 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantized Inference for OneRec-V2
Mar 12, 2026Quantized inference has demonstrated substantial system-level benefits in large language models while preserving model quality. In contrast, reliably applying low-precision quantization to recommender systems remains challenging in industrial settings. This difficulty arises from differences in training paradigms, architectural patterns, and computational characteristics, which lead to distinct numerical behaviors in weights and activations. Traditional recommender models often exhibit high-magnitude and high-variance weights and activations, making them more sensitive to quantization-induced perturbations. In addition, recommendation workloads frequently suffer from limited hardware utilization, limiting the practical gains of low-precision computation. In this work, we revisit low-precision inference in the context of generative recommendation. Through empirical distribution analysis, we show that the weight and activation statistics of OneRec-V2 are significantly more controlled and closer to those of large language models than traditional recommendation models. Moreover, OneRec-V2 exhibits a more compute-intensive inference pattern with substantially higher hardware utilization, enabling more end-to-end throughput gains with low-precision computation. Leveraging this property, we develop a FP8 post training quantization framework and integrate it into an optimized inference infrastructure. The proposed joint optimization achieves a 49\% reduction in end-to-end inference latency and a 92\% increase in throughput. Extensive online A/B testing further confirms that FP8 inference introduces no degradation in core metrics. These results suggest that as recommender systems evolve toward the paradigms of large language models, algorithm-level and system-level optimization techniques established in the LLM domain can be effectively adapted to large-scale recommendation workloads.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
OneRec Technical Report
Jun 16, 2025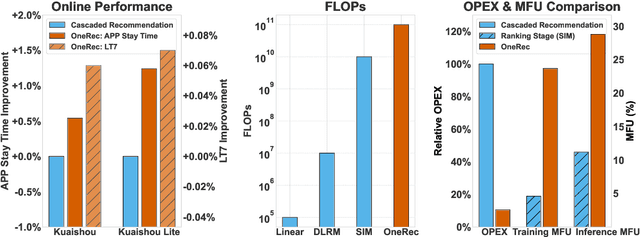

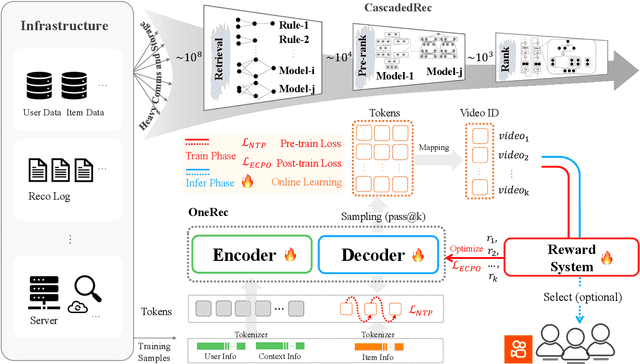
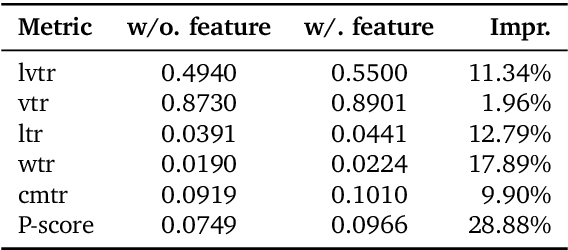
Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.