 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Unaligned Multimodal Sequence via Graph Convolution and Graph Pooling Fusion
Dec 02, 2020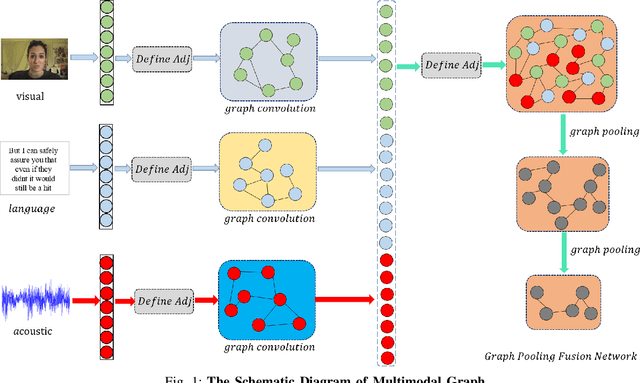

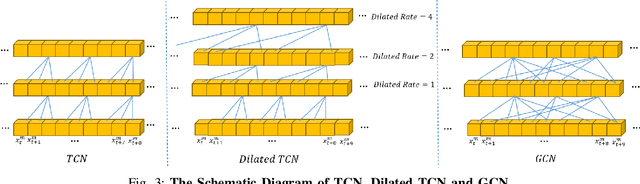
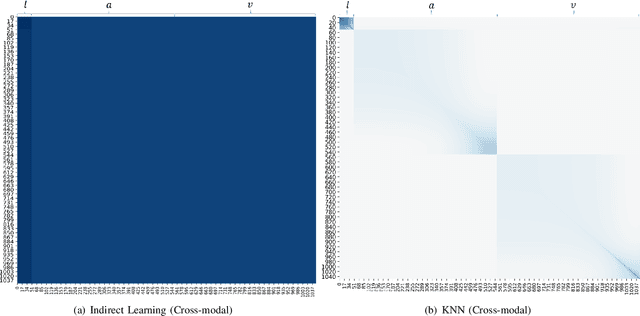
In this paper, we study the task of multimodal sequence analysis which aims to draw inferences from visual, language and acoustic sequences. A majority of existing works generally focus on aligned fusion, mostly at word level, of the three modalities to accomplish this task, which is impractical in real-world scenarios. To overcome this issue, we seek to address the task of multimodal sequence analysis on unaligned modality sequences which is still relatively underexplored and also more challenging. Recurrent neural network (RNN) and its variants are widely used in multimodal sequence analysis, but they are susceptible to the issues of gradient vanishing/explosion and high time complexity due to its recurrent nature. Therefore, we propose a novel model, termed Multimodal Graph, to investigate the effectiveness of graph neural networks (GNN) on modeling multimodal sequential data. The graph-based structure enables parallel computation in time dimension and can learn longer temporal dependency in long unaligned sequences. Specifically, our Multimodal Graph is hierarchically structured to cater to two stages, i.e., intra- and inter-modal dynamics learning. For the first stage, a graph convolutional network is employed for each modality to learn intra-modal dynamics. In the second stage, given that the multimodal sequences are unaligned, the commonly considered word-level fusion does not pertain. To this end, we devise a graph pooling fusion network to automatically learn the associations between various nodes from different modalities. Additionally, we define multiple ways to construct the adjacency matrix for sequential data. Experimental results suggest that our graph-based model reaches state-of-the-art performance on two benchmark datasets.
Xiaomingbot: A Multilingual Robot News Reporter
Jul 12, 2020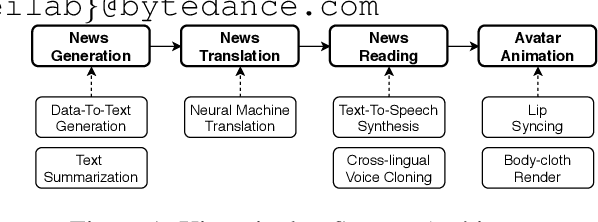
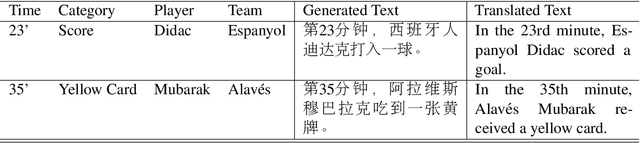
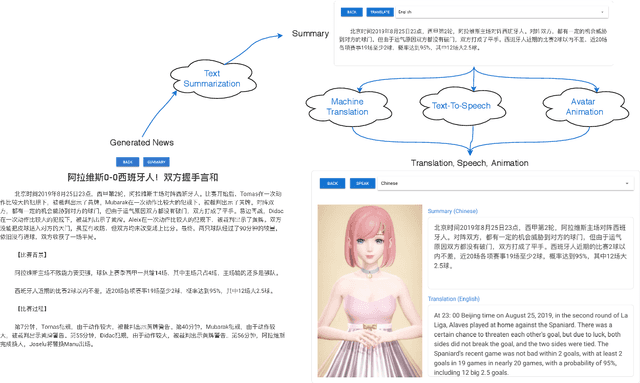
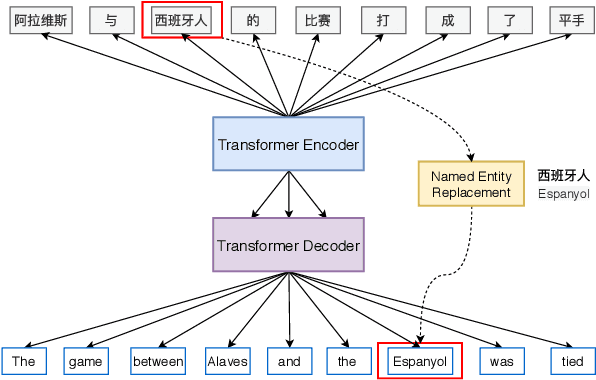
This paper proposes the building of Xiaomingbot, an intelligent, multilingual and multimodal software robot equipped with four integral capabilities: news generation, news translation, news reading and avatar animation. Its system summarizes Chinese news that it automatically generates from data tables. Next, it translates the summary or the full article into multiple languages, and reads the multilingual rendition through synthesized speech. Notably, Xiaomingbot utilizes a voice cloning technology to synthesize the speech trained from a real person's voice data in one input language. The proposed system enjoys several merits: it has an animated avatar, and is able to generate and read multilingual news. Since it was put into practice, Xiaomingbot has written over 600,000 articles, and gained over 150,000 followers on social media platforms.
Importance-Aware Learning for Neural Headline Editing
Nov 25, 2019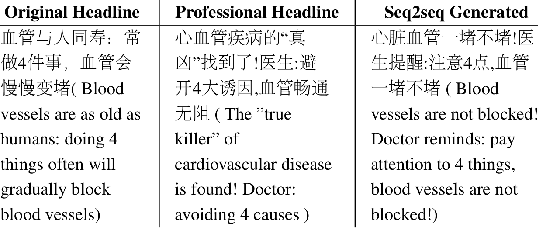
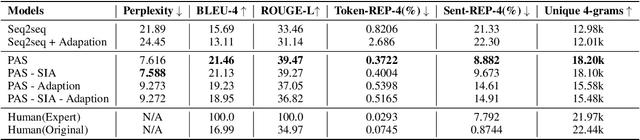
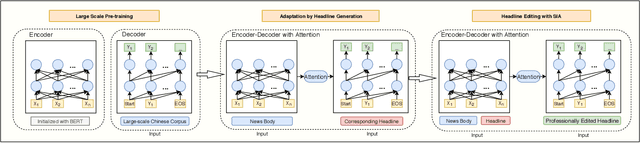

Many social media news writers are not professionally trained. Therefore, social media platforms have to hire professional editors to adjust amateur headlines to attract more readers. We propose to automate this headline editing process through neural network models to provide more immediate writing support for these social media news writers. To train such a neural headline editing model, we collected a dataset which contains articles with original headlines and professionally edited headlines. However, it is expensive to collect a large number of professionally edited headlines. To solve this low-resource problem, we design an encoder-decoder model which leverages large scale pre-trained language models. We further improve the pre-trained model's quality by introducing a headline generation task as an intermediate task before the headline editing task. Also, we propose Self Importance-Aware (SIA) loss to address the different levels of editing in the dataset by down-weighting the importance of easily classified tokens and sentences. With the help of Pre-training, Adaptation, and SIA, the model learns to generate headlines in the professional editor's style. Experimental results show that our method significantly improves the quality of headline editing comparing against previous methods.
Constraint-free Natural Image Reconstruction from fMRI Signals Based on Convolutional Neural Network
Jan 16, 2018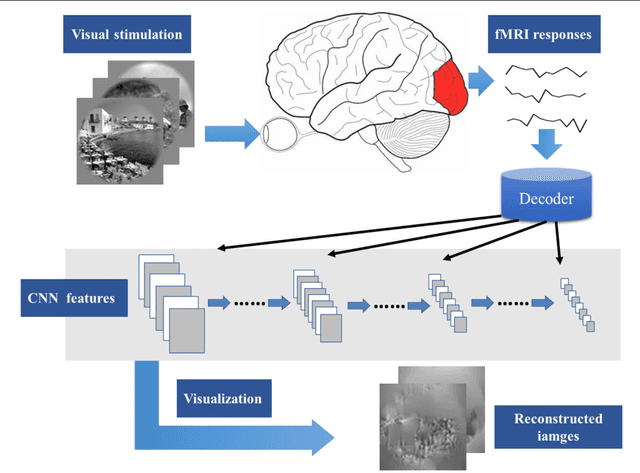

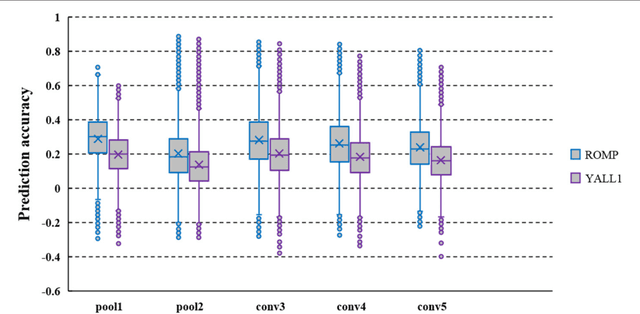
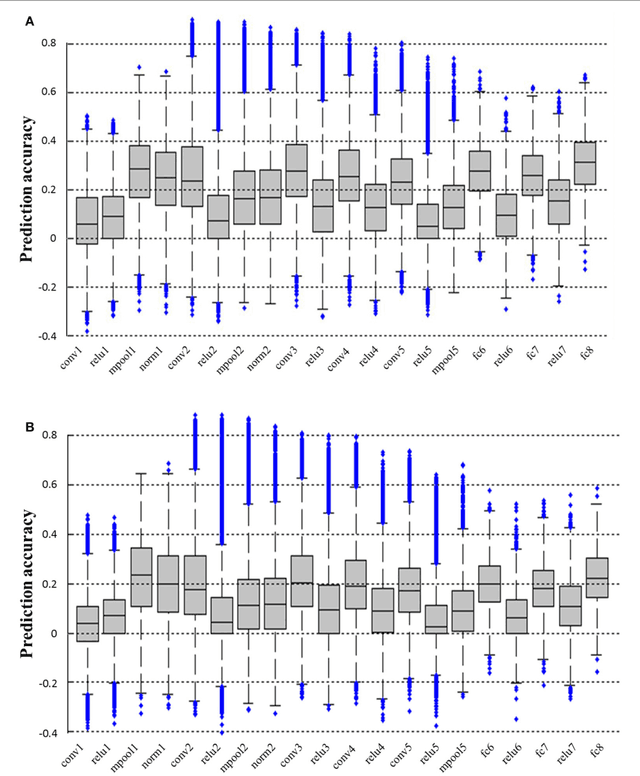
In recent years, research on decoding brain activity based on functional magnetic resonance imaging (fMRI) has made remarkable achievements. However, constraint-free natural image reconstruction from brain activity is still a challenge. The existing methods simplified the problem by using semantic prior information or just reconstructing simple images such as letters and digitals. Without semantic prior information, we present a novel method to reconstruct nature images from fMRI signals of human visual cortex based on the computation model of convolutional neural network (CNN). Firstly, we extracted the units output of viewed natural images in each layer of a pre-trained CNN as CNN features. Secondly, we transformed image reconstruction from fMRI signals into the problem of CNN feature visualizations by training a sparse linear regression to map from the fMRI patterns to CNN features. By iteratively optimization to find the matched image, whose CNN unit features become most similar to those predicted from the brain activity, we finally achieved the promising results for the challenging constraint-free natural image reconstruction. As there was no use of semantic prior information of the stimuli when training decoding model, any category of images (not constraint by the training set) could be reconstructed theoretically. We found that the reconstructed images resembled the natural stimuli, especially in position and shape. The experimental results suggest that hierarchical visual features can effectively express the visual perception process of human brain.
Scale Up Event Extraction Learning via Automatic Training Data Generation
Dec 11, 2017

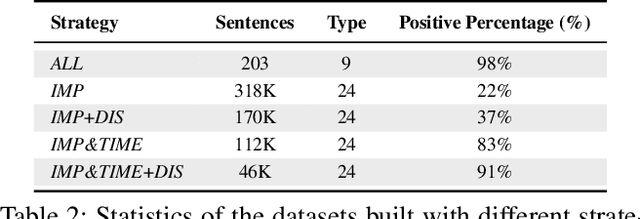
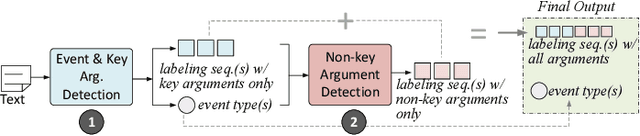
The task of event extraction has long been investigated in a supervised learning paradigm, which is bound by the number and the quality of the training instances. Existing training data must be manually generated through a combination of expert domain knowledge and extensive human involvement. However, due to drastic efforts required in annotating text, the resultant datasets are usually small, which severally affects the quality of the learned model, making it hard to generalize. Our work develops an automatic approach for generating training data for event extraction. Our approach allows us to scale up event extraction training instances from thousands to hundreds of thousands, and it does this at a much lower cost than a manual approach. We achieve this by employing distant supervision to automatically create event annotations from unlabelled text using existing structured knowledge bases or tables.We then develop a neural network model with post inference to transfer the knowledge extracted from structured knowledge bases to automatically annotate typed events with corresponding arguments in text.We evaluate our approach by using the knowledge extracted from Freebase to label texts from Wikipedia articles. Experimental results show that our approach can generate a large number of high quality training instances. We show that this large volume of training data not only leads to a better event extractor, but also allows us to detect multiple typed events.