 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFTP-1: A Generalist Foundation Tactile Policy Across Tactile Sensors for Contact-Rich Manipulation
Jun 11, 2026Despite the success of vision-based generalist robotic policies, existing tactile-based policies remain tied to fixed embodiments and sensor setups. This is because tactile signals are highly heterogeneous across hardware, making cross-sensor generalization difficult. We present FTP-1,the first generalist foundation tactile policy pretrained to acquire transferable tactile manipulation abilities across diverse sensors and embodiments. FTP-1 supports varied tactile inputs, including image-, array-, and state-based signals, by using heterogeneous encoders to project them into unified morphology-aware latent tokens that are jointly modeled by a shared tactile Transformer expert. Pretrained on around 3,000 hours of tactile manipulation data aggregated from 26 data sources, spanning human and robot demonstrations across 21 sensors, FTP-1 learns tactile skills that transfer beyond the sensors seen during pretraining. Across downstream finetuning experiments spanning 5 hardware configurations, FTP-1 improves contact-rich manipulation on seen sensor setups by +17.2% and, surprisingly, transfers to two previously unseen tactile-sensor setups, achieving a +31% gain in success rate. FTP-1 establishes the first unified foundation baseline for tactile manipulation, providing future tactile policies with a shared model-level starting point. Pretrained models, datasets, training code and more visualization at https://ftp1-policy.github.io.
LLaVA-OneVision-2: Towards Next-Generation Perceptual Intelligence
May 25, 2026We introduce LLaVA-OneVision-2 (LLaVA-OV-2), the most capable vision-language model in the LLaVA-OneVision series to date, achieving superior performance across a broad range of multimodal benchmarks. The model builds on a native OneVision-Encoder and incorporates Windowed Attention for efficient local computation while maintaining native resolution. Its key advance is codec-stream tokenization: it treats compressed video as a continuous bit-cost stream, where bit-cost dynamics determine adaptive temporal groups, and motion-residual cues select salient spatial evidence into compact visual canvases. This allocation concentrates a limited token budget on event-bearing content, enabling more stable long-video token compression than fixed groups of pictures. A shared 3D RoPE further places codec canvases, sampled frames, and images in a unified spatiotemporal coordinate system. Furthermore, we build the LLaVA-OV-2 data and training stack around large-scale open supervision: approximately 8M re-captioned video samples for pretraining, a 4M-sample spatial corpus for fine-tuning. We also introduce JumpScore, a temporal-localization benchmark targeting fine-grained grounding in high-frequency, densely repeated motion, a regime underrepresented by existing video evaluations. A standout capability of LLaVA-OV-2 is its unified perception across video understanding, temporal grounding, spatial grounding, and manipulation-trace reasoning. On JumpScore, LLaVA-OneVision-2-8B reaches 74.9 JumpScore mAP, surpassing Qwen3-VL-8B (30.1) by +44.8 points; under matched visual-token budgets on the same benchmark, codec-stream inputs improve temporal grounding over frame sampling by +9.7 points. Across standard benchmarks, LLaVA-OneVision-2-8B further outperforms Qwen3-VL-8B by +4.3 average points on video tasks, +5.3 on spatial tasks, and +15.6 average J&F on tracking tasks.
UW-VOS: A Large-Scale Dataset for Underwater Video Object Segmentation
Mar 25, 2026Underwater Video Object Segmentation (VOS) is essential for marine exploration, yet open-air methods suffer significant degradation due to color distortion, low contrast, and prevalent camouflage. A primary hurdle is the lack of high-quality training data. To bridge this gap, we introduce $\textbf{UW-VOS}$, the first large-scale underwater VOS benchmark comprising 1,431 video sequences across 409 categories with 309,295 mask annotations, constructed via a semi-automatic data engine with rigorous human verification. We further propose $\textbf{SAM-U}$, a parameter-efficient framework that adapts SAM2 to the underwater domain. By inserting lightweight adapters into the image encoder, SAM-U achieves state-of-the-art performance with only $\sim$2$\%$ trainable parameters. Extensive experiments reveal that existing methods experience an average 13-point $\mathcal{J}\&\mathcal{F}$ drop on UW-VOS, while SAM-U effectively bridges this domain gap. Detailed attribute-based analysis further identifies small targets, camouflage, and exit-re-entry as critical bottlenecks, providing a roadmap for future research in robust underwater perception.
OmniVTLA: Vision-Tactile-Language-Action Model with Semantic-Aligned Tactile Sensing
Aug 12, 2025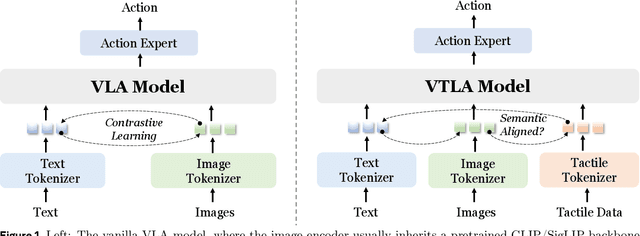

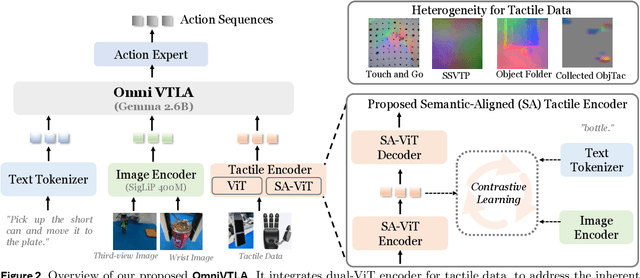

Recent vision-language-action (VLA) models build upon vision-language foundations, and have achieved promising results and exhibit the possibility of task generalization in robot manipulation. However, due to the heterogeneity of tactile sensors and the difficulty of acquiring tactile data, current VLA models significantly overlook the importance of tactile perception and fail in contact-rich tasks. To address this issue, this paper proposes OmniVTLA, a novel architecture involving tactile sensing. Specifically, our contributions are threefold. First, our OmniVTLA features a dual-path tactile encoder framework. This framework enhances tactile perception across diverse vision-based and force-based tactile sensors by using a pretrained vision transformer (ViT) and a semantically-aligned tactile ViT (SA-ViT). Second, we introduce ObjTac, a comprehensive force-based tactile dataset capturing textual, visual, and tactile information for 56 objects across 10 categories. With 135K tri-modal samples, ObjTac supplements existing visuo-tactile datasets. Third, leveraging this dataset, we train a semantically-aligned tactile encoder to learn a unified tactile representation, serving as a better initialization for OmniVTLA. Real-world experiments demonstrate substantial improvements over state-of-the-art VLA baselines, achieving 96.9% success rates with grippers, (21.9% higher over baseline) and 100% success rates with dexterous hands (6.2% higher over baseline) in pick-and-place tasks. Besides, OmniVTLA significantly reduces task completion time and generates smoother trajectories through tactile sensing compared to existing VLA.
Mamba-Adaptor: State Space Model Adaptor for Visual Recognition
May 19, 2025Recent State Space Models (SSM), especially Mamba, have demonstrated impressive performance in visual modeling and possess superior model efficiency. However, the application of Mamba to visual tasks suffers inferior performance due to three main constraints existing in the sequential model: 1) Casual computing is incapable of accessing global context; 2) Long-range forgetting when computing the current hidden states; 3) Weak spatial structural modeling due to the transformed sequential input. To address these issues, we investigate a simple yet powerful vision task Adaptor for Mamba models, which consists of two functional modules: Adaptor-T and Adaptor-S. When solving the hidden states for SSM, we apply a lightweight prediction module Adaptor-T to select a set of learnable locations as memory augmentations to ease long-range forgetting issues. Moreover, we leverage Adapator-S, composed of multi-scale dilated convolutional kernels, to enhance the spatial modeling and introduce the image inductive bias into the feature output. Both modules can enlarge the context modeling in casual computing, as the output is enhanced by the inaccessible features. We explore three usages of Mamba-Adaptor: A general visual backbone for various vision tasks; A booster module to raise the performance of pretrained backbones; A highly efficient fine-tuning module that adapts the base model for transfer learning tasks. Extensive experiments verify the effectiveness of Mamba-Adaptor in three settings. Notably, our Mamba-Adaptor achieves state-of the-art performance on the ImageNet and COCO benchmarks.