 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstantSticker: Realistic Decal Blending via Disentangled Object Reconstruction
Apr 09, 2025



We present InstantSticker, a disentangled reconstruction pipeline based on Image-Based Lighting (IBL), which focuses on highly realistic decal blending, simulates stickers attached to the reconstructed surface, and allows for instant editing and real-time rendering. To achieve stereoscopic impression of the decal, we introduce shadow factor into IBL, which can be adaptively optimized during training. This allows the shadow brightness of surfaces to be accurately decomposed rather than baked into the diffuse color, ensuring that the edited texture exhibits authentic shading. To address the issues of warping and blurriness in previous methods, we apply As-Rigid-As-Possible (ARAP) parameterization to pre-unfold a specified area of the mesh and use the local UV mapping combined with a neural texture map to enhance the ability to express high-frequency details in that area. For instant editing, we utilize the Disney BRDF model, explicitly defining material colors with 3-channel diffuse albedo. This enables instant replacement of albedo RGB values during the editing process, avoiding the prolonged optimization required in previous approaches. In our experiment, we introduce the Ratio Variance Warping (RVW) metric to evaluate the local geometric warping of the decal area. Extensive experimental results demonstrate that our method surpasses previous decal blending methods in terms of editing quality, editing speed and rendering speed, achieving the state-of-the-art.
DualNeRF: Text-Driven 3D Scene Editing via Dual-Field Representation
Feb 22, 2025



Recently, denoising diffusion models have achieved promising results in 2D image generation and editing. Instruct-NeRF2NeRF (IN2N) introduces the success of diffusion into 3D scene editing through an "Iterative dataset update" (IDU) strategy. Though achieving fascinating results, IN2N suffers from problems of blurry backgrounds and trapping in local optima. The first problem is caused by IN2N's lack of efficient guidance for background maintenance, while the second stems from the interaction between image editing and NeRF training during IDU. In this work, we introduce DualNeRF to deal with these problems. We propose a dual-field representation to preserve features of the original scene and utilize them as additional guidance to the model for background maintenance during IDU. Moreover, a simulated annealing strategy is embedded into IDU to endow our model with the power of addressing local optima issues. A CLIP-based consistency indicator is used to further improve the editing quality by filtering out low-quality edits. Extensive experiments demonstrate that our method outperforms previous methods both qualitatively and quantitatively.
AU-vMAE: Knowledge-Guide Action Units Detection via Video Masked Autoencoder
Jul 16, 2024



Current Facial Action Unit (FAU) detection methods generally encounter difficulties due to the scarcity of labeled video training data and the limited number of training face IDs, which renders the trained feature extractor insufficient coverage for modeling the large diversity of inter-person facial structures and movements. To explicitly address the above challenges, we propose a novel video-level pre-training scheme by fully exploring the multi-label property of FAUs in the video as well as the temporal label consistency. At the heart of our design is a pre-trained video feature extractor based on the video-masked autoencoder together with a fine-tuning network that jointly completes the multi-level video FAUs analysis tasks, \emph{i.e.} integrating both video-level and frame-level FAU detections, thus dramatically expanding the supervision set from sparse FAUs annotations to ALL video frames including masked ones. Moreover, we utilize inter-frame and intra-frame AU pair state matrices as prior knowledge to guide network training instead of traditional Graph Neural Networks, for better temporal supervision. Our approach demonstrates substantial enhancement in performance compared to the existing state-of-the-art methods used in BP4D and DISFA FAUs datasets.
Real-Time Neural BRDF with Spherically Distributed Primitives
Oct 12, 2023We propose a novel compact and efficient neural BRDF offering highly versatile material representation, yet with very-light memory and neural computation consumption towards achieving real-time rendering. The results in Figure 1, rendered at full HD resolution on a current desktop machine, show that our system achieves real-time rendering with a wide variety of appearances, which is approached by the following two designs. On the one hand, noting that bidirectional reflectance is distributed in a very sparse high-dimensional subspace, we propose to project the BRDF into two low-dimensional components, i.e., two hemisphere feature-grids for incoming and outgoing directions, respectively. On the other hand, learnable neural reflectance primitives are distributed on our highly-tailored spherical surface grid, which offer informative features for each component and alleviate the conventional heavy feature learning network to a much smaller one, leading to very fast evaluation. These primitives are centrally stored in a codebook and can be shared across multiple grids and even across materials, based on the low-cost indices stored in material-specific spherical surface grids. Our neural BRDF, which is agnostic to the material, provides a unified framework that can represent a variety of materials in consistent manner. Comprehensive experimental results on measured BRDF compression, Monte Carlo simulated BRDF acceleration, and extension to spatially varying effect demonstrate the superior quality and generalizability achieved by the proposed scheme.
SieveNet: Selecting Point-Based Features for Mesh Networks
Aug 24, 2023



Meshes are widely used in 3D computer vision and graphics, but their irregular topology poses challenges in applying them to existing neural network architectures. Recent advances in mesh neural networks turn to remeshing and push the boundary of pioneer methods that solely take the raw meshes as input. Although the remeshing offers a regular topology that significantly facilitates the design of mesh network architectures, features extracted from such remeshed proxies may struggle to retain the underlying geometry faithfully, limiting the subsequent neural network's capacity. To address this issue, we propose SieveNet, a novel paradigm that takes into account both the regular topology and the exact geometry. Specifically, this method utilizes structured mesh topology from remeshing and accurate geometric information from distortion-aware point sampling on the surface of the original mesh. Furthermore, our method eliminates the need for hand-crafted feature engineering and can leverage off-the-shelf network architectures such as the vision transformer. Comprehensive experimental results on classification and segmentation tasks well demonstrate the effectiveness and superiority of our method.
FocalDreamer: Text-driven 3D Editing via Focal-fusion Assembly
Aug 22, 2023



While text-3D editing has made significant strides in leveraging score distillation sampling, emerging approaches still fall short in delivering separable, precise and consistent outcomes that are vital to content creation. In response, we introduce FocalDreamer, a framework that merges base shape with editable parts according to text prompts for fine-grained editing within desired regions. Specifically, equipped with geometry union and dual-path rendering, FocalDreamer assembles independent 3D parts into a complete object, tailored for convenient instance reuse and part-wise control. We propose geometric focal loss and style consistency regularization, which encourage focal fusion and congruent overall appearance. Furthermore, FocalDreamer generates high-fidelity geometry and PBR textures which are compatible with widely-used graphics engines. Extensive experiments have highlighted the superior editing capabilities of FocalDreamer in both quantitative and qualitative evaluations.
3DQD: Generalized Deep 3D Shape Prior via Part-Discretized Diffusion Process
Mar 18, 2023



We develop a generalized 3D shape generation prior model, tailored for multiple 3D tasks including unconditional shape generation, point cloud completion, and cross-modality shape generation, etc. On one hand, to precisely capture local fine detailed shape information, a vector quantized variational autoencoder (VQ-VAE) is utilized to index local geometry from a compactly learned codebook based on a broad set of task training data. On the other hand, a discrete diffusion generator is introduced to model the inherent structural dependencies among different tokens. In the meantime, a multi-frequency fusion module (MFM) is developed to suppress high-frequency shape feature fluctuations, guided by multi-frequency contextual information. The above designs jointly equip our proposed 3D shape prior model with high-fidelity, diverse features as well as the capability of cross-modality alignment, and extensive experiments have demonstrated superior performances on various 3D shape generation tasks.
Imitating Arbitrary Talking Style for Realistic Audio-DrivenTalking Face Synthesis
Oct 30, 2021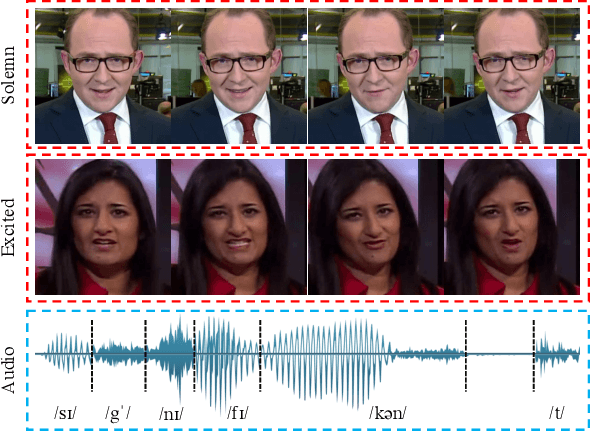
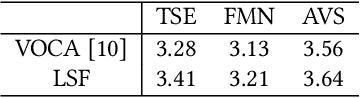
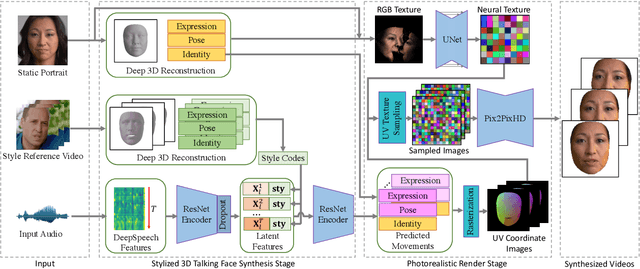
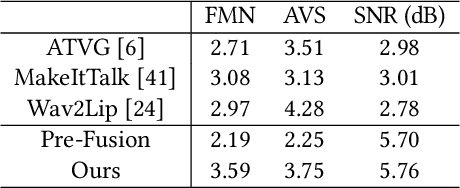
People talk with diversified styles. For one piece of speech, different talking styles exhibit significant differences in the facial and head pose movements. For example, the "excited" style usually talks with the mouth wide open, while the "solemn" style is more standardized and seldomly exhibits exaggerated motions. Due to such huge differences between different styles, it is necessary to incorporate the talking style into audio-driven talking face synthesis framework. In this paper, we propose to inject style into the talking face synthesis framework through imitating arbitrary talking style of the particular reference video. Specifically, we systematically investigate talking styles with our collected \textit{Ted-HD} dataset and construct style codes as several statistics of 3D morphable model~(3DMM) parameters. Afterwards, we devise a latent-style-fusion~(LSF) model to synthesize stylized talking faces by imitating talking styles from the style codes. We emphasize the following novel characteristics of our framework: (1) It doesn't require any annotation of the style, the talking style is learned in an unsupervised manner from talking videos in the wild. (2) It can imitate arbitrary styles from arbitrary videos, and the style codes can also be interpolated to generate new styles. Extensive experiments demonstrate that the proposed framework has the ability to synthesize more natural and expressive talking styles compared with baseline methods.