 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Style and Semantic Memory Mechanism for Domain Generalization
Dec 14, 2021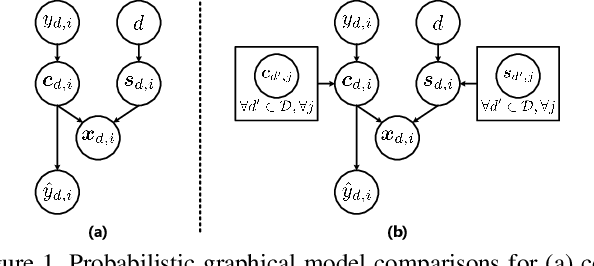
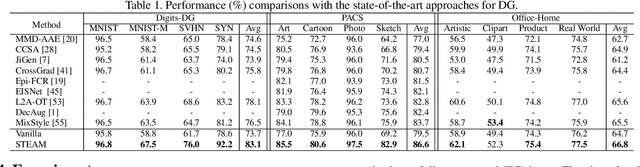
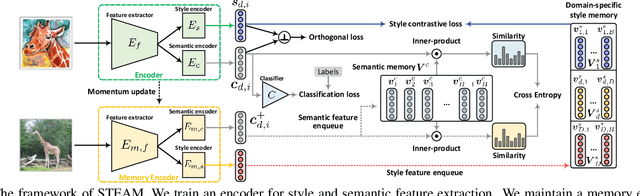
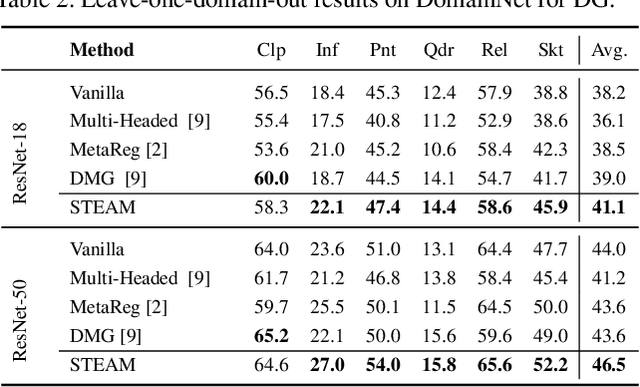
Mainstream state-of-the-art domain generalization algorithms tend to prioritize the assumption on semantic invariance across domains. Meanwhile, the inherent intra-domain style invariance is usually underappreciated and put on the shelf. In this paper, we reveal that leveraging intra-domain style invariance is also of pivotal importance in improving the efficiency of domain generalization. We verify that it is critical for the network to be informative on what domain features are invariant and shared among instances, so that the network sharpens its understanding and improves its semantic discriminative ability. Correspondingly, we also propose a novel "jury" mechanism, which is particularly effective in learning useful semantic feature commonalities among domains. Our complete model called STEAM can be interpreted as a novel probabilistic graphical model, for which the implementation requires convenient constructions of two kinds of memory banks: semantic feature bank and style feature bank. Empirical results show that our proposed framework surpasses the state-of-the-art methods by clear margins.
Transferrable Contrastive Learning for Visual Domain Adaptation
Dec 14, 2021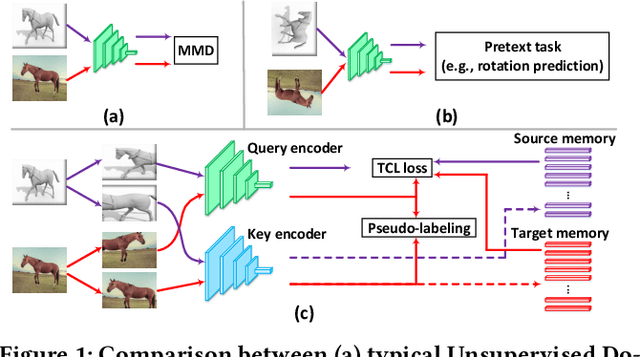
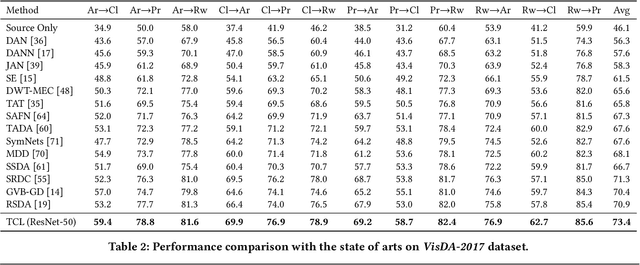
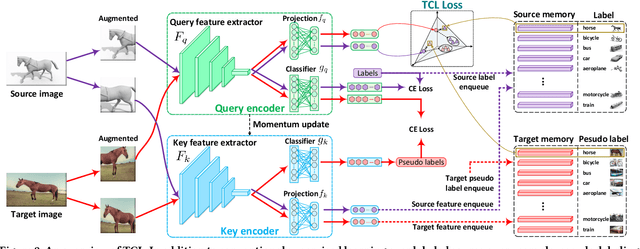
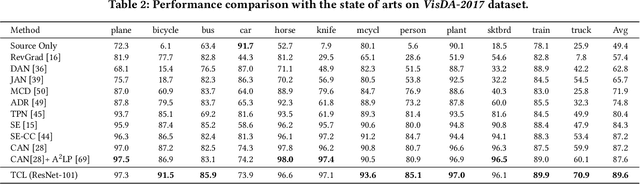
Self-supervised learning (SSL) has recently become the favorite among feature learning methodologies. It is therefore appealing for domain adaptation approaches to consider incorporating SSL. The intuition is to enforce instance-level feature consistency such that the predictor becomes somehow invariant across domains. However, most existing SSL methods in the regime of domain adaptation usually are treated as standalone auxiliary components, leaving the signatures of domain adaptation unattended. Actually, the optimal region where the domain gap vanishes and the instance level constraint that SSL peruses may not coincide at all. From this point, we present a particular paradigm of self-supervised learning tailored for domain adaptation, i.e., Transferrable Contrastive Learning (TCL), which links the SSL and the desired cross-domain transferability congruently. We find contrastive learning intrinsically a suitable candidate for domain adaptation, as its instance invariance assumption can be conveniently promoted to cross-domain class-level invariance favored by domain adaptation tasks. Based on particular memory bank constructions and pseudo label strategies, TCL then penalizes cross-domain intra-class domain discrepancy between source and target through a clean and novel contrastive loss. The free lunch is, thanks to the incorporation of contrastive learning, TCL relies on a moving-averaged key encoder that naturally achieves a temporally ensembled version of pseudo labels for target data, which avoids pseudo label error propagation at no extra cost. TCL therefore efficiently reduces cross-domain gaps. Through extensive experiments on benchmarks (Office-Home, VisDA-2017, Digits-five, PACS and DomainNet) for both single-source and multi-source domain adaptation tasks, TCL has demonstrated state-of-the-art performances.
CoCo-BERT: Improving Video-Language Pre-training with Contrastive Cross-modal Matching and Denoising
Dec 14, 2021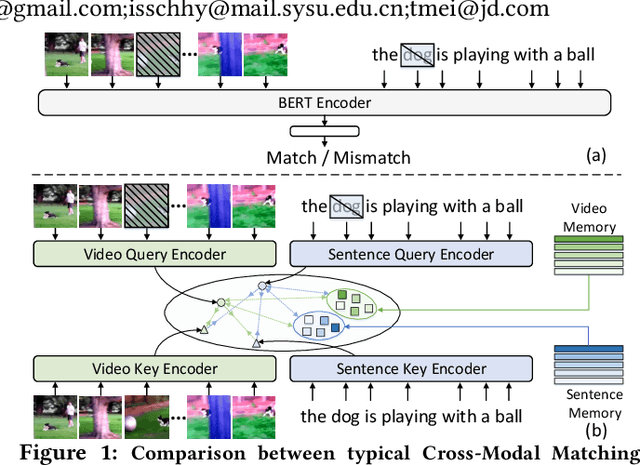
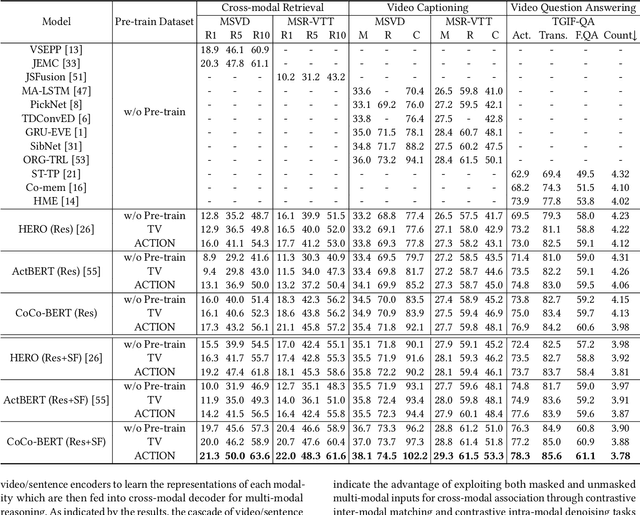
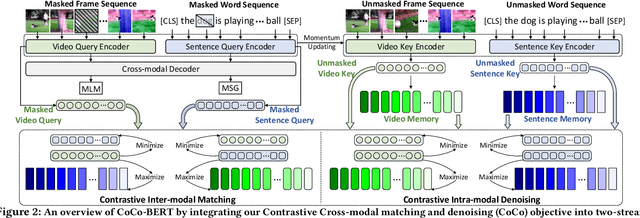
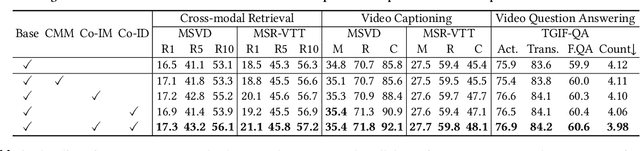
BERT-type structure has led to the revolution of vision-language pre-training and the achievement of state-of-the-art results on numerous vision-language downstream tasks. Existing solutions dominantly capitalize on the multi-modal inputs with mask tokens to trigger mask-based proxy pre-training tasks (e.g., masked language modeling and masked object/frame prediction). In this work, we argue that such masked inputs would inevitably introduce noise for cross-modal matching proxy task, and thus leave the inherent vision-language association under-explored. As an alternative, we derive a particular form of cross-modal proxy objective for video-language pre-training, i.e., Contrastive Cross-modal matching and denoising (CoCo). By viewing the masked frame/word sequences as the noisy augmentation of primary unmasked ones, CoCo strengthens video-language association by simultaneously pursuing inter-modal matching and intra-modal denoising between masked and unmasked inputs in a contrastive manner. Our CoCo proxy objective can be further integrated into any BERT-type encoder-decoder structure for video-language pre-training, named as Contrastive Cross-modal BERT (CoCo-BERT). We pre-train CoCo-BERT on TV dataset and a newly collected large-scale GIF video dataset (ACTION). Through extensive experiments over a wide range of downstream tasks (e.g., cross-modal retrieval, video question answering, and video captioning), we demonstrate the superiority of CoCo-BERT as a pre-trained structure.
CORE-Text: Improving Scene Text Detection with Contrastive Relational Reasoning
Dec 14, 2021
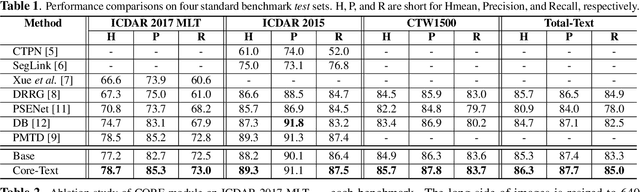
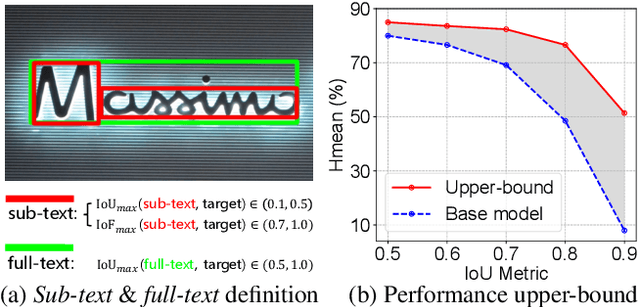
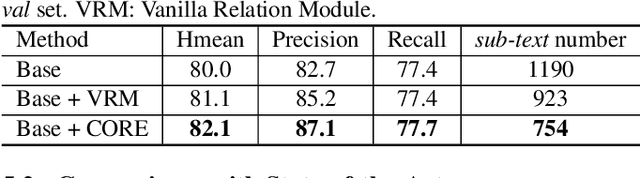
Localizing text instances in natural scenes is regarded as a fundamental challenge in computer vision. Nevertheless, owing to the extremely varied aspect ratios and scales of text instances in real scenes, most conventional text detectors suffer from the sub-text problem that only localizes the fragments of text instance (i.e., sub-texts). In this work, we quantitatively analyze the sub-text problem and present a simple yet effective design, COntrastive RElation (CORE) module, to mitigate that issue. CORE first leverages a vanilla relation block to model the relations among all text proposals (sub-texts of multiple text instances) and further enhances relational reasoning via instance-level sub-text discrimination in a contrastive manner. Such way naturally learns instance-aware representations of text proposals and thus facilitates scene text detection. We integrate the CORE module into a two-stage text detector of Mask R-CNN and devise our text detector CORE-Text. Extensive experiments on four benchmarks demonstrate the superiority of CORE-Text. Code is available: \url{https://github.com/jylins/CORE-Text}.
X-modaler: A Versatile and High-performance Codebase for Cross-modal Analytics
Aug 18, 2021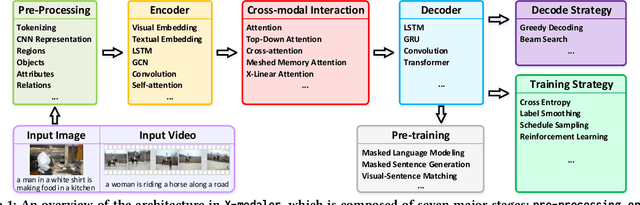
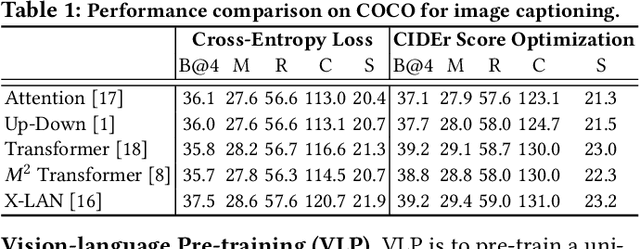
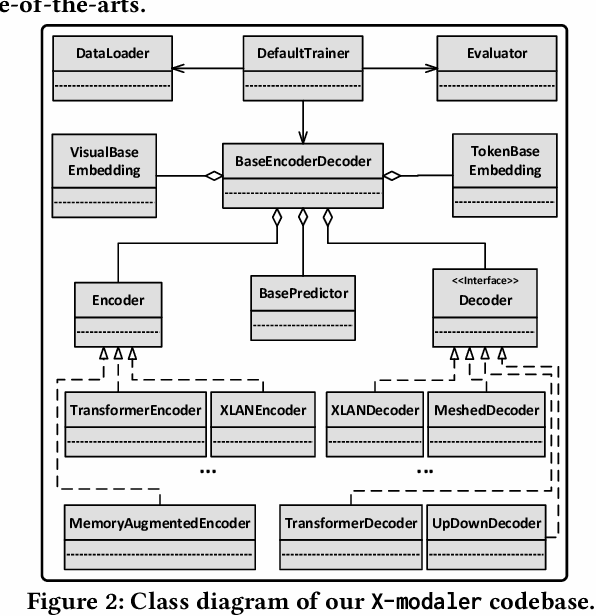
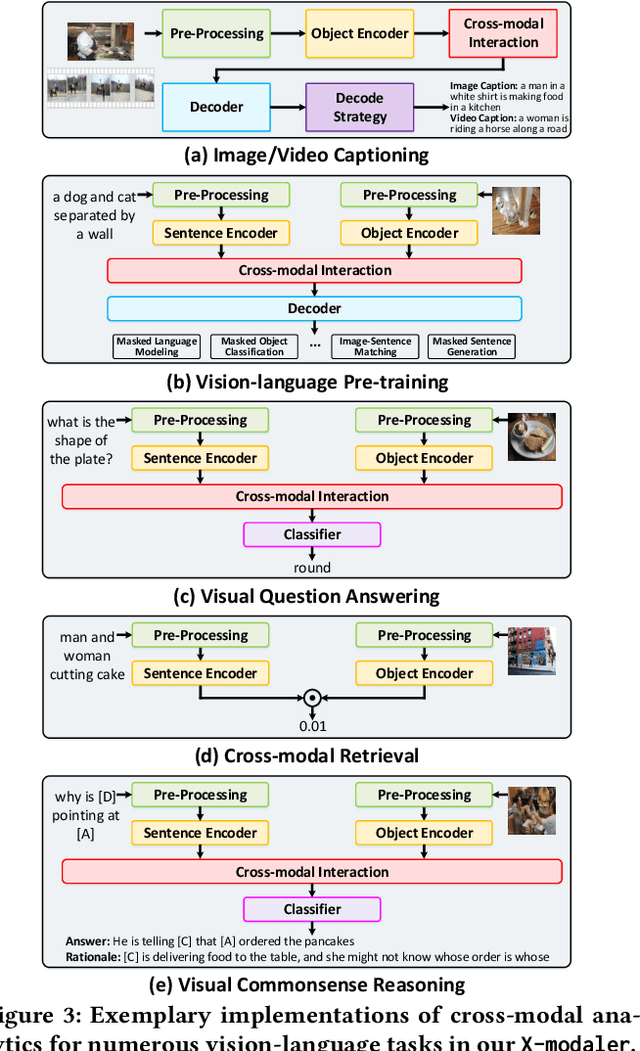
With the rise and development of deep learning over the past decade, there has been a steady momentum of innovation and breakthroughs that convincingly push the state-of-the-art of cross-modal analytics between vision and language in multimedia field. Nevertheless, there has not been an open-source codebase in support of training and deploying numerous neural network models for cross-modal analytics in a unified and modular fashion. In this work, we propose X-modaler -- a versatile and high-performance codebase that encapsulates the state-of-the-art cross-modal analytics into several general-purpose stages (e.g., pre-processing, encoder, cross-modal interaction, decoder, and decode strategy). Each stage is empowered with the functionality that covers a series of modules widely adopted in state-of-the-arts and allows seamless switching in between. This way naturally enables a flexible implementation of state-of-the-art algorithms for image captioning, video captioning, and vision-language pre-training, aiming to facilitate the rapid development of research community. Meanwhile, since the effective modular designs in several stages (e.g., cross-modal interaction) are shared across different vision-language tasks, X-modaler can be simply extended to power startup prototypes for other tasks in cross-modal analytics, including visual question answering, visual commonsense reasoning, and cross-modal retrieval. X-modaler is an Apache-licensed codebase, and its source codes, sample projects and pre-trained models are available on-line: https://github.com/YehLi/xmodaler.
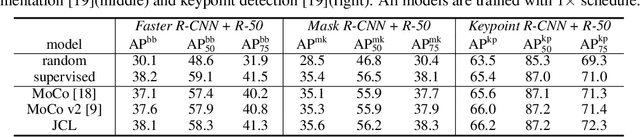
A Low Rank Promoting Prior for Unsupervised Contrastive Learning
Aug 05, 2021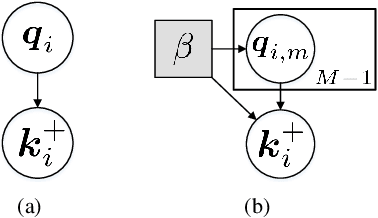
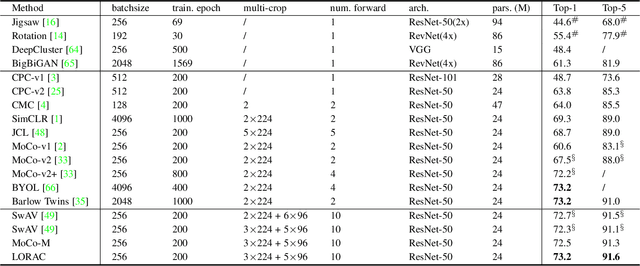
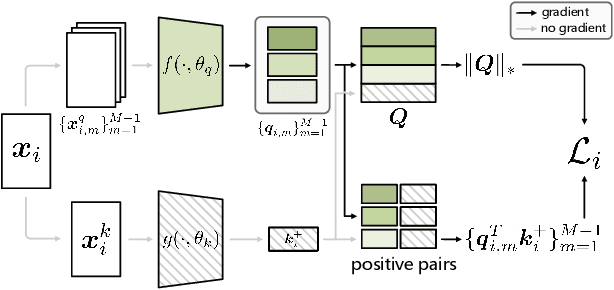

Unsupervised learning is just at a tipping point where it could really take off. Among these approaches, contrastive learning has seen tremendous progress and led to state-of-the-art performance. In this paper, we construct a novel probabilistic graphical model that effectively incorporates the low rank promoting prior into the framework of contrastive learning, referred to as LORAC. In contrast to the existing conventional self-supervised approaches that only considers independent learning, our hypothesis explicitly requires that all the samples belonging to the same instance class lie on the same subspace with small dimension. This heuristic poses particular joint learning constraints to reduce the degree of freedom of the problem during the search of the optimal network parameterization. Most importantly, we argue that the low rank prior employed here is not unique, and many different priors can be invoked in a similar probabilistic way, corresponding to different hypotheses about underlying truth behind the contrastive features. Empirical evidences show that the proposed algorithm clearly surpasses the state-of-the-art approaches on multiple benchmarks, including image classification, object detection, instance segmentation and keypoint detection.
Contextual Transformer Networks for Visual Recognition
Jul 26, 2021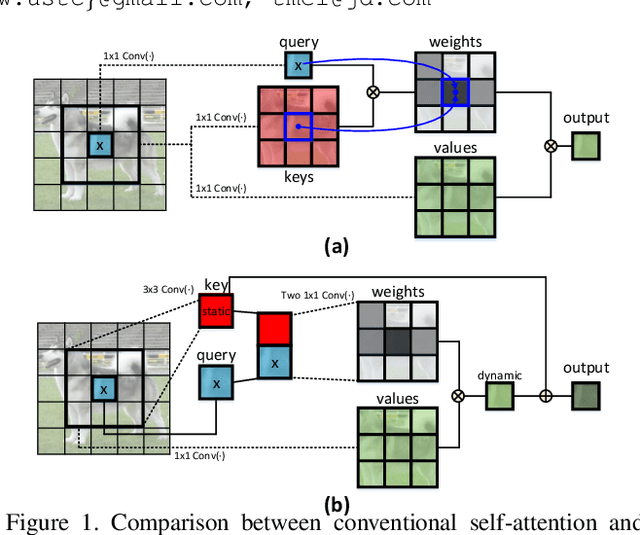
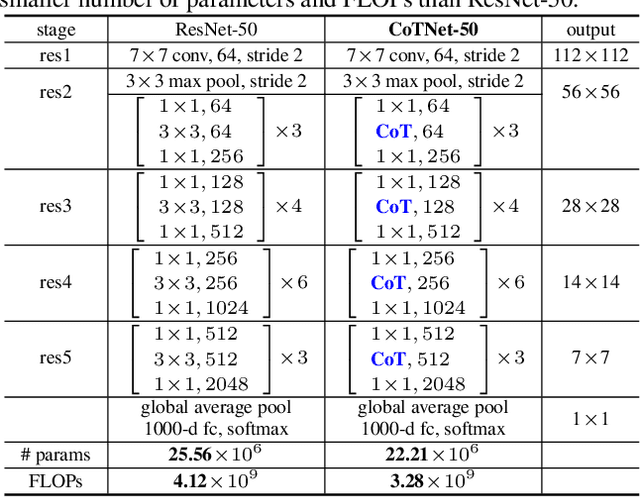
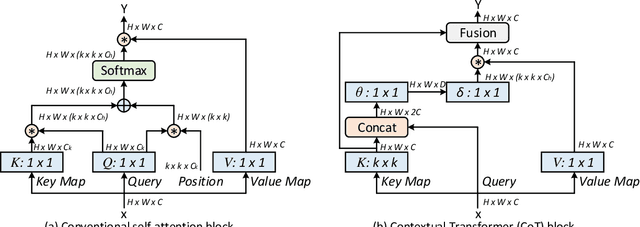
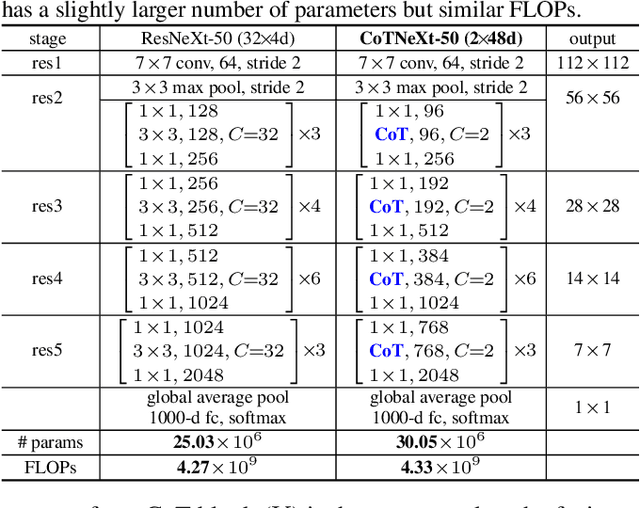
Transformer with self-attention has led to the revolutionizing of natural language processing field, and recently inspires the emergence of Transformer-style architecture design with competitive results in numerous computer vision tasks. Nevertheless, most of existing designs directly employ self-attention over a 2D feature map to obtain the attention matrix based on pairs of isolated queries and keys at each spatial location, but leave the rich contexts among neighbor keys under-exploited. In this work, we design a novel Transformer-style module, i.e., Contextual Transformer (CoT) block, for visual recognition. Such design fully capitalizes on the contextual information among input keys to guide the learning of dynamic attention matrix and thus strengthens the capacity of visual representation. Technically, CoT block first contextually encodes input keys via a $3\times3$ convolution, leading to a static contextual representation of inputs. We further concatenate the encoded keys with input queries to learn the dynamic multi-head attention matrix through two consecutive $1\times1$ convolutions. The learnt attention matrix is multiplied by input values to achieve the dynamic contextual representation of inputs. The fusion of the static and dynamic contextual representations are finally taken as outputs. Our CoT block is appealing in the view that it can readily replace each $3\times3$ convolution in ResNet architectures, yielding a Transformer-style backbone named as Contextual Transformer Networks (CoTNet). Through extensive experiments over a wide range of applications (e.g., image recognition, object detection and instance segmentation), we validate the superiority of CoTNet as a stronger backbone. Source code is available at \url{https://github.com/JDAI-CV/CoTNet}.
Scheduled Sampling in Vision-Language Pretraining with Decoupled Encoder-Decoder Network
Jan 27, 2021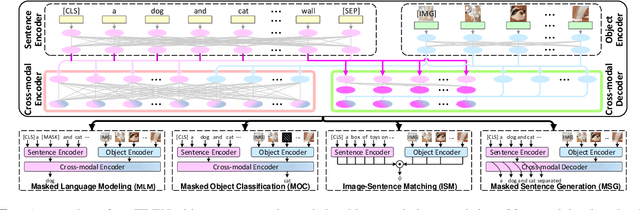
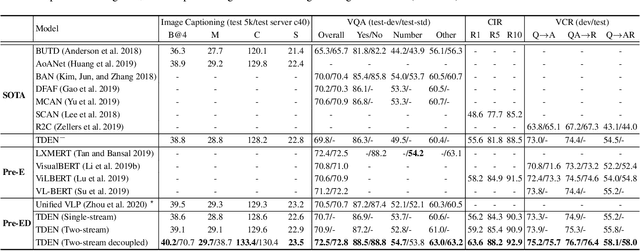

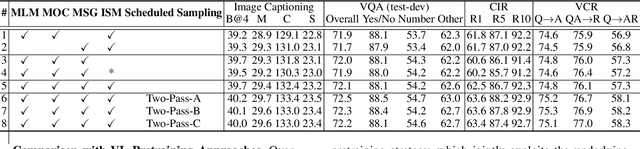
Despite having impressive vision-language (VL) pretraining with BERT-based encoder for VL understanding, the pretraining of a universal encoder-decoder for both VL understanding and generation remains challenging. The difficulty originates from the inherently different peculiarities of the two disciplines, e.g., VL understanding tasks capitalize on the unrestricted message passing across modalities, while generation tasks only employ visual-to-textual message passing. In this paper, we start with a two-stream decoupled design of encoder-decoder structure, in which two decoupled cross-modal encoder and decoder are involved to separately perform each type of proxy tasks, for simultaneous VL understanding and generation pretraining. Moreover, for VL pretraining, the dominant way is to replace some input visual/word tokens with mask tokens and enforce the multi-modal encoder/decoder to reconstruct the original tokens, but no mask token is involved when fine-tuning on downstream tasks. As an alternative, we propose a primary scheduled sampling strategy that elegantly mitigates such discrepancy via pretraining encoder-decoder in a two-pass manner. Extensive experiments demonstrate the compelling generalizability of our pretrained encoder-decoder by fine-tuning on four VL understanding and generation downstream tasks. Source code is available at \url{https://github.com/YehLi/TDEN}.
Joint Contrastive Learning with Infinite Possibilities
Oct 10, 2020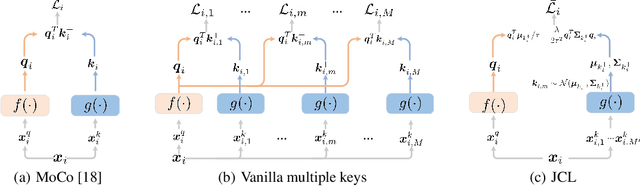
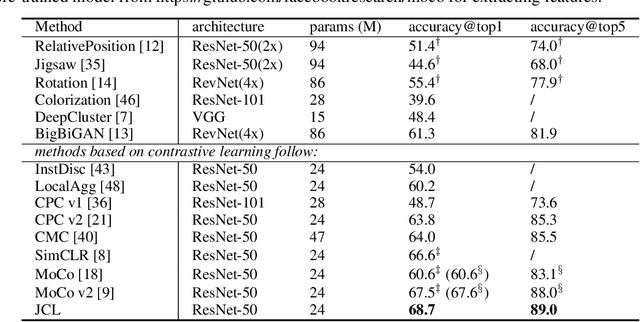
This paper explores useful modifications of the recent development in contrastive learning via novel probabilistic modeling. We derive a particular form of contrastive loss named Joint Contrastive Learning (JCL). JCL implicitly involves the simultaneous learning of an infinite number of query-key pairs, which poses tighter constraints when searching for invariant features. We derive an upper bound on this formulation that allows analytical solutions in an end-to-end training manner. While JCL is practically effective in numerous computer vision applications, we also theoretically unveil the certain mechanisms that govern the behavior of JCL. We demonstrate that the proposed formulation harbors an innate agency that strongly favors similarity within each instance-specific class, and therefore remains advantageous when searching for discriminative features among distinct instances. We evaluate these proposals on multiple benchmarks, demonstrating considerable improvements over existing algorithms. Code is publicly available at: https://github.com/caiqi/Joint-Contrastive-Learning.
SeCo: Exploring Sequence Supervision for Unsupervised Representation Learning
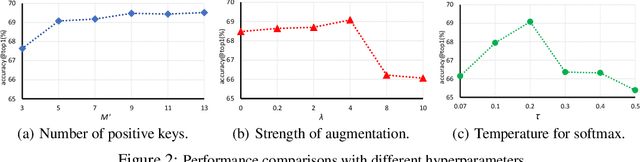
Aug 03, 2020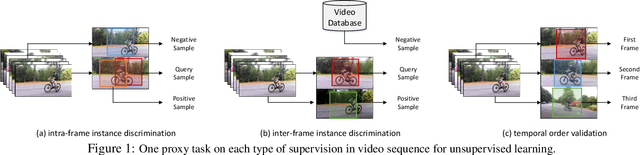
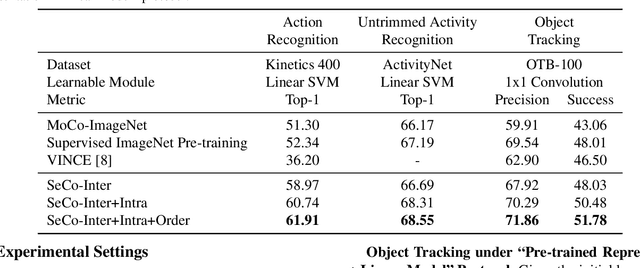
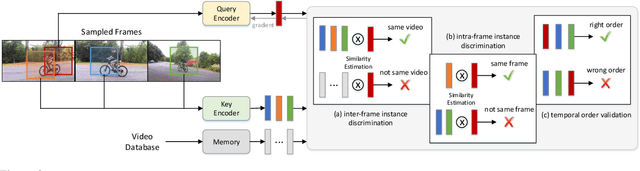
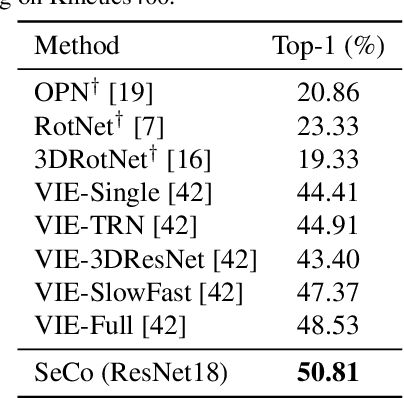
A steady momentum of innovations and breakthroughs has convincingly pushed the limits of unsupervised image representation learning. Compared to static 2D images, video has one more dimension (time). The inherent supervision existing in such sequential structure offers a fertile ground for building unsupervised learning models. In this paper, we compose a trilogy of exploring the basic and generic supervision in the sequence from spatial, spatiotemporal and sequential perspectives. We materialize the supervisory signals through determining whether a pair of samples is from one frame or from one video, and whether a triplet of samples is in the correct temporal order. We uniquely regard the signals as the foundation in contrastive learning and derive a particular form named Sequence Contrastive Learning (SeCo). SeCo shows superior results under the linear protocol on action recognition (Kinetics), untrimmed activity recognition (ActivityNet) and object tracking (OTB-100). More remarkably, SeCo demonstrates considerable improvements over recent unsupervised pre-training techniques, and leads the accuracy by 2.96% and 6.47% against fully-supervised ImageNet pre-training in action recognition task on UCF101 and HMDB51, respectively.