 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe N-Body Problem: Parallel Execution from Single-Person Egocentric Video
Dec 12, 2025Humans can intuitively parallelise complex activities, but can a model learn this from observing a single person? Given one egocentric video, we introduce the N-Body Problem: how N individuals, can hypothetically perform the same set of tasks observed in this video. The goal is to maximise speed-up, but naive assignment of video segments to individuals often violates real-world constraints, leading to physically impossible scenarios like two people using the same object or occupying the same space. To address this, we formalise the N-Body Problem and propose a suite of metrics to evaluate both performance (speed-up, task coverage) and feasibility (spatial collisions, object conflicts and causal constraints). We then introduce a structured prompting strategy that guides a Vision-Language Model (VLM) to reason about the 3D environment, object usage, and temporal dependencies to produce a viable parallel execution. On 100 videos from EPIC-Kitchens and HD-EPIC, our method for N = 2 boosts action coverage by 45% over a baseline prompt for Gemini 2.5 Pro, while simultaneously slashing collision rates, object and causal conflicts by 55%, 45% and 55% respectively.
Can MLLMs Read the Room? A Multimodal Benchmark for Verifying Truthfulness in Multi-Party Social Interactions
Oct 31, 2025As AI systems become increasingly integrated into human lives, endowing them with robust social intelligence has emerged as a critical frontier. A key aspect of this intelligence is discerning truth from deception, a ubiquitous element of human interaction that is conveyed through a complex interplay of verbal language and non-verbal visual cues. However, automatic deception detection in dynamic, multi-party conversations remains a significant challenge. The recent rise of powerful Multimodal Large Language Models (MLLMs), with their impressive abilities in visual and textual understanding, makes them natural candidates for this task. Consequently, their capabilities in this crucial domain are mostly unquantified. To address this gap, we introduce a new task, Multimodal Interactive Veracity Assessment (MIVA), and present a novel multimodal dataset derived from the social deduction game Werewolf. This dataset provides synchronized video, text, with verifiable ground-truth labels for every statement. We establish a comprehensive benchmark evaluating state-of-the-art MLLMs, revealing a significant performance gap: even powerful models like GPT-4o struggle to distinguish truth from falsehood reliably. Our analysis of failure modes indicates that these models fail to ground language in visual social cues effectively and may be overly conservative in their alignment, highlighting the urgent need for novel approaches to building more perceptive and trustworthy AI systems.
Affordance-Guided Diffusion Prior for 3D Hand Reconstruction
Oct 01, 2025

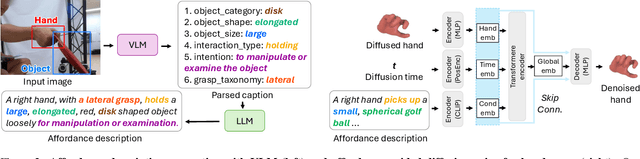

How can we reconstruct 3D hand poses when large portions of the hand are heavily occluded by itself or by objects? Humans often resolve such ambiguities by leveraging contextual knowledge -- such as affordances, where an object's shape and function suggest how the object is typically grasped. Inspired by this observation, we propose a generative prior for hand pose refinement guided by affordance-aware textual descriptions of hand-object interactions (HOI). Our method employs a diffusion-based generative model that learns the distribution of plausible hand poses conditioned on affordance descriptions, which are inferred from a large vision-language model (VLM). This enables the refinement of occluded regions into more accurate and functionally coherent hand poses. Extensive experiments on HOGraspNet, a 3D hand-affordance dataset with severe occlusions, demonstrate that our affordance-guided refinement significantly improves hand pose estimation over both recent regression methods and diffusion-based refinement lacking contextual reasoning.
EgoInstruct: An Egocentric Video Dataset of Face-to-face Instructional Interactions with Multi-modal LLM Benchmarking
Sep 26, 2025Analyzing instructional interactions between an instructor and a learner who are co-present in the same physical space is a critical problem for educational support and skill transfer. Yet such face-to-face instructional scenes have not been systematically studied in computer vision. We identify two key reasons: i) the lack of suitable datasets and ii) limited analytical techniques. To address this gap, we present a new egocentric video dataset of face-to-face instruction and provide ground-truth annotations for two fundamental tasks that serve as a first step toward a comprehensive understanding of instructional interactions: procedural step segmentation and conversation-state classification. Using this dataset, we benchmark multimodal large language models (MLLMs) against conventional task-specific models. Since face-to-face instruction involves multiple modalities (speech content and prosody, gaze and body motion, and visual context), effective understanding requires methods that handle verbal and nonverbal communication in an integrated manner. Accordingly, we evaluate recently introduced MLLMs that jointly process images, audio, and text. This evaluation quantifies the extent to which current machine learning models understand face-to-face instructional scenes. In experiments, MLLMs outperform specialized baselines even without task-specific fine-tuning, suggesting their promise for holistic understanding of instructional interactions.
Bridging Perspectives: A Survey on Cross-view Collaborative Intelligence with Egocentric-Exocentric Vision
Jun 06, 2025



Perceiving the world from both egocentric (first-person) and exocentric (third-person) perspectives is fundamental to human cognition, enabling rich and complementary understanding of dynamic environments. In recent years, allowing the machines to leverage the synergistic potential of these dual perspectives has emerged as a compelling research direction in video understanding. In this survey, we provide a comprehensive review of video understanding from both exocentric and egocentric viewpoints. We begin by highlighting the practical applications of integrating egocentric and exocentric techniques, envisioning their potential collaboration across domains. We then identify key research tasks to realize these applications. Next, we systematically organize and review recent advancements into three main research directions: (1) leveraging egocentric data to enhance exocentric understanding, (2) utilizing exocentric data to improve egocentric analysis, and (3) joint learning frameworks that unify both perspectives. For each direction, we analyze a diverse set of tasks and relevant works. Additionally, we discuss benchmark datasets that support research in both perspectives, evaluating their scope, diversity, and applicability. Finally, we discuss limitations in current works and propose promising future research directions. By synthesizing insights from both perspectives, our goal is to inspire advancements in video understanding and artificial intelligence, bringing machines closer to perceiving the world in a human-like manner. A GitHub repo of related works can be found at https://github.com/ayiyayi/Awesome-Egocentric-and-Exocentric-Vision.
Leadership Assessment in Pediatric Intensive Care Unit Team Training
May 30, 2025This paper addresses the task of assessing PICU team's leadership skills by developing an automated analysis framework based on egocentric vision. We identify key behavioral cues, including fixation object, eye contact, and conversation patterns, as essential indicators of leadership assessment. In order to capture these multimodal signals, we employ Aria Glasses to record egocentric video, audio, gaze, and head movement data. We collect one-hour videos of four simulated sessions involving doctors with different roles and levels. To automate data processing, we propose a method leveraging REMoDNaV, SAM, YOLO, and ChatGPT for fixation object detection, eye contact detection, and conversation classification. In the experiments, significant correlations are observed between leadership skills and behavioral metrics, i.e., the output of our proposed methods, such as fixation time, transition patterns, and direct orders in speech. These results indicate that our proposed data collection and analysis framework can effectively solve skill assessment for training PICU teams.
Egocentric Action-aware Inertial Localization in Point Clouds
May 20, 2025



This paper presents a novel inertial localization framework named Egocentric Action-aware Inertial Localization (EAIL), which leverages egocentric action cues from head-mounted IMU signals to localize the target individual within a 3D point cloud. Human inertial localization is challenging due to IMU sensor noise that causes trajectory drift over time. The diversity of human actions further complicates IMU signal processing by introducing various motion patterns. Nevertheless, we observe that some actions observed through the head-mounted IMU correlate with spatial environmental structures (e.g., bending down to look inside an oven, washing dishes next to a sink), thereby serving as spatial anchors to compensate for the localization drift. The proposed EAIL framework learns such correlations via hierarchical multi-modal alignment. By assuming that the 3D point cloud of the environment is available, it contrastively learns modality encoders that align short-term egocentric action cues in IMU signals with local environmental features in the point cloud. These encoders are then used in reasoning the IMU data and the point cloud over time and space to perform inertial localization. Interestingly, these encoders can further be utilized to recognize the corresponding sequence of actions as a by-product. Extensive experiments demonstrate the effectiveness of the proposed framework over state-of-the-art inertial localization and inertial action recognition baselines.
SiMHand: Mining Similar Hands for Large-Scale 3D Hand Pose Pre-training
Feb 21, 2025



We present a framework for pre-training of 3D hand pose estimation from in-the-wild hand images sharing with similar hand characteristics, dubbed SimHand. Pre-training with large-scale images achieves promising results in various tasks, but prior methods for 3D hand pose pre-training have not fully utilized the potential of diverse hand images accessible from in-the-wild videos. To facilitate scalable pre-training, we first prepare an extensive pool of hand images from in-the-wild videos and design our pre-training method with contrastive learning. Specifically, we collect over 2.0M hand images from recent human-centric videos, such as 100DOH and Ego4D. To extract discriminative information from these images, we focus on the similarity of hands: pairs of non-identical samples with similar hand poses. We then propose a novel contrastive learning method that embeds similar hand pairs closer in the feature space. Our method not only learns from similar samples but also adaptively weights the contrastive learning loss based on inter-sample distance, leading to additional performance gains. Our experiments demonstrate that our method outperforms conventional contrastive learning approaches that produce positive pairs sorely from a single image with data augmentation. We achieve significant improvements over the state-of-the-art method (PeCLR) in various datasets, with gains of 15% on FreiHand, 10% on DexYCB, and 4% on AssemblyHands. Our code is available at https://github.com/ut-vision/SiMHand.
Pre-Training for 3D Hand Pose Estimation with Contrastive Learning on Large-Scale Hand Images in the Wild
Sep 15, 2024



We present a contrastive learning framework based on in-the-wild hand images tailored for pre-training 3D hand pose estimators, dubbed HandCLR. Pre-training on large-scale images achieves promising results in various tasks, but prior 3D hand pose pre-training methods have not fully utilized the potential of diverse hand images accessible from in-the-wild videos. To facilitate scalable pre-training, we first prepare an extensive pool of hand images from in-the-wild videos and design our method with contrastive learning. Specifically, we collected over 2.0M hand images from recent human-centric videos, such as 100DOH and Ego4D. To extract discriminative information from these images, we focus on the similarity of hands; pairs of similar hand poses originating from different samples, and propose a novel contrastive learning method that embeds similar hand pairs closer in the latent space. Our experiments demonstrate that our method outperforms conventional contrastive learning approaches that produce positive pairs sorely from a single image with data augmentation. We achieve significant improvements over the state-of-the-art method in various datasets, with gains of 15% on FreiHand, 10% on DexYCB, and 4% on AssemblyHands.
WTS: A Pedestrian-Centric Traffic Video Dataset for Fine-grained Spatial-Temporal Understanding
Jul 22, 2024



In this paper, we address the challenge of fine-grained video event understanding in traffic scenarios, vital for autonomous driving and safety. Traditional datasets focus on driver or vehicle behavior, often neglecting pedestrian perspectives. To fill this gap, we introduce the WTS dataset, highlighting detailed behaviors of both vehicles and pedestrians across over 1.2k video events in hundreds of traffic scenarios. WTS integrates diverse perspectives from vehicle ego and fixed overhead cameras in a vehicle-infrastructure cooperative environment, enriched with comprehensive textual descriptions and unique 3D Gaze data for a synchronized 2D/3D view, focusing on pedestrian analysis. We also pro-vide annotations for 5k publicly sourced pedestrian-related traffic videos. Additionally, we introduce LLMScorer, an LLM-based evaluation metric to align inference captions with ground truth. Using WTS, we establish a benchmark for dense video-to-text tasks, exploring state-of-the-art Vision-Language Models with an instance-aware VideoLLM method as a baseline. WTS aims to advance fine-grained video event understanding, enhancing traffic safety and autonomous driving development.