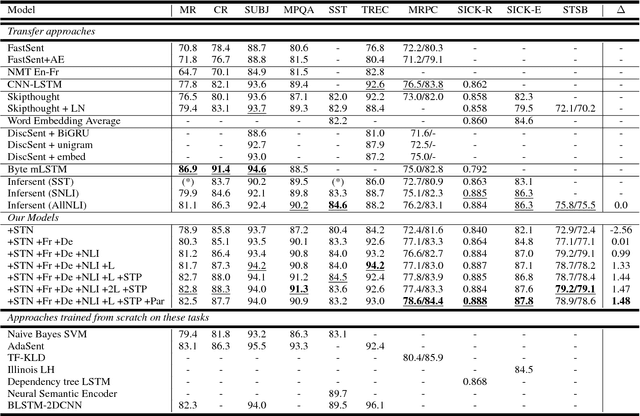
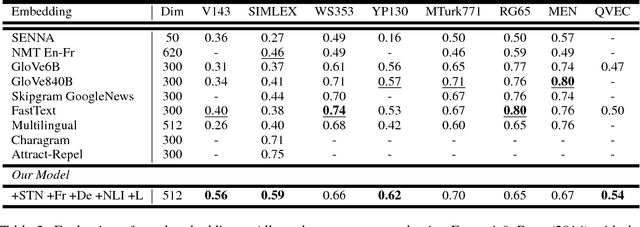
A lot of the recent success in natural language processing (NLP) has been driven by distributed vector representations of words trained on large amounts of text in an unsupervised manner. These representations are typically used as general purpose features for words across a range of NLP problems. However, extending this success to learning representations of sequences of words, such as sentences, remains an open problem. Recent work has explored unsupervised as well as supervised learning techniques with different training objectives to learn general purpose fixed-length sentence representations. In this work, we present a simple, effective multi-task learning framework for sentence representations that combines the inductive biases of diverse training objectives in a single model. We train this model on several data sources with multiple training objectives on over 100 million sentences. Extensive experiments demonstrate that sharing a single recurrent sentence encoder across weakly related tasks leads to consistent improvements over previous methods. We present substantial improvements in the context of transfer learning and low-resource settings using our learned general-purpose representations.
Fraternal Dropout
Mar 28, 2018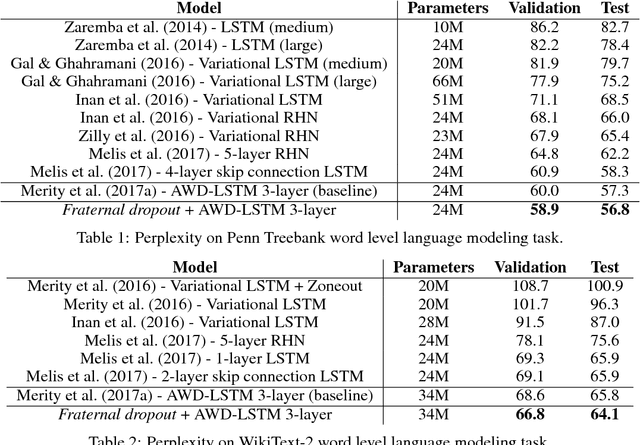
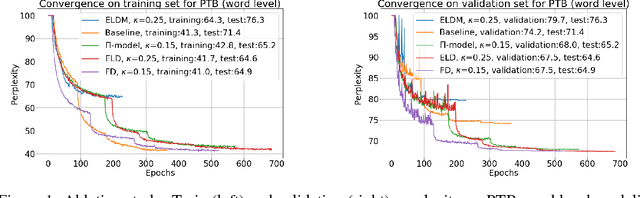
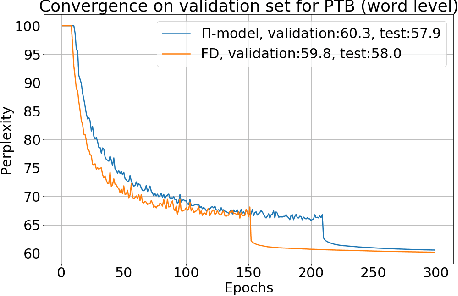

Recurrent neural networks (RNNs) are important class of architectures among neural networks useful for language modeling and sequential prediction. However, optimizing RNNs is known to be harder compared to feed-forward neural networks. A number of techniques have been proposed in literature to address this problem. In this paper we propose a simple technique called fraternal dropout that takes advantage of dropout to achieve this goal. Specifically, we propose to train two identical copies of an RNN (that share parameters) with different dropout masks while minimizing the difference between their (pre-softmax) predictions. In this way our regularization encourages the representations of RNNs to be invariant to dropout mask, thus being robust. We show that our regularization term is upper bounded by the expectation-linear dropout objective which has been shown to address the gap due to the difference between the train and inference phases of dropout. We evaluate our model and achieve state-of-the-art results in sequence modeling tasks on two benchmark datasets - Penn Treebank and Wikitext-2. We also show that our approach leads to performance improvement by a significant margin in image captioning (Microsoft COCO) and semi-supervised (CIFAR-10) tasks.