 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Guided Multi-View Multi-Domain Fake News Detection
Jun 26, 2022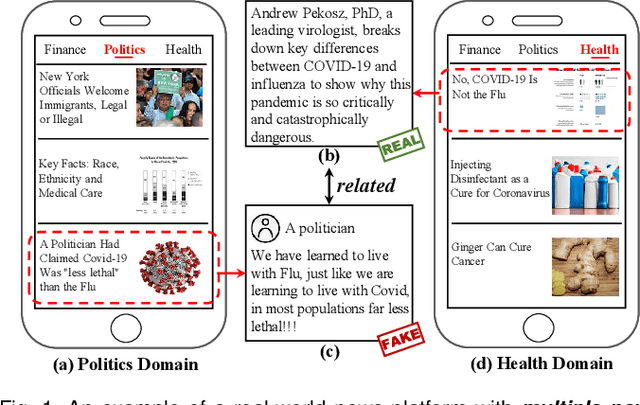
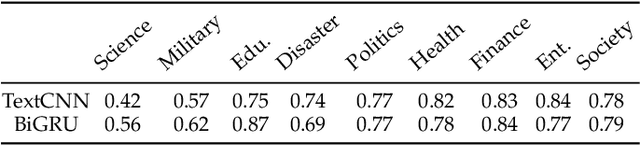
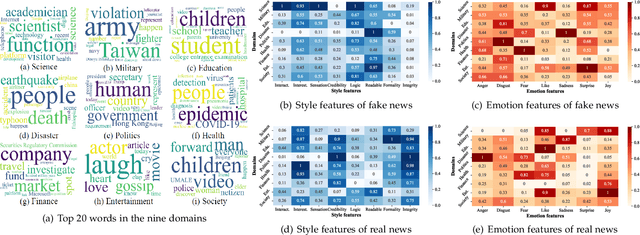
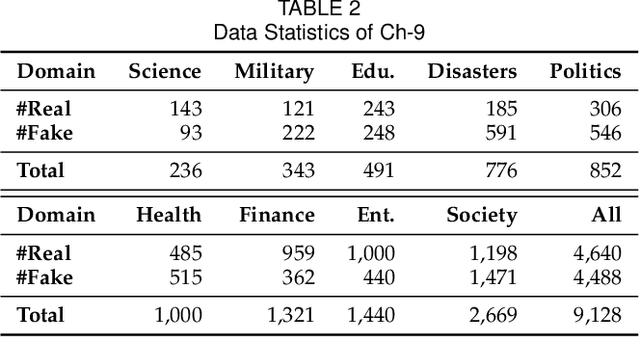
The wide spread of fake news is increasingly threatening both individuals and society. Great efforts have been made for automatic fake news detection on a single domain (e.g., politics). However, correlations exist commonly across multiple news domains, and thus it is promising to simultaneously detect fake news of multiple domains. Based on our analysis, we pose two challenges in multi-domain fake news detection: 1) domain shift, caused by the discrepancy among domains in terms of words, emotions, styles, etc. 2) domain labeling incompleteness, stemming from the real-world categorization that only outputs one single domain label, regardless of topic diversity of a news piece. In this paper, we propose a Memory-guided Multi-view Multi-domain Fake News Detection Framework (M$^3$FEND) to address these two challenges. We model news pieces from a multi-view perspective, including semantics, emotion, and style. Specifically, we propose a Domain Memory Bank to enrich domain information which could discover potential domain labels based on seen news pieces and model domain characteristics. Then, with enriched domain information as input, a Domain Adapter could adaptively aggregate discriminative information from multiple views for news in various domains. Extensive offline experiments on English and Chinese datasets demonstrate the effectiveness of M$^3$FEND, and online tests verify its superiority in practice. Our code is available at https://github.com/ICTMCG/M3FEND.
Personalized Prompts for Sequential Recommendation
May 19, 2022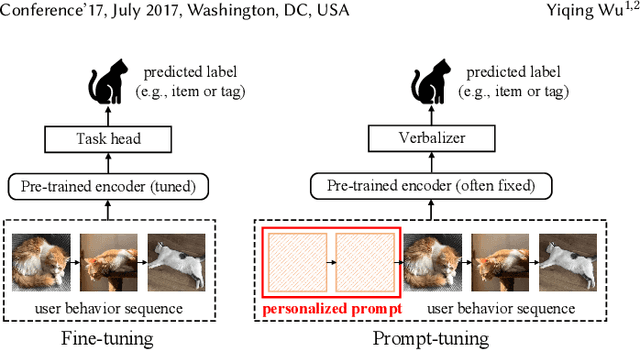
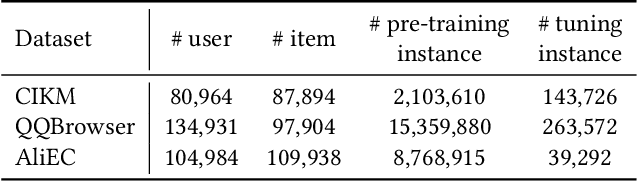
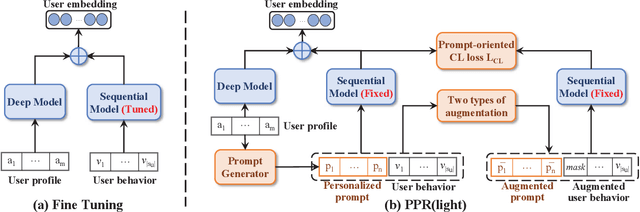
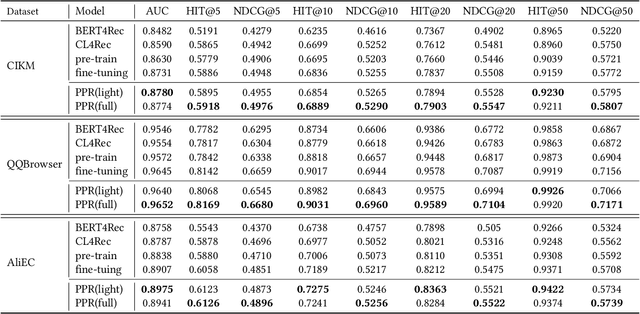
Pre-training models have shown their power in sequential recommendation. Recently, prompt has been widely explored and verified for tuning in NLP pre-training, which could help to more effectively and efficiently extract useful knowledge from pre-training models for downstream tasks, especially in cold-start scenarios. However, it is challenging to bring prompt-tuning from NLP to recommendation, since the tokens in recommendation (i.e., items) do not have explicit explainable semantics, and the sequence modeling should be personalized. In this work, we first introduces prompt to recommendation and propose a novel Personalized prompt-based recommendation (PPR) framework for cold-start recommendation. Specifically, we build the personalized soft prefix prompt via a prompt generator based on user profiles and enable a sufficient training of prompts via a prompt-oriented contrastive learning with both prompt- and behavior-based augmentations. We conduct extensive evaluations on various tasks. In both few-shot and zero-shot recommendation, PPR models achieve significant improvements over baselines on various metrics in three large-scale open datasets. We also conduct ablation tests and sparsity analysis for a better understanding of PPR. Moreover, We further verify PPR's universality on different pre-training models, and conduct explorations on PPR's other promising downstream tasks including cross-domain recommendation and user profile prediction.
Selective Fairness in Recommendation via Prompts
May 10, 2022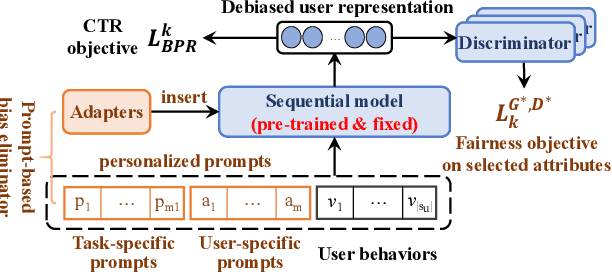

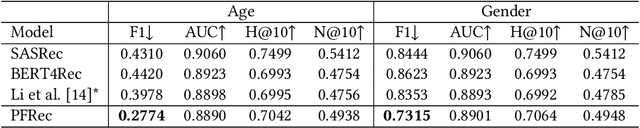
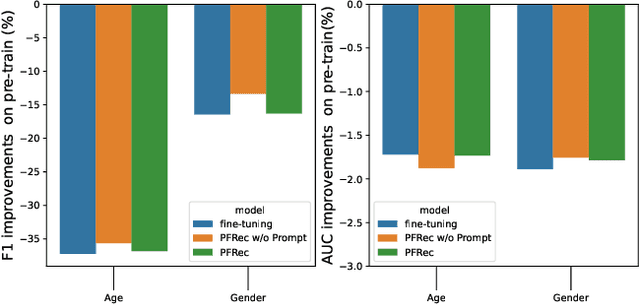
Recommendation fairness has attracted great attention recently. In real-world systems, users usually have multiple sensitive attributes (e.g. age, gender, and occupation), and users may not want their recommendation results influenced by those attributes. Moreover, which of and when these user attributes should be considered in fairness-aware modeling should depend on users' specific demands. In this work, we define the selective fairness task, where users can flexibly choose which sensitive attributes should the recommendation model be bias-free. We propose a novel parameter-efficient prompt-based fairness-aware recommendation (PFRec) framework, which relies on attribute-specific prompt-based bias eliminators with adversarial training, enabling selective fairness with different attribute combinations on sequential recommendation. Both task-specific and user-specific prompts are considered. We conduct extensive evaluations to verify PFRec's superiority in selective fairness. The source codes are released in \url{https://github.com/wyqing20/PFRec}.
Positive-Unlabeled Learning with Adversarial Data Augmentation for Knowledge Graph Completion
May 02, 2022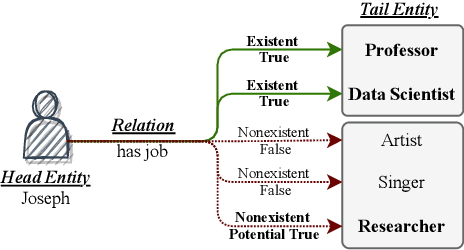
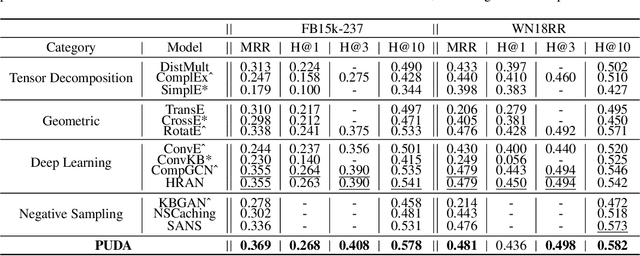
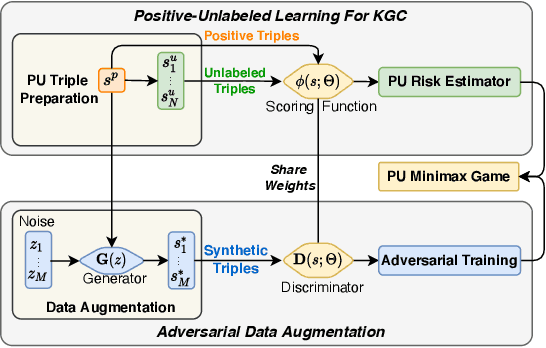
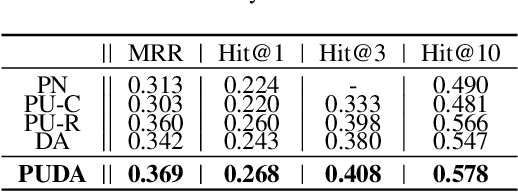
Most real-world knowledge graphs (KG) are far from complete and comprehensive. This problem has motivated efforts in predicting the most plausible missing facts to complete a given KG, i.e., knowledge graph completion (KGC). However, existing KGC methods suffer from two main issues, 1) the false negative issue, i.e., the candidates for sampling negative training instances include potential true facts; and 2) the data sparsity issue, i.e., true facts account for only a tiny part of all possible facts. To this end, we propose positive-unlabeled learning with adversarial data augmentation (PUDA) for KGC. In particular, PUDA tailors positive-unlabeled risk estimator for the KGC task to deal with the false negative issue. Furthermore, to address the data sparsity issue, PUDA achieves a data augmentation strategy by unifying adversarial training and positive-unlabeled learning under the positive-unlabeled minimax game. Extensive experimental results demonstrate its effectiveness and compatibility.
User-Centric Conversational Recommendation with Multi-Aspect User Modeling
Apr 25, 2022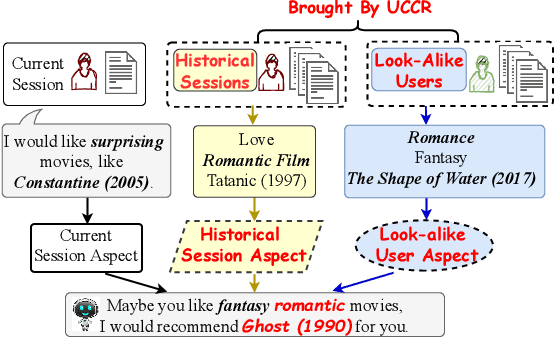
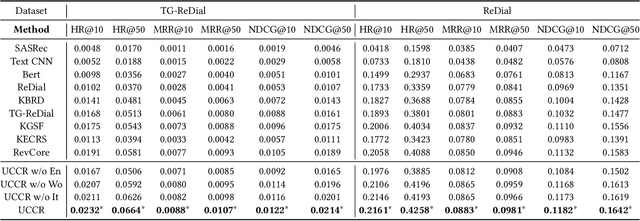
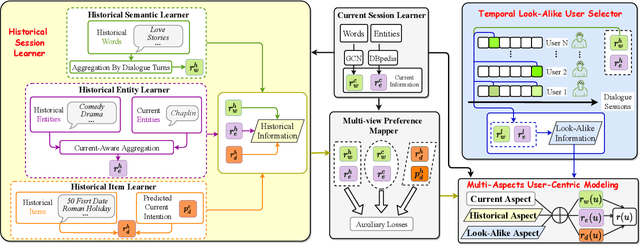
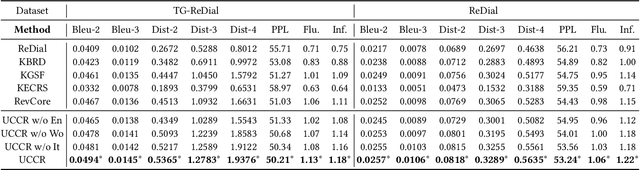
Conversational recommender systems (CRS) aim to provide highquality recommendations in conversations. However, most conventional CRS models mainly focus on the dialogue understanding of the current session, ignoring other rich multi-aspect information of the central subjects (i.e., users) in recommendation. In this work, we highlight that the user's historical dialogue sessions and look-alike users are essential sources of user preferences besides the current dialogue session in CRS. To systematically model the multi-aspect information, we propose a User-Centric Conversational Recommendation (UCCR) model, which returns to the essence of user preference learning in CRS tasks. Specifically, we propose a historical session learner to capture users' multi-view preferences from knowledge, semantic, and consuming views as supplements to the current preference signals. A multi-view preference mapper is conducted to learn the intrinsic correlations among different views in current and historical sessions via self-supervised objectives. We also design a temporal look-alike user selector to understand users via their similar users. The learned multi-aspect multi-view user preferences are then used for the recommendation and dialogue generation. In experiments, we conduct comprehensive evaluations on both Chinese and English CRS datasets. The significant improvements over competitive models in both recommendation and dialogue generation verify the superiority of UCCR.
Generalizing to the Future: Mitigating Entity Bias in Fake News Detection
Apr 20, 2022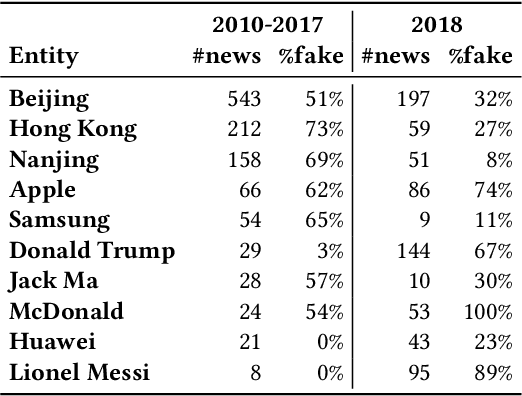
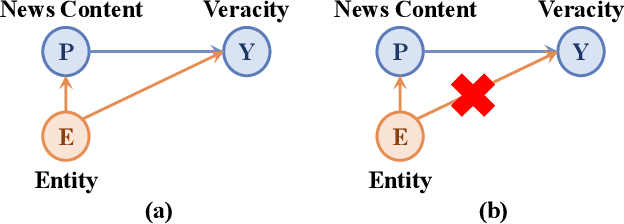
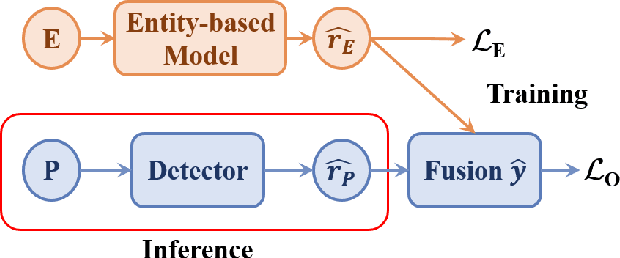
The wide dissemination of fake news is increasingly threatening both individuals and society. Fake news detection aims to train a model on the past news and detect fake news of the future. Though great efforts have been made, existing fake news detection methods overlooked the unintended entity bias in the real-world data, which seriously influences models' generalization ability to future data. For example, 97\% of news pieces in 2010-2017 containing the entity `Donald Trump' are real in our data, but the percentage falls down to merely 33\% in 2018. This would lead the model trained on the former set to hardly generalize to the latter, as it tends to predict news pieces about `Donald Trump' as real for lower training loss. In this paper, we propose an entity debiasing framework (\textbf{ENDEF}) which generalizes fake news detection models to the future data by mitigating entity bias from a cause-effect perspective. Based on the causal graph among entities, news contents, and news veracity, we separately model the contribution of each cause (entities and contents) during training. In the inference stage, we remove the direct effect of the entities to mitigate entity bias. Extensive offline experiments on the English and Chinese datasets demonstrate that the proposed framework can largely improve the performance of base fake news detectors, and online tests verify its superiority in practice. To the best of our knowledge, this is the first work to explicitly improve the generalization ability of fake news detection models to the future data. The code has been released at https://github.com/ICTMCG/ENDEF-SIGIR2022.
Zoom Out and Observe: News Environment Perception for Fake News Detection
Mar 21, 2022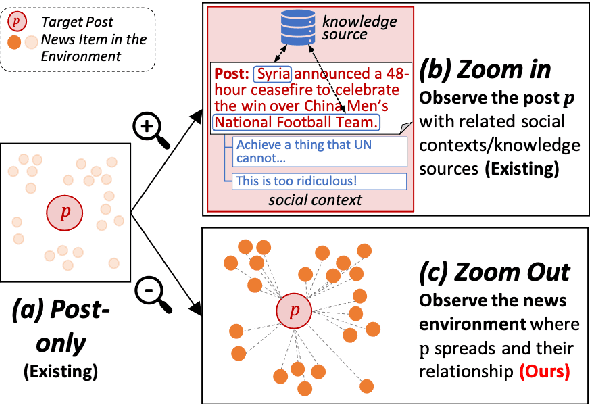
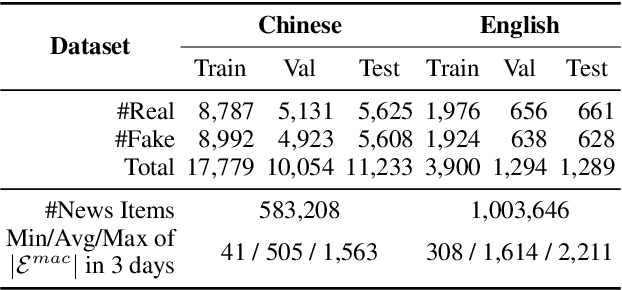
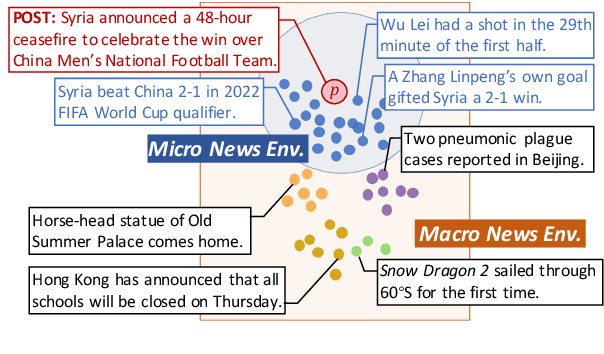
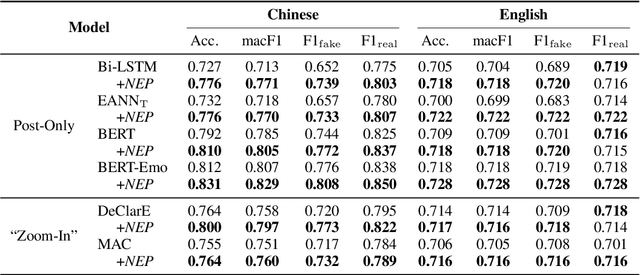
Fake news detection is crucial for preventing the dissemination of misinformation on social media. To differentiate fake news from real ones, existing methods observe the language patterns of the news post and "zoom in" to verify its content with knowledge sources or check its readers' replies. However, these methods neglect the information in the external news environment where a fake news post is created and disseminated. The news environment represents recent mainstream media opinion and public attention, which is an important inspiration of fake news fabrication because fake news is often designed to ride the wave of popular events and catch public attention with unexpected novel content for greater exposure and spread. To capture the environmental signals of news posts, we "zoom out" to observe the news environment and propose the News Environment Perception Framework (NEP). For each post, we construct its macro and micro news environment from recent mainstream news. Then we design a popularity-oriented and a novelty-oriented module to perceive useful signals and further assist final prediction. Experiments on our newly built datasets show that the NEP can efficiently improve the performance of basic fake news detectors.
Multi-view Multi-behavior Contrastive Learning in Recommendation
Mar 20, 2022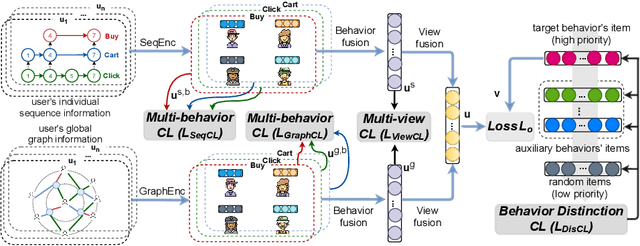
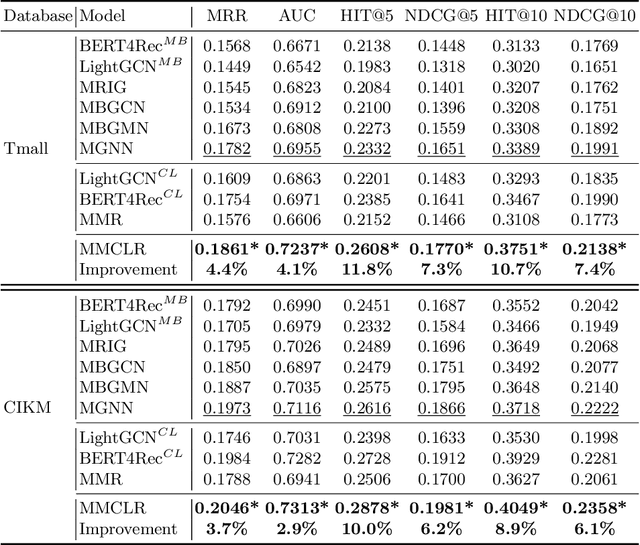
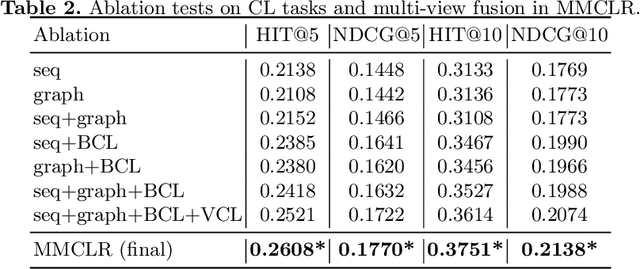
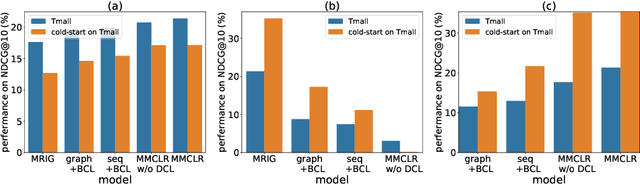
Multi-behavior recommendation (MBR) aims to jointly consider multiple behaviors to improve the target behavior's performance. We argue that MBR models should: (1) model the coarse-grained commonalities between different behaviors of a user, (2) consider both individual sequence view and global graph view in multi-behavior modeling, and (3) capture the fine-grained differences between multiple behaviors of a user. In this work, we propose a novel Multi-behavior Multi-view Contrastive Learning Recommendation (MMCLR) framework, including three new CL tasks to solve the above challenges, respectively. The multi-behavior CL aims to make different user single-behavior representations of the same user in each view to be similar. The multi-view CL attempts to bridge the gap between a user's sequence-view and graph-view representations. The behavior distinction CL focuses on modeling fine-grained differences of different behaviors. In experiments, we conduct extensive evaluations and ablation tests to verify the effectiveness of MMCLR and various CL tasks on two real-world datasets, achieving SOTA performance over existing baselines. Our code will be available on \url{https://github.com/wyqing20/MMCLR}
Modeling Users' Behavior Sequences with Hierarchical Explainable Network for Cross-domain Fraud Detection
Jan 04, 2022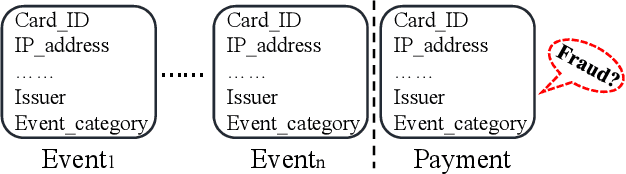
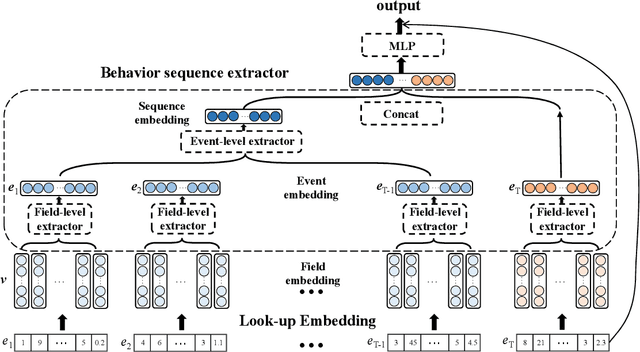
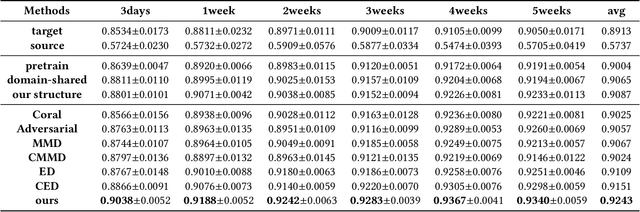
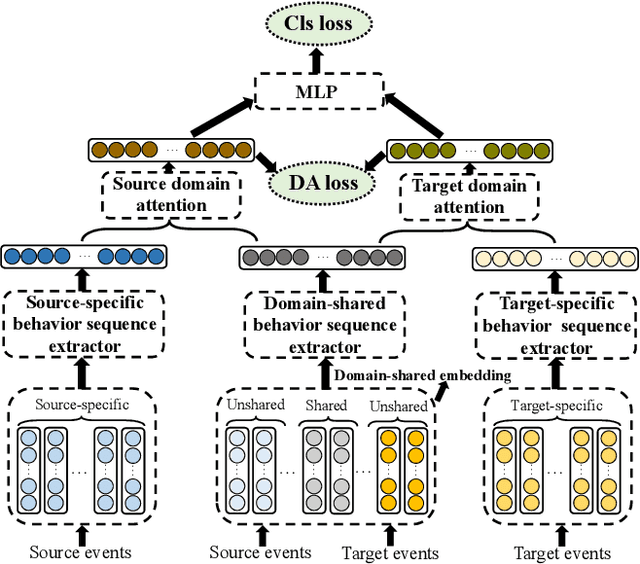
With the explosive growth of the e-commerce industry, detecting online transaction fraud in real-world applications has become increasingly important to the development of e-commerce platforms. The sequential behavior history of users provides useful information in differentiating fraudulent payments from regular ones. Recently, some approaches have been proposed to solve this sequence-based fraud detection problem. However, these methods usually suffer from two problems: the prediction results are difficult to explain and the exploitation of the internal information of behaviors is insufficient. To tackle the above two problems, we propose a Hierarchical Explainable Network (HEN) to model users' behavior sequences, which could not only improve the performance of fraud detection but also make the inference process interpretable. Meanwhile, as e-commerce business expands to new domains, e.g., new countries or new markets, one major problem for modeling user behavior in fraud detection systems is the limitation of data collection, e.g., very few data/labels available. Thus, in this paper, we further propose a transfer framework to tackle the cross-domain fraud detection problem, which aims to transfer knowledge from existing domains (source domains) with enough and mature data to improve the performance in the new domain (target domain). Our proposed method is a general transfer framework that could not only be applied upon HEN but also various existing models in the Embedding & MLP paradigm. Based on 90 transfer task experiments, we also demonstrate that our transfer framework could not only contribute to the cross-domain fraud detection task with HEN, but also be universal and expandable for various existing models.
Aligning Domain-specific Distribution and Classifier for Cross-domain Classification from Multiple Sources
Jan 04, 2022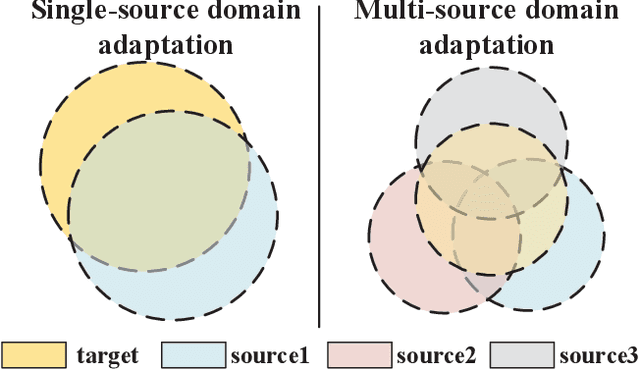
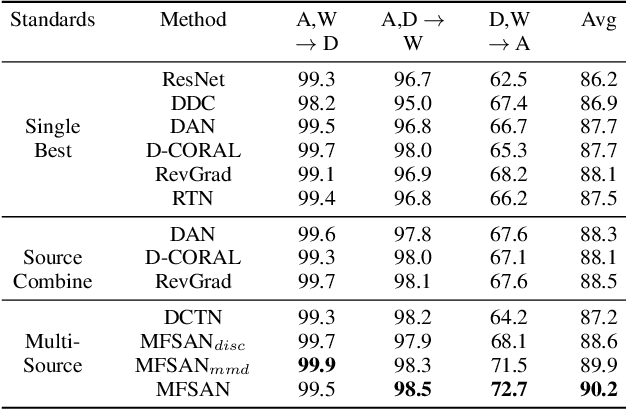
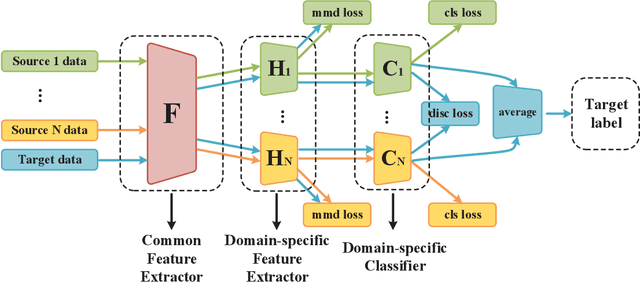
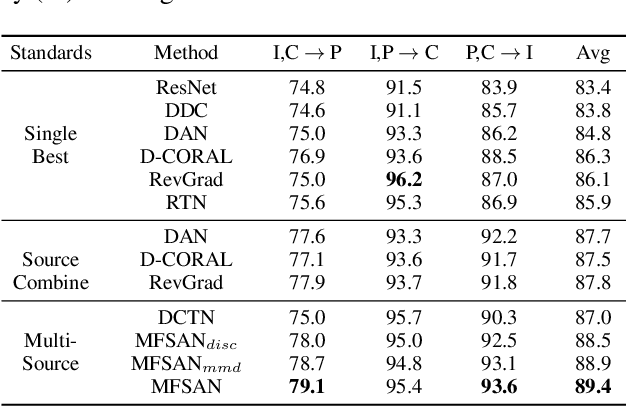
While Unsupervised Domain Adaptation (UDA) algorithms, i.e., there are only labeled data from source domains, have been actively studied in recent years, most algorithms and theoretical results focus on Single-source Unsupervised Domain Adaptation (SUDA). However, in the practical scenario, labeled data can be typically collected from multiple diverse sources, and they might be different not only from the target domain but also from each other. Thus, domain adapters from multiple sources should not be modeled in the same way. Recent deep learning based Multi-source Unsupervised Domain Adaptation (MUDA) algorithms focus on extracting common domain-invariant representations for all domains by aligning distribution of all pairs of source and target domains in a common feature space. However, it is often very hard to extract the same domain-invariant representations for all domains in MUDA. In addition, these methods match distributions without considering domain-specific decision boundaries between classes. To solve these problems, we propose a new framework with two alignment stages for MUDA which not only respectively aligns the distributions of each pair of source and target domains in multiple specific feature spaces, but also aligns the outputs of classifiers by utilizing the domain-specific decision boundaries. Extensive experiments demonstrate that our method can achieve remarkable results on popular benchmark datasets for image classification.