 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaCo: A Benchmark for Lossless and Lossy Codecs of Heterogeneous Tactile Data
Feb 10, 2026Tactile sensing is crucial for embodied intelligence, providing fine-grained perception and control in complex environments. However, efficient tactile data compression, which is essential for real-time robotic applications under strict bandwidth constraints, remains underexplored. The inherent heterogeneity and spatiotemporal complexity of tactile data further complicate this challenge. To bridge this gap, we introduce TaCo, the first comprehensive benchmark for Tactile data Codecs. TaCo evaluates 30 compression methods, including off-the-shelf compression algorithms and neural codecs, across five diverse datasets from various sensor types. We systematically assess both lossless and lossy compression schemes on four key tasks: lossless storage, human visualization, material and object classification, and dexterous robotic grasping. Notably, we pioneer the development of data-driven codecs explicitly trained on tactile data, TaCo-LL (lossless) and TaCo-L (lossy). Results have validated the superior performance of our TaCo-LL and TaCo-L. This benchmark provides a foundational framework for understanding the critical trade-offs between compression efficiency and task performance, paving the way for future advances in tactile perception.
RoboPaint: From Human Demonstration to Any Robot and Any View
Feb 05, 2026Acquiring large-scale, high-fidelity robot demonstration data remains a critical bottleneck for scaling Vision-Language-Action (VLA) models in dexterous manipulation. We propose a Real-Sim-Real data collection and data editing pipeline that transforms human demonstrations into robot-executable, environment-specific training data without direct robot teleoperation. Standardized data collection rooms are built to capture multimodal human demonstrations (synchronized 3 RGB-D videos, 11 RGB videos, 29-DoF glove joint angles, and 14-channel tactile signals). Based on these human demonstrations, we introduce a tactile-aware retargeting method that maps human hand states to robot dex-hand states via geometry and force-guided optimization. Then the retargeted robot trajectories are rendered in a photorealistic Isaac Sim environment to build robot training data. Real world experiments have demonstrated: (1) The retargeted dex-hand trajectories achieve an 84\% success rate across 10 diverse object manipulation tasks. (2) VLA policies (Pi0.5) trained exclusively on our generated data achieve 80\% average success rate on three representative tasks, i.e., pick-and-place, pushing and pouring. To conclude, robot training data can be efficiently "painted" from human demonstrations using our real-sim-real data pipeline. We offer a scalable, cost-effective alternative to teleoperation with minimal performance loss for complex dexterous manipulation.
OmniVTLA: Vision-Tactile-Language-Action Model with Semantic-Aligned Tactile Sensing
Aug 12, 2025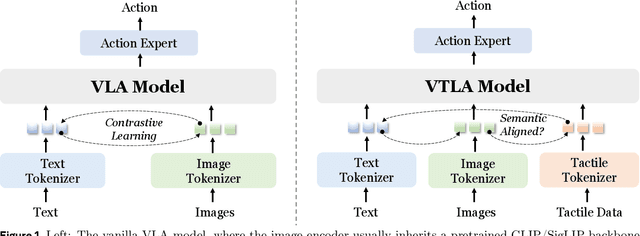

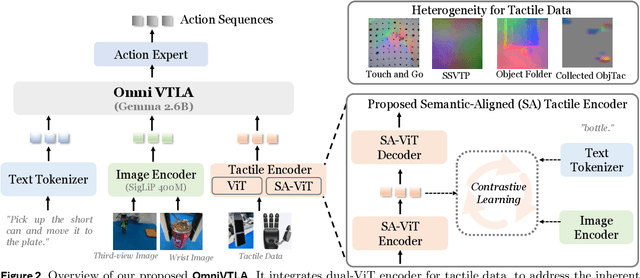

Recent vision-language-action (VLA) models build upon vision-language foundations, and have achieved promising results and exhibit the possibility of task generalization in robot manipulation. However, due to the heterogeneity of tactile sensors and the difficulty of acquiring tactile data, current VLA models significantly overlook the importance of tactile perception and fail in contact-rich tasks. To address this issue, this paper proposes OmniVTLA, a novel architecture involving tactile sensing. Specifically, our contributions are threefold. First, our OmniVTLA features a dual-path tactile encoder framework. This framework enhances tactile perception across diverse vision-based and force-based tactile sensors by using a pretrained vision transformer (ViT) and a semantically-aligned tactile ViT (SA-ViT). Second, we introduce ObjTac, a comprehensive force-based tactile dataset capturing textual, visual, and tactile information for 56 objects across 10 categories. With 135K tri-modal samples, ObjTac supplements existing visuo-tactile datasets. Third, leveraging this dataset, we train a semantically-aligned tactile encoder to learn a unified tactile representation, serving as a better initialization for OmniVTLA. Real-world experiments demonstrate substantial improvements over state-of-the-art VLA baselines, achieving 96.9% success rates with grippers, (21.9% higher over baseline) and 100% success rates with dexterous hands (6.2% higher over baseline) in pick-and-place tasks. Besides, OmniVTLA significantly reduces task completion time and generates smoother trajectories through tactile sensing compared to existing VLA.
TacCompress: A Benchmark for Multi-Point Tactile Data Compression in Dexterous Manipulation
May 22, 2025Though robotic dexterous manipulation has progressed substantially recently, challenges like in-hand occlusion still necessitate fine-grained tactile perception, leading to the integration of more tactile sensors into robotic hands. Consequently, the increased data volume imposes substantial bandwidth pressure on signal transmission from the hand's controller. However, the acquisition and compression of multi-point tactile signals based on the dexterous hands' physical structures have not been thoroughly explored. In this paper, our contributions are twofold. First, we introduce a Multi-Point Tactile Dataset for Dexterous Hand Grasping (Dex-MPTD). This dataset captures tactile signals from multiple contact sensors across various objects and grasping poses, offering a comprehensive benchmark for advancing dexterous robotic manipulation research. Second, we investigate both lossless and lossy compression on Dex-MPTD by converting tactile data into images and applying six lossless and five lossy image codecs for efficient compression. Experimental results demonstrate that tactile data can be losslessly compressed to as low as 0.0364 bits per sub-sample (bpss), achieving approximately 200$\times$ compression ratio compared to the raw tactile data. Efficient lossy compressors like HM and VTM can achieve about 1000x data reductions while preserving acceptable data fidelity. The exploration of lossy compression also reveals that screen-content-targeted coding tools outperform general-purpose codecs in compressing tactile data.