 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLG-Loc: Vision-Language Global Localization from Labeled Footprint Maps
Dec 18, 2025This paper presents Vision-Language Global Localization (VLG-Loc), a novel global localization method that uses human-readable labeled footprint maps containing only names and areas of distinctive visual landmarks in an environment. While humans naturally localize themselves using such maps, translating this capability to robotic systems remains highly challenging due to the difficulty of establishing correspondences between observed landmarks and those in the map without geometric and appearance details. To address this challenge, VLG-Loc leverages a vision-language model (VLM) to search the robot's multi-directional image observations for the landmarks noted in the map. The method then identifies robot poses within a Monte Carlo localization framework, where the found landmarks are used to evaluate the likelihood of each pose hypothesis. Experimental validation in simulated and real-world retail environments demonstrates superior robustness compared to existing scan-based methods, particularly under environmental changes. Further improvements are achieved through the probabilistic fusion of visual and scan-based localization.
Egocentric Action-aware Inertial Localization in Point Clouds
May 20, 2025



This paper presents a novel inertial localization framework named Egocentric Action-aware Inertial Localization (EAIL), which leverages egocentric action cues from head-mounted IMU signals to localize the target individual within a 3D point cloud. Human inertial localization is challenging due to IMU sensor noise that causes trajectory drift over time. The diversity of human actions further complicates IMU signal processing by introducing various motion patterns. Nevertheless, we observe that some actions observed through the head-mounted IMU correlate with spatial environmental structures (e.g., bending down to look inside an oven, washing dishes next to a sink), thereby serving as spatial anchors to compensate for the localization drift. The proposed EAIL framework learns such correlations via hierarchical multi-modal alignment. By assuming that the 3D point cloud of the environment is available, it contrastively learns modality encoders that align short-term egocentric action cues in IMU signals with local environmental features in the point cloud. These encoders are then used in reasoning the IMU data and the point cloud over time and space to perform inertial localization. Interestingly, these encoders can further be utilized to recognize the corresponding sequence of actions as a by-product. Extensive experiments demonstrate the effectiveness of the proposed framework over state-of-the-art inertial localization and inertial action recognition baselines.
Path Planning using Instruction-Guided Probabilistic Roadmaps
Feb 23, 2025



This work presents a novel data-driven path planning algorithm named Instruction-Guided Probabilistic Roadmap (IG-PRM). Despite the recent development and widespread use of mobile robot navigation, the safe and effective travels of mobile robots still require significant engineering effort to take into account the constraints of robots and their tasks. With IG-PRM, we aim to address this problem by allowing robot operators to specify such constraints through natural language instructions, such as ``aim for wider paths'' or ``mind small gaps''. The key idea is to convert such instructions into embedding vectors using large-language models (LLMs) and use the vectors as a condition to predict instruction-guided cost maps from occupancy maps. By constructing a roadmap based on the predicted costs, we can find instruction-guided paths via the standard shortest path search. Experimental results demonstrate the effectiveness of our approach on both synthetic and real-world indoor navigation environments.
Opt-in Camera: Person Identification in Video via UWB Localization and Its Application to Opt-in Systems
Sep 30, 2024



This paper presents opt-in camera, a concept of privacy-preserving camera systems capable of recording only specific individuals in a crowd who explicitly consent to be recorded. Our system utilizes a mobile wireless communication tag attached to personal belongings as proof of opt-in and as a means of localizing tag carriers in video footage. Specifically, the on-ground positions of the wireless tag are first tracked over time using the unscented Kalman filter (UKF). The tag trajectory is then matched against visual tracking results for pedestrians found in videos to identify the tag carrier. Technically, we devise a dedicated trajectory matching technique based on constrained linear optimization, as well as a novel calibration technique that handles wireless tag-camera calibration and hyperparameter tuning for the UKF, which mitigates the non-line-of-sight (NLoS) issue in wireless localization. We realize the proposed opt-in camera system using ultra-wideband (UWB) devices and an off-the-shelf webcam installed in the environment. Experimental results demonstrate that our system can perform opt-in recording of individuals in near real-time at 10 fps, with reliable identification accuracy for a crowd of 8-23 people in a confined space.
CXSimulator: A User Behavior Simulation using LLM Embeddings for Web-Marketing Campaign Assessment
Jul 31, 2024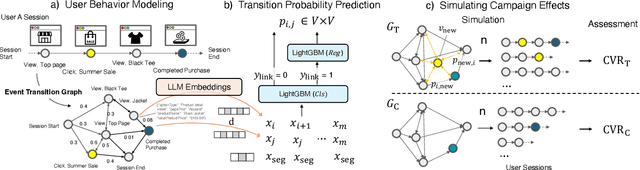



This paper presents the Customer Experience (CX) Simulator, a novel framework designed to assess the effects of untested web-marketing campaigns through user behavior simulations. The proposed framework leverages large language models (LLMs) to represent various events in a user's behavioral history, such as viewing an item, applying a coupon, or purchasing an item, as semantic embedding vectors. We train a model to predict transitions between events from their LLM embeddings, which can even generalize to unseen events by learning from diverse training data. In web-marketing applications, we leverage this transition prediction model to simulate how users might react differently when new campaigns or products are presented to them. This allows us to eliminate the need for costly online testing and enhance the marketers' abilities to reveal insights. Our numerical evaluation and user study, utilizing BigQuery Public Datasets from the Google Merchandise Store, demonstrate the effectiveness of our framework.
TSPDiffuser: Diffusion Models as Learned Samplers for Traveling Salesperson Path Planning Problems
Jun 05, 2024



This paper presents TSPDiffuser, a novel data-driven path planner for traveling salesperson path planning problems (TSPPPs) in environments rich with obstacles. Given a set of destinations within obstacle maps, our objective is to efficiently find the shortest possible collision-free path that visits all the destinations. In TSPDiffuser, we train a diffusion model on a large collection of TSPPP instances and their respective solutions to generate plausible paths for unseen problem instances. The model can then be employed as a learned sampler to construct a roadmap that contains potential solutions with a small number of nodes and edges. This approach enables efficient and accurate estimation of traveling costs between destinations, effectively addressing the primary computational challenge in solving TSPPPs. Experimental evaluations with diverse synthetic and real-world indoor/outdoor environments demonstrate the effectiveness of TSPDiffuser over existing methods in terms of the trade-off between solution quality and computational time requirements.
RetailOpt: An Opt-In, Easy-to-Deploy Trajectory Estimation System Leveraging Smartphone Motion Data and Retail Facility Information
Apr 19, 2024



We present RetailOpt, a novel opt-in, easy-to-deploy system for tracking customer movements in indoor retail environments. The system utilizes information presently accessible to customers through smartphones and retail apps: motion data, store map, and purchase records. The approach eliminates the need for additional hardware installations/maintenance and ensures customers maintain full control of their data. Specifically, RetailOpt first employs inertial navigation to recover relative trajectories from smartphone motion data. The store map and purchase records are then cross-referenced to identify a list of visited shelves, providing anchors to localize the relative trajectories in a store through continuous and discrete optimization. We demonstrate the effectiveness of our system through systematic experiments in five diverse environments. The proposed system, if successful, would produce accurate customer movement data, essential for a broad range of retail applications, including customer behavior analysis and in-store navigation. The potential application could also extend to other domains such as entertainment and assistive technologies.
Counterfactual Fairness Filter for Fair-Delay Multi-Robot Navigation
May 19, 2023



Multi-robot navigation is the task of finding trajectories for a team of robotic agents to reach their destinations as quickly as possible without collisions. In this work, we introduce a new problem: fair-delay multi-robot navigation, which aims not only to enable such efficient, safe travels but also to equalize the travel delays among agents in terms of actual trajectories as compared to the best possible trajectories. The learning of a navigation policy to achieve this objective requires resolving a nontrivial credit assignment problem with robotic agents having continuous action spaces. Hence, we developed a new algorithm called Navigation with Counterfactual Fairness Filter (NCF2). With NCF2, each agent performs counterfactual inference on whether it can advance toward its goal or should stay still to let other agents go. Doing so allows us to effectively address the aforementioned credit assignment problem and improve fairness regarding travel delays while maintaining high efficiency and safety. Our extensive experimental results in several challenging multi-robot navigation environments demonstrate the greater effectiveness of NCF2 as compared to state-of-the-art fairness-aware multi-agent reinforcement learning methods. Our demo videos and code are available on the project webpage: https://omron-sinicx.github.io/ncf2/
When to Replan? An Adaptive Replanning Strategy for Autonomous Navigation using Deep Reinforcement Learning
Apr 24, 2023The hierarchy of global and local planners is one of the most commonly utilized system designs in robot autonomous navigation. While the global planner generates a reference path from the current to goal locations based on the pre-built static map, the local planner produces a collision-free, kinodynamic trajectory to follow the reference path while avoiding perceived obstacles. The reference path should be replanned regularly to accommodate new obstacles that were absent in the pre-built map, but when to execute replanning remains an open question. In this work, we conduct an extensive simulation experiment to compare various replanning strategies and confirm that effective strategies highly depend on the environment as well as on the global and local planners. We then propose a new adaptive replanning strategy based on deep reinforcement learning, where an agent learns from experiences to decide appropriate replanning timings in the given environment and planning setups. Our experimental results demonstrate that the proposed replanning agent can achieve performance on par or even better than current best-performing strategies across multiple situations in terms of navigation robustness and efficiency.
Benchmarking Actor-Critic Deep Reinforcement Learning Algorithms for Robotics Control with Action Constraints
Apr 18, 2023



This study presents a benchmark for evaluating action-constrained reinforcement learning (RL) algorithms. In action-constrained RL, each action taken by the learning system must comply with certain constraints. These constraints are crucial for ensuring the feasibility and safety of actions in real-world systems. We evaluate existing algorithms and their novel variants across multiple robotics control environments, encompassing multiple action constraint types. Our evaluation provides the first in-depth perspective of the field, revealing surprising insights, including the effectiveness of a straightforward baseline approach. The benchmark problems and associated code utilized in our experiments are made available online at github.com/omron-sinicx/action-constrained-RL-benchmark for further research and development.