 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThree Factors Influencing Minima in SGD
Sep 13, 2018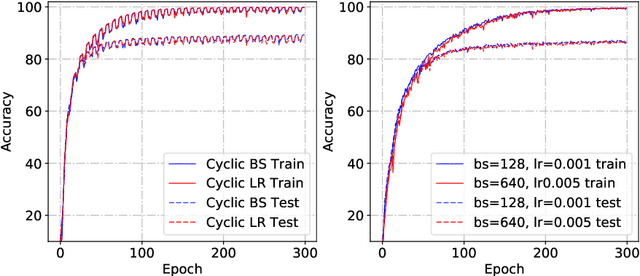
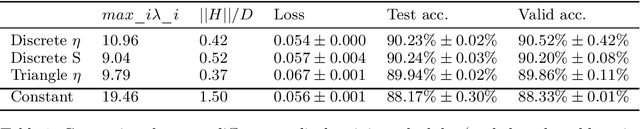
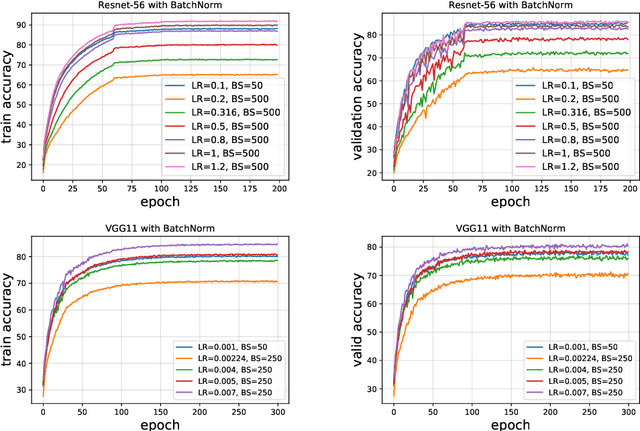
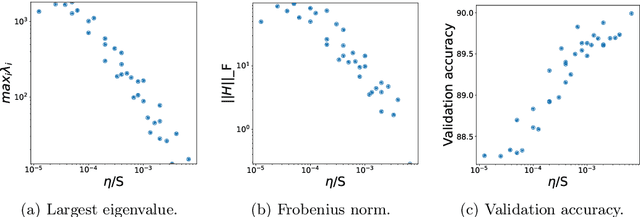
We investigate the dynamical and convergent properties of stochastic gradient descent (SGD) applied to Deep Neural Networks (DNNs). Characterizing the relation between learning rate, batch size and the properties of the final minima, such as width or generalization, remains an open question. In order to tackle this problem we investigate the previously proposed approximation of SGD by a stochastic differential equation (SDE). We theoretically argue that three factors - learning rate, batch size and gradient covariance - influence the minima found by SGD. In particular we find that the ratio of learning rate to batch size is a key determinant of SGD dynamics and of the width of the final minima, and that higher values of the ratio lead to wider minima and often better generalization. We confirm these findings experimentally. Further, we include experiments which show that learning rate schedules can be replaced with batch size schedules and that the ratio of learning rate to batch size is an important factor influencing the memorization process.
Combined Reinforcement Learning via Abstract Representations
Sep 12, 2018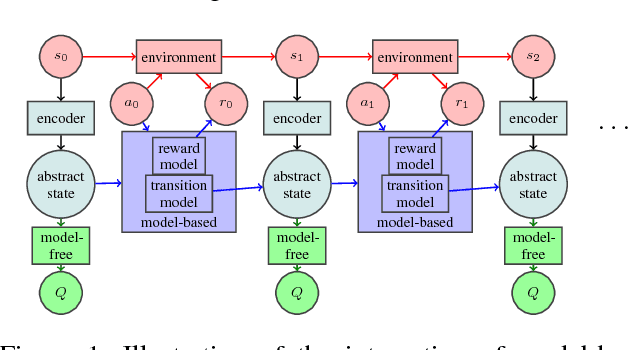
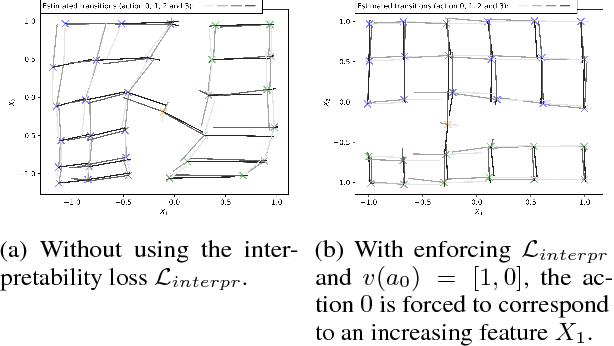
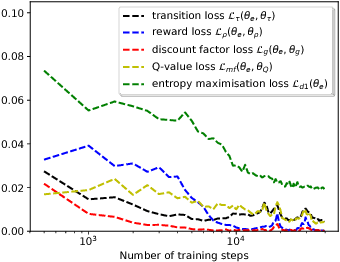
In the quest for efficient and robust reinforcement learning methods, both model-free and model-based approaches offer advantages. In this paper we propose a new way of explicitly bridging both approaches via a shared low-dimensional learned encoding of the environment, meant to capture summarizing abstractions. We show that the modularity brought by this approach leads to good generalization while being computationally efficient, with planning happening in a smaller latent state space. In addition, this approach recovers a sufficient low-dimensional representation of the environment, which opens up new strategies for interpretable AI, exploration and transfer learning.
Predicting Solution Summaries to Integer Linear Programs under Imperfect Information with Machine Learning
Sep 12, 2018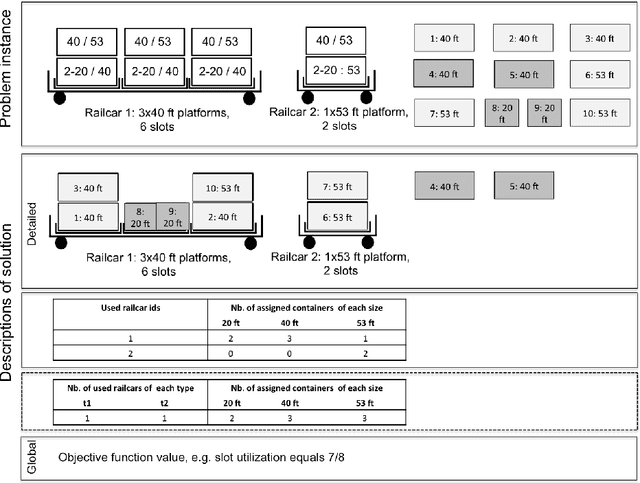
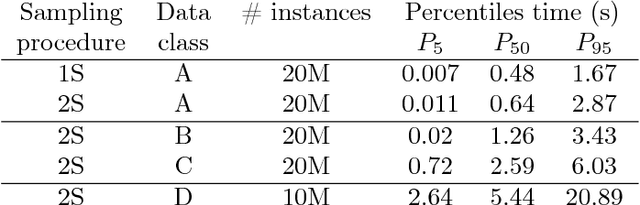
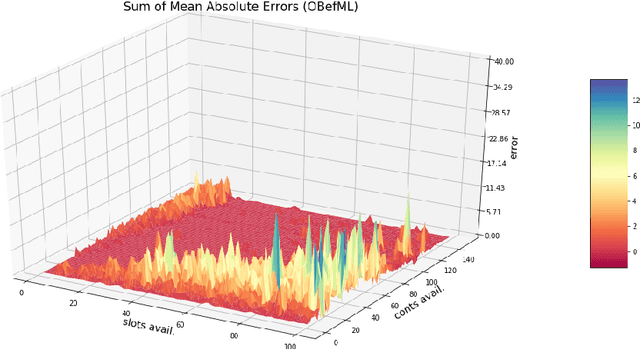
The paper provides a methodological contribution at the intersection of machine learning and operations research. Namely, we propose a methodology to quickly predict solution summaries (i.e., solution descriptions at a given level of detail) to discrete stochastic optimization problems. We approximate the solutions based on supervised learning and the training dataset consists of a large number of deterministic problems that have been solved independently and offline. Uncertainty regarding a missing subset of the inputs is addressed through sampling and aggregation methods. Our motivating application concerns booking decisions of intermodal containers on double-stack trains. Under perfect information, this is the so-called load planning problem and it can be formulated by means of integer linear programming. However, the formulation cannot be used for the application at hand because of the restricted computational budget and unknown container weights. The results show that standard deep learning algorithms allow one to predict descriptions of solutions with high accuracy in very short time (milliseconds or less).
Sparse Attentive Backtracking: Temporal CreditAssignment Through Reminding
Sep 11, 2018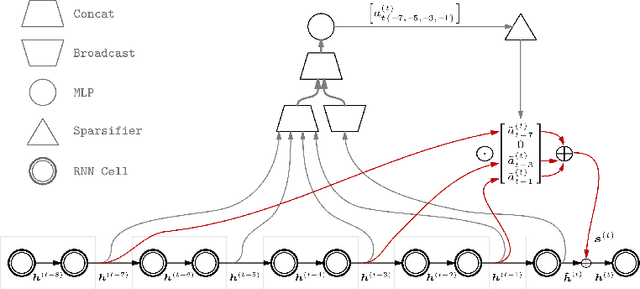

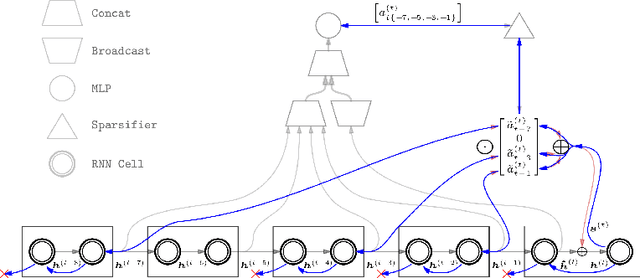
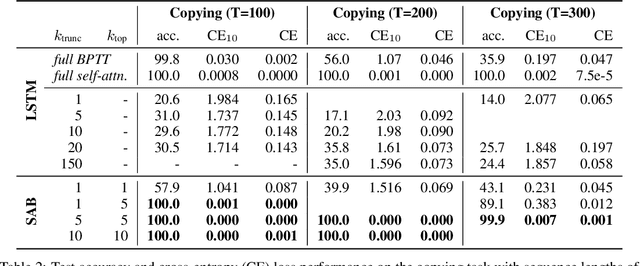
Learning long-term dependencies in extended temporal sequences requires credit assignment to events far back in the past. The most common method for training recurrent neural networks, back-propagation through time (BPTT), requires credit information to be propagated backwards through every single step of the forward computation, potentially over thousands or millions of time steps. This becomes computationally expensive or even infeasible when used with long sequences. Importantly, biological brains are unlikely to perform such detailed reverse replay over very long sequences of internal states (consider days, months, or years.) However, humans are often reminded of past memories or mental states which are associated with the current mental state. We consider the hypothesis that such memory associations between past and present could be used for credit assignment through arbitrarily long sequences, propagating the credit assigned to the current state to the associated past state. Based on this principle, we study a novel algorithm which only back-propagates through a few of these temporal skip connections, realized by a learned attention mechanism that associates current states with relevant past states. We demonstrate in experiments that our method matches or outperforms regular BPTT and truncated BPTT in tasks involving particularly long-term dependencies, but without requiring the biologically implausible backward replay through the whole history of states. Additionally, we demonstrate that the proposed method transfers to longer sequences significantly better than LSTMs trained with BPTT and LSTMs trained with full self-attention.
Speaker Recognition from Raw Waveform with SincNet
Sep 09, 2018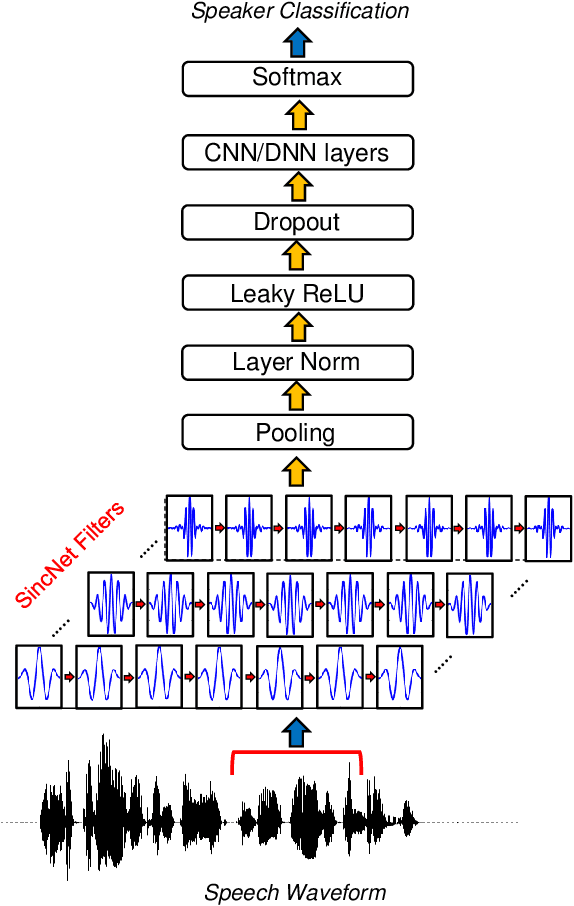
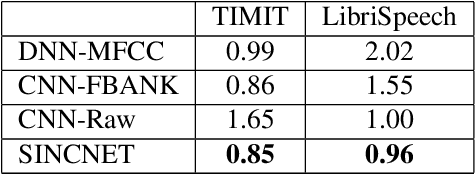
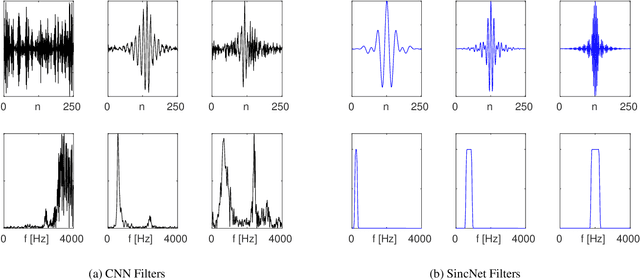
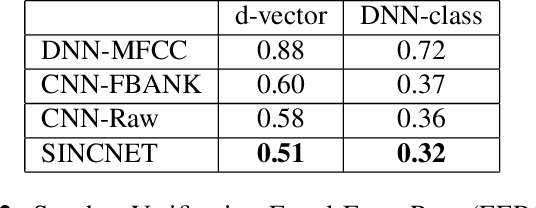
Deep learning is progressively gaining popularity as a viable alternative to i-vectors for speaker recognition. Promising results have been recently obtained with Convolutional Neural Networks (CNNs) when fed by raw speech samples directly. Rather than employing standard hand-crafted features, the latter CNNs learn low-level speech representations from waveforms, potentially allowing the network to better capture important narrow-band speaker characteristics such as pitch and formants. Proper design of the neural network is crucial to achieve this goal. This paper proposes a novel CNN architecture, called SincNet, that encourages the first convolutional layer to discover more meaningful filters. SincNet is based on parametrized sinc functions, which implement band-pass filters. In contrast to standard CNNs, that learn all elements of each filter, only low and high cutoff frequencies are directly learned from data with the proposed method. This offers a very compact and efficient way to derive a customized filter bank specifically tuned for the desired application. Our experiments, conducted on both speaker identification and speaker verification tasks, show that the proposed architecture converges faster and performs better than a standard CNN on raw waveforms.
Variance Regularizing Adversarial Learning
Aug 19, 2018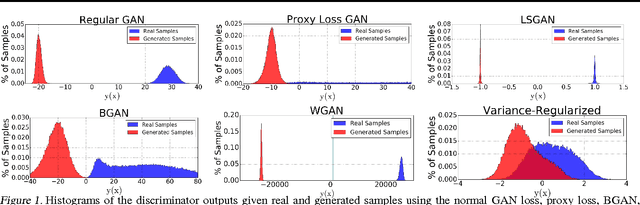

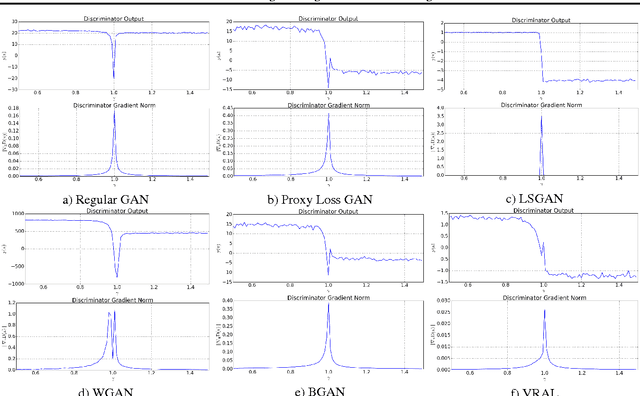

We introduce a novel approach for training adversarial models by replacing the discriminator score with a bi-modal Gaussian distribution over the real/fake indicator variables. In order to do this, we train the Gaussian classifier to match the target bi-modal distribution implicitly through meta-adversarial training. We hypothesize that this approach ensures a non-zero gradient to the generator, even in the limit of a perfect classifier. We test our method against standard benchmark image datasets as well as show the classifier output distribution is smooth and has overlap between the real and fake modes.
Generalization of Equilibrium Propagation to Vector Field Dynamics
Aug 14, 2018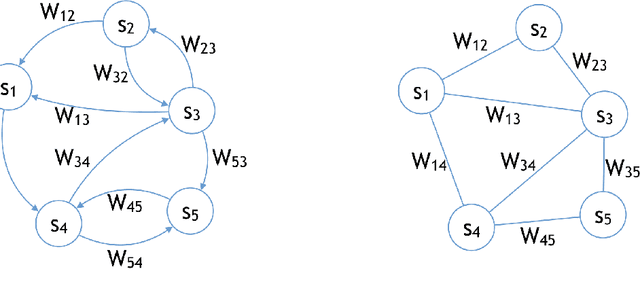

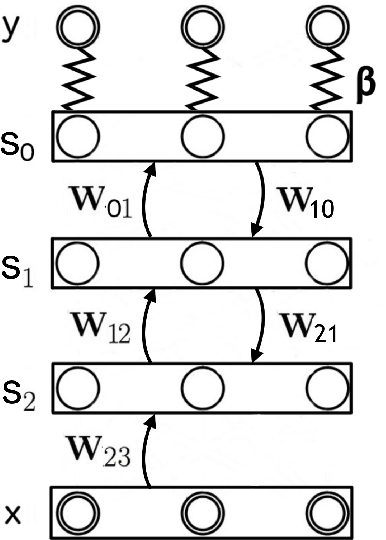

The biological plausibility of the backpropagation algorithm has long been doubted by neuroscientists. Two major reasons are that neurons would need to send two different types of signal in the forward and backward phases, and that pairs of neurons would need to communicate through symmetric bidirectional connections. We present a simple two-phase learning procedure for fixed point recurrent networks that addresses both these issues. In our model, neurons perform leaky integration and synaptic weights are updated through a local mechanism. Our learning method generalizes Equilibrium Propagation to vector field dynamics, relaxing the requirement of an energy function. As a consequence of this generalization, the algorithm does not compute the true gradient of the objective function, but rather approximates it at a precision which is proven to be directly related to the degree of symmetry of the feedforward and feedback weights. We show experimentally that our algorithm optimizes the objective function.
DNN's Sharpest Directions Along the SGD Trajectory
Jul 13, 2018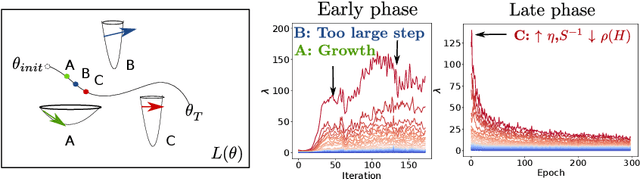
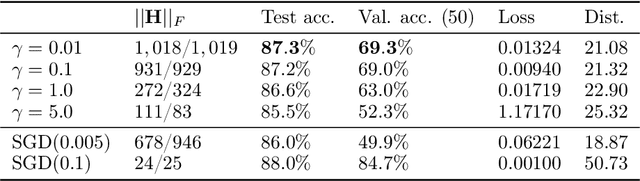
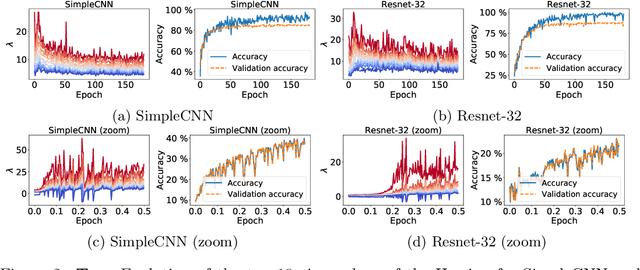
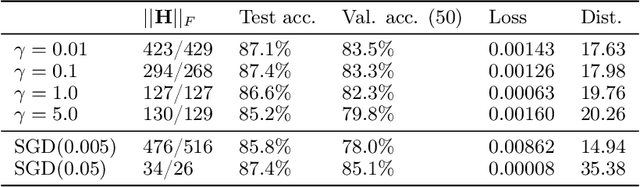
Recent work has identified that using a high learning rate or a small batch size for Stochastic Gradient Descent (SGD) based training of deep neural networks encourages finding flatter minima of the training loss towards the end of training. Moreover, measures of the flatness of minima have been shown to correlate with good generalization performance. Extending this previous work, we investigate the loss curvature through the Hessian eigenvalue spectrum in the early phase of training and find an analogous bias: even at the beginning of training, a high learning rate or small batch size influences SGD to visit flatter loss regions. In addition, the evolution of the largest eigenvalues appears to always follow a similar pattern, with a fast increase in the early phase, and a decrease or stabilization thereafter, where the peak value is determined by the learning rate and batch size. Finally, we find that by altering the learning rate just in the direction of the eigenvectors associated with the largest eigenvalues, SGD can be steered towards regions which are an order of magnitude sharper but correspond to models with similar generalization, which suggests the curvature of the endpoint found by SGD is not predictive of its generalization properties.
The Bottleneck Simulator: A Model-based Deep Reinforcement Learning Approach
Jul 12, 2018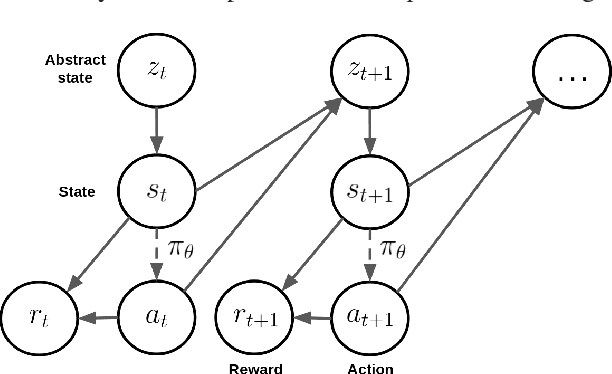

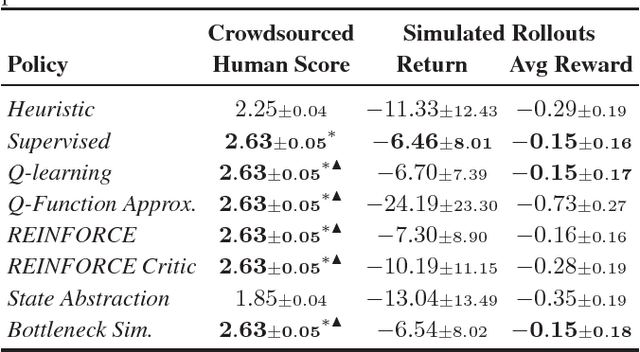
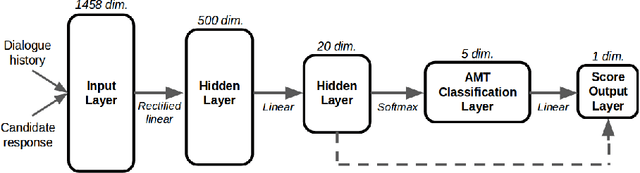
Deep reinforcement learning has recently shown many impressive successes. However, one major obstacle towards applying such methods to real-world problems is their lack of data-efficiency. To this end, we propose the Bottleneck Simulator: a model-based reinforcement learning method which combines a learned, factorized transition model of the environment with rollout simulations to learn an effective policy from few examples. The learned transition model employs an abstract, discrete (bottleneck) state, which increases sample efficiency by reducing the number of model parameters and by exploiting structural properties of the environment. We provide a mathematical analysis of the Bottleneck Simulator in terms of fixed points of the learned policy, which reveals how performance is affected by four distinct sources of error: an error related to the abstract space structure, an error related to the transition model estimation variance, an error related to the transition model estimation bias, and an error related to the transition model class bias. Finally, we evaluate the Bottleneck Simulator on two natural language processing tasks: a text adventure game and a real-world, complex dialogue response selection task. On both tasks, the Bottleneck Simulator yields excellent performance beating competing approaches.
Quaternion Recurrent Neural Networks
Jul 05, 2018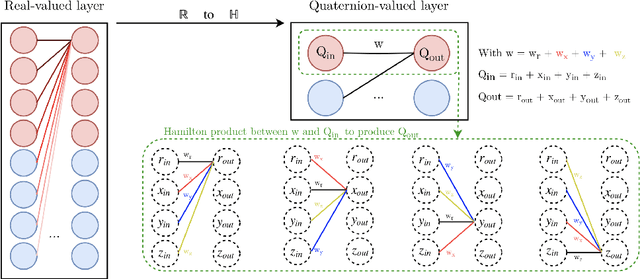
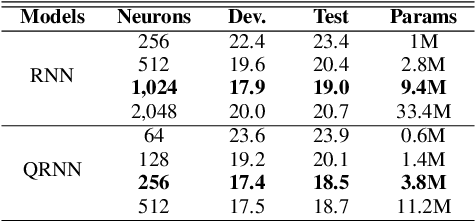
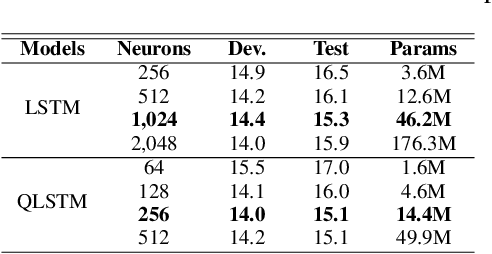

Recurrent neural networks (RNNs) are powerful architectures to model sequential data, due to their capability to learn short and long-term dependencies between the basic elements of a sequence. Nonetheless, popular tasks such as speech or images recognition, involve multi-dimensional input features that are characterized by strong internal dependencies between the dimensions of the input vector. We propose a novel quaternion recurrent neural network (QRNN) that takes into account both the external relations and these internal structural dependencies with the quaternion algebra. Similarly to capsules, quaternions allow the QRNN to code internal dependencies by composing and processing multidimensional features as single entities, while the recurrent operation reveals correlations between the elements composing the sequence. We show that the QRNN achieves better performances in both a synthetic memory copy task and in realistic applications of automatic speech recognition. Finally, we show that the QRNN reduces by a factor of 3x the number of free parameters needed, compared to RNNs to reach better results, leading to a more compact representation of the relevant information.