 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Self-supervised Monocular Depth Learning with Sparse LiDAR
Sep 21, 2021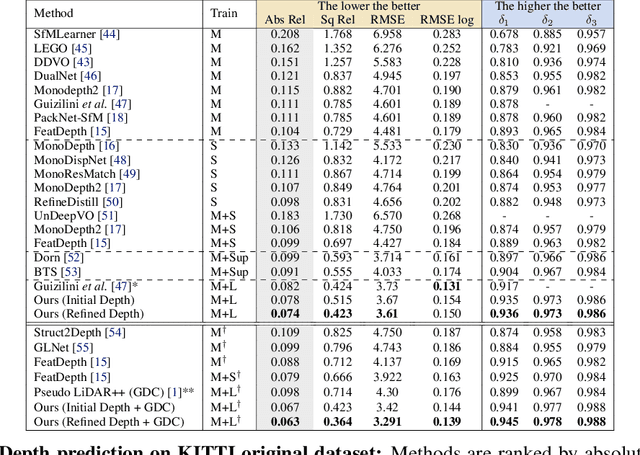
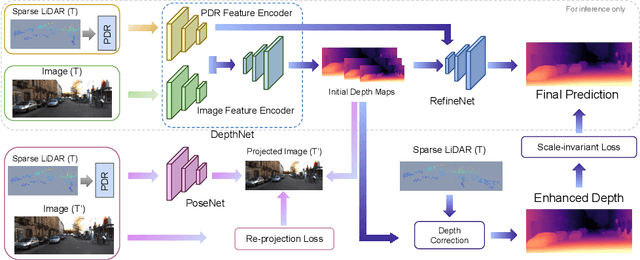
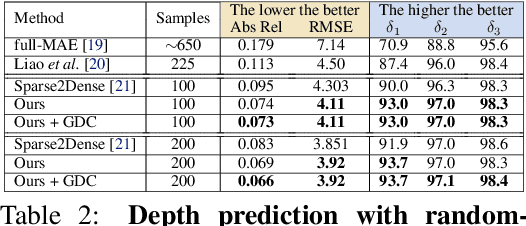
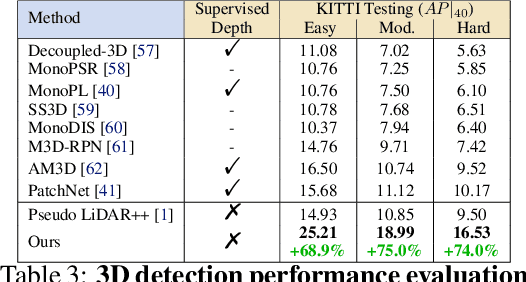
Self-supervised monocular depth prediction provides a cost-effective solution to obtain the 3D location of each pixel. However, the existing approaches usually lead to unsatisfactory accuracy, which is critical for autonomous robots. In this paper, we propose a novel two-stage network to advance the self-supervised monocular dense depth learning by leveraging low-cost sparse (e.g. 4-beam) LiDAR. Unlike the existing methods that use sparse LiDAR mainly in a manner of time-consuming iterative post-processing, our model fuses monocular image features and sparse LiDAR features to predict initial depth maps. Then, an efficient feed-forward refine network is further designed to correct the errors in these initial depth maps in pseudo-3D space with real-time performance. Extensive experiments show that our proposed model significantly outperforms all the state-of-the-art self-supervised methods, as well as the sparse-LiDAR-based methods on both self-supervised monocular depth prediction and completion tasks. With the accurate dense depth prediction, our model outperforms the state-of-the-art sparse-LiDAR-based method (Pseudo-LiDAR++) by more than 68% for the downstream task monocular 3D object detection on the KITTI Leaderboard.
FESTA: Flow Estimation via Spatial-Temporal Attention for Scene Point Clouds
Apr 01, 2021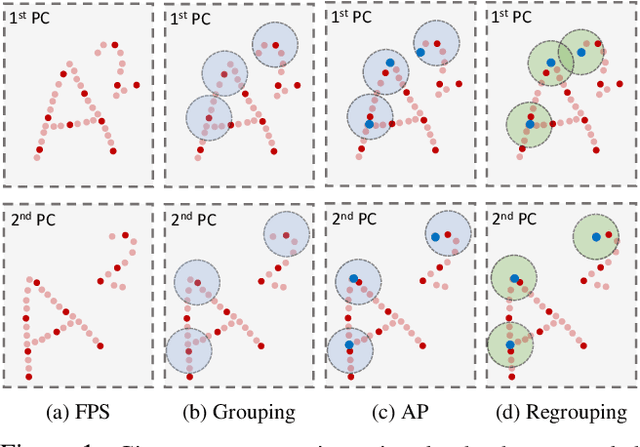
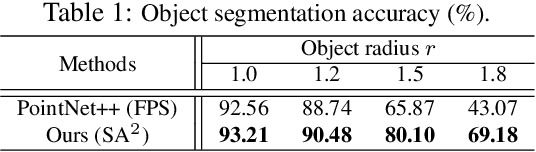
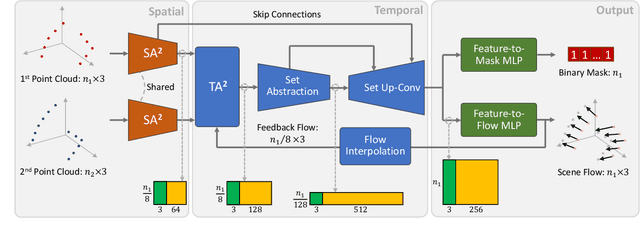
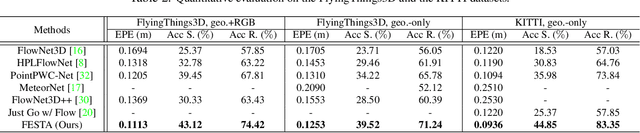
Scene flow depicts the dynamics of a 3D scene, which is critical for various applications such as autonomous driving, robot navigation, AR/VR, etc. Conventionally, scene flow is estimated from dense/regular RGB video frames. With the development of depth-sensing technologies, precise 3D measurements are available via point clouds which have sparked new research in 3D scene flow. Nevertheless, it remains challenging to extract scene flow from point clouds due to the sparsity and irregularity in typical point cloud sampling patterns. One major issue related to irregular sampling is identified as the randomness during point set abstraction/feature extraction -- an elementary process in many flow estimation scenarios. A novel Spatial Abstraction with Attention (SA^2) layer is accordingly proposed to alleviate the unstable abstraction problem. Moreover, a Temporal Abstraction with Attention (TA^2) layer is proposed to rectify attention in temporal domain, leading to benefits with motions scaled in a larger range. Extensive analysis and experiments verified the motivation and significant performance gains of our method, dubbed as Flow Estimation via Spatial-Temporal Attention (FESTA), when compared to several state-of-the-art benchmarks of scene flow estimation.
Cross-modal Center Loss
Aug 08, 2020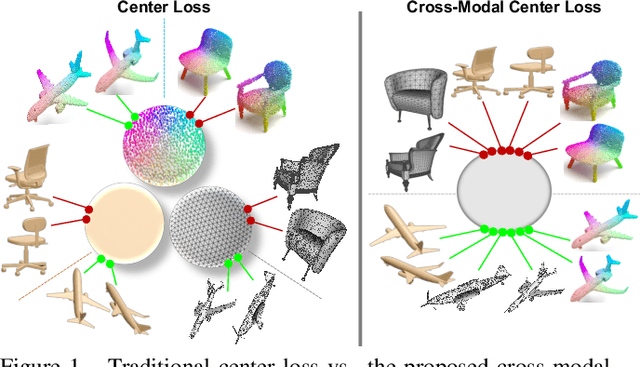
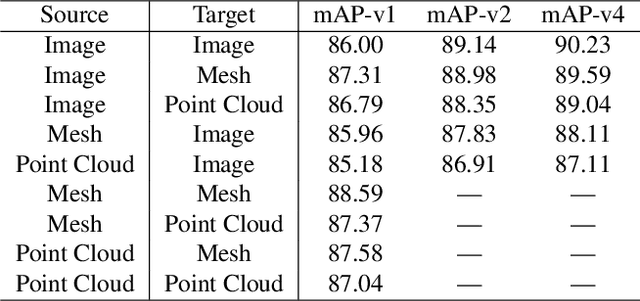
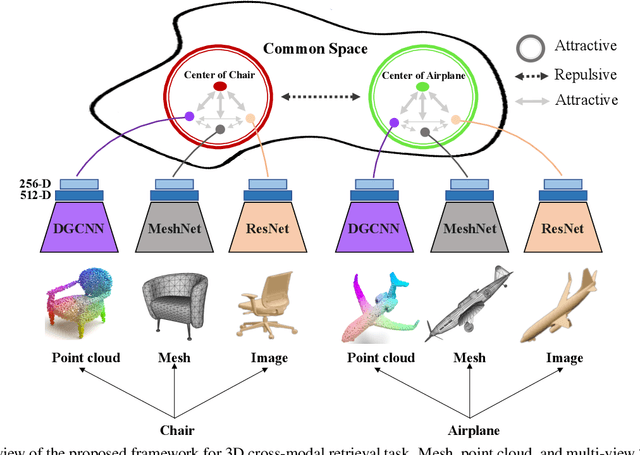
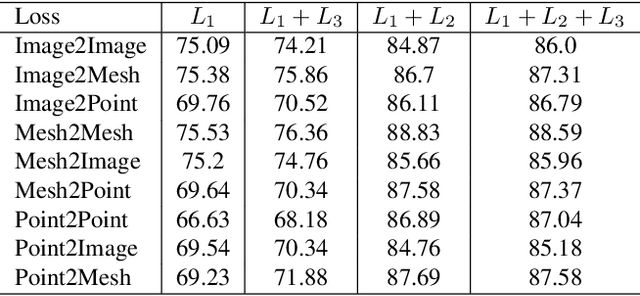
Cross-modal retrieval aims to learn discriminative and modal-invariant features for data from different modalities. Unlike the existing methods which usually learn from the features extracted by offline networks, in this paper, we propose an approach to jointly train the components of cross-modal retrieval framework with metadata, and enable the network to find optimal features. The proposed end-to-end framework is updated with three loss functions: 1) a novel cross-modal center loss to eliminate cross-modal discrepancy, 2) cross-entropy loss to maximize inter-class variations, and 3) mean-square-error loss to reduce modality variations. In particular, our proposed cross-modal center loss minimizes the distances of features from objects belonging to the same class across all modalities. Extensive experiments have been conducted on the retrieval tasks across multi-modalities, including 2D image, 3D point cloud, and mesh data. The proposed framework significantly outperforms the state-of-the-art methods on the ModelNet40 dataset.
Monocular Human Pose Estimation: A Survey of Deep Learning-based Methods
Jun 02, 2020
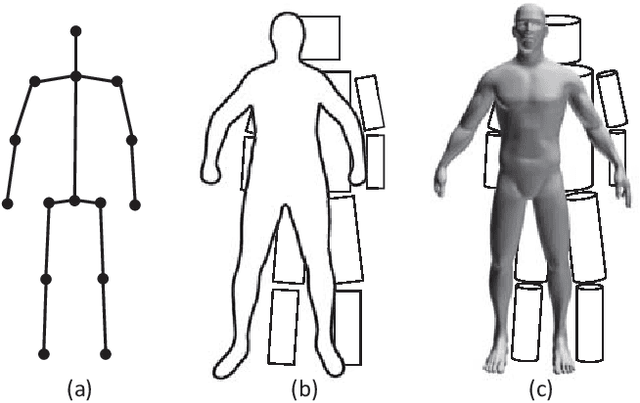
Vision-based monocular human pose estimation, as one of the most fundamental and challenging problems in computer vision, aims to obtain posture of the human body from input images or video sequences. The recent developments of deep learning techniques have been brought significant progress and remarkable breakthroughs in the field of human pose estimation. This survey extensively reviews the recent deep learning-based 2D and 3D human pose estimation methods published since 2014. This paper summarizes the challenges, main frameworks, benchmark datasets, evaluation metrics, performance comparison, and discusses some promising future research directions.
* This version corresponds to the pre-print of the paper accepted for Computer Vision and Image Understanding (CVIU)
Self-supervised Modal and View Invariant Feature Learning
May 28, 2020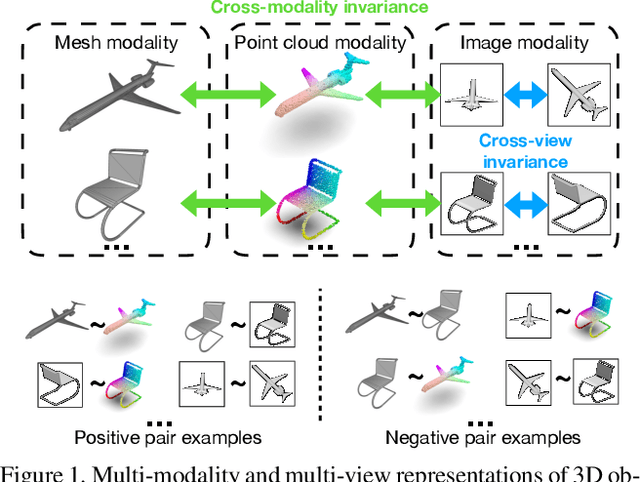
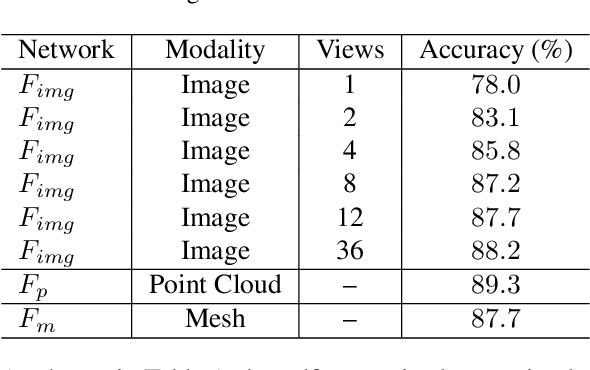
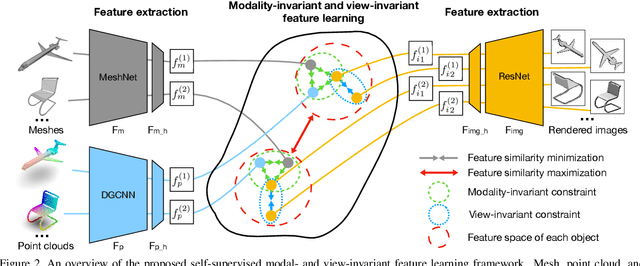
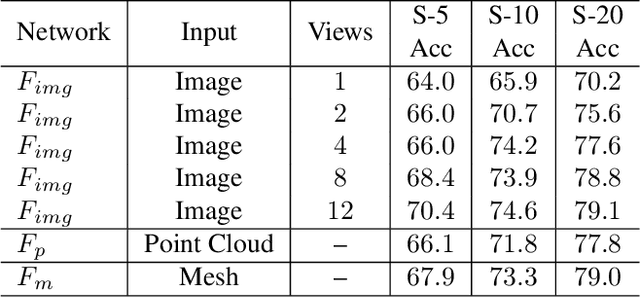
Most of the existing self-supervised feature learning methods for 3D data either learn 3D features from point cloud data or from multi-view images. By exploring the inherent multi-modality attributes of 3D objects, in this paper, we propose to jointly learn modal-invariant and view-invariant features from different modalities including image, point cloud, and mesh with heterogeneous networks for 3D data. In order to learn modal- and view-invariant features, we propose two types of constraints: cross-modal invariance constraint and cross-view invariant constraint. Cross-modal invariance constraint forces the network to maximum the agreement of features from different modalities for same objects, while the cross-view invariance constraint forces the network to maximum agreement of features from different views of images for same objects. The quality of learned features has been tested on different downstream tasks with three modalities of data including point cloud, multi-view images, and mesh. Furthermore, the invariance cross different modalities and views are evaluated with the cross-modal retrieval task. Extensive evaluation results demonstrate that the learned features are robust and have strong generalizability across different tasks.
Weakly Supervised Semantic Segmentation in 3D Graph-Structured Point Clouds of Wild Scenes
May 17, 2020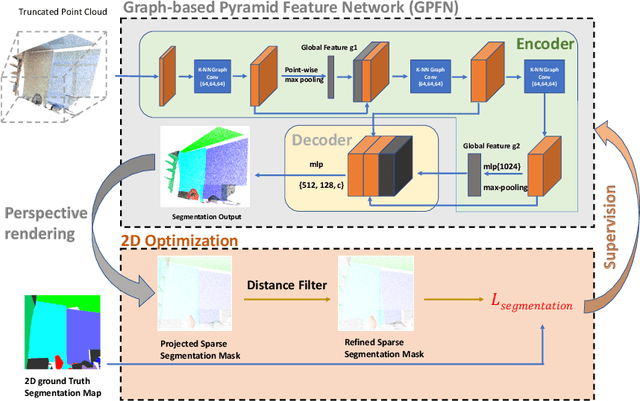
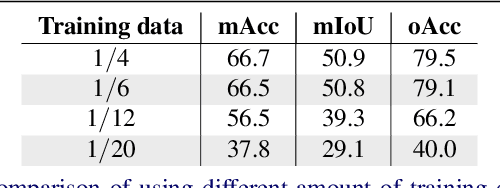
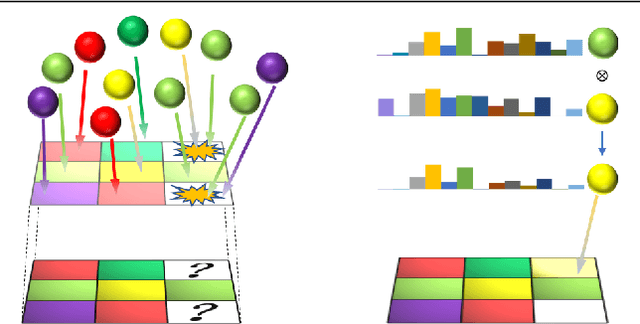
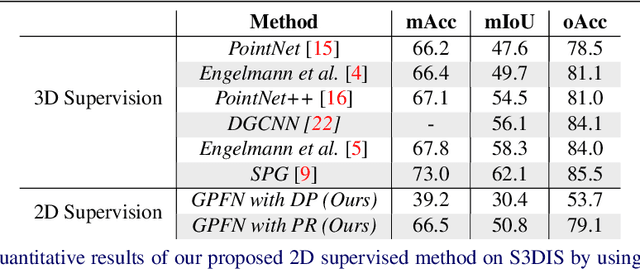
The deficiency of 3D segmentation labels is one of the main obstacles to effective point cloud segmentation, especially for scenes in the wild with varieties of different objects. To alleviate this issue, we propose a novel deep graph convolutional network-based framework for large-scale semantic scene segmentation in point clouds with sole 2D supervision. Different with numerous preceding multi-view supervised approaches focusing on single object point clouds, we argue that 2D supervision is capable of providing sufficient guidance information for training 3D semantic segmentation models of natural scene point clouds while not explicitly capturing their inherent structures, even with only single view per training sample. Specifically, a Graph-based Pyramid Feature Network (GPFN) is designed to implicitly infer both global and local features of point sets and an Observability Network (OBSNet) is introduced to further solve object occlusion problem caused by complicated spatial relations of objects in 3D scenes. During the projection process, perspective rendering and semantic fusion modules are proposed to provide refined 2D supervision signals for training along with a 2D-3D joint optimization strategy. Extensive experimental results demonstrate the effectiveness of our 2D supervised framework, which achieves comparable results with the state-of-the-art approaches trained with full 3D labels, for semantic point cloud segmentation on the popular SUNCG synthetic dataset and S3DIS real-world dataset.
Recognizing American Sign Language Nonmanual Signal Grammar Errors in Continuous Videos
May 01, 2020
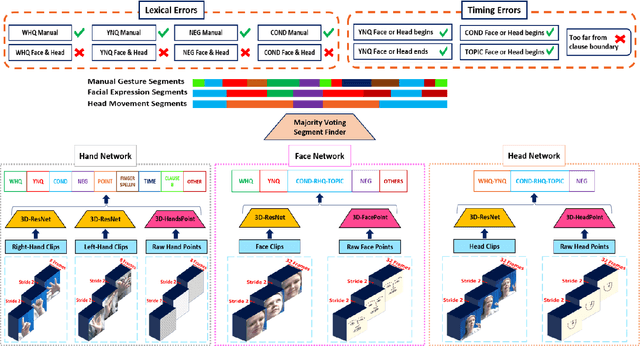
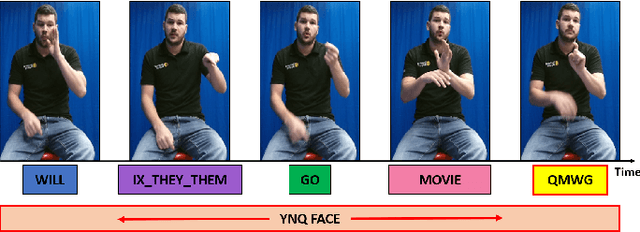
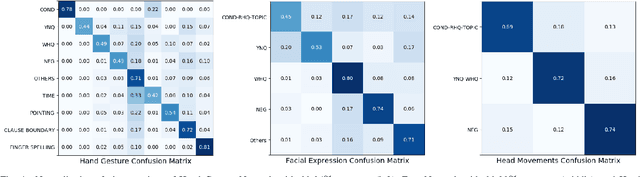
As part of the development of an educational tool that can help students achieve fluency in American Sign Language (ASL) through independent and interactive practice with immediate feedback, this paper introduces a near real-time system to recognize grammatical errors in continuous signing videos without necessarily identifying the entire sequence of signs. Our system automatically recognizes if performance of ASL sentences contains grammatical errors made by ASL students. We first recognize the ASL grammatical elements including both manual gestures and nonmanual signals independently from multiple modalities (i.e. hand gestures, facial expressions, and head movements) by 3D-ResNet networks. Then the temporal boundaries of grammatical elements from different modalities are examined to detect ASL grammatical mistakes by using a sliding window-based approach. We have collected a dataset of continuous sign language, ASL-HW-RGBD, covering different aspects of ASL grammars for training and testing. Our system is able to recognize grammatical elements on ASL-HW-RGBD from manual gestures, facial expressions, and head movements and successfully detect 8 ASL grammatical mistakes.
Self-supervised Feature Learning by Cross-modality and Cross-view Correspondences
Apr 13, 2020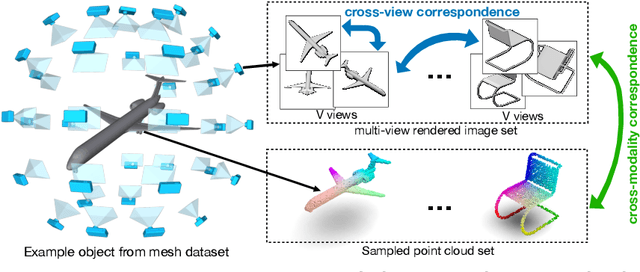

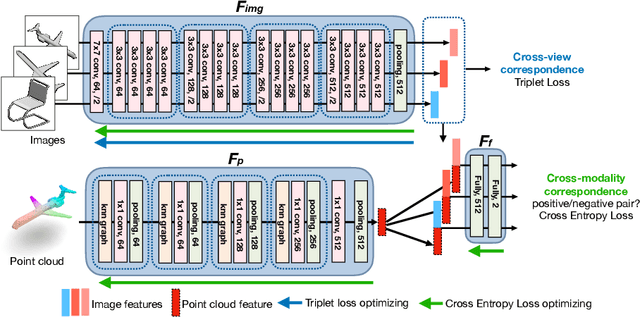

The success of supervised learning requires large-scale ground truth labels which are very expensive, time-consuming, or may need special skills to annotate. To address this issue, many self- or un-supervised methods are developed. Unlike most existing self-supervised methods to learn only 2D image features or only 3D point cloud features, this paper presents a novel and effective self-supervised learning approach to jointly learn both 2D image features and 3D point cloud features by exploiting cross-modality and cross-view correspondences without using any human annotated labels. Specifically, 2D image features of rendered images from different views are extracted by a 2D convolutional neural network, and 3D point cloud features are extracted by a graph convolution neural network. Two types of features are fed into a two-layer fully connected neural network to estimate the cross-modality correspondence. The three networks are jointly trained (i.e. cross-modality) by verifying whether two sampled data of different modalities belong to the same object, meanwhile, the 2D convolutional neural network is additionally optimized through minimizing intra-object distance while maximizing inter-object distance of rendered images in different views (i.e. cross-view). The effectiveness of the learned 2D and 3D features is evaluated by transferring them on five different tasks including multi-view 2D shape recognition, 3D shape recognition, multi-view 2D shape retrieval, 3D shape retrieval, and 3D part-segmentation. Extensive evaluations on all the five different tasks across different datasets demonstrate strong generalization and effectiveness of the learned 2D and 3D features by the proposed self-supervised method.
VideoSSL: Semi-Supervised Learning for Video Classification
Feb 29, 2020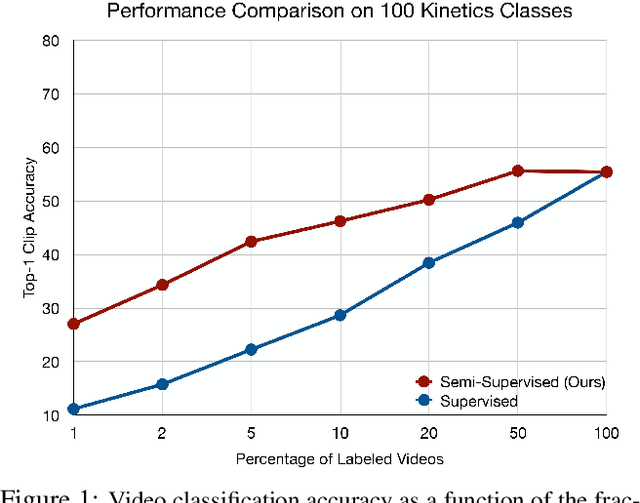



We propose a semi-supervised learning approach for video classification, VideoSSL, using convolutional neural networks (CNN). Like other computer vision tasks, existing supervised video classification methods demand a large amount of labeled data to attain good performance. However, annotation of a large dataset is expensive and time consuming. To minimize the dependence on a large annotated dataset, our proposed semi-supervised method trains from a small number of labeled examples and exploits two regulatory signals from unlabeled data. The first signal is the pseudo-labels of unlabeled examples computed from the confidences of the CNN being trained. The other is the normalized probabilities, as predicted by an image classifier CNN, that captures the information about appearances of the interesting objects in the video. We show that, under the supervision of these guiding signals from unlabeled examples, a video classification CNN can achieve impressive performances utilizing a small fraction of annotated examples on three publicly available datasets: UCF101, HMDB51 and Kinetics.
Accurate and Robust Pulmonary Nodule Detection by 3D Feature Pyramid Network with Self-supervised Feature Learning
Jul 25, 2019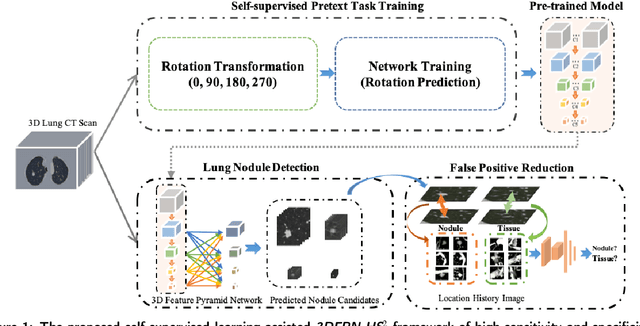

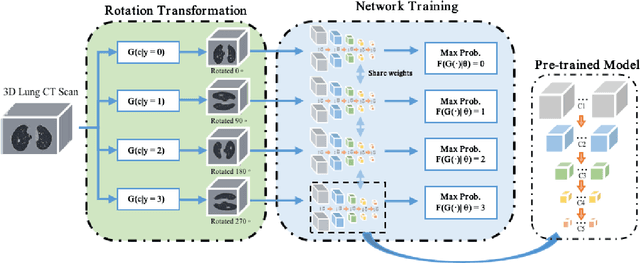

Accurate detection of pulmonary nodules with high sensitivity and specificity is essential for automatic lung cancer diagnosis from CT scans. Although many deep learning-based algorithms make great progress for improving the accuracy of nodule detection, the high false positive rate is still a challenging problem which limits the automatic diagnosis in routine clinical practice. Moreover, the CT scans collected from multiple manufacturers may affect the robustness of Computer-aided diagnosis (CAD) due to the differences in intensity scales and machine noises. In this paper, we propose a novel self-supervised learning assisted pulmonary nodule detection framework based on a 3D Feature Pyramid Network (3DFPN) to improve the sensitivity of nodule detection by employing multi-scale features to increase the resolution of nodules, as well as a parallel top-down path to transit the high-level semantic features to complement low-level general features. Furthermore, a High Sensitivity and Specificity (HS2) network is introduced to eliminate the false positive nodule candidates by tracking the appearance changes in continuous CT slices of each nodule candidate on Location History Images (LHI). In addition, in order to improve the performance consistency of the proposed framework across data captured by different CT scanners without using additional annotations, an effective self-supervised learning schema is applied to learn spatiotemporal features of CT scans from large-scale unlabeled data. The performance and robustness of our method are evaluated on several publicly available datasets with significant performance improvements. The proposed framework is able to accurately detect pulmonary nodules with high sensitivity and specificity and achieves 90.6% sensitivity with 1/8 false positive per scan which outperforms the state-of-the-art results 15.8% on LUNA16 dataset.