 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data-Efficient Framework for Training and Sim-to-Real Transfer of Navigation Policies
Oct 11, 2018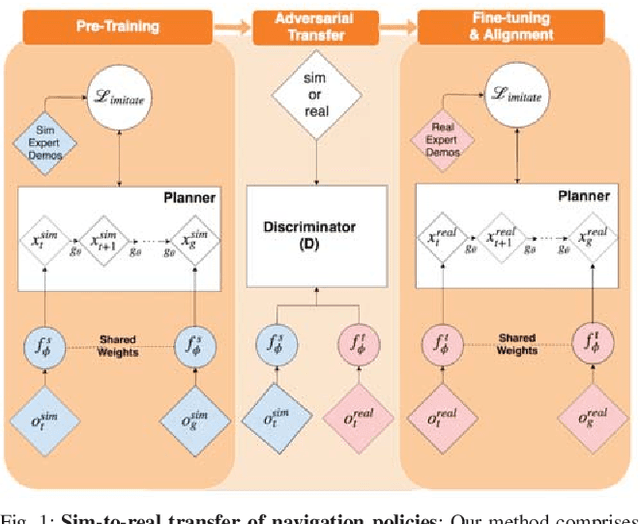

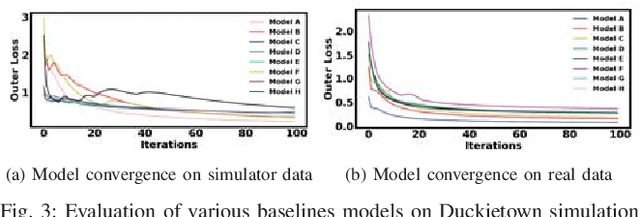
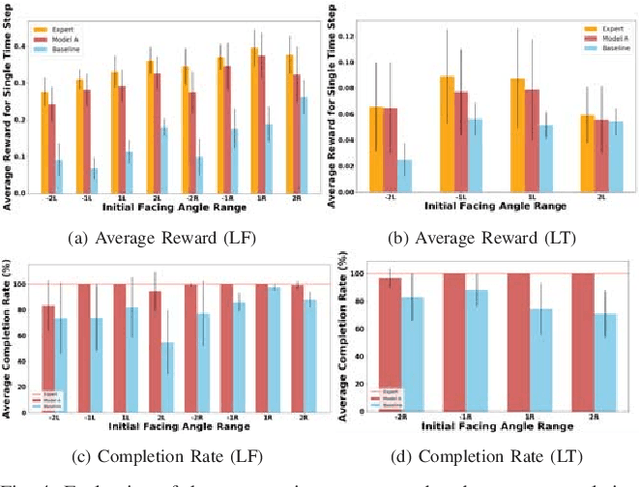
Learning effective visuomotor policies for robots purely from data is challenging, but also appealing since a learning-based system should not require manual tuning or calibration. In the case of a robot operating in a real environment the training process can be costly, time-consuming, and even dangerous since failures are common at the start of training. For this reason, it is desirable to be able to leverage \textit{simulation} and \textit{off-policy} data to the extent possible to train the robot. In this work, we introduce a robust framework that plans in simulation and transfers well to the real environment. Our model incorporates a gradient-descent based planning module, which, given the initial image and goal image, encodes the images to a lower dimensional latent state and plans a trajectory to reach the goal. The model, consisting of the encoder and planner modules, is trained through a meta-learning strategy in simulation first. We subsequently perform adversarial domain transfer on the encoder by using a bank of unlabelled but random images from the simulation and real environments to enable the encoder to map images from the real and simulated environments to a similarly distributed latent representation. By fine tuning the entire model (encoder + planner) with far fewer real world expert demonstrations, we show successful planning performances in different navigation tasks.
Towards the Latent Transcriptome
Oct 08, 2018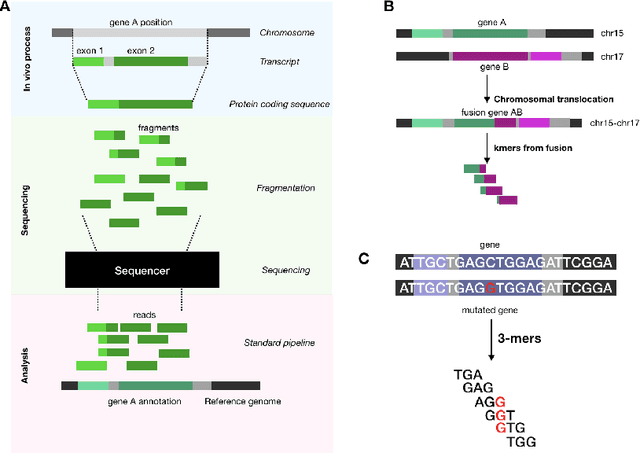

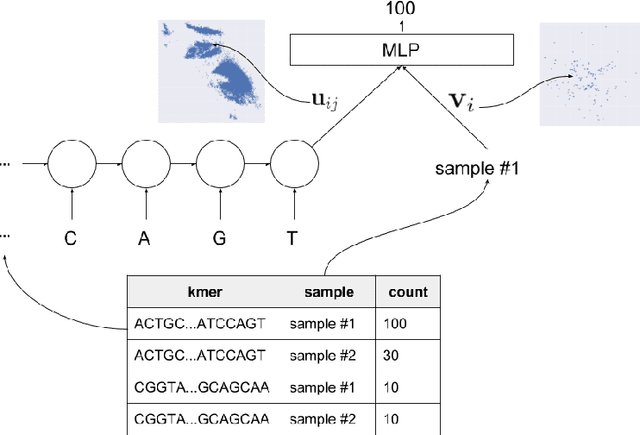
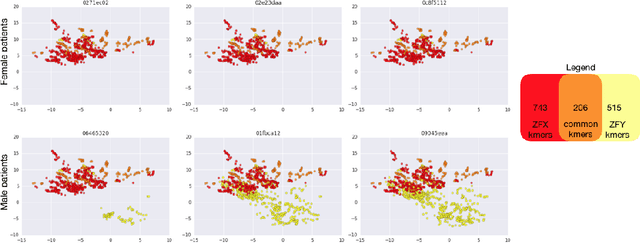
In this work we propose a method to compute continuous embeddings for kmers from raw RNA-seq data, in a reference-free fashion. We report that our model captures information of both DNA sequence similarity as well as DNA sequence abundance in the embedding latent space. We confirm the quality of these vectors by comparing them to known gene sub-structures and report that the latent space recovers exon information from raw RNA-Seq data from acute myeloid leukemia patients. Furthermore we show that this latent space allows the detection of genomic abnormalities such as translocations as well as patient-specific mutations, making this representation space both useful for visualization as well as analysis.
Manifold Mixup: Learning Better Representations by Interpolating Hidden States
Oct 04, 2018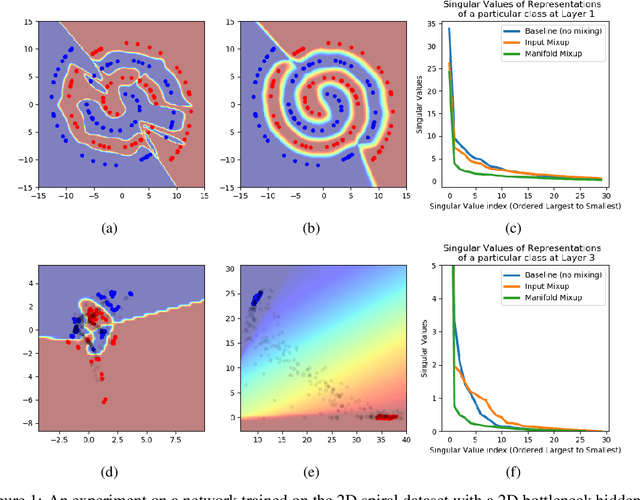
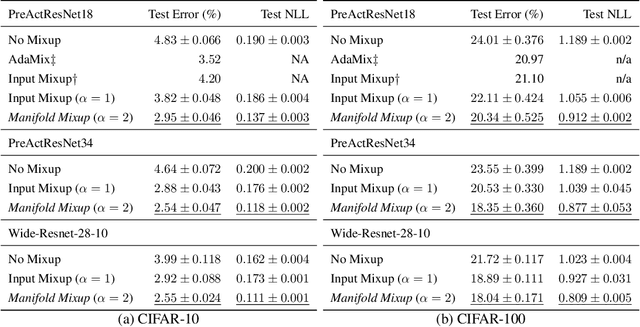
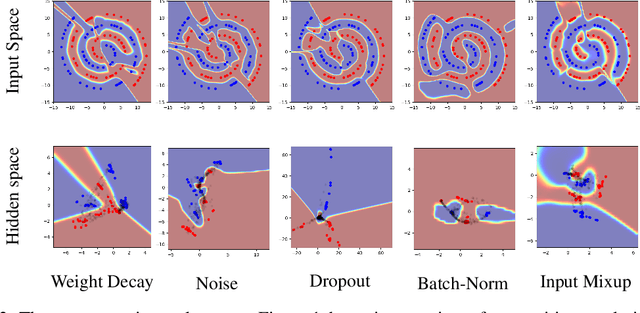
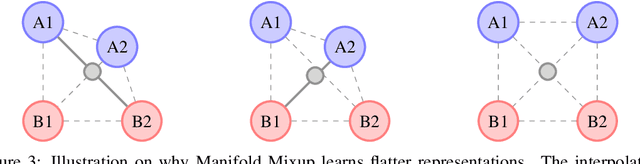
Deep networks often perform well on the data distribution on which they are trained, yet give incorrect (and often very confident) answers when evaluated on points from off of the training distribution. This is exemplified by the adversarial examples phenomenon but can also be seen in terms of model generalization and domain shift. Ideally, a model would assign lower confidence to points unlike those from the training distribution. We propose a regularizer which addresses this issue by training with interpolated hidden states and encouraging the classifier to be less confident at these points. Because the hidden states are learned, this has an important effect of encouraging the hidden states for a class to be concentrated in such a way so that interpolations within the same class or between two different classes do not intersect with the real data points from other classes. This has a major advantage in that it avoids the underfitting which can result from interpolating in the input space. We prove that the exact condition for this problem of underfitting to be avoided by Manifold Mixup is that the dimensionality of the hidden states exceeds the number of classes, which is often the case in practice. Additionally, this concentration can be seen as making the features in earlier layers more discriminative. We show that despite requiring no significant additional computation, Manifold Mixup achieves large improvements over strong baselines in supervised learning, robustness to single-step adversarial attacks, semi-supervised learning, and Negative Log-Likelihood on held out samples.
Learning deep representations by mutual information estimation and maximization
Oct 03, 2018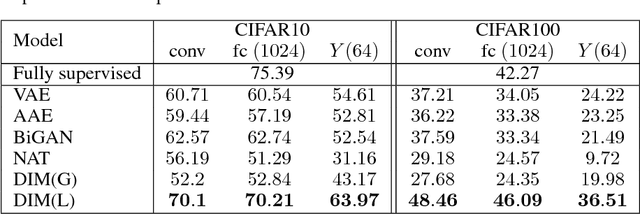
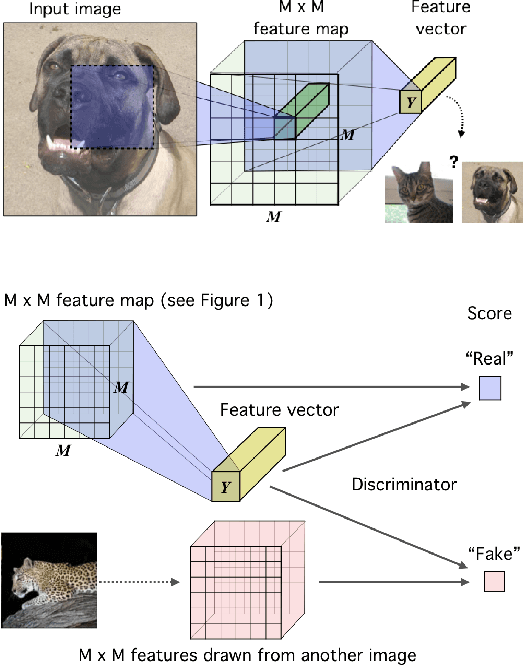
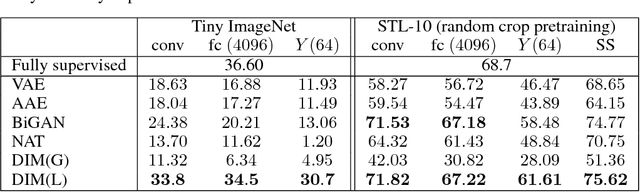
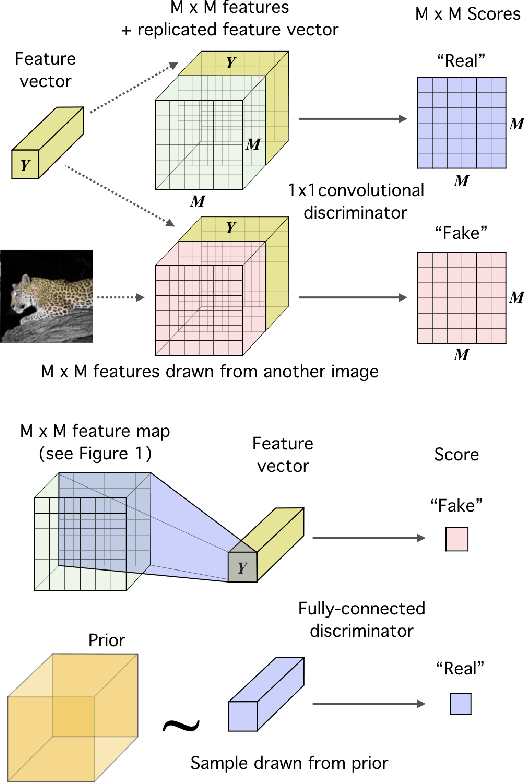
In this work, we perform unsupervised learning of representations by maximizing mutual information between an input and the output of a deep neural network encoder. Importantly, we show that structure matters: incorporating knowledge about locality of the input to the objective can greatly influence a representation's suitability for downstream tasks. We further control characteristics of the representation by matching to a prior distribution adversarially. Our method, which we call Deep InfoMax (DIM), outperforms a number of popular unsupervised learning methods and competes with fully-supervised learning on several classification tasks. DIM opens new avenues for unsupervised learning of representations and is an important step towards flexible formulations of representation-learning objectives for specific end-goals.
Towards Understanding Generalization via Analytical Learning Theory
Oct 01, 2018

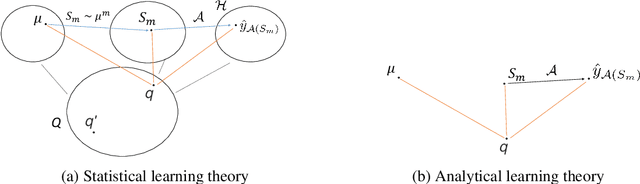
This paper introduces a novel measure-theoretic theory for machine learning that does not require statistical assumptions. Based on this theory, a new regularization method in deep learning is derived and shown to outperform previous methods in CIFAR-10, CIFAR-100, and SVHN. Moreover, the proposed theory provides a theoretical basis for a family of practically successful regularization methods in deep learning. We discuss several consequences of our results on one-shot learning, representation learning, deep learning, and curriculum learning. Unlike statistical learning theory, the proposed learning theory analyzes each problem instance individually via measure theory, rather than a set of problem instances via statistics. As a result, it provides different types of results and insights when compared to statistical learning theory.
Adversarial Domain Adaptation for Stable Brain-Machine Interfaces
Sep 28, 2018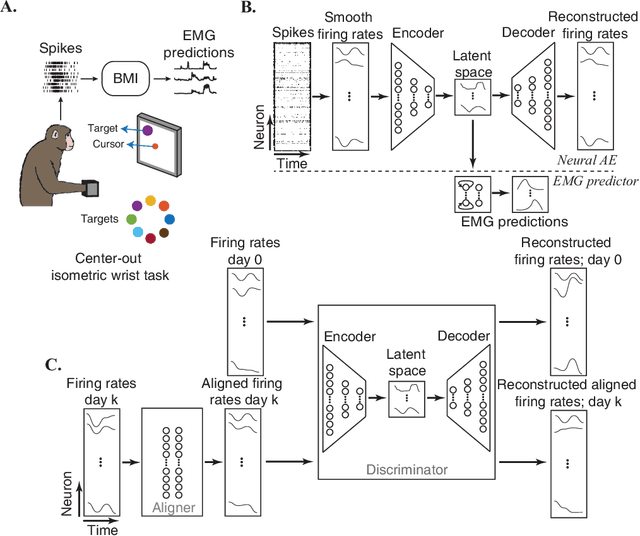
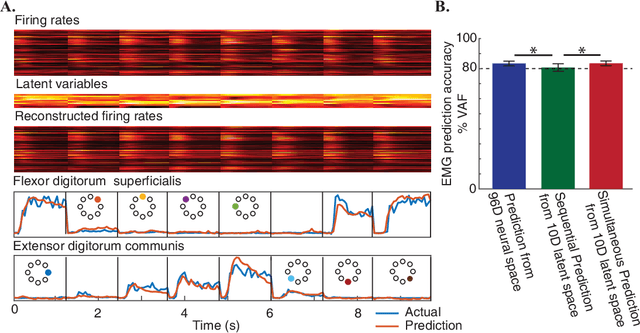
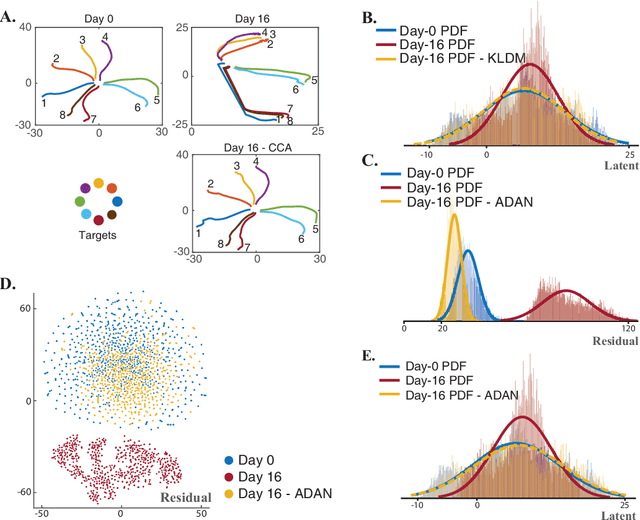
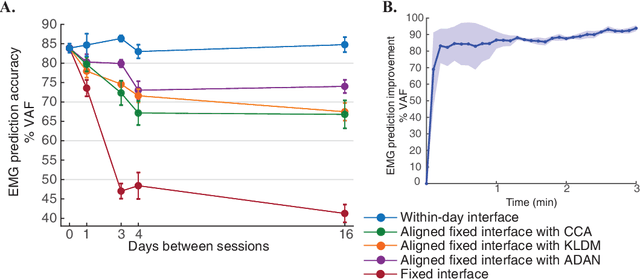
Brain-Machine Interfaces (BMIs) have recently emerged as a clinically viable option to restore voluntary movements after paralysis. These devices are based on the ability to extract information about movement intent from neural signals recorded using multi-electrode arrays chronically implanted in the motor cortices of the brain. However, the inherent loss and turnover of recorded neurons requires repeated recalibrations of the interface, which can potentially alter the day-to-day user experience. The resulting need for continued user adaptation interferes with the natural, subconscious use of the BMI. Here, we introduce a new computational approach that decodes movement intent from a low-dimensional latent representation of the neural data. We implement various domain adaptation methods to stabilize the interface over significantly long times. This includes Canonical Correlation Analysis used to align the latent variables across days; this method requires prior point-to-point correspondence of the time series across domains. Alternatively, we match the empirical probability distributions of the latent variables across days through the minimization of their Kullback-Leibler divergence. These two methods provide a significant and comparable improvement in the performance of the interface. However, implementation of an Adversarial Domain Adaptation Network trained to match the empirical probability distribution of the residuals of the reconstructed neural signals outperforms the two methods based on latent variables, while requiring remarkably few data points to solve the domain adaptation problem.
Deep Graph Infomax
Sep 27, 2018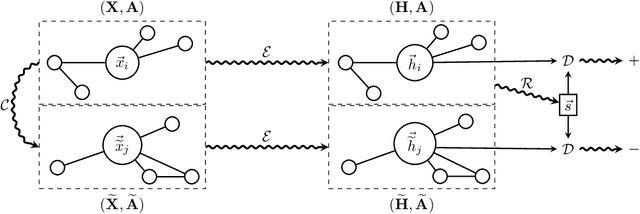
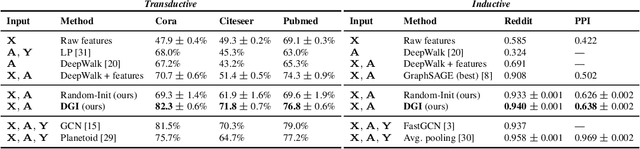
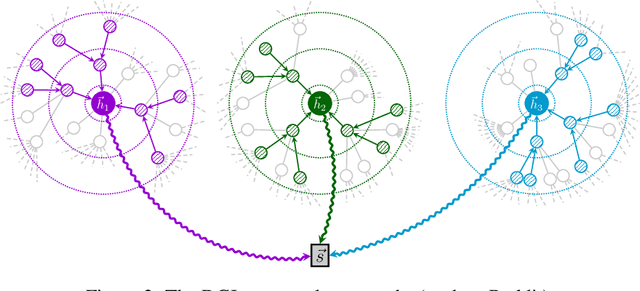

We present Deep Graph Infomax (DGI), a general approach for learning node representations within graph-structured data in an unsupervised manner. DGI relies on maximizing mutual information between patch representations and corresponding high-level summaries of graphs---both derived using established graph convolutional network architectures. The learnt patch representations summarize subgraphs centered around nodes of interest, and can thus be reused for downstream node-wise learning tasks. In contrast to most prior approaches to graph representation learning, DGI does not rely on random walks, and is readily applicable to both transductive and inductive learning setups. We demonstrate competitive performance on a variety of node classification benchmarks, which at times even exceeds the performance of supervised learning.
How can deep learning advance computational modeling of sensory information processing?
Sep 25, 2018Deep learning, computational neuroscience, and cognitive science have overlapping goals related to understanding intelligence such that perception and behaviour can be simulated in computational systems. In neuroimaging, machine learning methods have been used to test computational models of sensory information processing. Recently, these model comparison techniques have been used to evaluate deep neural networks (DNNs) as models of sensory information processing. However, the interpretation of such model evaluations is muddied by imprecise statistical conclusions. Here, we make explicit the types of conclusions that can be drawn from these existing model comparison techniques and how these conclusions change when the model in question is a DNN. We discuss how DNNs are amenable to new model comparison techniques that allow for stronger conclusions to be made about the computational mechanisms underlying sensory information processing.
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
Sep 25, 2018
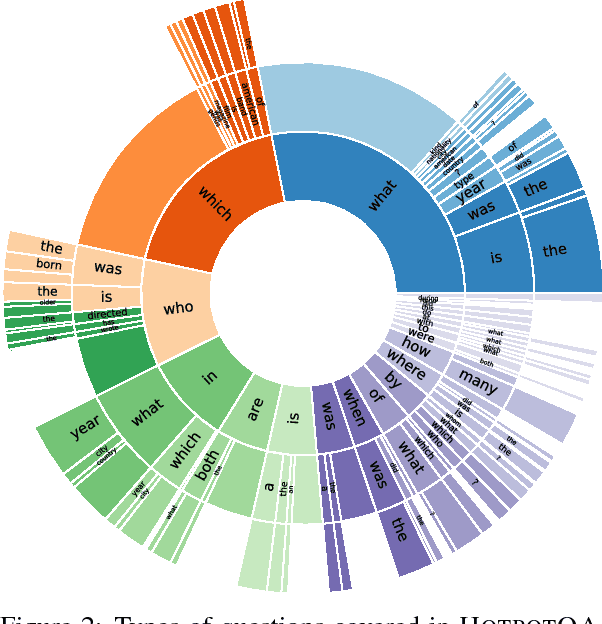
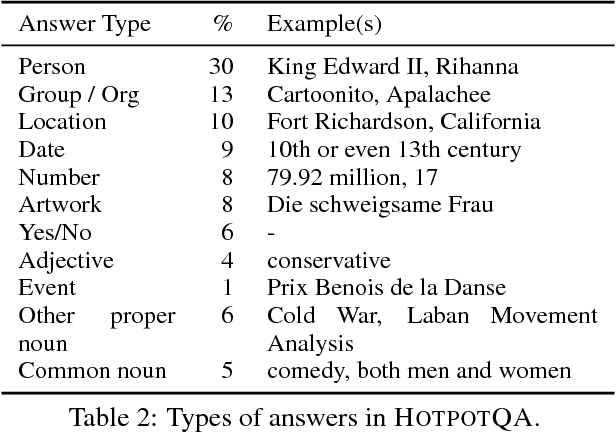
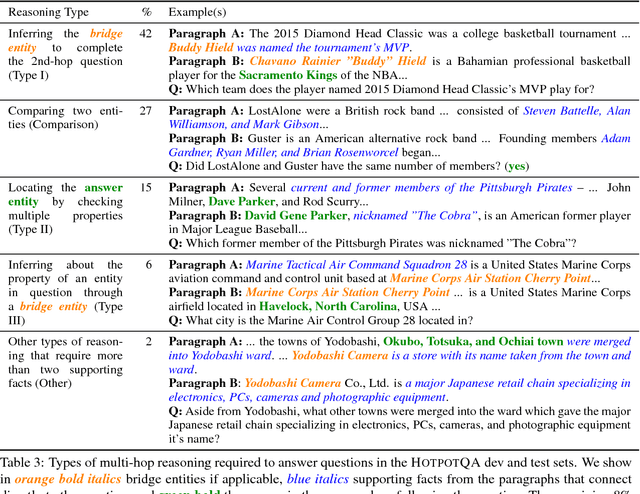
Existing question answering (QA) datasets fail to train QA systems to perform complex reasoning and provide explanations for answers. We introduce HotpotQA, a new dataset with 113k Wikipedia-based question-answer pairs with four key features: (1) the questions require finding and reasoning over multiple supporting documents to answer; (2) the questions are diverse and not constrained to any pre-existing knowledge bases or knowledge schemas; (3) we provide sentence-level supporting facts required for reasoning, allowing QA systems to reason with strong supervision and explain the predictions; (4) we offer a new type of factoid comparison questions to test QA systems' ability to extract relevant facts and perform necessary comparison. We show that HotpotQA is challenging for the latest QA systems, and the supporting facts enable models to improve performance and make explainable predictions.
On the Learning Dynamics of Deep Neural Networks
Sep 18, 2018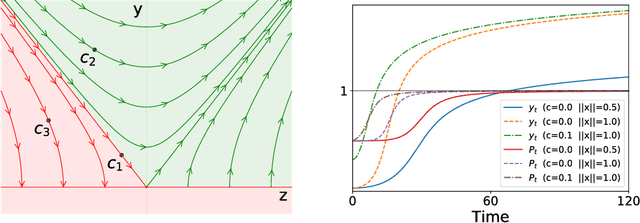
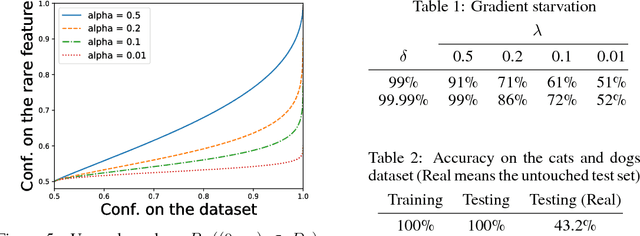
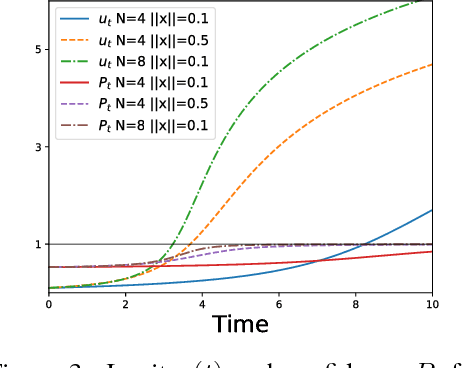
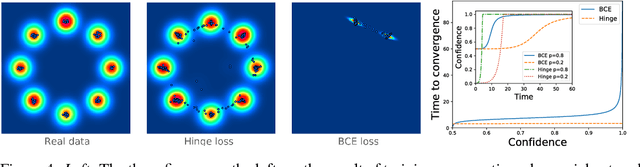
While a lot of progress has been made in recent years, the dynamics of learning in deep nonlinear neural networks remain to this day largely misunderstood. In this work, we study the case of binary classification and prove various properties of learning in such networks under strong assumptions such as linear separability of the data. Extending existing results from the linear case, we confirm empirical observations by proving that the classification error also follows a sigmoidal shape in nonlinear architectures. We show that given proper initialization, learning expounds parallel independent modes and that certain regions of parameter space might lead to failed training. We also demonstrate that input norm and features' frequency in the dataset lead to distinct convergence speeds which might shed some light on the generalization capabilities of deep neural networks. We provide a comparison between the dynamics of learning with cross-entropy and hinge losses, which could prove useful to understand recent progress in the training of generative adversarial networks. Finally, we identify a phenomenon that we baptize gradient starvation where the most frequent features in a dataset prevent the learning of other less frequent but equally informative features.