 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestoration Score Distillation: From Corrupted Diffusion Pretraining to One-Step High-Quality Generation
May 19, 2025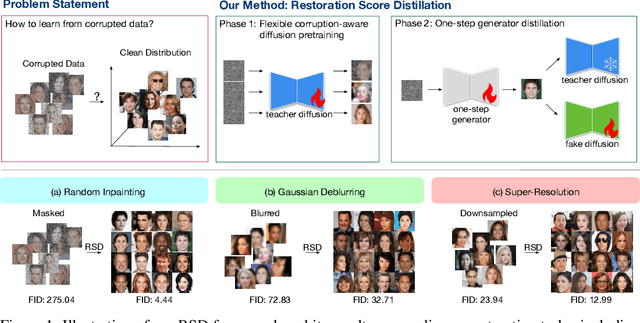


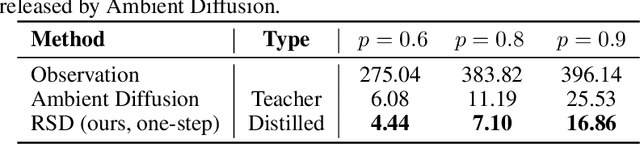
Learning generative models from corrupted data is a fundamental yet persistently challenging task across scientific disciplines, particularly when access to clean data is limited or expensive. Denoising Score Distillation (DSD) \cite{chen2025denoising} recently introduced a novel and surprisingly effective strategy that leverages score distillation to train high-fidelity generative models directly from noisy observations. Building upon this foundation, we propose \textit{Restoration Score Distillation} (RSD), a principled generalization of DSD that accommodates a broader range of corruption types, such as blurred, incomplete, or low-resolution images. RSD operates by first pretraining a teacher diffusion model solely on corrupted data and subsequently distilling it into a single-step generator that produces high-quality reconstructions. Empirically, RSD consistently surpasses its teacher model across diverse restoration tasks on both natural and scientific datasets. Moreover, beyond standard diffusion objectives, the RSD framework is compatible with several corruption-aware training techniques such as Ambient Tweedie, Ambient Diffusion, and its Fourier-space variant, enabling flexible integration with recent advances in diffusion modeling. Theoretically, we demonstrate that in a linear regime, RSD recovers the eigenspace of the clean data covariance matrix from linear measurements, thereby serving as an implicit regularizer. This interpretation recasts score distillation not only as a sampling acceleration technique but as a principled approach to enhancing generative performance in severely degraded data regimes.
Latent Adaptive Planner for Dynamic Manipulation
May 06, 2025



This paper presents Latent Adaptive Planner (LAP), a novel approach for dynamic nonprehensile manipulation tasks that formulates planning as latent space inference, effectively learned from human demonstration videos. Our method addresses key challenges in visuomotor policy learning through a principled variational replanning framework that maintains temporal consistency while efficiently adapting to environmental changes. LAP employs Bayesian updating in latent space to incrementally refine plans as new observations become available, striking an optimal balance between computational efficiency and real-time adaptability. We bridge the embodiment gap between humans and robots through model-based proportional mapping that regenerates accurate kinematic-dynamic joint states and object positions from human demonstrations. Experimental evaluations across multiple complex manipulation benchmarks demonstrate that LAP achieves state-of-the-art performance, outperforming existing approaches in success rate, trajectory smoothness, and energy efficiency, particularly in dynamic adaptation scenarios. Our approach enables robots to perform complex interactions with human-like adaptability while providing an expandable framework applicable to diverse robotic platforms using the same human demonstration videos.
Denoising Score Distillation: From Noisy Diffusion Pretraining to One-Step High-Quality Generation
Mar 10, 2025Diffusion models have achieved remarkable success in generating high-resolution, realistic images across diverse natural distributions. However, their performance heavily relies on high-quality training data, making it challenging to learn meaningful distributions from corrupted samples. This limitation restricts their applicability in scientific domains where clean data is scarce or costly to obtain. In this work, we introduce denoising score distillation (DSD), a surprisingly effective and novel approach for training high-quality generative models from low-quality data. DSD first pretrains a diffusion model exclusively on noisy, corrupted samples and then distills it into a one-step generator capable of producing refined, clean outputs. While score distillation is traditionally viewed as a method to accelerate diffusion models, we show that it can also significantly enhance sample quality, particularly when starting from a degraded teacher model. Across varying noise levels and datasets, DSD consistently improves generative performancewe summarize our empirical evidence in Fig. 1. Furthermore, we provide theoretical insights showing that, in a linear model setting, DSD identifies the eigenspace of the clean data distributions covariance matrix, implicitly regularizing the generator. This perspective reframes score distillation as not only a tool for efficiency but also a mechanism for improving generative models, particularly in low-quality data settings.
Scalable Language Models with Posterior Inference of Latent Thought Vectors
Feb 03, 2025



We propose a novel family of language models, Latent-Thought Language Models (LTMs), which incorporate explicit latent thought vectors that follow an explicit prior model in latent space. These latent thought vectors guide the autoregressive generation of ground tokens through a Transformer decoder. Training employs a dual-rate optimization process within the classical variational Bayes framework: fast learning of local variational parameters for the posterior distribution of latent vectors, and slow learning of global decoder parameters. Empirical studies reveal that LTMs possess additional scaling dimensions beyond traditional LLMs, yielding a structured design space. Higher sample efficiency can be achieved by increasing training compute per token, with further gains possible by trading model size for more inference steps. Designed based on these scaling properties, LTMs demonstrate superior sample and parameter efficiency compared to conventional autoregressive models and discrete diffusion models. They significantly outperform these counterparts in validation perplexity and zero-shot language modeling. Additionally, LTMs exhibit emergent few-shot in-context reasoning capabilities that scale with model and latent size, and achieve competitive performance in conditional and unconditional text generation.
Better Prompt Compression Without Multi-Layer Perceptrons
Jan 12, 2025



Prompt compression is a promising approach to speeding up language model inference without altering the generative model. Prior works compress prompts into smaller sequences of learned tokens using an encoder that is trained as a LowRank Adaptation (LoRA) of the inference language model. However, we show that the encoder does not need to keep the original language model's architecture to achieve useful compression. We introduce the Attention-Only Compressor (AOC), which learns a prompt compression encoder after removing the multilayer perceptron (MLP) layers in the Transformer blocks of a language model, resulting in an encoder with roughly 67% less parameters compared to the original model. Intriguingly we find that, across a range of compression ratios up to 480x, AOC can better regenerate prompts and outperform a baseline compression encoder that is a LoRA of the inference language model without removing MLP layers. These results demonstrate that the architecture of prompt compression encoders does not need to be identical to that of the original decoder language model, paving the way for further research into architectures and approaches for prompt compression.
TeamCraft: A Benchmark for Multi-Modal Multi-Agent Systems in Minecraft
Dec 06, 2024



Collaboration is a cornerstone of society. In the real world, human teammates make use of multi-sensory data to tackle challenging tasks in ever-changing environments. It is essential for embodied agents collaborating in visually-rich environments replete with dynamic interactions to understand multi-modal observations and task specifications. To evaluate the performance of generalizable multi-modal collaborative agents, we present TeamCraft, a multi-modal multi-agent benchmark built on top of the open-world video game Minecraft. The benchmark features 55,000 task variants specified by multi-modal prompts, procedurally-generated expert demonstrations for imitation learning, and carefully designed protocols to evaluate model generalization capabilities. We also perform extensive analyses to better understand the limitations and strengths of existing approaches. Our results indicate that existing models continue to face significant challenges in generalizing to novel goals, scenes, and unseen numbers of agents. These findings underscore the need for further research in this area. The TeamCraft platform and dataset are publicly available at https://github.com/teamcraft-bench/teamcraft.
Learning the Evolution of Physical Structure of Galaxies via Diffusion Models
Nov 27, 2024



In astrophysics, understanding the evolution of galaxies in primarily through imaging data is fundamental to comprehending the formation of the Universe. This paper introduces a novel approach to conditioning Denoising Diffusion Probabilistic Models (DDPM) on redshifts for generating galaxy images. We explore whether this advanced generative model can accurately capture the physical characteristics of galaxies based solely on their images and redshift measurements. Our findings demonstrate that this model not only produces visually realistic galaxy images but also encodes the underlying changes in physical properties with redshift that are the result of galaxy evolution. This approach marks a significant advancement in using generative models to enhance our scientific insight into cosmic phenomena.
Unlocking the Potential of Text-to-Image Diffusion with PAC-Bayesian Theory
Nov 25, 2024



Text-to-image (T2I) diffusion models have revolutionized generative modeling by producing high-fidelity, diverse, and visually realistic images from textual prompts. Despite these advances, existing models struggle with complex prompts involving multiple objects and attributes, often misaligning modifiers with their corresponding nouns or neglecting certain elements. Recent attention-based methods have improved object inclusion and linguistic binding, but still face challenges such as attribute misbinding and a lack of robust generalization guarantees. Leveraging the PAC-Bayes framework, we propose a Bayesian approach that designs custom priors over attention distributions to enforce desirable properties, including divergence between objects, alignment between modifiers and their corresponding nouns, minimal attention to irrelevant tokens, and regularization for better generalization. Our approach treats the attention mechanism as an interpretable component, enabling fine-grained control and improved attribute-object alignment. We demonstrate the effectiveness of our method on standard benchmarks, achieving state-of-the-art results across multiple metrics. By integrating custom priors into the denoising process, our method enhances image quality and addresses long-standing challenges in T2I diffusion models, paving the way for more reliable and interpretable generative models.
Quantifying Preferences of Vision-Language Models via Value Decomposition in Social Media Contexts
Nov 18, 2024The rapid advancement of Vision-Language Models (VLMs) has expanded multimodal applications, yet evaluations often focus on basic tasks like object recognition, overlooking abstract aspects such as personalities and values. To address this gap, we introduce Value-Spectrum, a visual question-answering benchmark aimed at assessing VLMs based on Schwartz's value dimensions, which capture core values guiding people's beliefs and actions across cultures. We constructed a vectorized database of over 50,000 short videos sourced from TikTok, YouTube Shorts, and Instagram Reels, covering multiple months and a wide array of topics such as family, health, hobbies, society, and technology. We also developed a VLM agent pipeline to automate video browsing and analysis. Benchmarking representative VLMs on Value-Spectrum reveals significant differences in their responses to value-oriented content, with most models exhibiting a preference for hedonistic topics. Beyond identifying natural preferences, we explored the ability of VLM agents to adopt specific personas when explicitly prompted, revealing insights into the models' adaptability in role-playing scenarios. These findings highlight the potential of Value-Spectrum as a comprehensive evaluation set for tracking VLM advancements in value-based tasks and for developing more sophisticated role-playing AI agents.
A minimalistic representation model for head direction system
Nov 15, 2024



We present a minimalistic representation model for the head direction (HD) system, aiming to learn a high-dimensional representation of head direction that captures essential properties of HD cells. Our model is a representation of rotation group $U(1)$, and we study both the fully connected version and convolutional version. We demonstrate the emergence of Gaussian-like tuning profiles and a 2D circle geometry in both versions of the model. We also demonstrate that the learned model is capable of accurate path integration.