 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-fidelity 3D Reconstruction of Plants using Neural Radiance Field
Nov 07, 2023



Accurate reconstruction of plant phenotypes plays a key role in optimising sustainable farming practices in the field of Precision Agriculture (PA). Currently, optical sensor-based approaches dominate the field, but the need for high-fidelity 3D reconstruction of crops and plants in unstructured agricultural environments remains challenging. Recently, a promising development has emerged in the form of Neural Radiance Field (NeRF), a novel method that utilises neural density fields. This technique has shown impressive performance in various novel vision synthesis tasks, but has remained relatively unexplored in the agricultural context. In our study, we focus on two fundamental tasks within plant phenotyping: (1) the synthesis of 2D novel-view images and (2) the 3D reconstruction of crop and plant models. We explore the world of neural radiance fields, in particular two SOTA methods: Instant-NGP, which excels in generating high-quality images with impressive training and inference speed, and Instant-NSR, which improves the reconstructed geometry by incorporating the Signed Distance Function (SDF) during training. In particular, we present a novel plant phenotype dataset comprising real plant images from production environments. This dataset is a first-of-its-kind initiative aimed at comprehensively exploring the advantages and limitations of NeRF in agricultural contexts. Our experimental results show that NeRF demonstrates commendable performance in the synthesis of novel-view images and is able to achieve reconstruction results that are competitive with Reality Capture, a leading commercial software for 3D Multi-View Stereo (MVS)-based reconstruction. However, our study also highlights certain drawbacks of NeRF, including relatively slow training speeds, performance limitations in cases of insufficient sampling, and challenges in obtaining geometry quality in complex setups.
Towards Anytime Fine-tuning: Continually Pre-trained Language Models with Hypernetwork Prompt
Oct 19, 2023



Continual pre-training has been urgent for adapting a pre-trained model to a multitude of domains and tasks in the fast-evolving world. In practice, a continually pre-trained model is expected to demonstrate not only greater capacity when fine-tuned on pre-trained domains but also a non-decreasing performance on unseen ones. In this work, we first investigate such anytime fine-tuning effectiveness of existing continual pre-training approaches, concluding with unanimously decreased performance on unseen domains. To this end, we propose a prompt-guided continual pre-training method, where we train a hypernetwork to generate domain-specific prompts by both agreement and disagreement losses. The agreement loss maximally preserves the generalization of a pre-trained model to new domains, and the disagreement one guards the exclusiveness of the generated hidden states for each domain. Remarkably, prompts by the hypernetwork alleviate the domain identity when fine-tuning and promote knowledge transfer across domains. Our method achieved improvements of 3.57% and 3.4% on two real-world datasets (including domain shift and temporal shift), respectively, demonstrating its efficacy.
Learning to Substitute Spans towards Improving Compositional Generalization
Jun 05, 2023Despite the rising prevalence of neural sequence models, recent empirical evidences suggest their deficiency in compositional generalization. One of the current de-facto solutions to this problem is compositional data augmentation, aiming to incur additional compositional inductive bias. Nonetheless, the improvement offered by existing handcrafted augmentation strategies is limited when successful systematic generalization of neural sequence models requires multi-grained compositional bias (i.e., not limited to either lexical or structural biases only) or differentiation of training sequences in an imbalanced difficulty distribution. To address the two challenges, we first propose a novel compositional augmentation strategy dubbed \textbf{Span} \textbf{Sub}stitution (SpanSub) that enables multi-grained composition of substantial substructures in the whole training set. Over and above that, we introduce the \textbf{L}earning \textbf{to} \textbf{S}ubstitute \textbf{S}pan (L2S2) framework which empowers the learning of span substitution probabilities in SpanSub in an end-to-end manner by maximizing the loss of neural sequence models, so as to outweigh those challenging compositions with elusive concepts and novel surroundings. Our empirical results on three standard compositional generalization benchmarks, including SCAN, COGS and GeoQuery (with an improvement of at most 66.5\%, 10.3\%, 1.2\%, respectively), demonstrate the superiority of SpanSub, %the learning framework L2S2 and their combination.
Blind Image Quality Assessment via Vision-Language Correspondence: A Multitask Learning Perspective
Mar 27, 2023We aim at advancing blind image quality assessment (BIQA), which predicts the human perception of image quality without any reference information. We develop a general and automated multitask learning scheme for BIQA to exploit auxiliary knowledge from other tasks, in a way that the model parameter sharing and the loss weighting are determined automatically. Specifically, we first describe all candidate label combinations (from multiple tasks) using a textual template, and compute the joint probability from the cosine similarities of the visual-textual embeddings. Predictions of each task can be inferred from the joint distribution, and optimized by carefully designed loss functions. Through comprehensive experiments on learning three tasks - BIQA, scene classification, and distortion type identification, we verify that the proposed BIQA method 1) benefits from the scene classification and distortion type identification tasks and outperforms the state-of-the-art on multiple IQA datasets, 2) is more robust in the group maximum differentiation competition, and 3) realigns the quality annotations from different IQA datasets more effectively. The source code is available at https://github.com/zwx8981/LIQE.
Detecting the open-world objects with the help of the Brain
Mar 21, 2023



Open World Object Detection (OWOD) is a novel computer vision task with a considerable challenge, bridging the gap between classic object detection (OD) benchmarks and real-world object detection. In addition to detecting and classifying seen/known objects, OWOD algorithms are expected to detect unseen/unknown objects and incrementally learn them. The natural instinct of humans to identify unknown objects in their environments mainly depends on their brains' knowledge base. It is difficult for a model to do this only by learning from the annotation of several tiny datasets. The large pre-trained grounded language-image models - VL (\ie GLIP) have rich knowledge about the open world but are limited to the text prompt. We propose leveraging the VL as the ``Brain'' of the open-world detector by simply generating unknown labels. Leveraging it is non-trivial because the unknown labels impair the model's learning of known objects. In this paper, we alleviate these problems by proposing the down-weight loss function and decoupled detection structure. Moreover, our detector leverages the ``Brain'' to learn novel objects beyond VL through our pseudo-labeling scheme.
FGAHOI: Fine-Grained Anchors for Human-Object Interaction Detection
Jan 08, 2023Human-Object Interaction (HOI), as an important problem in computer vision, requires locating the human-object pair and identifying the interactive relationships between them. The HOI instance has a greater span in spatial, scale, and task than the individual object instance, making its detection more susceptible to noisy backgrounds. To alleviate the disturbance of noisy backgrounds on HOI detection, it is necessary to consider the input image information to generate fine-grained anchors which are then leveraged to guide the detection of HOI instances. However, it is challenging for the following reasons. i) how to extract pivotal features from the images with complex background information is still an open question. ii) how to semantically align the extracted features and query embeddings is also a difficult issue. In this paper, a novel end-to-end transformer-based framework (FGAHOI) is proposed to alleviate the above problems. FGAHOI comprises three dedicated components namely, multi-scale sampling (MSS), hierarchical spatial-aware merging (HSAM) and task-aware merging mechanism (TAM). MSS extracts features of humans, objects and interaction areas from noisy backgrounds for HOI instances of various scales. HSAM and TAM semantically align and merge the extracted features and query embeddings in the hierarchical spatial and task perspectives in turn. In the meanwhile, a novel training strategy Stage-wise Training Strategy is designed to reduce the training pressure caused by overly complex tasks done by FGAHOI. In addition, we propose two ways to measure the difficulty of HOI detection and a novel dataset, i.e., HOI-SDC for the two challenges (Uneven Distributed Area in Human-Object Pairs and Long Distance Visual Modeling of Human-Object Pairs) of HOI instances detection.
CAT: LoCalization and IdentificAtion Cascade Detection Transformer for Open-World Object Detection
Jan 05, 2023



Open-world object detection (OWOD), as a more general and challenging goal, requires the model trained from data on known objects to detect both known and unknown objects and incrementally learn to identify these unknown objects. The existing works which employ standard detection framework and fixed pseudo-labelling mechanism (PLM) have the following problems: (i) The inclusion of detecting unknown objects substantially reduces the model's ability to detect known ones. (ii) The PLM does not adequately utilize the priori knowledge of inputs. (iii) The fixed selection manner of PLM cannot guarantee that the model is trained in the right direction. We observe that humans subconsciously prefer to focus on all foreground objects and then identify each one in detail, rather than localize and identify a single object simultaneously, for alleviating the confusion. This motivates us to propose a novel solution called CAT: LoCalization and IdentificAtion Cascade Detection Transformer which decouples the detection process via the shared decoder in the cascade decoding way. In the meanwhile, we propose the self-adaptive pseudo-labelling mechanism which combines the model-driven with input-driven PLM and self-adaptively generates robust pseudo-labels for unknown objects, significantly improving the ability of CAT to retrieve unknown objects. Comprehensive experiments on two benchmark datasets, i.e., MS-COCO and PASCAL VOC, show that our model outperforms the state-of-the-art in terms of all metrics in the task of OWOD, incremental object detection (IOD) and open-set detection.
Hybrid Censored Quantile Regression Forest to Assess the Heterogeneous Effects
Dec 12, 2022In many applications, heterogeneous treatment effects on a censored response variable are of primary interest, and it is natural to evaluate the effects at different quantiles (e.g., median). The large number of potential effect modifiers, the unknown structure of the treatment effects, and the presence of right censoring pose significant challenges. In this paper, we develop a hybrid forest approach called Hybrid Censored Quantile Regression Forest (HCQRF) to assess the heterogeneous effects varying with high-dimensional variables. The hybrid estimation approach takes advantage of the random forests and the censored quantile regression. We propose a doubly-weighted estimation procedure that consists of a redistribution-of-mass weight to handle censoring and an adaptive nearest neighbor weight derived from the forest to handle high-dimensional effect functions. We propose a variable importance decomposition to measure the impact of a variable on the treatment effect function. Extensive simulation studies demonstrate the efficacy and stability of HCQRF. The result of the simulation study also convinces us of the effectiveness of the variable importance decomposition. We apply HCQRF to a clinical trial of colorectal cancer. We achieve insightful estimations of the treatment effect and meaningful variable importance results. The result of the variable importance also confirms the necessity of the decomposition.
Disentangling Task Relations for Few-shot Text Classification via Self-Supervised Hierarchical Task Clustering
Nov 16, 2022Few-Shot Text Classification (FSTC) imitates humans to learn a new text classifier efficiently with only few examples, by leveraging prior knowledge from historical tasks. However, most prior works assume that all the tasks are sampled from a single data source, which cannot adapt to real-world scenarios where tasks are heterogeneous and lie in different distributions. As such, existing methods may suffer from their globally knowledge-shared mechanisms to handle the task heterogeneity. On the other hand, inherent task relation are not explicitly captured, making task knowledge unorganized and hard to transfer to new tasks. Thus, we explore a new FSTC setting where tasks can come from a diverse range of data sources. To address the task heterogeneity, we propose a self-supervised hierarchical task clustering (SS-HTC) method. SS-HTC not only customizes cluster-specific knowledge by dynamically organizing heterogeneous tasks into different clusters in hierarchical levels but also disentangles underlying relations between tasks to improve the interpretability. Extensive experiments on five public FSTC benchmark datasets demonstrate the effectiveness of SS-HTC.
Wasserstein Distributional Learning
Sep 12, 2022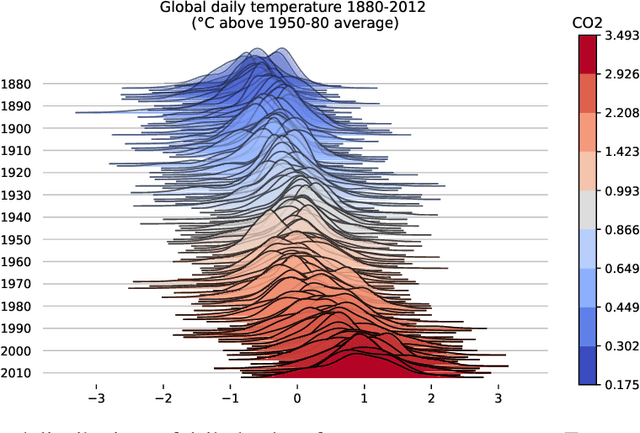

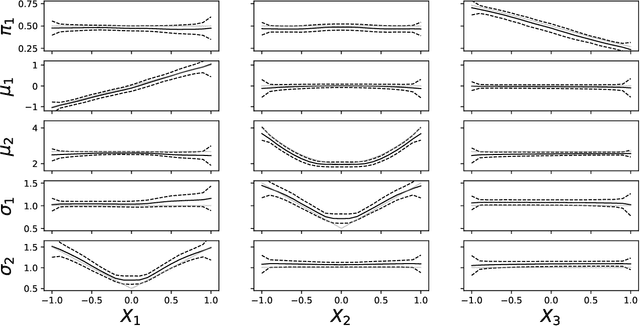
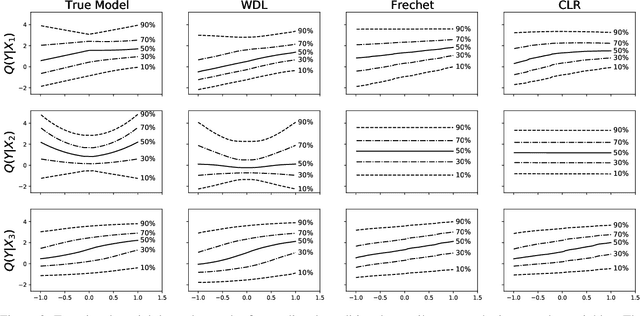
Learning conditional densities and identifying factors that influence the entire distribution are vital tasks in data-driven applications. Conventional approaches work mostly with summary statistics, and are hence inadequate for a comprehensive investigation. Recently, there have been developments on functional regression methods to model density curves as functional outcomes. A major challenge for developing such models lies in the inherent constraint of non-negativity and unit integral for the functional space of density outcomes. To overcome this fundamental issue, we propose Wasserstein Distributional Learning (WDL), a flexible density-on-scalar regression modeling framework that starts with the Wasserstein distance $W_2$ as a proper metric for the space of density outcomes. We then introduce a heterogeneous and flexible class of Semi-parametric Conditional Gaussian Mixture Models (SCGMM) as the model class $\mathfrak{F} \otimes \mathcal{T}$. The resulting metric space $(\mathfrak{F} \otimes \mathcal{T}, W_2)$ satisfies the required constraints and offers a dense and closed functional subspace. For fitting the proposed model, we further develop an efficient algorithm based on Majorization-Minimization optimization with boosted trees. Compared with methods in the previous literature, WDL better characterizes and uncovers the nonlinear dependence of the conditional densities, and their derived summary statistics. We demonstrate the effectiveness of the WDL framework through simulations and real-world applications.