 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaF^2M^2: Comprehensive Learning and Responsive Leveraging Features in Recommendation System
Jan 27, 2025



Feature modeling, which involves feature representation learning and leveraging, plays an essential role in industrial recommendation systems. However, the data distribution in real-world applications usually follows a highly skewed long-tail pattern due to the popularity bias, which easily leads to over-reliance on ID-based features, such as user/item IDs and ID sequences of interactions. Such over-reliance makes it hard for models to learn features comprehensively, especially for those non-ID meta features, e.g., user/item characteristics. Further, it limits the feature leveraging ability in models, getting less generalized and more susceptible to data noise. Previous studies on feature modeling focus on feature extraction and interaction, hardly noticing the problems brought about by the long-tail data distribution. To achieve better feature representation learning and leveraging on real-world data, we propose a model-agnostic framework AdaF^2M^2, short for Adaptive Feature Modeling with Feature Mask. The feature-mask mechanism helps comprehensive feature learning via multi-forward training with augmented samples, while the adapter applies adaptive weights on features responsive to different user/item states. By arming base models with AdaF^2M^2, we conduct online A/B tests on multiple recommendation scenarios, obtaining +1.37% and +1.89% cumulative improvements on user active days and app duration respectively. Besides, the extended offline experiments on different models show improvements as well. AdaF$^2$M$^2$ has been widely deployed on both retrieval and ranking tasks in multiple applications of Douyin Group, indicating its superior effectiveness and universality.
Interest Clock: Time Perception in Real-Time Streaming Recommendation System
Apr 30, 2024



User preferences follow a dynamic pattern over a day, e.g., at 8 am, a user might prefer to read news, while at 8 pm, they might prefer to watch movies. Time modeling aims to enable recommendation systems to perceive time changes to capture users' dynamic preferences over time, which is an important and challenging problem in recommendation systems. Especially, streaming recommendation systems in the industry, with only available samples of the current moment, present greater challenges for time modeling. There is still a lack of effective time modeling methods for streaming recommendation systems. In this paper, we propose an effective and universal method Interest Clock to perceive time information in recommendation systems. Interest Clock first encodes users' time-aware preferences into a clock (hour-level personalized features) and then uses Gaussian distribution to smooth and aggregate them into the final interest clock embedding according to the current time for the final prediction. By arming base models with Interest Clock, we conduct online A/B tests, obtaining +0.509% and +0.758% improvements on user active days and app duration respectively. Besides, the extended offline experiments show improvements as well. Interest Clock has been deployed on Douyin Music App.
SPAN: A Stochastic Projected Approximate Newton Method
Mar 03, 2020
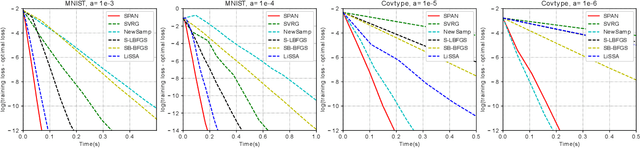
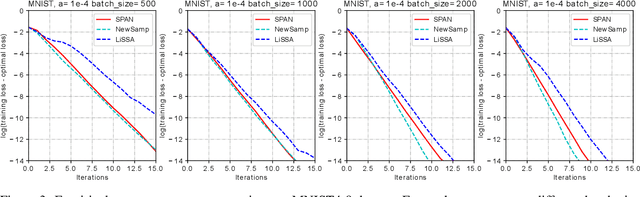
Second-order optimization methods have desirable convergence properties. However, the exact Newton method requires expensive computation for the Hessian and its inverse. In this paper, we propose SPAN, a novel approximate and fast Newton method. SPAN computes the inverse of the Hessian matrix via low-rank approximation and stochastic Hessian-vector products. Our experiments on multiple benchmark datasets demonstrate that SPAN outperforms existing first-order and second-order optimization methods in terms of the convergence wall-clock time. Furthermore, we provide a theoretical analysis of the per-iteration complexity, the approximation error, and the convergence rate. Both the theoretical analysis and experimental results show that our proposed method achieves a better trade-off between the convergence rate and the per-iteration efficiency.
BRITS: Bidirectional Recurrent Imputation for Time Series
May 27, 2018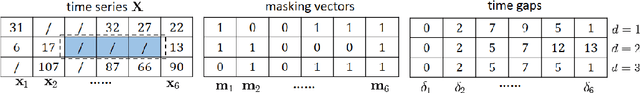
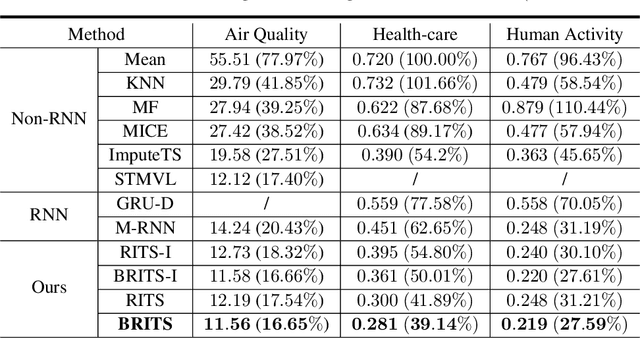
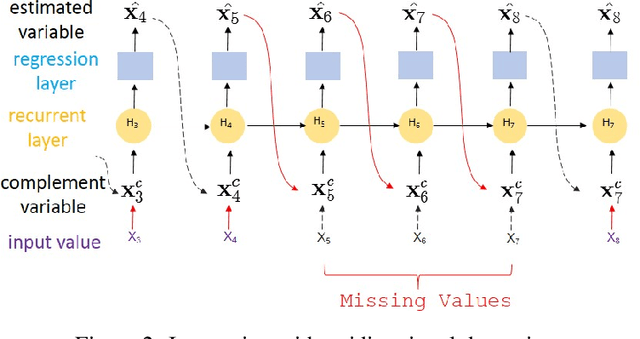
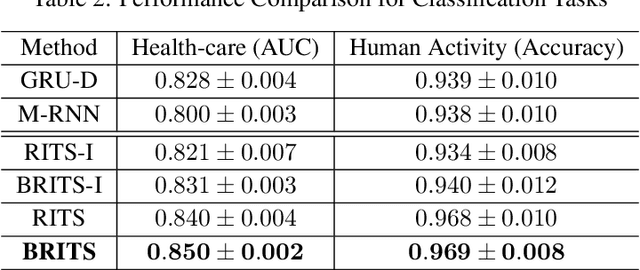
Time series are widely used as signals in many classification/regression tasks. It is ubiquitous that time series contains many missing values. Given multiple correlated time series data, how to fill in missing values and to predict their class labels? Existing imputation methods often impose strong assumptions of the underlying data generating process, such as linear dynamics in the state space. In this paper, we propose BRITS, a novel method based on recurrent neural networks for missing value imputation in time series data. Our proposed method directly learns the missing values in a bidirectional recurrent dynamical system, without any specific assumption. The imputed values are treated as variables of RNN graph and can be effectively updated during the backpropagation.BRITS has three advantages: (a) it can handle multiple correlated missing values in time series; (b) it generalizes to time series with nonlinear dynamics underlying; (c) it provides a data-driven imputation procedure and applies to general settings with missing data.We evaluate our model on three real-world datasets, including an air quality dataset, a health-care data, and a localization data for human activity. Experiments show that our model outperforms the state-of-the-art methods in both imputation and classification/regression accuracies.
Make Workers Work Harder: Decoupled Asynchronous Proximal Stochastic Gradient Descent
May 21, 2016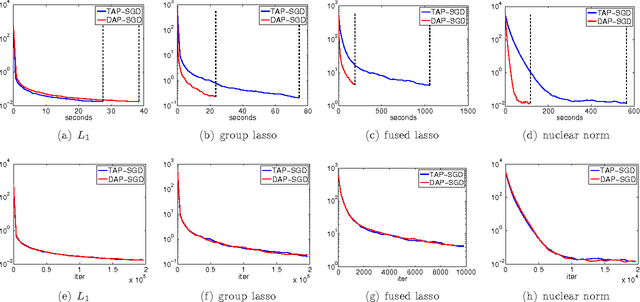
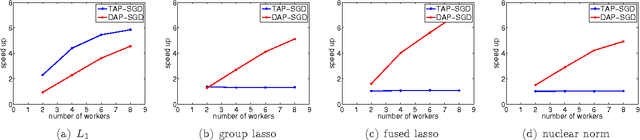
Asynchronous parallel optimization algorithms for solving large-scale machine learning problems have drawn significant attention from academia to industry recently. This paper proposes a novel algorithm, decoupled asynchronous proximal stochastic gradient descent (DAP-SGD), to minimize an objective function that is the composite of the average of multiple empirical losses and a regularization term. Unlike the traditional asynchronous proximal stochastic gradient descent (TAP-SGD) in which the master carries much of the computation load, the proposed algorithm off-loads the majority of computation tasks from the master to workers, and leaves the master to conduct simple addition operations. This strategy yields an easy-to-parallelize algorithm, whose performance is justified by theoretical convergence analyses. To be specific, DAP-SGD achieves an $O(\log T/T)$ rate when the step-size is diminishing and an ergodic $O(1/\sqrt{T})$ rate when the step-size is constant, where $T$ is the number of total iterations.