 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWiMamba: Linear-Scale Wireless Foundation Model
Mar 27, 2026Foundation models learn transferable representations, motivating growing interest in their application to wireless systems. Existing wireless foundation models are predominantly based on transformer architectures, whose quadratic computational and memory complexity can hinder practical deployment for large-scale channels. In this work, we introduce WiMamba, a wireless foundation model built upon the recently proposed Mamba architecture, which replaces attention mechanisms with selective state-space models and enables linear-time sequence modeling. Leveraging this architectural advantage combined with adaptive preprocessing, WiMamba achieves scalable and low-latency inference while maintaining strong representational expressivity. We further develop a dedicated task-agnostic, self-supervised pre-training framework tailored to wireless channels, resulting in a genuine foundation model that learns transferable channel representations. Evaluations across four downstream tasks demonstrate that WiMamba matches or outperforms transformer-based wireless foundation models, while offering dramatic latency and memory reductions.
In-Context Learning for Gradient-Free Receiver Adaptation: Principles, Applications, and Theory
Jun 18, 2025In recent years, deep learning has facilitated the creation of wireless receivers capable of functioning effectively in conditions that challenge traditional model-based designs. Leveraging programmable hardware architectures, deep learning-based receivers offer the potential to dynamically adapt to varying channel environments. However, current adaptation strategies, including joint training, hypernetwork-based methods, and meta-learning, either demonstrate limited flexibility or necessitate explicit optimization through gradient descent. This paper presents gradient-free adaptation techniques rooted in the emerging paradigm of in-context learning (ICL). We review architectural frameworks for ICL based on Transformer models and structured state-space models (SSMs), alongside theoretical insights into how sequence models effectively learn adaptation from contextual information. Further, we explore the application of ICL to cell-free massive MIMO networks, providing both theoretical analyses and empirical evidence. Our findings indicate that ICL represents a principled and efficient approach to real-time receiver adaptation using pilot signals and auxiliary contextual information-without requiring online retraining.
Modular Hypernetworks for Scalable and Adaptive Deep MIMO Receivers
Aug 21, 2024Deep neural networks (DNNs) were shown to facilitate the operation of uplink multiple-input multiple-output (MIMO) receivers, with emerging architectures augmenting modules of classic receiver processing. Current designs consider static DNNs, whose architecture is fixed and weights are pre-trained. This induces a notable challenge, as the resulting MIMO receiver is suitable for a given configuration, i.e., channel distribution and number of users, while in practice these parameters change frequently with network variations and users leaving and joining the network. In this work, we tackle this core challenge of DNN-aided MIMO receivers. We build upon the concept of hypernetworks, augmenting the receiver with a pre-trained deep model whose purpose is to update the weights of the DNN-aided receiver upon instantaneous channel variations. We design our hypernetwork to augment modular deep receivers, leveraging their modularity to have the hypernetwork adapt not only the weights, but also the architecture. Our modular hypernetwork leads to a DNN-aided receiver whose architecture and resulting complexity adapts to the number of users, in addition to channel variations, without retraining. Our numerical studies demonstrate superior error-rate performance of modular hypernetworks in time-varying channels compared to static pre-trained receivers, while providing rapid adaptivity and scalability to network variations.
Optimization of Iterative Blind Detection based on Expectation Maximization and Belief Propagation
Aug 05, 2024We study iterative blind symbol detection for block-fading linear inter-symbol interference channels. Based on the factor graph framework, we design a joint channel estimation and detection scheme that combines the expectation maximization (EM) algorithm and the ubiquitous belief propagation (BP) algorithm. Interweaving the iterations of both schemes significantly reduces the EM algorithm's computational burden while retaining its excellent performance. To this end, we apply simple yet effective model-based learning methods to find a suitable parameter update schedule by introducing momentum in both the EM parameter updates as well as in the BP message passing. Numerical simulations verify that the proposed method can learn efficient schedules that generalize well and even outperform coherent BP detection in high signal-to-noise scenarios.
Asynchronous Online Adaptation via Modular Drift Detection for Deep Receivers
Jul 12, 2024



Deep learning is envisioned to facilitate the operation of wireless receivers, with emerging architectures integrating deep neural networks (DNNs) with traditional modular receiver processing. While deep receivers were shown to operate reliably in complex settings for which they were trained, the dynamic nature of wireless communications gives rise to the need to repeatedly adapt deep receivers to channel variations. However, frequent re-training is costly and ineffective, while in practice, not every channel variation necessitates adaptation of the entire DNN. In this paper, we study concept drift detection for identifying when does a deep receiver no longer match the channel, enabling asynchronous adaptation, i.e., re-training only when necessary. We identify existing drift detection schemes from the machine learning literature that can be adapted for deep receivers in dynamic channels, and propose a novel soft-output detection mechanism tailored to the communication domain. Moreover, for deep receivers that preserve conventional modular receiver processing, we design modular drift detection mechanisms, that simultaneously identify when and which sub-module to re-train. The provided numerical studies show that even in a rapidly time-varying scenarios, asynchronous adaptation via modular drift detection dramatically reduces the number of trained parameters and re-training times, with little compromise on performance.
Blind Channel Estimation and Joint Symbol Detection with Data-Driven Factor Graphs
Jan 23, 2024We investigate the application of the factor graph framework for blind joint channel estimation and symbol detection on time-variant linear inter-symbol interference channels. In particular, we consider the expectation maximization (EM) algorithm for maximum likelihood estimation, which typically suffers from high complexity as it requires the computation of the symbol-wise posterior distributions in every iteration. We address this issue by efficiently approximating the posteriors using the belief propagation (BP) algorithm on a suitable factor graph. By interweaving the iterations of BP and EM, the detection complexity can be further reduced to a single BP iteration per EM step. In addition, we propose a data-driven version of our algorithm that introduces momentum in the BP updates and learns a suitable EM parameter update schedule, thereby significantly improving the performance-complexity tradeoff with a few offline training samples. Our numerical experiments demonstrate the excellent performance of the proposed blind detector and show that it even outperforms coherent BP detection in high signal-to-noise scenarios.
Modular Model-Based Bayesian Learning for Uncertainty-Aware and Reliable Deep MIMO Receivers
Feb 05, 2023



In the design of wireless receivers, DNNs can be combined with traditional model-based receiver algorithms to realize modular hybrid model-based/data-driven architectures that can account for domain knowledge. Such architectures typically include multiple modules, each carrying out a different functionality. Conventionally trained DNN-based modules are known to produce poorly calibrated, typically overconfident, decisions. This implies that an incorrect decision may propagate through the architecture without any indication of its insufficient accuracy. To address this problem, we present a novel combination of Bayesian learning with hybrid model-based/data-driven architectures for wireless receiver design. The proposed methodology, referred to as modular model-based Bayesian learning, results in better calibrated modules, improving accuracy and calibration of the overall receiver. We demonstrate this approach for the recently proposed DeepSIC MIMO receiver, showing significant improvements with respect to the state-of-the-art learning methods.
Online Meta-Learning For Hybrid Model-Based Deep Receivers
Mar 27, 2022
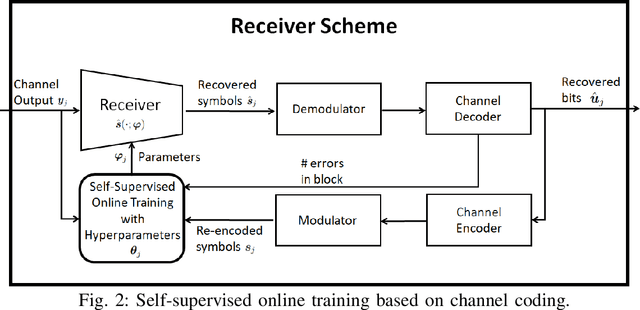
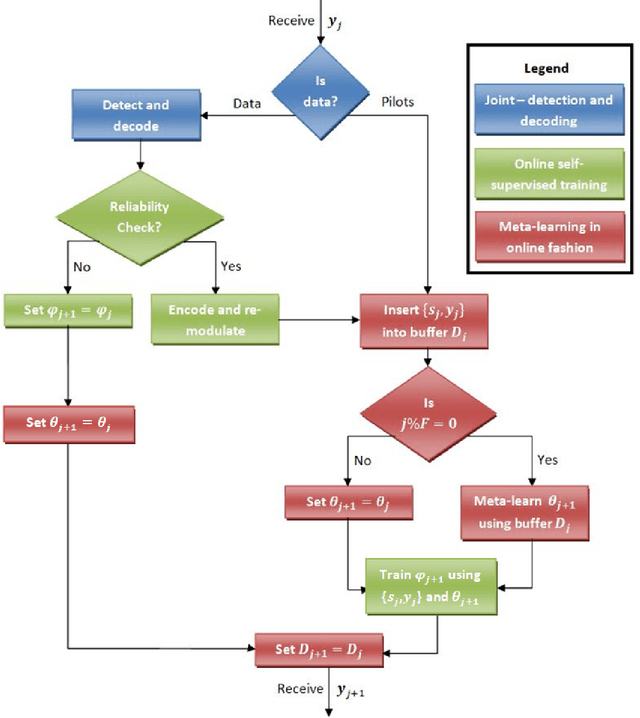
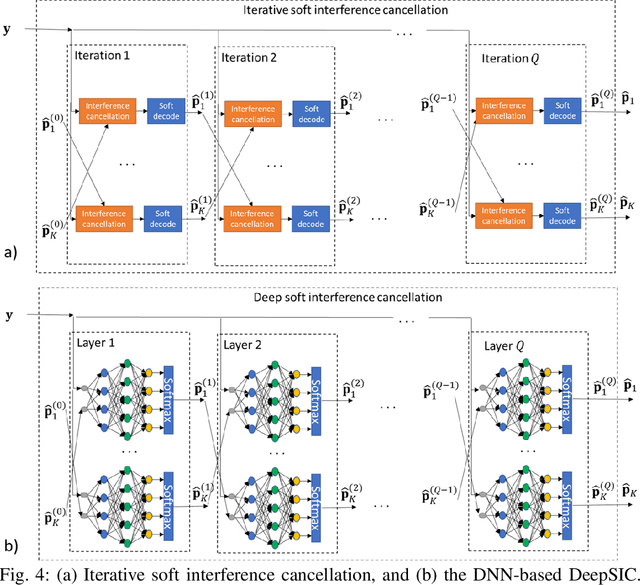
Recent years have witnessed growing interest in the application of deep neural networks (DNNs) for receiver design, which can potentially be applied in complex environments without relying on knowledge of the channel model. However, the dynamic nature of communication channels often leads to rapid distribution shifts, which may require periodically retraining. This paper formulates a data-efficient two-stage training method that facilitates rapid online adaptation. Our training mechanism uses a predictive meta-learning scheme to train rapidly from data corresponding to both current and past channel realizations. Our method is applicable to any deep neural network (DNN)-based receiver, and does not require transmission of new pilot data for training. To illustrate the proposed approach, we study DNN-aided receivers that utilize an interpretable model-based architecture, and introduce a modular training strategy based on predictive meta-learning. We demonstrate our techniques in simulations on a synthetic linear channel, a synthetic non-linear channel, and a COST 2100 channel. Our results demonstrate that the proposed online training scheme allows receivers to outperform previous techniques based on self-supervision and joint-learning by a margin of up to 2.5 dB in coded bit error rate in rapidly-varying scenarios.
Meta-ViterbiNet: Online Meta-Learned Viterbi Equalization for Non-Stationary Channels
Mar 24, 2021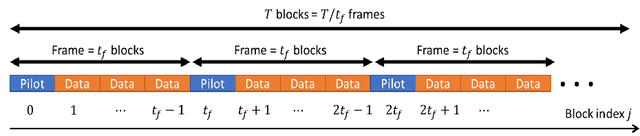
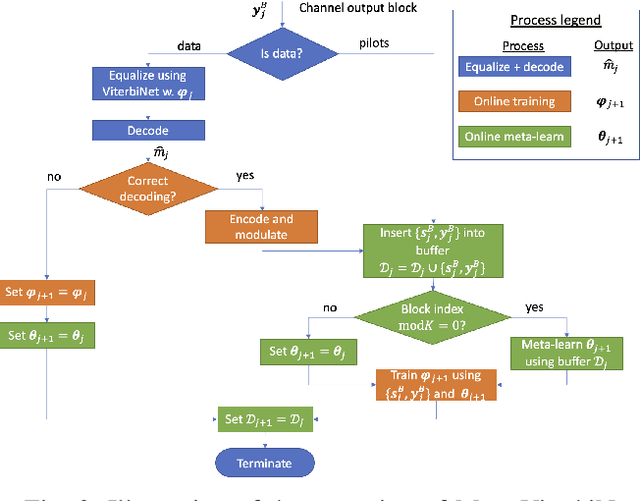
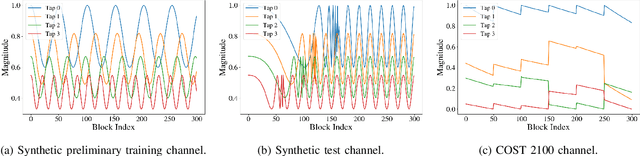
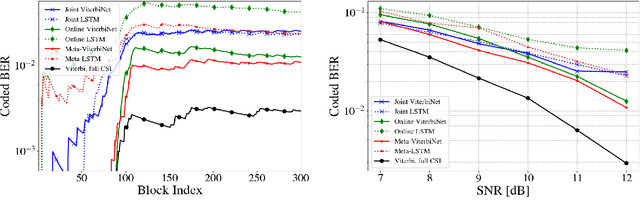
Deep neural networks (DNNs) based digital receivers can potentially operate in complex environments. However, the dynamic nature of communication channels implies that in some scenarios, DNN-based receivers should be periodically retrained in order to track temporal variations in the channel conditions. To this aim, frequent transmissions of lengthy pilot sequences are generally required, at the cost of substantial overhead. In this work we propose a DNN-aided symbol detector, Meta-ViterbiNet, that tracks channel variations with reduced overhead by integrating three complementary techniques: 1) We leverage domain knowledge to implement a model-based/data-driven equalizer, ViterbiNet, that operates with a relatively small number of trainable parameters; 2) We tailor a meta-learning procedure to the symbol detection problem, optimizing the hyperparameters of the learning algorithm to facilitate rapid online adaptation; and 3) We adopt a decision-directed approach based on coded communications to enable online training with short-length pilot blocks. Numerical results demonstrate that Meta-ViterbiNet operates accurately in rapidly-varying channels, outperforming the previous best approach, based on ViterbiNet or conventional recurrent neural networks without meta-learning, by a margin of up to 0.6dB in bit error rate in various challenging scenarios.
perm2vec: Graph Permutation Selection for Decoding of Error Correction Codes using Self-Attention
Feb 06, 2020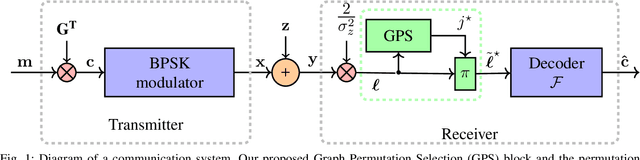
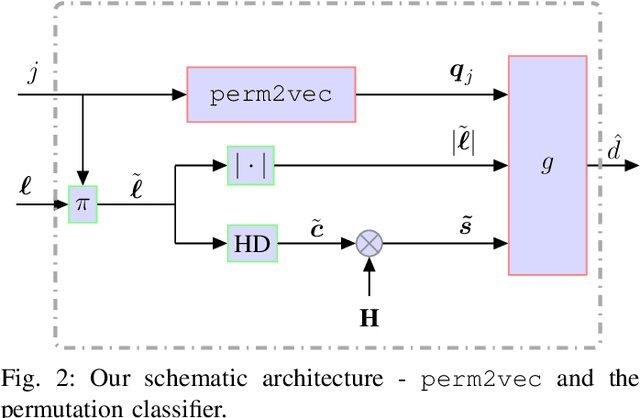
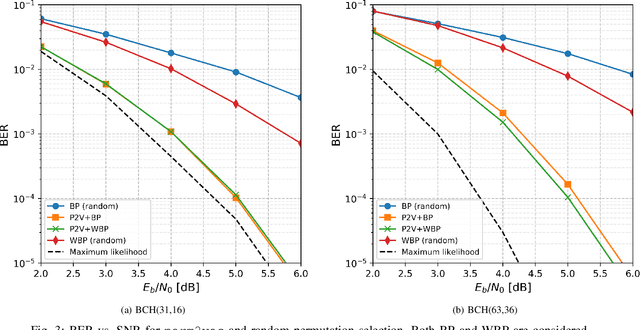
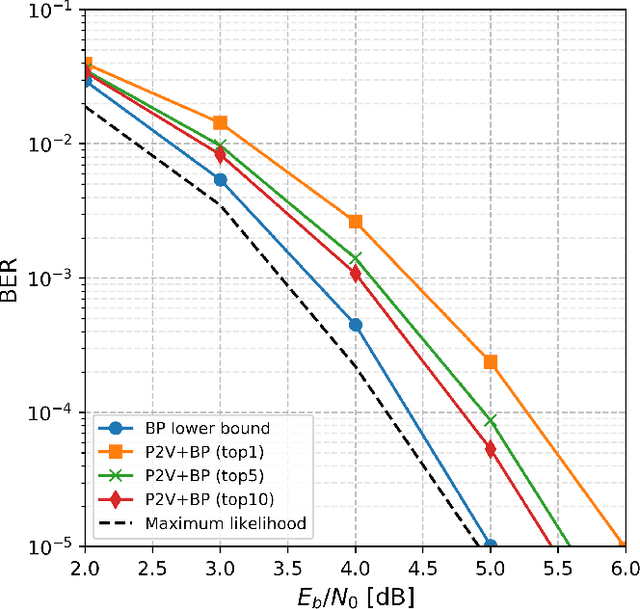
Error correction codes are integral part of communication applications, boosting the reliability of transmission. The optimal decoding of transmitted codewords is the maximum likelihood rule, which is NP-hard due to the curse of dimensionality. For practical realizations, suboptimal decoding algorithms are employed; yet limited theoretical insights prevents one from exploiting the full potential of these algorithms. One such insight is the choice of permutation in permutation decoding. We present a data-driven framework for permutation selection, combining domain knowledge with machine learning concepts such as node embedding and self-attention. Significant and consistent improvements in the bit error rate are introduced for all simulated codes, over the baseline decoders. To the best of the authors' knowledge, this work is the first to leverage the benefits of the neural Transformer networks in physical layer communication systems.