 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestart Sampling for Improving Generative Processes
Jun 26, 2023



Generative processes that involve solving differential equations, such as diffusion models, frequently necessitate balancing speed and quality. ODE-based samplers are fast but plateau in performance while SDE-based samplers deliver higher sample quality at the cost of increased sampling time. We attribute this difference to sampling errors: ODE-samplers involve smaller discretization errors while stochasticity in SDE contracts accumulated errors. Based on these findings, we propose a novel sampling algorithm called Restart in order to better balance discretization errors and contraction. The sampling method alternates between adding substantial noise in additional forward steps and strictly following a backward ODE. Empirically, Restart sampler surpasses previous SDE and ODE samplers in both speed and accuracy. Restart not only outperforms the previous best SDE results, but also accelerates the sampling speed by 10-fold / 2-fold on CIFAR-10 / ImageNet $64 \times 64$. In addition, it attains significantly better sample quality than ODE samplers within comparable sampling times. Moreover, Restart better balances text-image alignment/visual quality versus diversity than previous samplers in the large-scale text-to-image Stable Diffusion model pre-trained on LAION $512 \times 512$. Code is available at https://github.com/Newbeeer/diffusion_restart_sampling
StableRep: Synthetic Images from Text-to-Image Models Make Strong Visual Representation Learners
Jun 01, 2023We investigate the potential of learning visual representations using synthetic images generated by text-to-image models. This is a natural question in the light of the excellent performance of such models in generating high-quality images. We consider specifically the Stable Diffusion, one of the leading open source text-to-image models. We show that (1) when the generative model is configured with proper classifier-free guidance scale, training self-supervised methods on synthetic images can match or beat the real image counterpart; (2) by treating the multiple images generated from the same text prompt as positives for each other, we develop a multi-positive contrastive learning method, which we call StableRep. With solely synthetic images, the representations learned by StableRep surpass the performance of representations learned by SimCLR and CLIP using the same set of text prompts and corresponding real images, on large scale datasets. When we further add language supervision, StableRep trained with 20M synthetic images achieves better accuracy than CLIP trained with 50M real images.
Improving CLIP Training with Language Rewrites
May 31, 2023



Contrastive Language-Image Pre-training (CLIP) stands as one of the most effective and scalable methods for training transferable vision models using paired image and text data. CLIP models are trained using contrastive loss, which typically relies on data augmentations to prevent overfitting and shortcuts. However, in the CLIP training paradigm, data augmentations are exclusively applied to image inputs, while language inputs remain unchanged throughout the entire training process, limiting the exposure of diverse texts to the same image. In this paper, we introduce Language augmented CLIP (LaCLIP), a simple yet highly effective approach to enhance CLIP training through language rewrites. Leveraging the in-context learning capability of large language models, we rewrite the text descriptions associated with each image. These rewritten texts exhibit diversity in sentence structure and vocabulary while preserving the original key concepts and meanings. During training, LaCLIP randomly selects either the original texts or the rewritten versions as text augmentations for each image. Extensive experiments on CC3M, CC12M, RedCaps and LAION-400M datasets show that CLIP pre-training with language rewrites significantly improves the transfer performance without computation or memory overhead during training. Specifically for ImageNet zero-shot accuracy, LaCLIP outperforms CLIP by 8.2% on CC12M and 2.4% on LAION-400M. Code is available at https://github.com/LijieFan/LaCLIP.
PFGM++: Unlocking the Potential of Physics-Inspired Generative Models
Feb 10, 2023We introduce a new family of physics-inspired generative models termed PFGM++ that unifies diffusion models and Poisson Flow Generative Models (PFGM). These models realize generative trajectories for $N$ dimensional data by embedding paths in $N{+}D$ dimensional space while still controlling the progression with a simple scalar norm of the $D$ additional variables. The new models reduce to PFGM when $D{=}1$ and to diffusion models when $D{\to}\infty$. The flexibility of choosing $D$ allows us to trade off robustness against rigidity as increasing $D$ results in more concentrated coupling between the data and the additional variable norms. We dispense with the biased large batch field targets used in PFGM and instead provide an unbiased perturbation-based objective similar to diffusion models. To explore different choices of $D$, we provide a direct alignment method for transferring well-tuned hyperparameters from diffusion models ($D{\to} \infty$) to any finite $D$ values. Our experiments show that models with finite $D$ can be superior to previous state-of-the-art diffusion models on CIFAR-10/FFHQ $64{\times}64$ datasets, with FID scores of $1.91/2.43$ when $D{=}2048/128$. In class-conditional setting, $D{=}2048$ yields current state-of-the-art FID of $1.74$ on CIFAR-10. In addition, we demonstrate that models with smaller $D$ exhibit improved robustness against modeling errors. Code is available at https://github.com/Newbeeer/pfgmpp
Self-supervision through Random Segments with Autoregressive Coding (RandSAC)
Mar 22, 2022

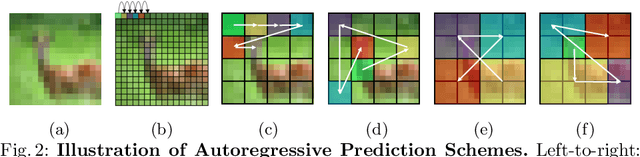

Inspired by the success of self-supervised autoregressive representation learning in natural language (GPT and its variants), and advances in recent visual architecture design with Vision Transformers (ViTs), in this paper, we explore the effects various design choices have on the success of applying such training strategies for visual feature learning. Specifically, we introduce a novel strategy that we call Random Segments with Autoregressive Coding (RandSAC). In RandSAC, we group patch representations (image tokens) into hierarchically arranged segments; within each segment, tokens are predicted in parallel, similar to BERT, while across segment predictions are sequential, similar to GPT. We illustrate that randomized serialization of the segments significantly improves the performance and results in distribution over spatially-long (across-segments) and -short (within-segment) predictions which are effective for feature learning. We illustrate the pertinence of these design choices and explore alternatives on a number of datasets (e.g., CIFAR10, ImageNet). While our pre-training strategy works with vanilla Transformer, we also propose a conceptually simple, but highly effective, addition to the decoder that allows learnable skip-connections to encoder feature layers, which further improves the performance. Our final model, trained on ImageNet, achieves new state-of-the-art linear probing performance 68.3% among comparative predictive self-supervised learning approaches.
Co-advise: Cross Inductive Bias Distillation
Jun 23, 2021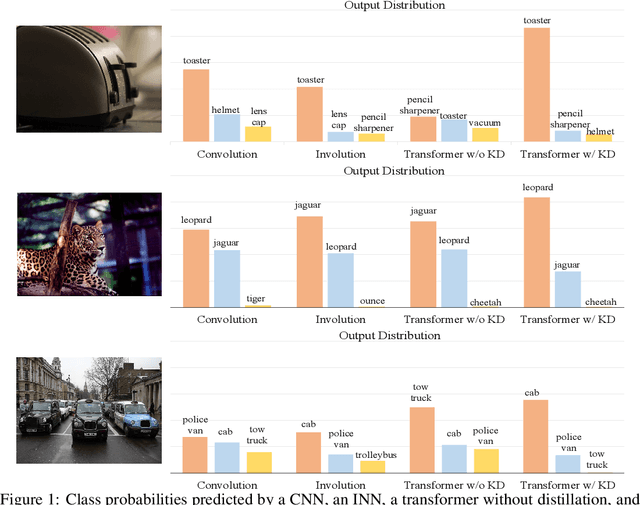
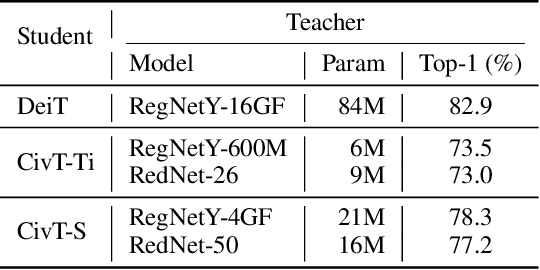
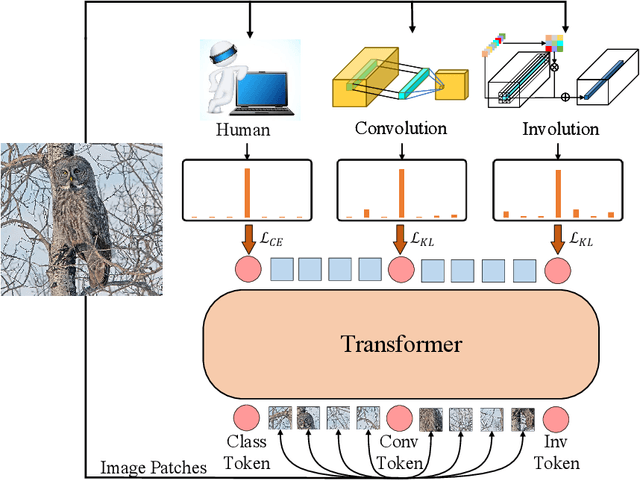
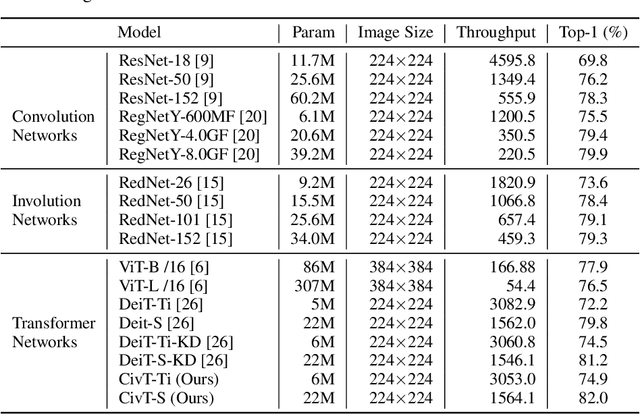
Transformers recently are adapted from the community of natural language processing as a promising substitute of convolution-based neural networks for visual learning tasks. However, its supremacy degenerates given an insufficient amount of training data (e.g., ImageNet). To make it into practical utility, we propose a novel distillation-based method to train vision transformers. Unlike previous works, where merely heavy convolution-based teachers are provided, we introduce lightweight teachers with different architectural inductive biases (e.g., convolution and involution) to co-advise the student transformer. The key is that teachers with different inductive biases attain different knowledge despite that they are trained on the same dataset, and such different knowledge compounds and boosts the student's performance during distillation. Equipped with this cross inductive bias distillation method, our vision transformers (termed as CivT) outperform all previous transformers of the same architecture on ImageNet.
Simple Distillation Baselines for Improving Small Self-supervised Models
Jun 21, 2021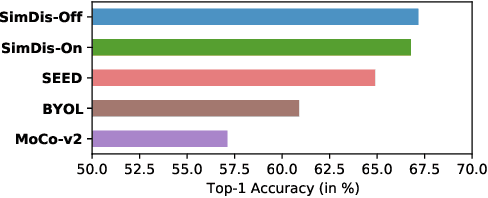

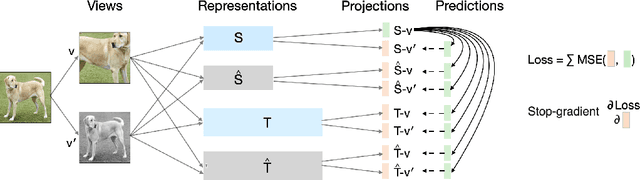
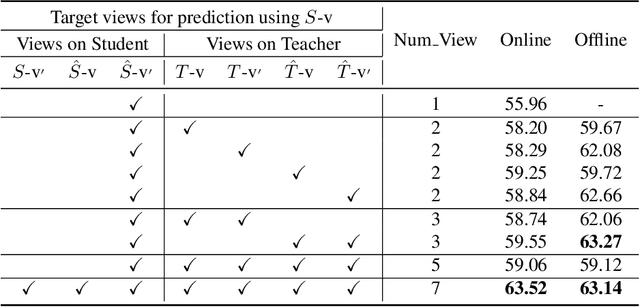
While large self-supervised models have rivalled the performance of their supervised counterparts, small models still struggle. In this report, we explore simple baselines for improving small self-supervised models via distillation, called SimDis. Specifically, we present an offline-distillation baseline, which establishes a new state-of-the-art, and an online-distillation baseline, which achieves similar performance with minimal computational overhead. We hope these baselines will provide useful experience for relevant future research. Code is available at: https://github.com/JindongGu/SimDis/
Generative Models as a Data Source for Multiview Representation Learning
Jun 09, 2021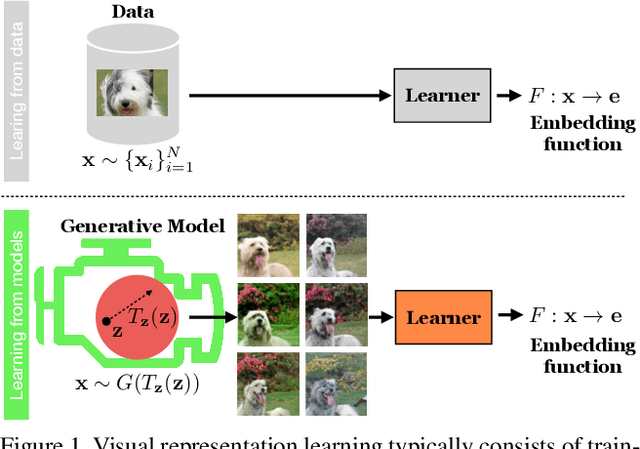
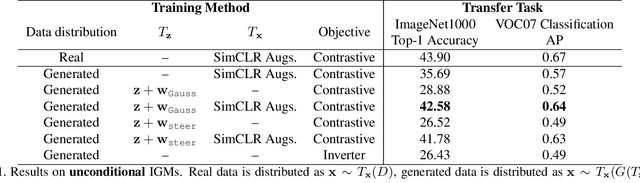
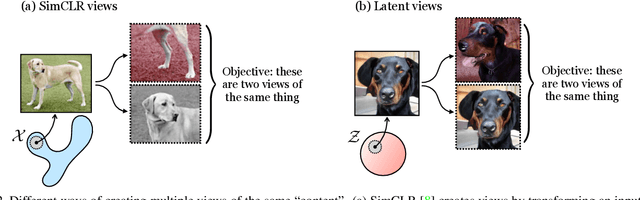
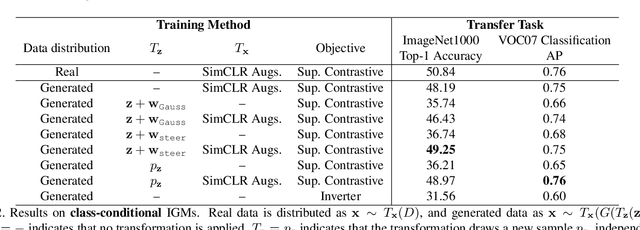
Generative models are now capable of producing highly realistic images that look nearly indistinguishable from the data on which they are trained. This raises the question: if we have good enough generative models, do we still need datasets? We investigate this question in the setting of learning general-purpose visual representations from a black-box generative model rather than directly from data. Given an off-the-shelf image generator without any access to its training data, we train representations from the samples output by this generator. We compare several representation learning methods that can be applied to this setting, using the latent space of the generator to generate multiple "views" of the same semantic content. We show that for contrastive methods, this multiview data can naturally be used to identify positive pairs (nearby in latent space) and negative pairs (far apart in latent space). We find that the resulting representations rival those learned directly from real data, but that good performance requires care in the sampling strategy applied and the training method. Generative models can be viewed as a compressed and organized copy of a dataset, and we envision a future where more and more "model zoos" proliferate while datasets become increasingly unwieldy, missing, or private. This paper suggests several techniques for dealing with visual representation learning in such a future. Code is released on our project page: https://ali-design.github.io/GenRep/
Divide and Contrast: Self-supervised Learning from Uncurated Data
May 17, 2021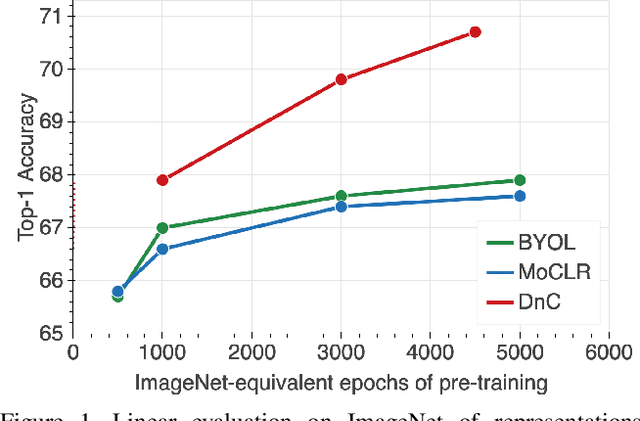
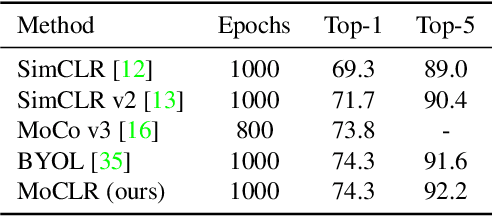
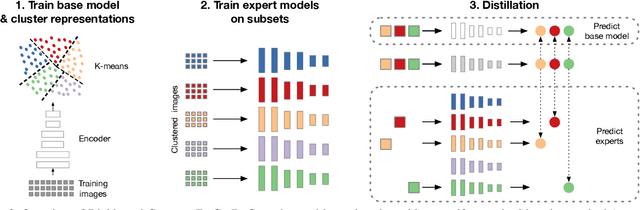
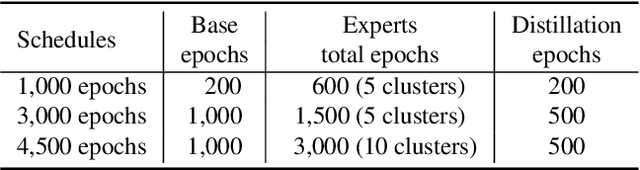
Self-supervised learning holds promise in leveraging large amounts of unlabeled data, however much of its progress has thus far been limited to highly curated pre-training data such as ImageNet. We explore the effects of contrastive learning from larger, less-curated image datasets such as YFCC, and find there is indeed a large difference in the resulting representation quality. We hypothesize that this curation gap is due to a shift in the distribution of image classes -- which is more diverse and heavy-tailed -- resulting in less relevant negative samples to learn from. We test this hypothesis with a new approach, Divide and Contrast (DnC), which alternates between contrastive learning and clustering-based hard negative mining. When pretrained on less curated datasets, DnC greatly improves the performance of self-supervised learning on downstream tasks, while remaining competitive with the current state-of-the-art on curated datasets.
Composable Augmentation Encoding for Video Representation Learning
Apr 01, 2021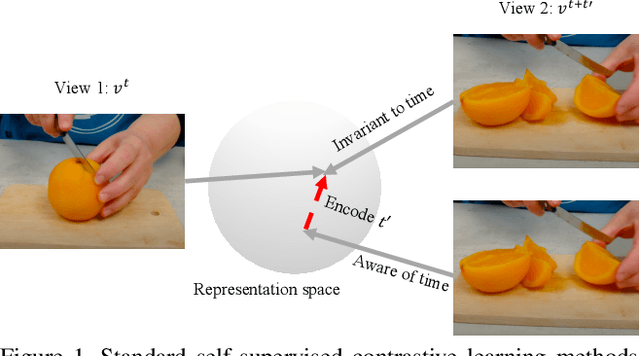

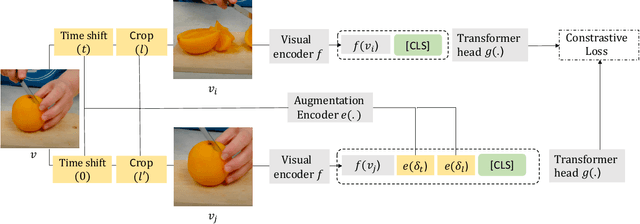

We focus on contrastive methods for self-supervised video representation learning. A common paradigm in contrastive learning is to construct positive pairs by sampling different data views for the same instance, with different data instances as negatives. These methods implicitly assume a set of representational invariances to the view selection mechanism (eg, sampling frames with temporal shifts), which may lead to poor performance on downstream tasks which violate these invariances (fine-grained video action recognition that would benefit from temporal information). To overcome this limitation, we propose an 'augmentation aware' contrastive learning framework, where we explicitly provide a sequence of augmentation parameterisations (such as the values of the time shifts used to create data views) as composable augmentation encodings (CATE) to our model when projecting the video representations for contrastive learning. We show that representations learned by our method encode valuable information about specified spatial or temporal augmentation, and in doing so also achieve state-of-the-art performance on a number of video benchmarks.