 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Flow Networks for Discrete Probabilistic Modeling
Feb 03, 2022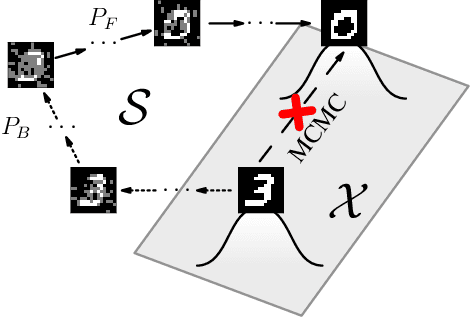
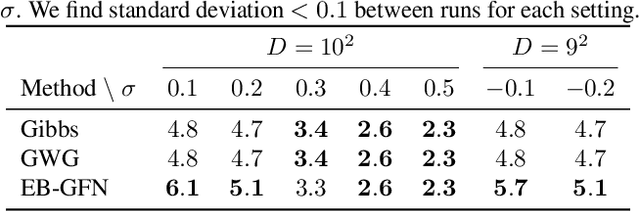
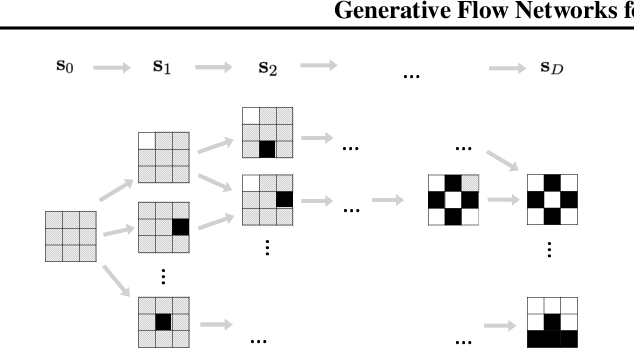
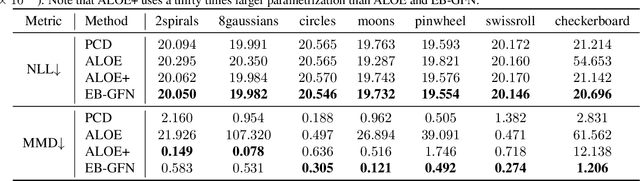
We present energy-based generative flow networks (EB-GFN), a novel probabilistic modeling algorithm for high-dimensional discrete data. Building upon the theory of generative flow networks (GFlowNets), we model the generation process by a stochastic data construction policy and thus amortize expensive MCMC exploration into a fixed number of actions sampled from a GFlowNet. We show how GFlowNets can approximately perform large-block Gibbs sampling to mix between modes. We propose a framework to jointly train a GFlowNet with an energy function, so that the GFlowNet learns to sample from the energy distribution, while the energy learns with an approximate MLE objective with negative samples from the GFlowNet. We demonstrate EB-GFN's effectiveness on various probabilistic modeling tasks.
Adaptive Discrete Communication Bottlenecks with Dynamic Vector Quantization
Feb 02, 2022



Vector Quantization (VQ) is a method for discretizing latent representations and has become a major part of the deep learning toolkit. It has been theoretically and empirically shown that discretization of representations leads to improved generalization, including in reinforcement learning where discretization can be used to bottleneck multi-agent communication to promote agent specialization and robustness. The discretization tightness of most VQ-based methods is defined by the number of discrete codes in the representation vector and the codebook size, which are fixed as hyperparameters. In this work, we propose learning to dynamically select discretization tightness conditioned on inputs, based on the hypothesis that data naturally contains variations in complexity that call for different levels of representational coarseness. We show that dynamically varying tightness in communication bottlenecks can improve model performance on visual reasoning and reinforcement learning tasks.
Towards Scaling Difference Target Propagation by Learning Backprop Targets
Jan 31, 2022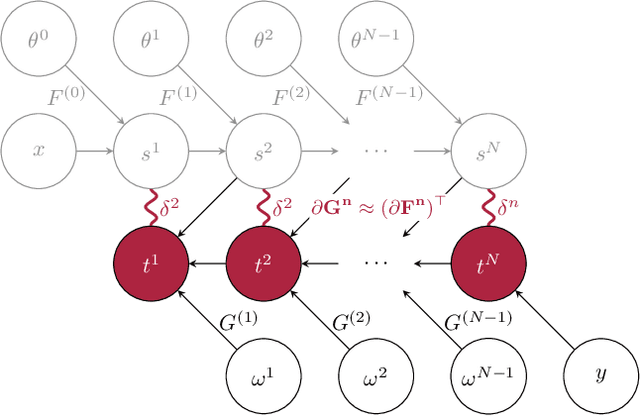


The development of biologically-plausible learning algorithms is important for understanding learning in the brain, but most of them fail to scale-up to real-world tasks, limiting their potential as explanations for learning by real brains. As such, it is important to explore learning algorithms that come with strong theoretical guarantees and can match the performance of backpropagation (BP) on complex tasks. One such algorithm is Difference Target Propagation (DTP), a biologically-plausible learning algorithm whose close relation with Gauss-Newton (GN) optimization has been recently established. However, the conditions under which this connection rigorously holds preclude layer-wise training of the feedback pathway synaptic weights (which is more biologically plausible). Moreover, good alignment between DTP weight updates and loss gradients is only loosely guaranteed and under very specific conditions for the architecture being trained. In this paper, we propose a novel feedback weight training scheme that ensures both that DTP approximates BP and that layer-wise feedback weight training can be restored without sacrificing any theoretical guarantees. Our theory is corroborated by experimental results and we report the best performance ever achieved by DTP on CIFAR-10 and ImageNet 32$\times$32
Trajectory Balance: Improved Credit Assignment in GFlowNets
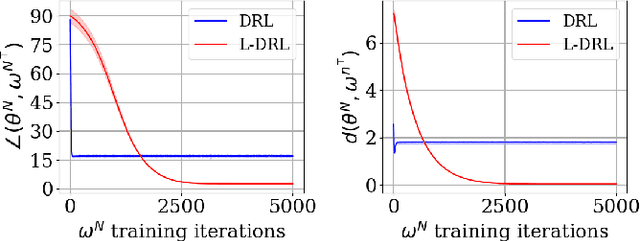
Jan 31, 2022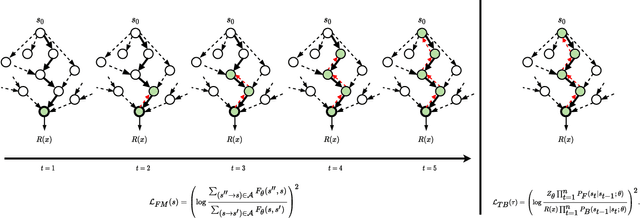
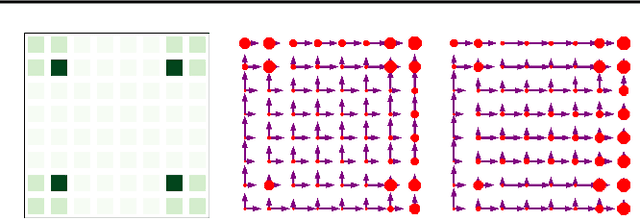

Generative Flow Networks (GFlowNets) are a method for learning a stochastic policy for generating compositional objects, such as graphs or strings, from a given unnormalized density by sequences of actions, where many possible action sequences may lead to the same object. Prior temporal difference-like learning objectives for training GFlowNets, such as flow matching and detailed balance, are prone to inefficient credit propagation across action sequences, particularly in the case of long sequences. We propose a new learning objective for GFlowNets, trajectory balance, as a more efficient alternative to previously used objectives. We prove that any global minimizer of the trajectory balance objective can define a policy that samples exactly from the target distribution. In experiments on four distinct domains, we empirically demonstrate the benefits of the trajectory balance objective for GFlowNet convergence, diversity of generated samples, and robustness to long action sequences and large action spaces.
Rethinking Learning Dynamics in RL using Adversarial Networks
Jan 27, 2022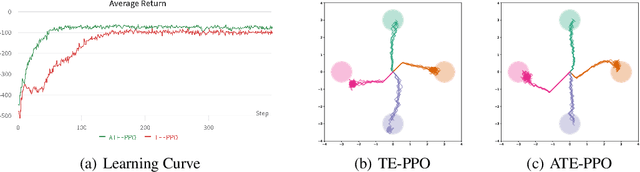

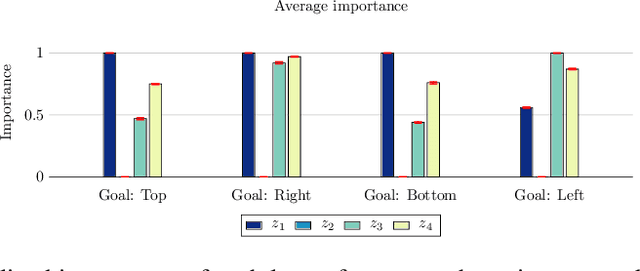

We present a learning mechanism for reinforcement learning of closely related skills parameterized via a skill embedding space. Our approach is grounded on the intuition that nothing makes you learn better than a coevolving adversary. The main contribution of our work is to formulate an adversarial training regime for reinforcement learning with the help of entropy-regularized policy gradient formulation. We also adapt existing measures of causal attribution to draw insights from the skills learned. Our experiments demonstrate that the adversarial process leads to a better exploration of multiple solutions and understanding the minimum number of different skills necessary to solve a given set of tasks.
The Effect of Diversity in Meta-Learning
Jan 27, 2022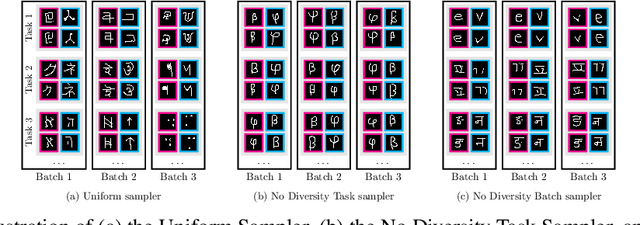
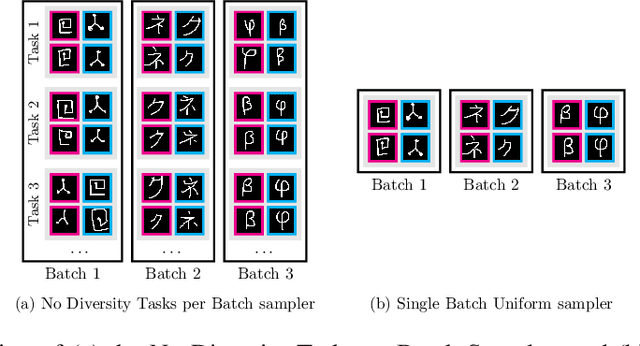
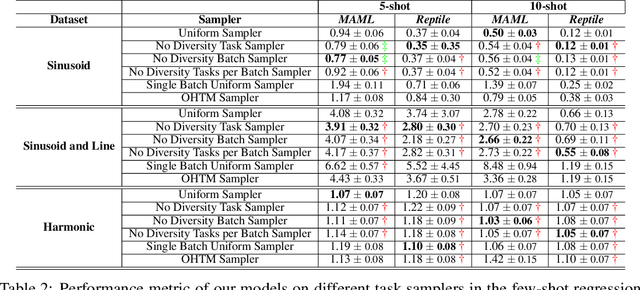
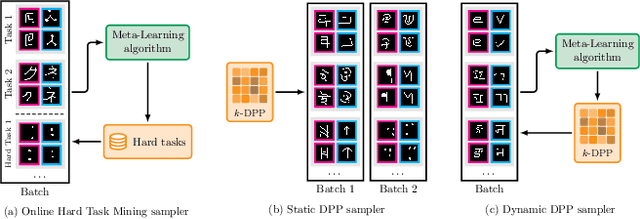
Few-shot learning aims to learn representations that can tackle novel tasks given a small number of examples. Recent studies show that task distribution plays a vital role in the model's performance. Conventional wisdom is that task diversity should improve the performance of meta-learning. In this work, we find evidence to the contrary; we study different task distributions on a myriad of models and datasets to evaluate the effect of task diversity on meta-learning algorithms. For this experiment, we train on multiple datasets, and with three broad classes of meta-learning models - Metric-based (i.e., Protonet, Matching Networks), Optimization-based (i.e., MAML, Reptile, and MetaOptNet), and Bayesian meta-learning models (i.e., CNAPs). Our experiments demonstrate that the effect of task diversity on all these algorithms follows a similar trend, and task diversity does not seem to offer any benefits to the learning of the model. Furthermore, we also demonstrate that even a handful of tasks, repeated over multiple batches, would be sufficient to achieve a performance similar to uniform sampling and draws into question the need for additional tasks to create better models.
Multi-Domain Balanced Sampling Improves Out-of-Distribution Generalization of Chest X-ray Pathology Prediction Models
Dec 28, 2021
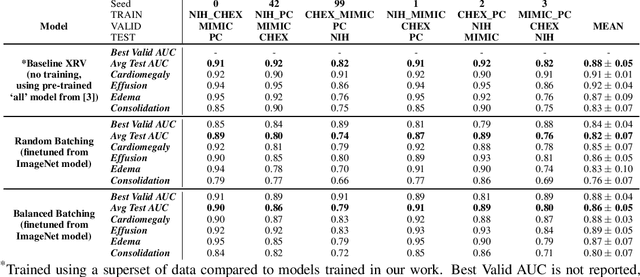
Learning models that generalize under different distribution shifts in medical imaging has been a long-standing research challenge. There have been several proposals for efficient and robust visual representation learning among vision research practitioners, especially in the sensitive and critical biomedical domain. In this paper, we propose an idea for out-of-distribution generalization of chest X-ray pathologies that uses a simple balanced batch sampling technique. We observed that balanced sampling between the multiple training datasets improves the performance over baseline models trained without balancing.
Multi-scale Feature Learning Dynamics: Insights for Double Descent
Dec 06, 2021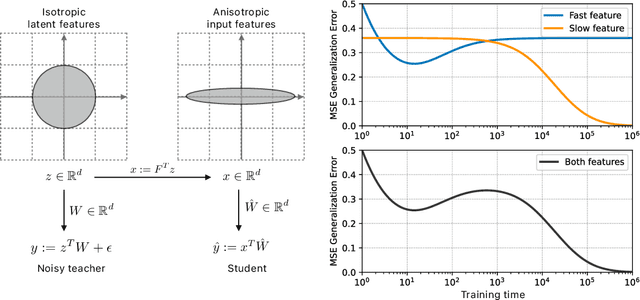
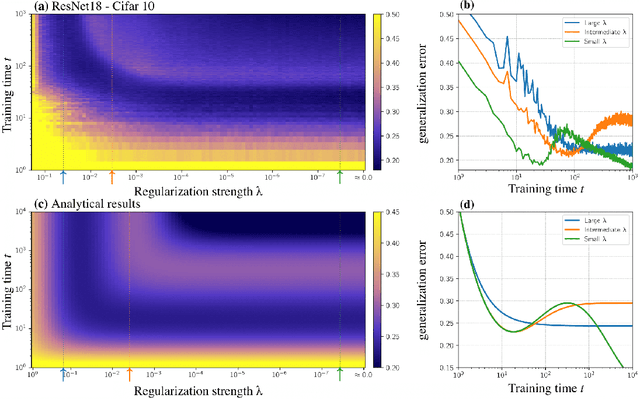
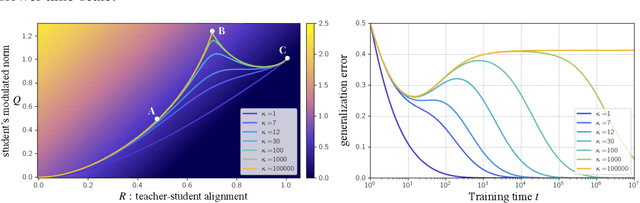
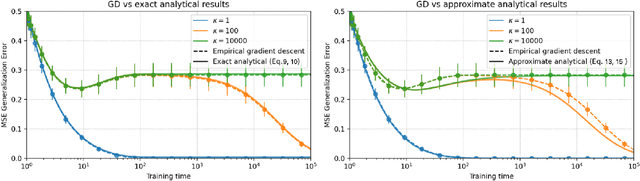
A key challenge in building theoretical foundations for deep learning is the complex optimization dynamics of neural networks, resulting from the high-dimensional interactions between the large number of network parameters. Such non-trivial dynamics lead to intriguing behaviors such as the phenomenon of "double descent" of the generalization error. The more commonly studied aspect of this phenomenon corresponds to model-wise double descent where the test error exhibits a second descent with increasing model complexity, beyond the classical U-shaped error curve. In this work, we investigate the origins of the less studied epoch-wise double descent in which the test error undergoes two non-monotonous transitions, or descents as the training time increases. By leveraging tools from statistical physics, we study a linear teacher-student setup exhibiting epoch-wise double descent similar to that in deep neural networks. In this setting, we derive closed-form analytical expressions for the evolution of generalization error over training. We find that double descent can be attributed to distinct features being learned at different scales: as fast-learning features overfit, slower-learning features start to fit, resulting in a second descent in test error. We validate our findings through numerical experiments where our theory accurately predicts empirical findings and remains consistent with observations in deep neural networks.
GFlowNet Foundations
Nov 17, 2021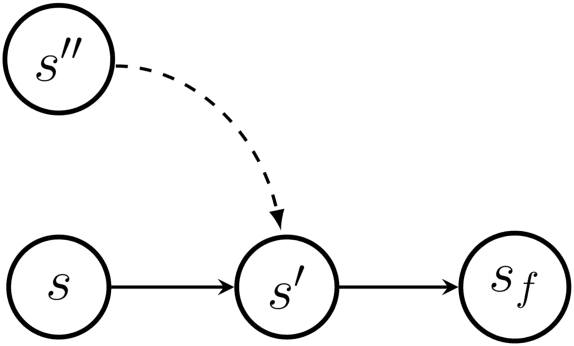
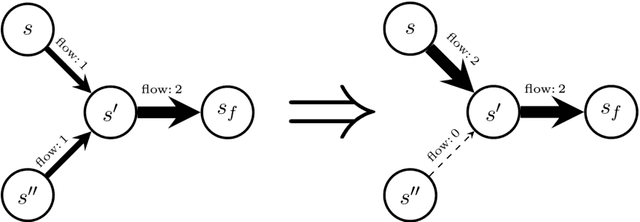
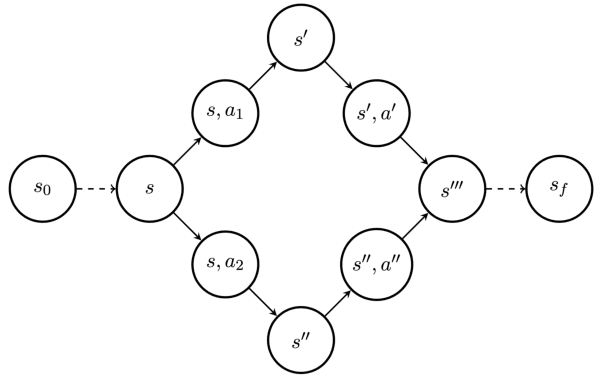
Generative Flow Networks (GFlowNets) have been introduced as a method to sample a diverse set of candidates in an active learning context, with a training objective that makes them approximately sample in proportion to a given reward function. In this paper, we show a number of additional theoretical properties of GFlowNets. They can be used to estimate joint probability distributions and the corresponding marginal distributions where some variables are unspecified and, of particular interest, can represent distributions over composite objects like sets and graphs. GFlowNets amortize the work typically done by computationally expensive MCMC methods in a single but trained generative pass. They could also be used to estimate partition functions and free energies, conditional probabilities of supersets (supergraphs) given a subset (subgraph), as well as marginal distributions over all supersets (supergraphs) of a given set (graph). We introduce variations enabling the estimation of entropy and mutual information, sampling from a Pareto frontier, connections to reward-maximizing policies, and extensions to stochastic environments, continuous actions and modular energy functions.
Properties from Mechanisms: An Equivariance Perspective on Identifiable Representation Learning
Oct 29, 2021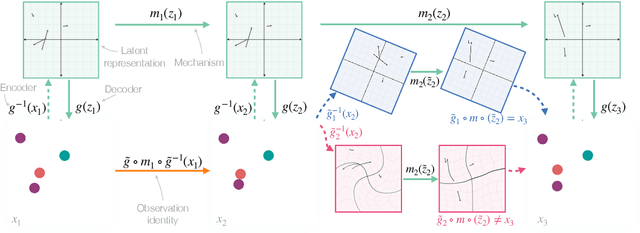

A key goal of unsupervised representation learning is "inverting" a data generating process to recover its latent properties. Existing work that provably achieves this goal relies on strong assumptions on relationships between the latent variables (e.g., independence conditional on auxiliary information). In this paper, we take a very different perspective on the problem and ask, "Can we instead identify latent properties by leveraging knowledge of the mechanisms that govern their evolution?" We provide a complete characterization of the sources of non-identifiability as we vary knowledge about a set of possible mechanisms. In particular, we prove that if we know the exact mechanisms under which the latent properties evolve, then identification can be achieved up to any equivariances that are shared by the underlying mechanisms. We generalize this characterization to settings where we only know some hypothesis class over possible mechanisms, as well as settings where the mechanisms are stochastic. We demonstrate the power of this mechanism-based perspective by showing that we can leverage our results to generalize existing identifiable representation learning results. These results suggest that by exploiting inductive biases on mechanisms, it is possible to design a range of new identifiable representation learning approaches.