 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResponse Uncertainty and Probe Modeling: Two Sides of the Same Coin in LLM Interpretability?
May 24, 2025Probing techniques have shown promise in revealing how LLMs encode human-interpretable concepts, particularly when applied to curated datasets. However, the factors governing a dataset's suitability for effective probe training are not well-understood. This study hypothesizes that probe performance on such datasets reflects characteristics of both the LLM's generated responses and its internal feature space. Through quantitative analysis of probe performance and LLM response uncertainty across a series of tasks, we find a strong correlation: improved probe performance consistently corresponds to a reduction in response uncertainty, and vice versa. Subsequently, we delve deeper into this correlation through the lens of feature importance analysis. Our findings indicate that high LLM response variance is associated with a larger set of important features, which poses a greater challenge for probe models and often results in diminished performance. Moreover, leveraging the insights from response uncertainty analysis, we are able to identify concrete examples where LLM representations align with human knowledge across diverse domains, offering additional evidence of interpretable reasoning in LLMs.
Knowledge Retrieval in LLM Gaming: A Shift from Entity-Centric to Goal-Oriented Graphs
May 24, 2025Large Language Models (LLMs) demonstrate impressive general capabilities but often struggle with step-by-step reasoning, especially in complex applications such as games. While retrieval-augmented methods like GraphRAG attempt to bridge this gap through cross-document extraction and indexing, their fragmented entity-relation graphs and overly dense local connectivity hinder the construction of coherent reasoning. In this paper, we propose a novel framework based on Goal-Oriented Graphs (GoGs), where each node represents a goal and its associated attributes, and edges encode logical dependencies between goals. This structure enables explicit retrieval of reasoning paths by first identifying high-level goals and recursively retrieving their subgoals, forming coherent reasoning chains to guide LLM prompting. Our method significantly enhances the reasoning ability of LLMs in game-playing tasks, as demonstrated by extensive experiments on the Minecraft testbed, outperforming GraphRAG and other baselines.
RoleRAG: Enhancing LLM Role-Playing via Graph Guided Retrieval
May 24, 2025Large Language Models (LLMs) have shown promise in character imitation, enabling immersive and engaging conversations. However, they often generate content that is irrelevant or inconsistent with a character's background. We attribute these failures to: (1) the inability to accurately recall character-specific knowledge due to entity ambiguity, and (2) a lack of awareness of the character's cognitive boundaries. To address these issues, we propose RoleRAG, a retrieval-based framework that integrates efficient entity disambiguation for knowledge indexing with a boundary-aware retriever for extracting contextually appropriate information from a structured knowledge graph. Experiments on role-playing benchmarks show that RoleRAG's calibrated retrieval helps both general-purpose and role-specific LLMs better align with character knowledge and reduce hallucinated responses.
An Intelligent and Privacy-Preserving Digital Twin Model for Aging-in-Place
Apr 04, 2025The population of older adults is steadily increasing, with a strong preference for aging-in-place rather than moving to care facilities. Consequently, supporting this growing demographic has become a significant global challenge. However, facilitating successful aging-in-place is challenging, requiring consideration of multiple factors such as data privacy, health status monitoring, and living environments to improve health outcomes. In this paper, we propose an unobtrusive sensor system designed for installation in older adults' homes. Using data from the sensors, our system constructs a digital twin, a virtual representation of events and activities that occurred in the home. The system uses neural network models and decision rules to capture residents' activities and living environments. This digital twin enables continuous health monitoring by providing actionable insights into residents' well-being. Our system is designed to be low-cost and privacy-preserving, with the aim of providing green and safe monitoring for the health of older adults. We have successfully deployed our system in two homes over a time period of two months, and our findings demonstrate the feasibility and effectiveness of digital twin technology in supporting independent living for older adults. This study highlights that our system could revolutionize elder care by enabling personalized interventions, such as lifestyle adjustments, medical treatments, or modifications to the residential environment, to enhance health outcomes.
A Survey on Natural Language Counterfactual Generation
Jul 04, 2024



Natural Language Counterfactual generation aims to minimally modify a given text such that the modified text will be classified into a different class. The generated counterfactuals provide insight into the reasoning behind a model's predictions by highlighting which words significantly influence the outcomes. Additionally, they can be used to detect model fairness issues or augment the training data to enhance the model's robustness. A substantial amount of research has been conducted to generate counterfactuals for various NLP tasks, employing different models and methodologies. With the rapid growth of studies in this field, a systematic review is crucial to guide future researchers and developers. To bridge this gap, this survey comprehensively overview textual counterfactual generation methods, particularly including those based on Large Language Models. We propose a new taxonomy that categorizes the generation methods into four groups and systematically summarize the metrics for evaluating the generation quality. Finally, we discuss ongoing research challenges and outline promising directions for future work.
PairCFR: Enhancing Model Training on Paired Counterfactually Augmented Data through Contrastive Learning
Jun 09, 2024



Counterfactually Augmented Data (CAD) involves creating new data samples by applying minimal yet sufficient modifications to flip the label of existing data samples to other classes. Training with CAD enhances model robustness against spurious features that happen to correlate with labels by spreading the casual relationships across different classes. Yet, recent research reveals that training with CAD may lead models to overly focus on modified features while ignoring other important contextual information, inadvertently introducing biases that may impair performance on out-ofdistribution (OOD) datasets. To mitigate this issue, we employ contrastive learning to promote global feature alignment in addition to learning counterfactual clues. We theoretically prove that contrastive loss can encourage models to leverage a broader range of features beyond those modified ones. Comprehensive experiments on two human-edited CAD datasets demonstrate that our proposed method outperforms the state-of-the-art on OOD datasets.
Gradient based Feature Attribution in Explainable AI: A Technical Review
Mar 15, 2024The surge in black-box AI models has prompted the need to explain the internal mechanism and justify their reliability, especially in high-stakes applications, such as healthcare and autonomous driving. Due to the lack of a rigorous definition of explainable AI (XAI), a plethora of research related to explainability, interpretability, and transparency has been developed to explain and analyze the model from various perspectives. Consequently, with an exhaustive list of papers, it becomes challenging to have a comprehensive overview of XAI research from all aspects. Considering the popularity of neural networks in AI research, we narrow our focus to a specific area of XAI research: gradient based explanations, which can be directly adopted for neural network models. In this review, we systematically explore gradient based explanation methods to date and introduce a novel taxonomy to categorize them into four distinct classes. Then, we present the essence of technique details in chronological order and underscore the evolution of algorithms. Next, we introduce both human and quantitative evaluations to measure algorithm performance. More importantly, we demonstrate the general challenges in XAI and specific challenges in gradient based explanations. We hope that this survey can help researchers understand state-of-the-art progress and their corresponding disadvantages, which could spark their interest in addressing these issues in future work.
Flexible and Robust Counterfactual Explanations with Minimal Satisfiable Perturbations
Sep 09, 2023



Counterfactual explanations (CFEs) exemplify how to minimally modify a feature vector to achieve a different prediction for an instance. CFEs can enhance informational fairness and trustworthiness, and provide suggestions for users who receive adverse predictions. However, recent research has shown that multiple CFEs can be offered for the same instance or instances with slight differences. Multiple CFEs provide flexible choices and cover diverse desiderata for user selection. However, individual fairness and model reliability will be damaged if unstable CFEs with different costs are returned. Existing methods fail to exploit flexibility and address the concerns of non-robustness simultaneously. To address these issues, we propose a conceptually simple yet effective solution named Counterfactual Explanations with Minimal Satisfiable Perturbations (CEMSP). Specifically, CEMSP constrains changing values of abnormal features with the help of their semantically meaningful normal ranges. For efficiency, we model the problem as a Boolean satisfiability problem to modify as few features as possible. Additionally, CEMSP is a general framework and can easily accommodate more practical requirements, e.g., casualty and actionability. Compared to existing methods, we conduct comprehensive experiments on both synthetic and real-world datasets to demonstrate that our method provides more robust explanations while preserving flexibility.
Explaining Language Models' Predictions with High-Impact Concepts
May 03, 2023



The emergence of large-scale pretrained language models has posed unprecedented challenges in deriving explanations of why the model has made some predictions. Stemmed from the compositional nature of languages, spurious correlations have further undermined the trustworthiness of NLP systems, leading to unreliable model explanations that are merely correlated with the output predictions. To encourage fairness and transparency, there exists an urgent demand for reliable explanations that allow users to consistently understand the model's behavior. In this work, we propose a complete framework for extending concept-based interpretability methods to NLP. Specifically, we propose a post-hoc interpretability method for extracting predictive high-level features (concepts) from the pretrained model's hidden layer activations. We optimize for features whose existence causes the output predictions to change substantially, \ie generates a high impact. Moreover, we devise several evaluation metrics that can be universally applied. Extensive experiments on real and synthetic tasks demonstrate that our method achieves superior results on {predictive impact}, usability, and faithfulness compared to the baselines.
On the Use of BERT for Automated Essay Scoring: Joint Learning of Multi-Scale Essay Representation
May 21, 2022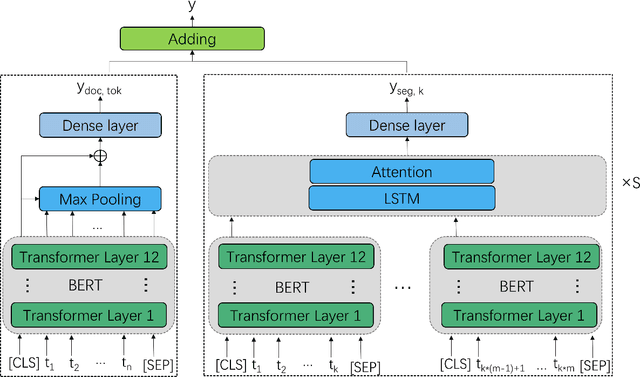
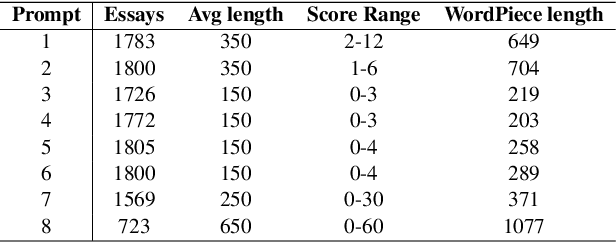
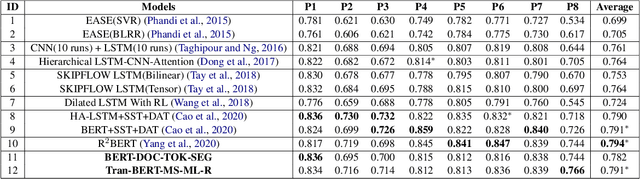
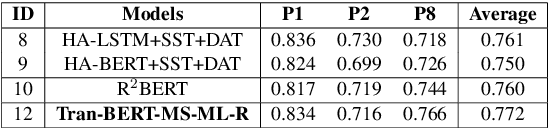
In recent years, pre-trained models have become dominant in most natural language processing (NLP) tasks. However, in the area of Automated Essay Scoring (AES), pre-trained models such as BERT have not been properly used to outperform other deep learning models such as LSTM. In this paper, we introduce a novel multi-scale essay representation for BERT that can be jointly learned. We also employ multiple losses and transfer learning from out-of-domain essays to further improve the performance. Experiment results show that our approach derives much benefit from joint learning of multi-scale essay representation and obtains almost the state-of-the-art result among all deep learning models in the ASAP task. Our multi-scale essay representation also generalizes well to CommonLit Readability Prize data set, which suggests that the novel text representation proposed in this paper may be a new and effective choice for long-text tasks.