 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFraternal Dropout
Mar 28, 2018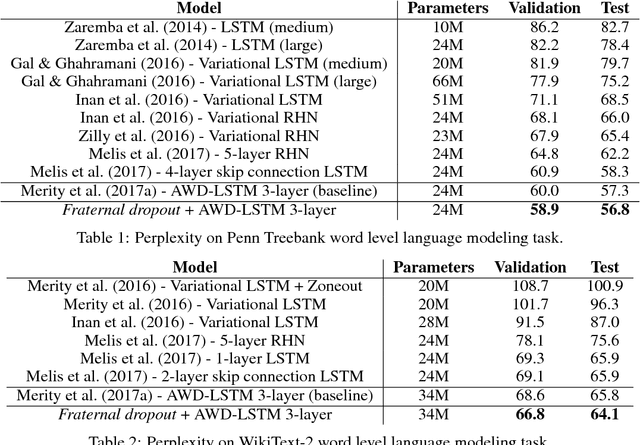
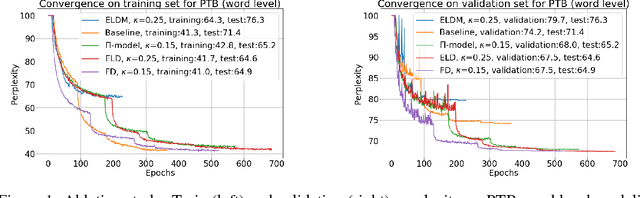
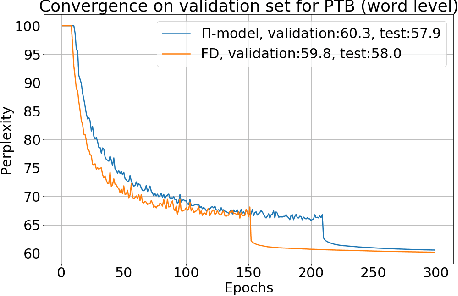

Recurrent neural networks (RNNs) are important class of architectures among neural networks useful for language modeling and sequential prediction. However, optimizing RNNs is known to be harder compared to feed-forward neural networks. A number of techniques have been proposed in literature to address this problem. In this paper we propose a simple technique called fraternal dropout that takes advantage of dropout to achieve this goal. Specifically, we propose to train two identical copies of an RNN (that share parameters) with different dropout masks while minimizing the difference between their (pre-softmax) predictions. In this way our regularization encourages the representations of RNNs to be invariant to dropout mask, thus being robust. We show that our regularization term is upper bounded by the expectation-linear dropout objective which has been shown to address the gap due to the difference between the train and inference phases of dropout. We evaluate our model and achieve state-of-the-art results in sequence modeling tasks on two benchmark datasets - Penn Treebank and Wikitext-2. We also show that our approach leads to performance improvement by a significant margin in image captioning (Microsoft COCO) and semi-supervised (CIFAR-10) tasks.
ChatPainter: Improving Text to Image Generation using Dialogue
Feb 22, 2018

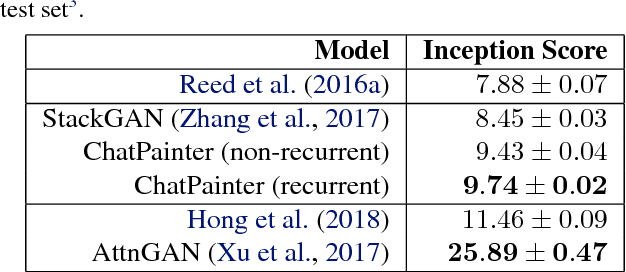
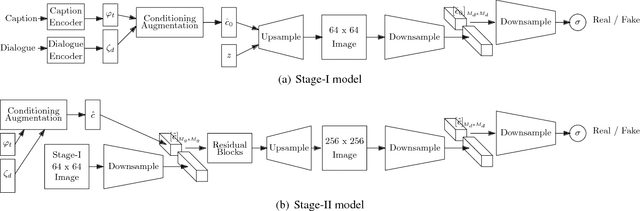
Synthesizing realistic images from text descriptions on a dataset like Microsoft Common Objects in Context (MS COCO), where each image can contain several objects, is a challenging task. Prior work has used text captions to generate images. However, captions might not be informative enough to capture the entire image and insufficient for the model to be able to understand which objects in the images correspond to which words in the captions. We show that adding a dialogue that further describes the scene leads to significant improvement in the inception score and in the quality of generated images on the MS COCO dataset.
A Deep Reinforcement Learning Chatbot (Short Version)
Jan 20, 2018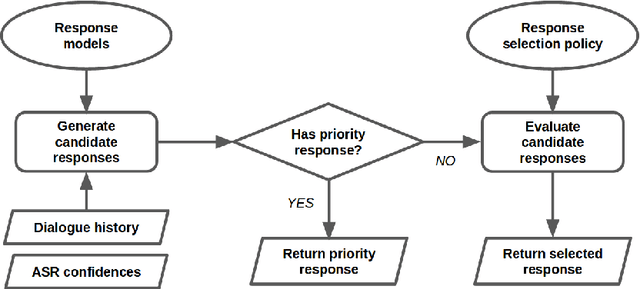
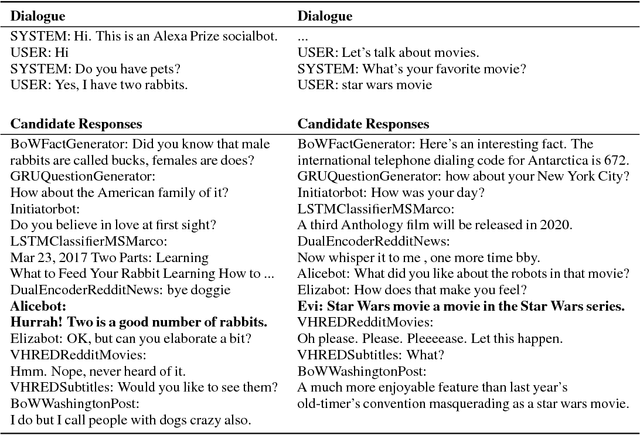
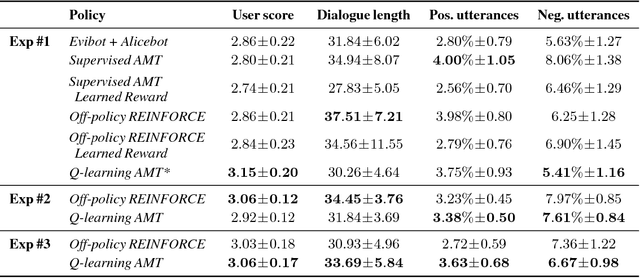
We present MILABOT: a deep reinforcement learning chatbot developed by the Montreal Institute for Learning Algorithms (MILA) for the Amazon Alexa Prize competition. MILABOT is capable of conversing with humans on popular small talk topics through both speech and text. The system consists of an ensemble of natural language generation and retrieval models, including neural network and template-based models. By applying reinforcement learning to crowdsourced data and real-world user interactions, the system has been trained to select an appropriate response from the models in its ensemble. The system has been evaluated through A/B testing with real-world users, where it performed significantly better than other systems. The results highlight the potential of coupling ensemble systems with deep reinforcement learning as a fruitful path for developing real-world, open-domain conversational agents.
A Deep Reinforcement Learning Chatbot
Nov 05, 2017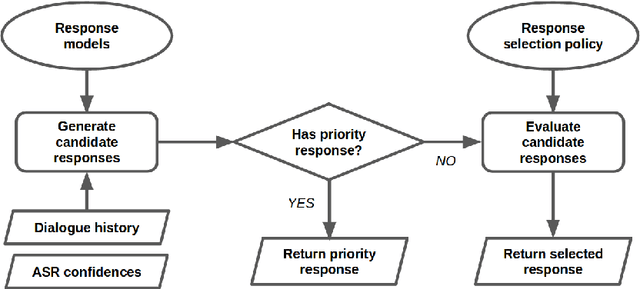
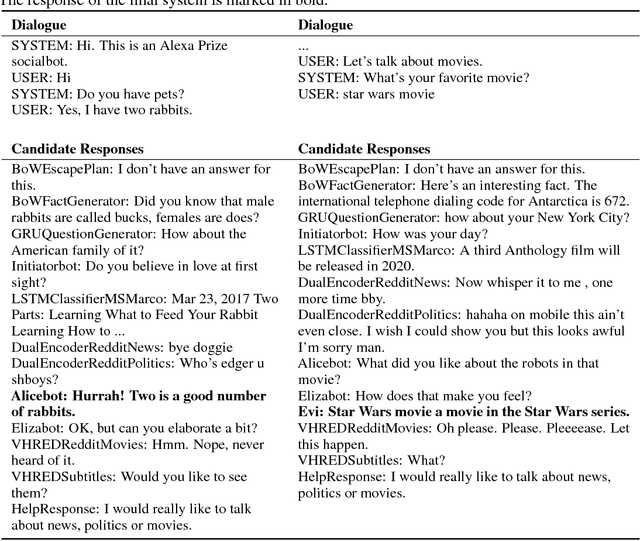
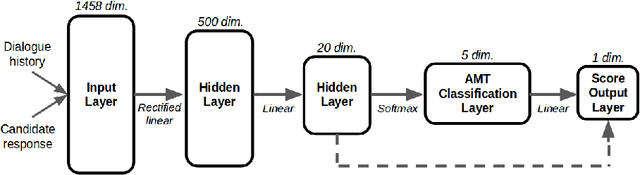

We present MILABOT: a deep reinforcement learning chatbot developed by the Montreal Institute for Learning Algorithms (MILA) for the Amazon Alexa Prize competition. MILABOT is capable of conversing with humans on popular small talk topics through both speech and text. The system consists of an ensemble of natural language generation and retrieval models, including template-based models, bag-of-words models, sequence-to-sequence neural network and latent variable neural network models. By applying reinforcement learning to crowdsourced data and real-world user interactions, the system has been trained to select an appropriate response from the models in its ensemble. The system has been evaluated through A/B testing with real-world users, where it performed significantly better than many competing systems. Due to its machine learning architecture, the system is likely to improve with additional data.