 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy Multi-phase Liver Tumor Segmentation via Evidence-based Uncertainty
May 09, 2023



Multi-phase liver contrast-enhanced computed tomography (CECT) images convey the complementary multi-phase information for liver tumor segmentation (LiTS), which are crucial to assist the diagnosis of liver cancer clinically. However, the performances of existing multi-phase liver tumor segmentation (MPLiTS)-based methods suffer from redundancy and weak interpretability, % of the fused result, resulting in the implicit unreliability of clinical applications. In this paper, we propose a novel trustworthy multi-phase liver tumor segmentation (TMPLiTS), which is a unified framework jointly conducting segmentation and uncertainty estimation. The trustworthy results could assist the clinicians to make a reliable diagnosis. Specifically, Dempster-Shafer Evidence Theory (DST) is introduced to parameterize the segmentation and uncertainty as evidence following Dirichlet distribution. The reliability of segmentation results among multi-phase CECT images is quantified explicitly. Meanwhile, a multi-expert mixture scheme (MEMS) is proposed to fuse the multi-phase evidences, which can guarantee the effect of fusion procedure based on theoretical analysis. Experimental results demonstrate the superiority of TMPLiTS compared with the state-of-the-art methods. Meanwhile, the robustness of TMPLiTS is verified, where the reliable performance can be guaranteed against the perturbations.
Joint Device Activity Detection, Channel Estimation and Signal Detection for Massive Grant-free Access via BiGAMP
Apr 03, 2023



Massive access has been challenging for the fifth generation (5G) and beyond since the abundance of devices causes communication overload to skyrocket. In an uplink massive access scenario, device traffic is sporadic in any given coherence time. Thus, channels across the antennas of each device exhibit correlation, which can be characterized by the row sparse channel matrix structure. In this work, we develop a bilinear generalized approximate message passing (BiGAMP) algorithm based on the row sparse channel matrix structure. This algorithm can jointly detect device activities, estimate channels, and detect signals in massive multiple-input multiple-output (MIMO) systems by alternating updates between channel matrices and signal matrices. The signal observation provides additional information for performance improvement compared to the existing algorithms. We further analyze state evolution (SE) to measure the performance of the proposed algorithm and characterize the convergence condition for SE. Moreover, we perform theoretical analysis on the error probability of device activity detection, the mean square error of channel estimation, and the symbol error rate of signal detection. The numerical results demonstrate the superiority of the proposed algorithm over the state-of-the-art methods in DADCE-SD, and the numerical results are relatively close to the theoretical analysis results.
Optimization and Optimizers for Adversarial Robustness
Mar 23, 2023



Empirical robustness evaluation (RE) of deep learning models against adversarial perturbations entails solving nontrivial constrained optimization problems. Existing numerical algorithms that are commonly used to solve them in practice predominantly rely on projected gradient, and mostly handle perturbations modeled by the $\ell_1$, $\ell_2$ and $\ell_\infty$ distances. In this paper, we introduce a novel algorithmic framework that blends a general-purpose constrained-optimization solver PyGRANSO with Constraint Folding (PWCF), which can add more reliability and generality to the state-of-the-art RE packages, e.g., AutoAttack. Regarding reliability, PWCF provides solutions with stationarity measures and feasibility tests to assess the solution quality. For generality, PWCF can handle perturbation models that are typically inaccessible to the existing projected gradient methods; the main requirement is the distance metric to be almost everywhere differentiable. Taking advantage of PWCF and other existing numerical algorithms, we further explore the distinct patterns in the solutions found for solving these optimization problems using various combinations of losses, perturbation models, and optimization algorithms. We then discuss the implications of these patterns on the current robustness evaluation and adversarial training.
Optimization for Robustness Evaluation beyond $\ell_p$ Metrics
Oct 02, 2022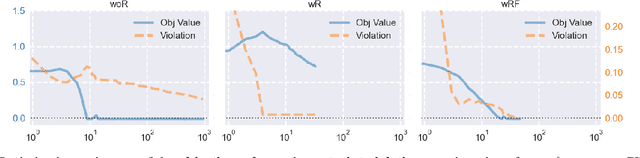
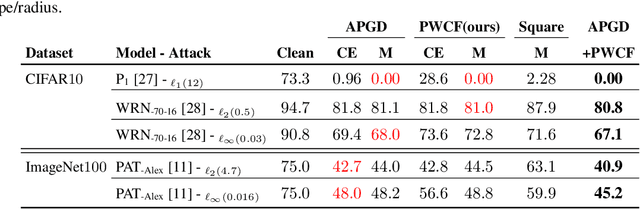
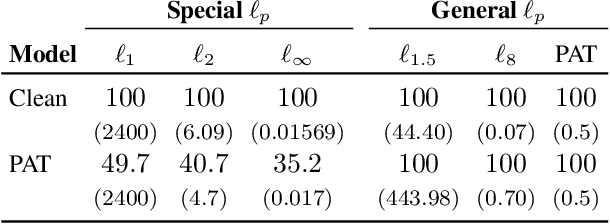
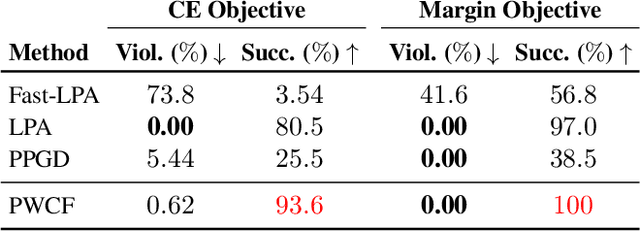
Empirical evaluation of deep learning models against adversarial attacks entails solving nontrivial constrained optimization problems. Popular algorithms for solving these constrained problems rely on projected gradient descent (PGD) and require careful tuning of multiple hyperparameters. Moreover, PGD can only handle $\ell_1$, $\ell_2$, and $\ell_\infty$ attack models due to the use of analytical projectors. In this paper, we introduce a novel algorithmic framework that blends a general-purpose constrained-optimization solver PyGRANSO, With Constraint-Folding (PWCF), to add reliability and generality to robustness evaluation. PWCF 1) finds good-quality solutions without the need of delicate hyperparameter tuning, and 2) can handle general attack models, e.g., general $\ell_p$ ($p \geq 0$) and perceptual attacks, which are inaccessible to PGD-based algorithms.
Optimization-based Block Coordinate Gradient Coding for Mitigating Partial Stragglers in Distributed Learning
Jun 06, 2022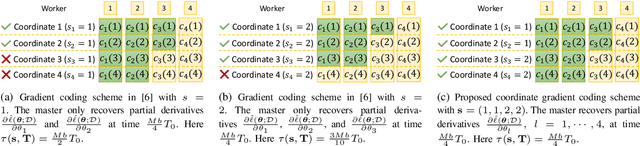
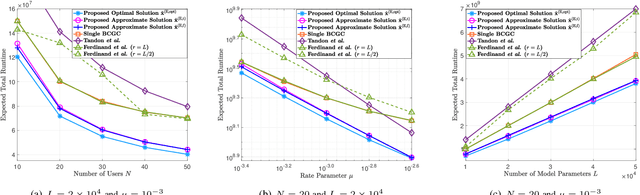
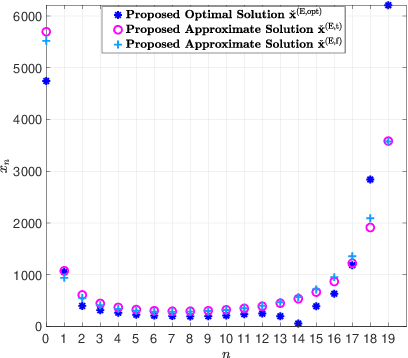
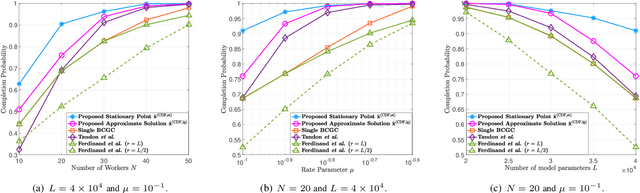
Gradient coding schemes effectively mitigate full stragglers in distributed learning by introducing identical redundancy in coded local partial derivatives corresponding to all model parameters. However, they are no longer effective for partial stragglers as they cannot utilize incomplete computation results from partial stragglers. This paper aims to design a new gradient coding scheme for mitigating partial stragglers in distributed learning. Specifically, we consider a distributed system consisting of one master and N workers, characterized by a general partial straggler model and focuses on solving a general large-scale machine learning problem with L model parameters using gradient coding. First, we propose a coordinate gradient coding scheme with L coding parameters representing L possibly different diversities for the L coordinates, which generates most gradient coding schemes. Then, we consider the minimization of the expected overall runtime and the maximization of the completion probability with respect to the L coding parameters for coordinates, which are challenging discrete optimization problems. To reduce computational complexity, we first transform each to an equivalent but much simpler discrete problem with N\llL variables representing the partition of the L coordinates into N blocks, each with identical redundancy. This indicates an equivalent but more easily implemented block coordinate gradient coding scheme with N coding parameters for blocks. Then, we adopt continuous relaxation to further reduce computational complexity. For the resulting minimization of expected overall runtime, we develop an iterative algorithm of computational complexity O(N^2) to obtain an optimal solution and derive two closed-form approximate solutions both with computational complexity O(N). For the resultant maximization of the completion probability, we develop an iterative algorithm of...
Analysis and Optimization of A Double-IRS Cooperatively Assisted System with A Quasi-Static Phase Shift Design
Mar 31, 2022
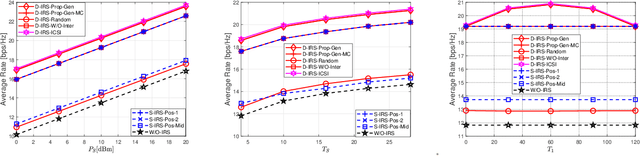
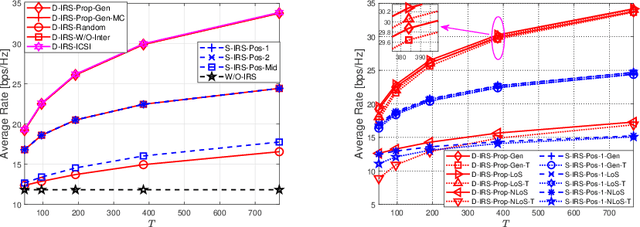
The analysis and optimization of single intelligent reflecting surface (IRS)-assisted systems have been extensively studied, whereas little is known regarding multiple-IRS-assisted systems. This paper investigates the analysis and optimization of a double-IRS cooperatively assisted downlink system, where a multi-antenna base station (BS) serves a single-antenna user with the help of two multi-element IRSs, connected by an inter-IRS channel. The channel between any two nodes is modeled with Rician fading. The BS adopts the instantaneous CSI-adaptive maximum-ratio transmission (MRT) beamformer, and the two IRSs adopt a cooperative quasi-static phase shift design. The goal is to maximize the average achievable rate, which can be reflected by the average channel power of the equivalent channel between the BS and user, at a low phase adjustment cost and computational complexity. First, we obtain tractable expressions of the average channel power of the equivalent channel in the general Rician factor, pure line of sight (LoS), and pure non-line of sight (NLoS) regimes, respectively. Then, we jointly optimize the phase shifts of the two IRSs to maximize the average channel power of the equivalent channel in these regimes. The optimization problems are challenging non-convex problems. We obtain globally optimal closed-form solutions for some cases and propose computationally efficient iterative algorithms to obtain stationary points for the other cases. Next, we compare the computational complexity for optimizing the phase shifts and the optimal average channel power of the double-IRS cooperatively assisted system with those of a counterpart single-IRS-assisted system at a large number of reflecting elements in the three regimes. Finally, we numerically demonstrate notable gains of the proposed solutions over the existing solutions at different system parameters.
PointAttN: You Only Need Attention for Point Cloud Completion
Mar 16, 2022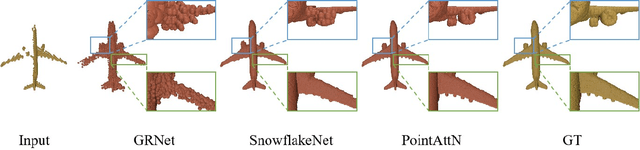
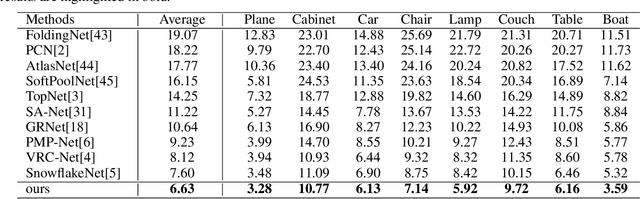
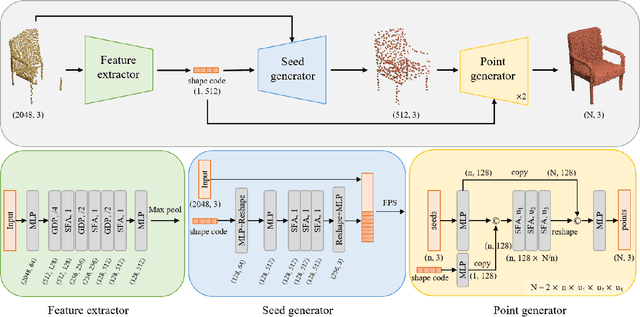
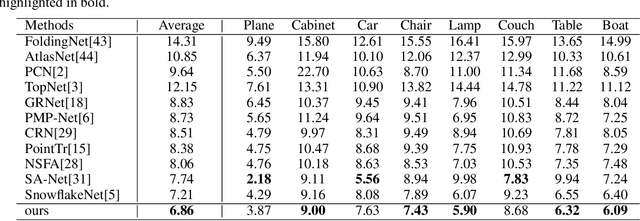
Point cloud completion referring to completing 3D shapes from partial 3D point clouds is a fundamental problem for 3D point cloud analysis tasks. Benefiting from the development of deep neural networks, researches on point cloud completion have made great progress in recent years. However, the explicit local region partition like kNNs involved in existing methods makes them sensitive to the density distribution of point clouds. Moreover, it serves limited receptive fields that prevent capturing features from long-range context information. To solve the problems, we leverage the cross-attention and self-attention mechanisms to design novel neural network for processing point cloud in a per-point manner to eliminate kNNs. Two essential blocks Geometric Details Perception (GDP) and Self-Feature Augment (SFA) are proposed to establish the short-range and long-range structural relationships directly among points in a simple yet effective way via attention mechanism. Then based on GDP and SFA, we construct a new framework with popular encoder-decoder architecture for point cloud completion. The proposed framework, namely PointAttN, is simple, neat and effective, which can precisely capture the structural information of 3D shapes and predict complete point clouds with highly detailed geometries. Experimental results demonstrate that our PointAttN outperforms state-of-the-art methods by a large margin on popular benchmarks like Completion3D and PCN. Code is available at: https://github.com/ohhhyeahhh/PointAttN
Statistical Device Activity Detection for OFDM-based Massive Grant-Free Access
Dec 31, 2021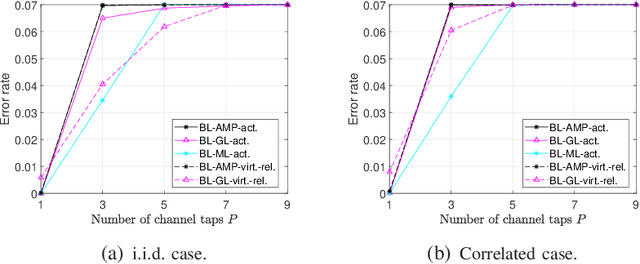
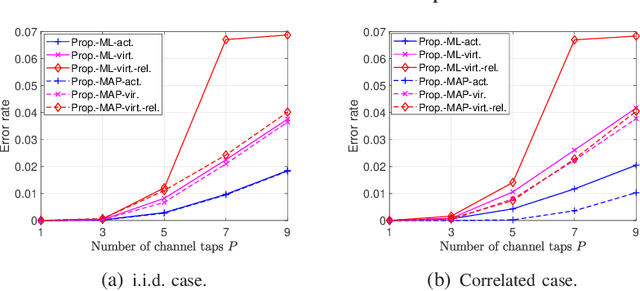
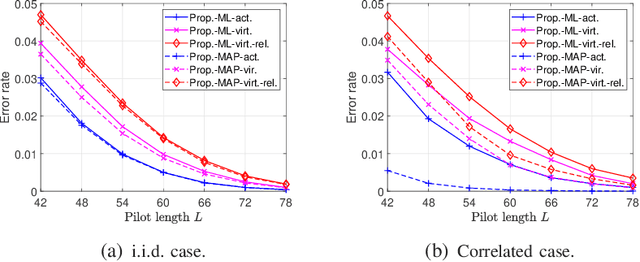
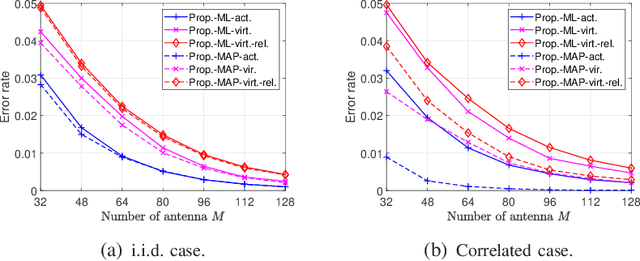
Existing works on grant-free access, proposed to support massive machine-type communication (mMTC) for the Internet of things (IoT), mainly concentrate on narrow band systems under flat fading. However, little is known about massive grant-free access for wideband systems under frequency-selective fading. This paper investigates massive grant-free access in a wideband system under frequency-selective fading. First, we present an orthogonal frequency division multiplexing (OFDM)-based massive grant-free access scheme. Then, we propose two different but equivalent models for the received pilot signal, which are essential for designing various device activity detection and channel estimation methods for OFDM-based massive grant-free access. One directly models the received signal for actual devices, whereas the other can be interpreted as a signal model for virtual devices. Next, we investigate statistical device activity detection under frequency-selective Rayleigh fading based on the two signal models. We first model device activities as unknown deterministic quantities and propose three maximum likelihood (ML) estimation-based device activity detection methods with different detection accuracies and computation times. We also model device activities as random variables with a known joint distribution and propose three maximum a posterior probability (MAP) estimation-based device activity methods, which further enhance the accuracies of the corresponding ML estimation-based methods. Optimization techniques and matrix analysis are applied in designing and analyzing these methods. Finally, numerical results show that the proposed statistical device activity detection methods outperform existing state-of-the-art device activity detection methods under frequency-selective Rayleigh fading.
An Optimization Framework for Federated Edge Learning
Nov 26, 2021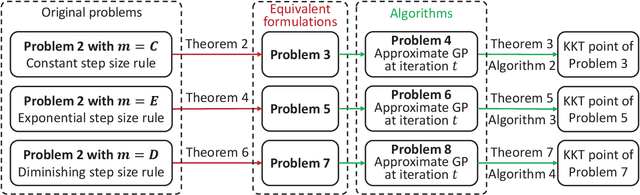

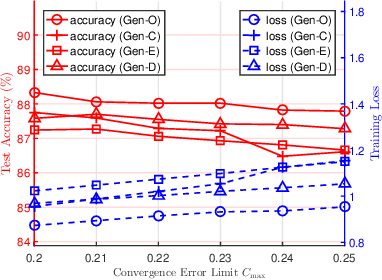
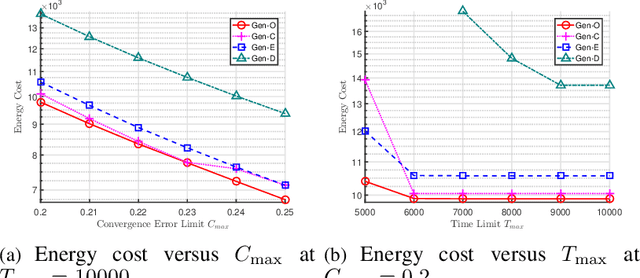
The optimal design of federated learning (FL) algorithms for solving general machine learning (ML) problems in practical edge computing systems with quantized message passing remains an open problem. This paper considers an edge computing system where the server and workers have possibly different computing and communication capabilities and employ quantization before transmitting messages. To explore the full potential of FL in such an edge computing system, we first present a general FL algorithm, namely GenQSGD, parameterized by the numbers of global and local iterations, mini-batch size, and step size sequence. Then, we analyze its convergence for an arbitrary step size sequence and specify the convergence results under three commonly adopted step size rules, namely the constant, exponential, and diminishing step size rules. Next, we optimize the algorithm parameters to minimize the energy cost under the time constraint and convergence error constraint, with the focus on the overall implementing process of FL. Specifically, for any given step size sequence under each considered step size rule, we optimize the numbers of global and local iterations and mini-batch size to optimally implement FL for applications with preset step size sequences. We also optimize the step size sequence along with these algorithm parameters to explore the full potential of FL. The resulting optimization problems are challenging non-convex problems with non-differentiable constraint functions. We propose iterative algorithms to obtain KKT points using general inner approximation (GIA) and tricks for solving complementary geometric programming (CGP). Finally, we numerically demonstrate the remarkable gains of GenQSGD with optimized algorithm parameters over existing FL algorithms and reveal the significance of optimally designing general FL algorithms.
Optimization-Based GenQSGD for Federated Edge Learning
Nov 26, 2021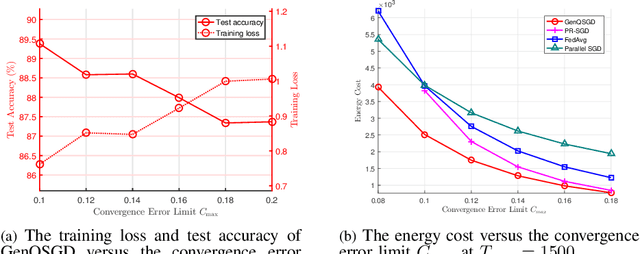
Optimal algorithm design for federated learning (FL) remains an open problem. This paper explores the full potential of FL in practical edge computing systems where workers may have different computation and communication capabilities, and quantized intermediate model updates are sent between the server and workers. First, we present a general quantized parallel mini-batch stochastic gradient descent (SGD) algorithm for FL, namely GenQSGD, which is parameterized by the number of global iterations, the numbers of local iterations at all workers, and the mini-batch size. We also analyze its convergence error for any choice of the algorithm parameters. Then, we optimize the algorithm parameters to minimize the energy cost under the time constraint and convergence error constraint. The optimization problem is a challenging non-convex problem with non-differentiable constraint functions. We propose an iterative algorithm to obtain a KKT point using advanced optimization techniques. Numerical results demonstrate the significant gains of GenQSGD over existing FL algorithms and reveal the importance of optimally designing FL algorithms.