 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData and Physics Driven Learning Models for Fast MRI -- Fundamentals and Methodologies from CNN, GAN to Attention and Transformers
Apr 01, 2022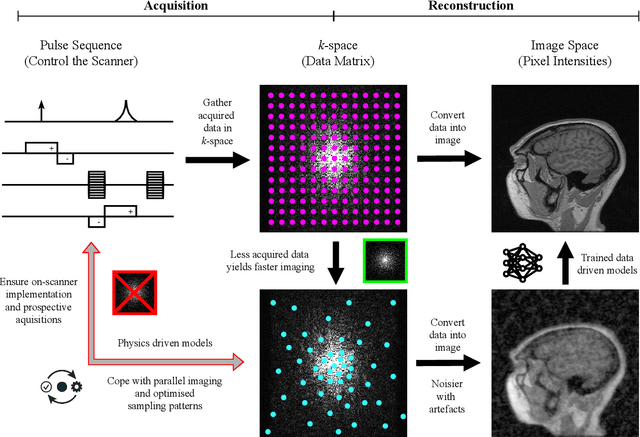
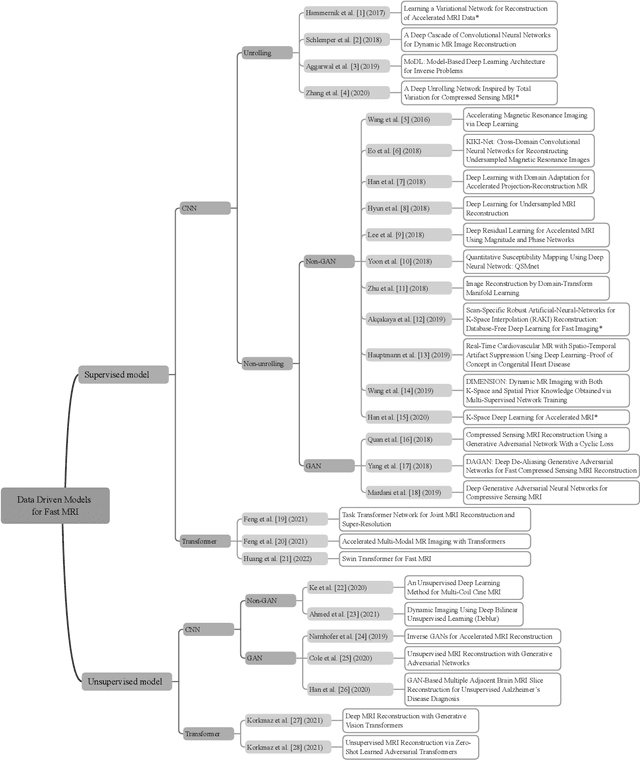
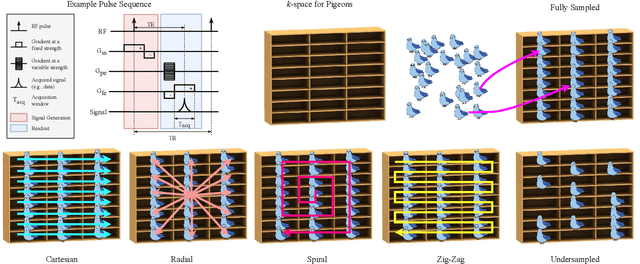
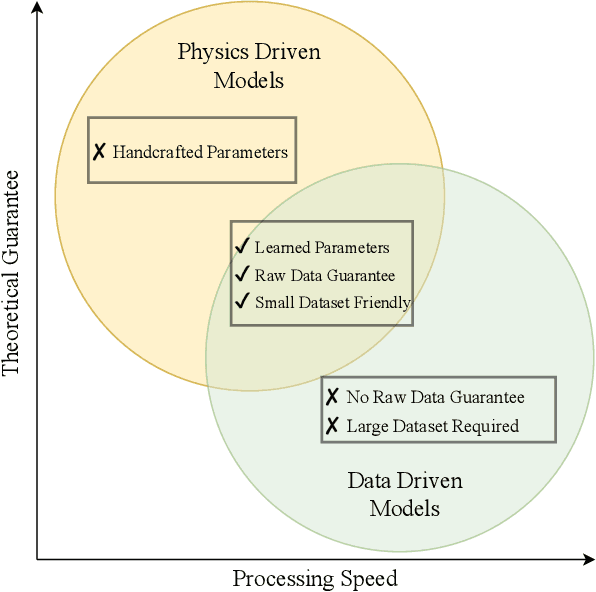
Research studies have shown no qualms about using data driven deep learning models for downstream tasks in medical image analysis, e.g., anatomy segmentation and lesion detection, disease diagnosis and prognosis, and treatment planning. However, deep learning models are not the sovereign remedy for medical image analysis when the upstream imaging is not being conducted properly (with artefacts). This has been manifested in MRI studies, where the scanning is typically slow, prone to motion artefacts, with a relatively low signal to noise ratio, and poor spatial and/or temporal resolution. Recent studies have witnessed substantial growth in the development of deep learning techniques for propelling fast MRI. This article aims to (1) introduce the deep learning based data driven techniques for fast MRI including convolutional neural network and generative adversarial network based methods, (2) survey the attention and transformer based models for speeding up MRI reconstruction, and (3) detail the research in coupling physics and data driven models for MRI acceleration. Finally, we will demonstrate through a few clinical applications, explain the importance of data harmonisation and explainable models for such fast MRI techniques in multicentre and multi-scanner studies, and discuss common pitfalls in current research and recommendations for future research directions.
Online Meta-Learning For Hybrid Model-Based Deep Receivers
Mar 27, 2022
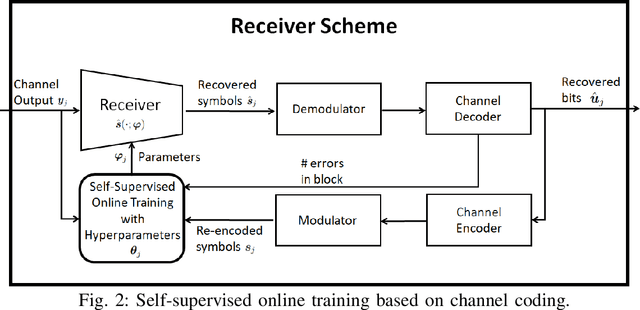
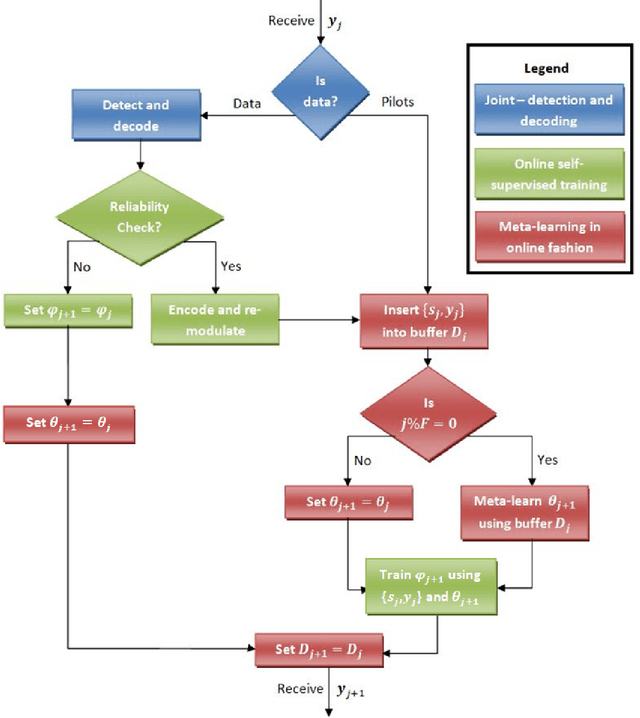
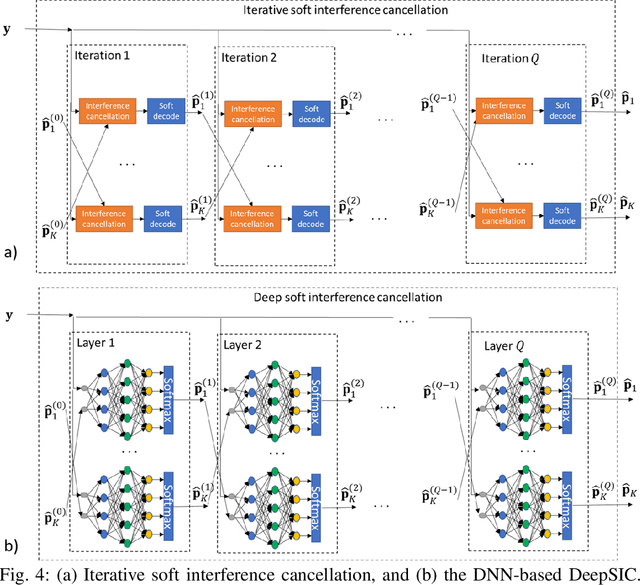
Recent years have witnessed growing interest in the application of deep neural networks (DNNs) for receiver design, which can potentially be applied in complex environments without relying on knowledge of the channel model. However, the dynamic nature of communication channels often leads to rapid distribution shifts, which may require periodically retraining. This paper formulates a data-efficient two-stage training method that facilitates rapid online adaptation. Our training mechanism uses a predictive meta-learning scheme to train rapidly from data corresponding to both current and past channel realizations. Our method is applicable to any deep neural network (DNN)-based receiver, and does not require transmission of new pilot data for training. To illustrate the proposed approach, we study DNN-aided receivers that utilize an interpretable model-based architecture, and introduce a modular training strategy based on predictive meta-learning. We demonstrate our techniques in simulations on a synthetic linear channel, a synthetic non-linear channel, and a COST 2100 channel. Our results demonstrate that the proposed online training scheme allows receivers to outperform previous techniques based on self-supervision and joint-learning by a margin of up to 2.5 dB in coded bit error rate in rapidly-varying scenarios.
6G Wireless Communications: From Far-field Beam Steering to Near-field Beam Focusing
Mar 24, 2022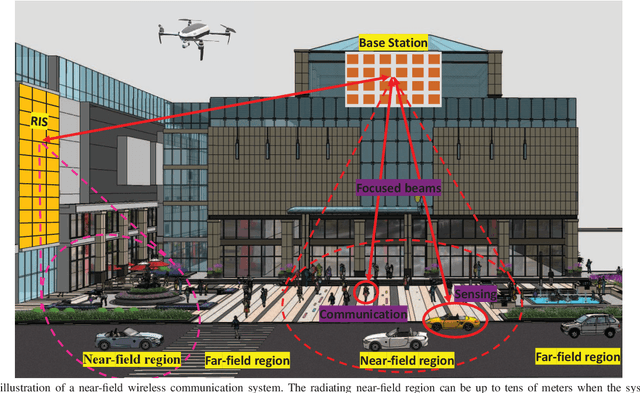
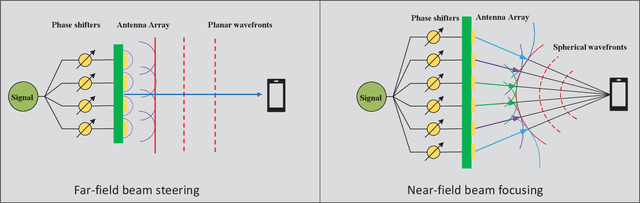
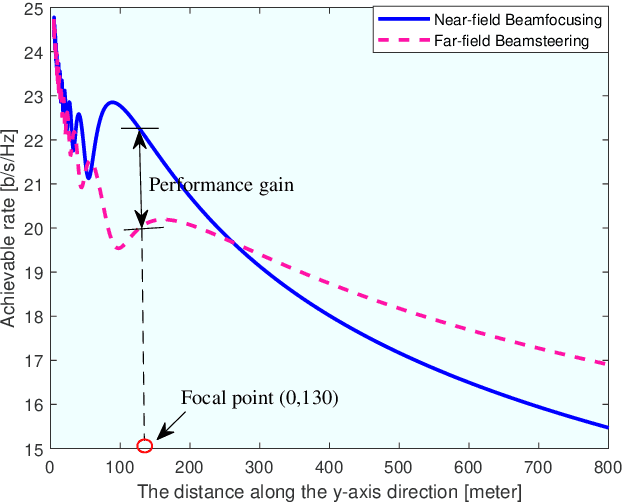
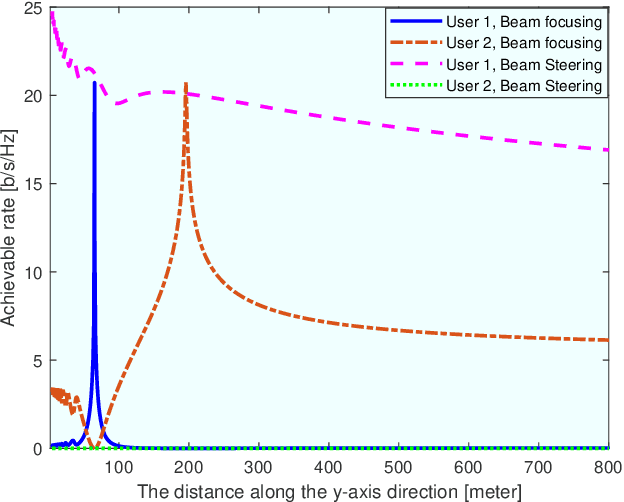
6G networks will be required to support higher data rates, improved energy efficiency, lower latency, and more diverse users compared with 5G systems. To meet these requirements, extremely large antenna arrays and high-frequency signaling are envisioned to be key physical-layer technologies. The deployment of extremely large antenna arrays, especially in high-frequency bands, indicates that future 6G wireless networks are likely to operate in the radiating near-field (Fresnel) region, as opposed to the traditional far-field operation of current wireless technologies. In this article, we discuss the opportunities and challenges that arise in radiating near-field communications. We begin by discussing the key physical characteristics of near-field communications, where the standard plane-wave propagation assumption no longer holds, and clarify its implication on the modelling of wireless channels. Then, we elaborate on the ability to leverage spherical wavefronts via beam focusing, highlighting its advantages for 6G systems. We point out several appealing application scenarios which, with proper design, can benefit from near-field operation, including interference mitigation in multi-user communications, accurate localization and focused sensing, as well as wireless power transfer with minimal energy pollution. We conclude with discussing some of the design challenges and research directions that are yet to be explored to fully harness the potential of this emerging paradigm.
Transmit Precoder Design Approaches for Dual-Function Radar-Communication Systems
Mar 17, 2022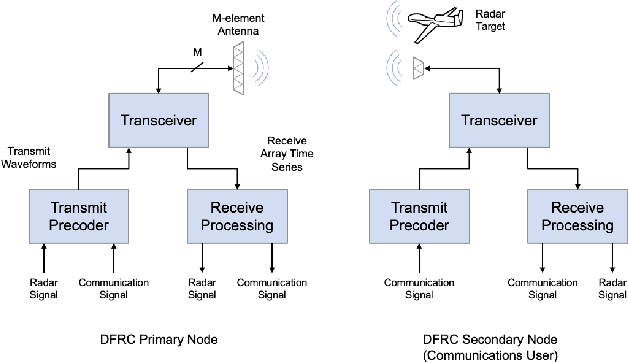
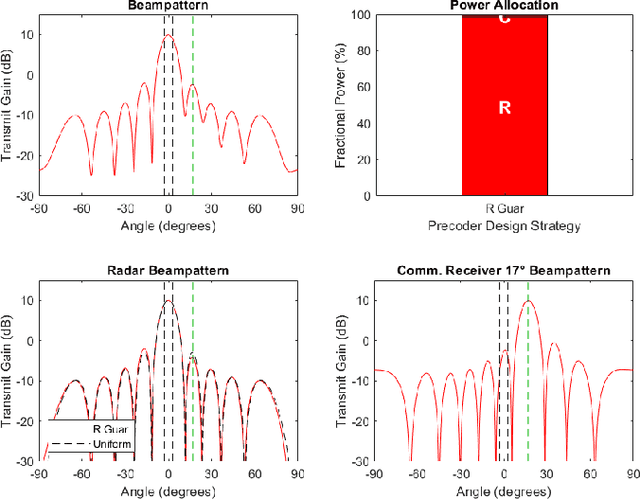
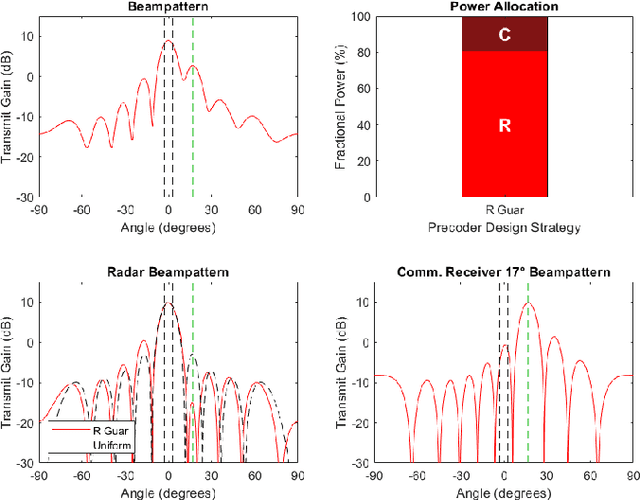
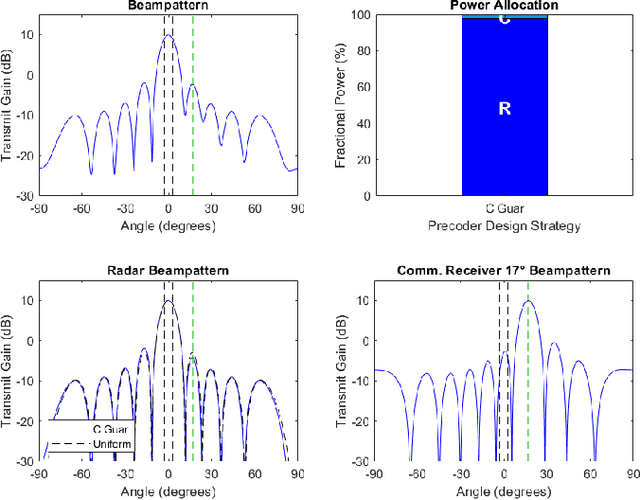
As radio-frequency (RF) antenna, component and processing capabilities increase, the ability to perform multiple RF system functions from a common aperture is being realized. Conducting both radar and communications from the same system is potentially useful in vehicular, health monitoring, and surveillance settings. This paper considers multiple-input-multiple-output (MIMO) dual-function radar-communication (DFRC) systems in which the radar and communication modes use distinct baseband waveforms. A transmit precoder provides spatial multiplexing and power allocation among the radar and communication modes. Multiple precoder design approaches are introduced for a radar detection mode in which a total search volume is divided into dwells to be searched sequentially. The approaches are designed to enforce a reliance on radar waveforms for sensing purposes, yielding improved approximation of desired ambiguity functions over prior methods found in the literature. The methods are also shown via simulation to enable design flexibility, allowing for prioritization of either subsystem and specification of a desired level of radar or communication performance.
Channel Estimation with Simultaneous Reflecting and Sensing Reconfigurable Intelligent Metasurfaces
Feb 11, 2022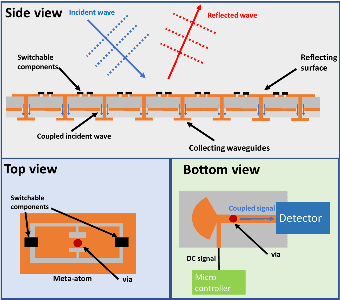
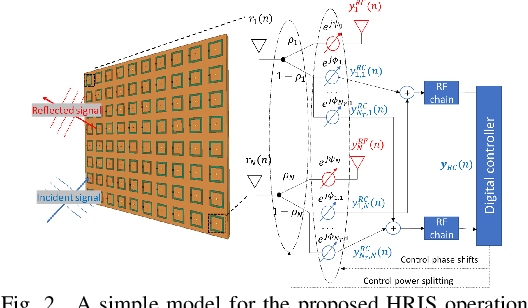
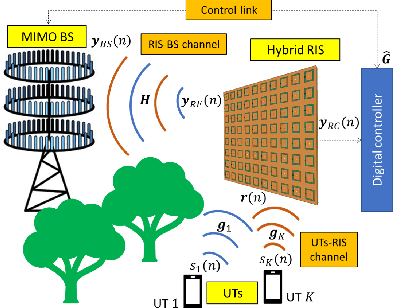
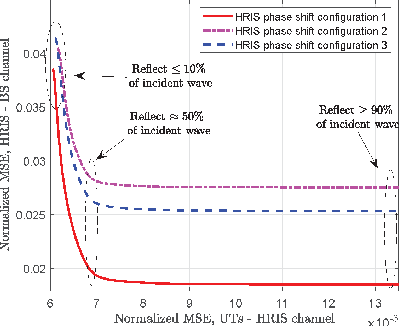
Reconfigurable Intelligent Surfaces (RISs) are envisioned to play a key role in future wireless communications, enabling programmable radio propagation environments. They are usually considered as nearly passive planar structures that operate as adjustable reflectors, giving rise to a multitude of implementation challenges, including an inherent difficulty in estimating the underlying wireless channels. In this paper, we propose the concept of Hybrid RISs (HRISs), which do not solely reflect the impinging waveform in a controllable fashion, but are also capable of sensing and processing a portion of it via some active reception elements. We first present implementation details for this novel metasurface architecture and propose a simple model for its operation, when considered for wireless communications. As an indicative application of HRISs, we formulate and solve the individual channels identification problem for the uplink of multi-user HRIS-empowered systems. Our numerical results showcase that, in the high signal-to-noise regime, HRISs enable individual channel estimation with notably reduced amounts of pilots, compared to those needed when using a purely reflective RIS that can only estimate the cascaded channel.
On the Acquisition of Stationary Signals Using Uniform ADCs
Feb 10, 2022
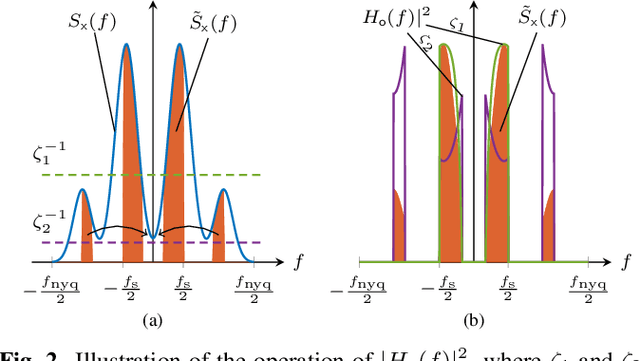
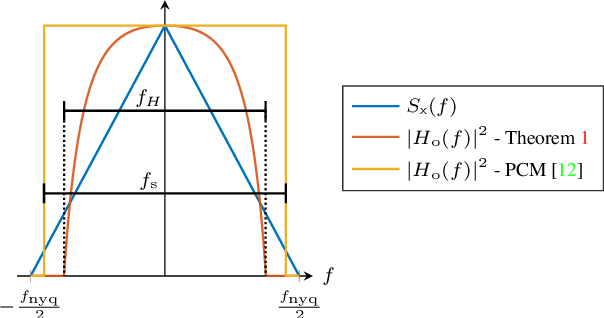
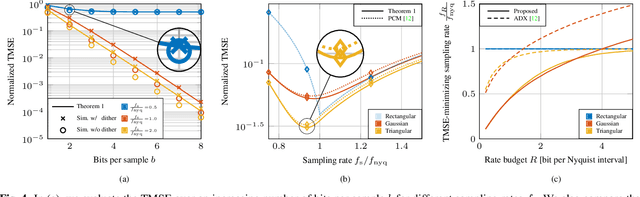
In this work, we consider the acquisition of stationary signals using uniform analog-to-digital converters (ADCs), i.e., employing uniform sampling and scalar uniform quantization. We jointly optimize the pre-sampling and reconstruction filters to minimize the time-averaged mean-squared error (TMSE) in recovering the continuous-time input signal for a fixed sampling rate and quantizer resolution and obtain closed-form expressions for the minimal achievable TMSE. We show that the TMSE-minimizing pre-sampling filter omits aliasing and discards weak frequency components to resolve the remaining ones with higher resolution when the rate budget is small. In our numerical study, we validate our results and show that sub-Nyquist sampling often minimizes the TMSE under tight rate budgets at the output of the ADC.
Deep Task-Based Analog-to-Digital Conversion
Jan 29, 2022Analog-to-digital converters (ADCs) allow physical signals to be processed using digital hardware. Their conversion consists of two stages: Sampling, which maps a continuous-time signal into discrete-time, and quantization, i.e., representing the continuous-amplitude quantities using a finite number of bits. ADCs typically implement generic uniform conversion mappings that are ignorant of the task for which the signal is acquired, and can be costly when operating in high rates and fine resolutions. In this work we design task-oriented ADCs which learn from data how to map an analog signal into a digital representation such that the system task can be efficiently carried out. We propose a model for sampling and quantization that facilitates the learning of non-uniform mappings from data. Based on this learnable ADC mapping, we present a mechanism for optimizing a hybrid acquisition system comprised of analog combining, tunable ADCs with fixed rates, and digital processing, by jointly learning its components end-to-end. Then, we show how one can exploit the representation of hybrid acquisition systems as deep network to optimize the sampling rate and quantization rate given the task by utilizing Bayesian meta-learning techniques. We evaluate the proposed deep task-based ADC in two case studies: the first considers symbol detection in multi-antenna digital receivers, where multiple analog signals are simultaneously acquired in order to recover a set of discrete information symbols. The second application is the beamforming of analog channel data acquired in ultrasound imaging. Our numerical results demonstrate that the proposed approach achieves performance which is comparable to operating with high sampling rates and fine resolution quantization, while operating with reduced overall bit rate.
Deep Proximal Learning for High-Resolution Plane Wave Compounding
Dec 23, 2021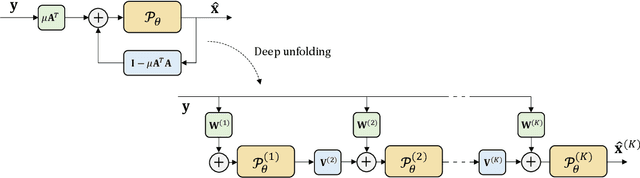
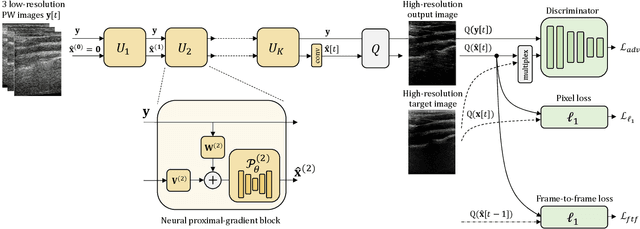
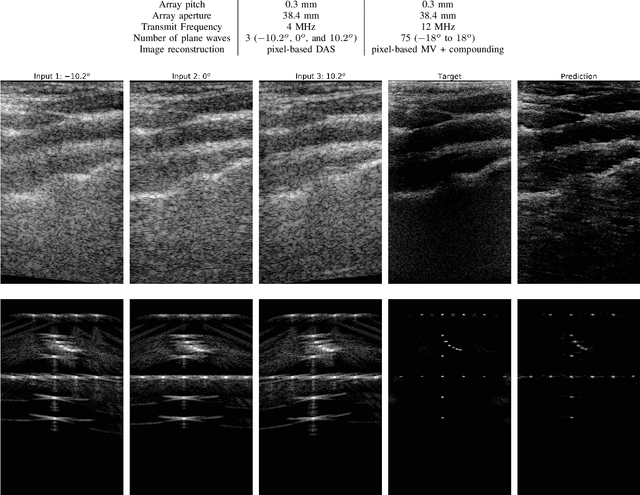
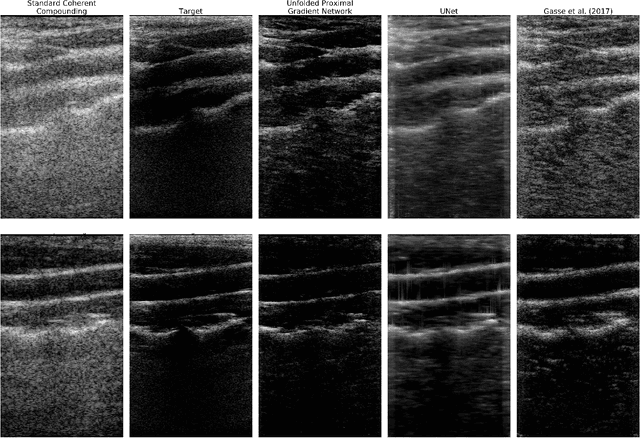
Plane Wave imaging enables many applications that require high frame rates, including localisation microscopy, shear wave elastography, and ultra-sensitive Doppler. To alleviate the degradation of image quality with respect to conventional focused acquisition, typically, multiple acquisitions from distinctly steered plane waves are coherently (i.e. after time-of-flight correction) compounded into a single image. This poses a trade-off between image quality and achievable frame-rate. To that end, we propose a new deep learning approach, derived by formulating plane wave compounding as a linear inverse problem, that attains high resolution, high-contrast images from just 3 plane wave transmissions. Our solution unfolds the iterations of a proximal gradient descent algorithm as a deep network, thereby directly exploiting the physics-based generative acquisition model into the neural network design. We train our network in a greedy manner, i.e. layer-by-layer, using a combination of pixel, temporal, and distribution (adversarial) losses to achieve both perceptual fidelity and data consistency. Through the strong model-based inductive bias, the proposed architecture outperforms several standard benchmark architectures in terms of image quality, with a low computational and memory footprint.
Two-Timescale End-to-End Learning for Channel Acquisition and Hybrid Precoding
Oct 26, 2021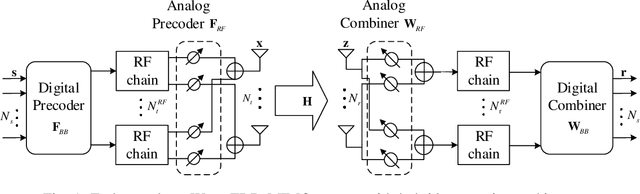

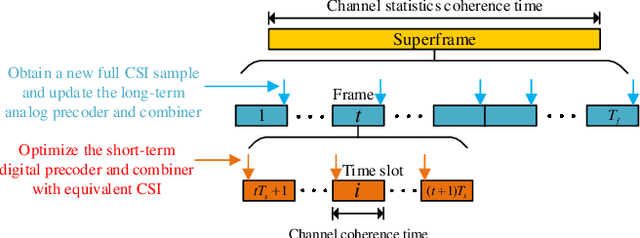
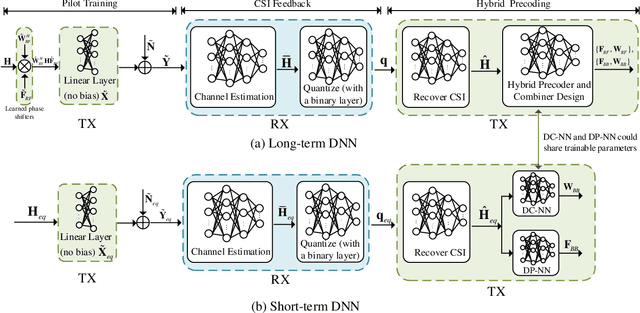
In this paper, we propose an end-to-end deep learning-based joint transceiver design algorithm for millimeter wave (mmWave) massive multiple-input multiple-output (MIMO) systems, which consists of deep neural network (DNN)-aided pilot training, channel feedback, and hybrid analog-digital (HAD) precoding. Specifically, we develop a DNN architecture that maps the received pilots into feedback bits at the receiver, and then further maps the feedback bits into the hybrid precoder at the transmitter. To reduce the signaling overhead and channel state information (CSI) mismatch caused by the transmission delay, a two-timescale DNN composed of a long-term DNN and a short-term DNN is developed. The analog precoders are designed by the long-term DNN based on the CSI statistics and updated once in a frame consisting of a number of time slots. In contrast, the digital precoders are optimized by the short-term DNN at each time slot based on the estimated low-dimensional equivalent CSI matrices. A two-timescale training method is also developed for the proposed DNN with a binary layer. We then analyze the generalization ability and signaling overhead for the proposed DNN based algorithm. Simulation results show that our proposed technique significantly outperforms conventional schemes in terms of bit-error rate performance with reduced signaling overhead and shorter pilot sequences.
Learning to Estimate Without Bias
Oct 24, 2021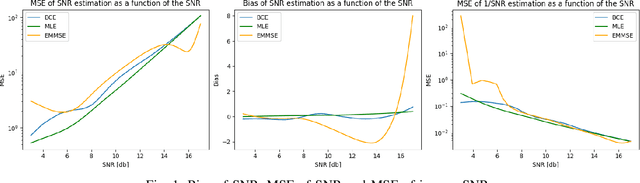
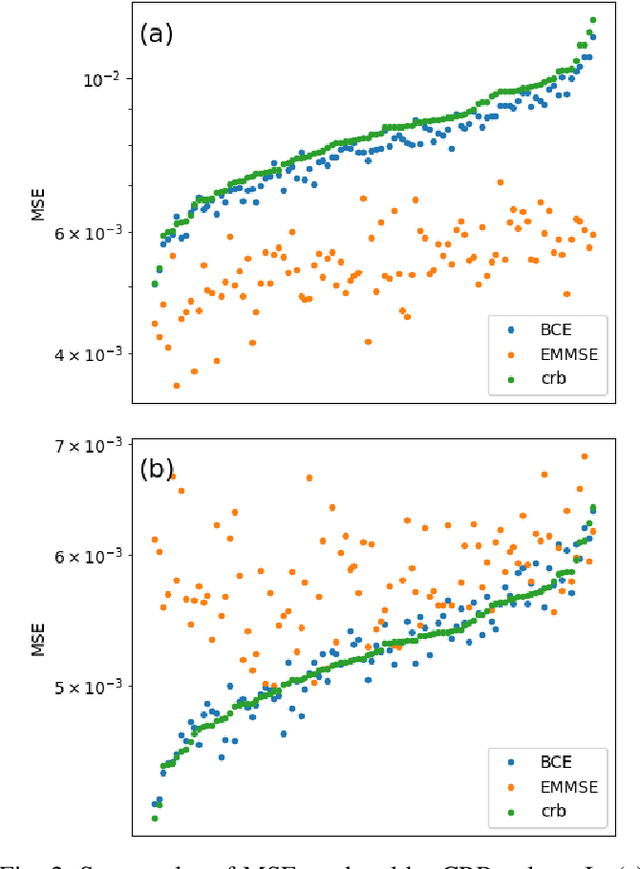
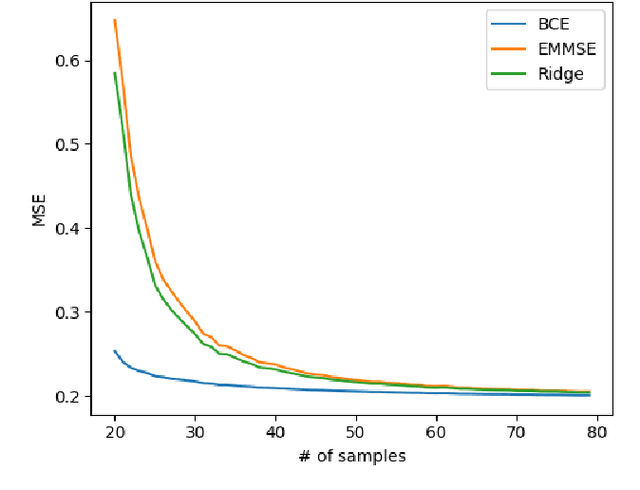
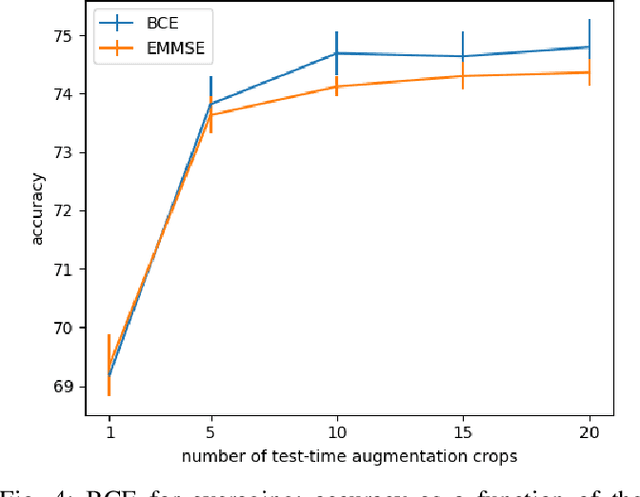
We consider the use of deep learning for parameter estimation. We propose Bias Constrained Estimators (BCE) that add a squared bias term to the standard mean squared error (MSE) loss. The main motivation to BCE is learning to estimate deterministic unknown parameters with no Bayesian prior. Unlike standard learning based estimators that are optimal on average, we prove that BCEs converge to Minimum Variance Unbiased Estimators (MVUEs). We derive closed form solutions to linear BCEs. These provide a flexible bridge between linear regrssion and the least squares method. In non-linear settings, we demonstrate that BCEs perform similarly to MVUEs even when the latter are computationally intractable. A second motivation to BCE is in applications where multiple estimates of the same unknown are averaged for improved performance. Examples include distributed sensor networks and data augmentation in test-time. In such applications, unbiasedness is a necessary condition for asymptotic consistency.