 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimalist and High-performance Conversational Recommendation with Uncertainty Estimation for User Preference
Jul 01, 2022

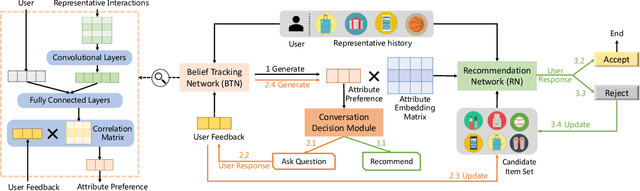
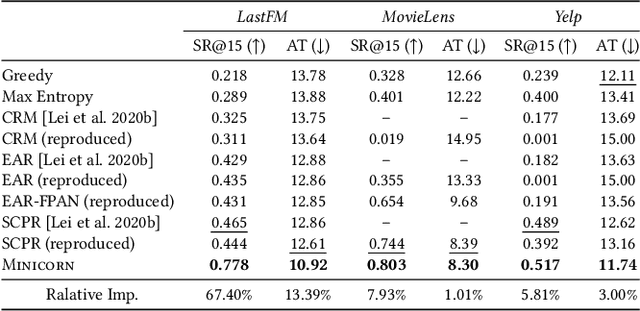
Conversational recommendation system (CRS) is emerging as a user-friendly way to capture users' dynamic preferences over candidate items and attributes. Multi-shot CRS is designed to make recommendations multiple times until the user either accepts the recommendation or leaves at the end of their patience. Existing works are trained with reinforcement learning (RL), which may suffer from unstable learning and prohibitively high demands for computing. In this work, we propose a simple and efficient CRS, MInimalist Non-reinforced Interactive COnversational Recommender Network (MINICORN). MINICORN models the epistemic uncertainty of the estimated user preference and queries the user for the attribute with the highest uncertainty. The system employs a simple network architecture and makes the query-vs-recommendation decision using a single rule. Somewhat surprisingly, this minimalist approach outperforms state-of-the-art RL methods on three real-world datasets by large margins. We hope that MINICORN will serve as a valuable baseline for future research.
Learning Large-scale Subsurface Simulations with a Hybrid Graph Network Simulator
Jun 15, 2022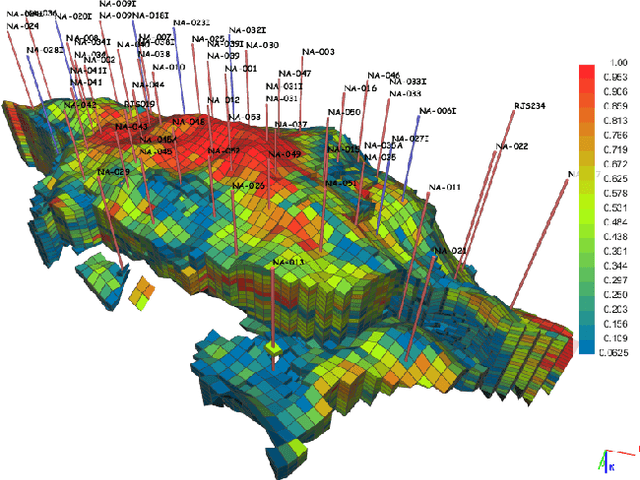
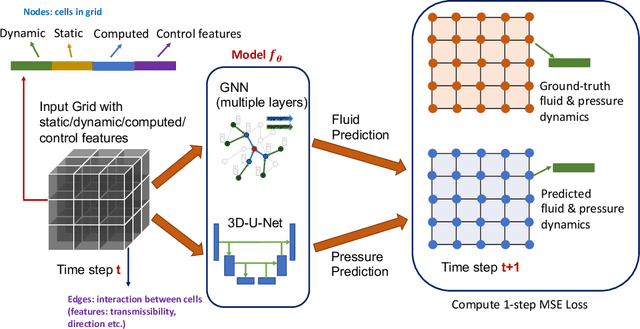
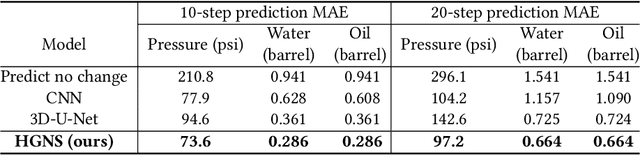
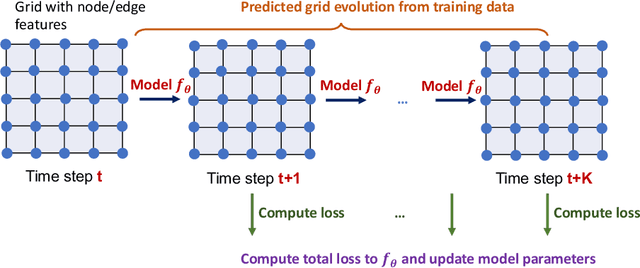
Subsurface simulations use computational models to predict the flow of fluids (e.g., oil, water, gas) through porous media. These simulations are pivotal in industrial applications such as petroleum production, where fast and accurate models are needed for high-stake decision making, for example, for well placement optimization and field development planning. Classical finite difference numerical simulators require massive computational resources to model large-scale real-world reservoirs. Alternatively, streamline simulators and data-driven surrogate models are computationally more efficient by relying on approximate physics models, however they are insufficient to model complex reservoir dynamics at scale. Here we introduce Hybrid Graph Network Simulator (HGNS), which is a data-driven surrogate model for learning reservoir simulations of 3D subsurface fluid flows. To model complex reservoir dynamics at both local and global scale, HGNS consists of a subsurface graph neural network (SGNN) to model the evolution of fluid flows, and a 3D-U-Net to model the evolution of pressure. HGNS is able to scale to grids with millions of cells per time step, two orders of magnitude higher than previous surrogate models, and can accurately predict the fluid flow for tens of time steps (years into the future). Using an industry-standard subsurface flow dataset (SPE-10) with 1.1 million cells, we demonstrate that HGNS is able to reduce the inference time up to 18 times compared to standard subsurface simulators, and that it outperforms other learning-based models by reducing long-term prediction errors by up to 21%.
IA-GCN: Interactive Graph Convolutional Network for Recommendation
Apr 08, 2022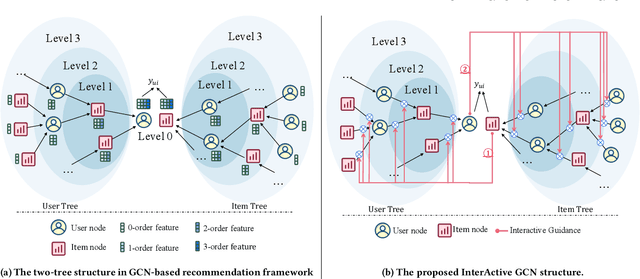

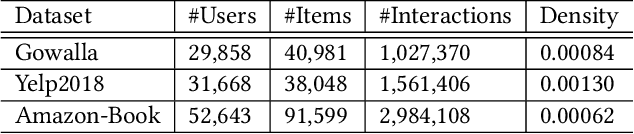
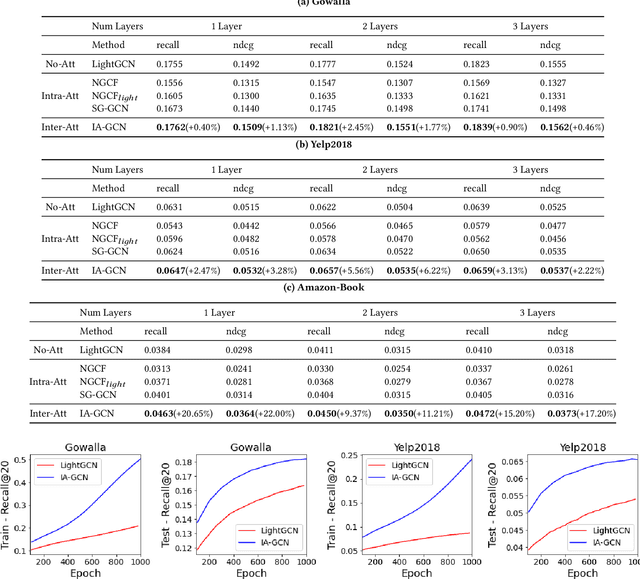
Recently, Graph Convolutional Network (GCN) has become a novel state-of-art for Collaborative Filtering (CF) based Recommender Systems (RS). It is a common practice to learn informative user and item representations by performing embedding propagation on a user-item bipartite graph, and then provide the users with personalized item suggestions based on the representations. Despite effectiveness, existing algorithms neglect precious interactive features between user-item pairs in the embedding process. When predicting a user's preference for different items, they still aggregate the user tree in the same way, without emphasizing target-related information in the user neighborhood. Such a uniform aggregation scheme easily leads to suboptimal user and item representations, limiting the model expressiveness to some extent. In this work, we address this problem by building bilateral interactive guidance between each user-item pair and proposing a new model named IA-GCN (short for InterActive GCN). Specifically, when learning the user representation from its neighborhood, we assign higher attention weights to those neighbors similar to the target item. Correspondingly, when learning the item representation, we pay more attention to those neighbors resembling the target user. This leads to interactive and interpretable features, effectively distilling target-specific information through each graph convolutional operation. Our model is built on top of LightGCN, a state-of-the-art GCN model for CF, and can be combined with various GCN-based CF architectures in an end-to-end fashion. Extensive experiments on three benchmark datasets demonstrate the effectiveness and robustness of IA-GCN.
Initialization Matters: Regularizing Manifold-informed Initialization for Neural Recommendation Systems
Jun 09, 2021

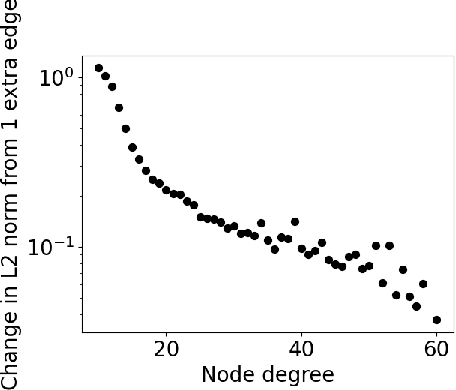
Proper initialization is crucial to the optimization and the generalization of neural networks. However, most existing neural recommendation systems initialize the user and item embeddings randomly. In this work, we propose a new initialization scheme for user and item embeddings called Laplacian Eigenmaps with Popularity-based Regularization for Isolated Data (LEPORID). LEPORID endows the embeddings with information regarding multi-scale neighborhood structures on the data manifold and performs adaptive regularization to compensate for high embedding variance on the tail of the data distribution. Exploiting matrix sparsity, LEPORID embeddings can be computed efficiently. We evaluate LEPORID in a wide range of neural recommendation models. In contrast to the recent surprising finding that the simple K-nearest-neighbor (KNN) method often outperforms neural recommendation systems, we show that existing neural systems initialized with LEPORID often perform on par or better than KNN. To maximize the effects of the initialization, we propose the Dual-Loss Residual Recommendation (DLR2) network, which, when initialized with LEPORID, substantially outperforms both traditional and state-of-the-art neural recommender systems.
Neural Radiance Flow for 4D View Synthesis and Video Processing
Dec 17, 2020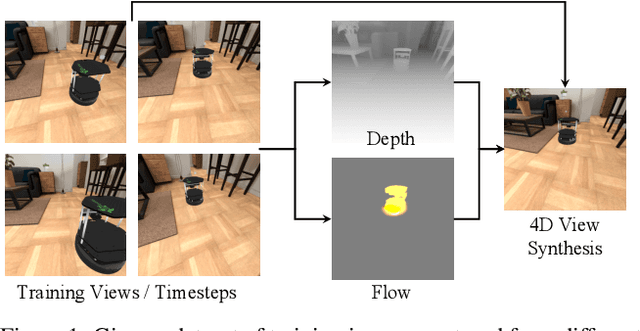
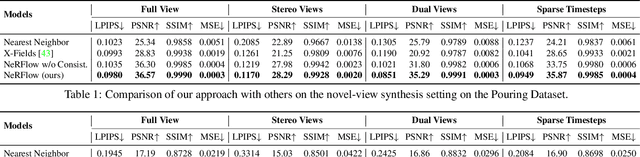
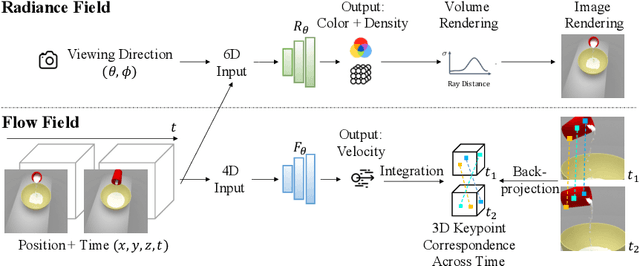

We present a method, Neural Radiance Flow (NeRFlow),to learn a 4D spatial-temporal representation of a dynamic scene from a set of RGB images. Key to our approach is the use of a neural implicit representation that learns to capture the 3D occupancy, radiance, and dynamics of the scene. By enforcing consistency across different modalities, our representation enables multi-view rendering in diverse dynamic scenes, including water pouring, robotic interaction, and real images, outperforming state-of-the-art methods for spatial-temporal view synthesis. Our approach works even when inputs images are captured with only one camera. We further demonstrate that the learned representation can serve as an implicit scene prior, enabling video processing tasks such as image super-resolution and de-noising without any additional supervision.
Image GANs meet Differentiable Rendering for Inverse Graphics and Interpretable 3D Neural Rendering
Oct 18, 2020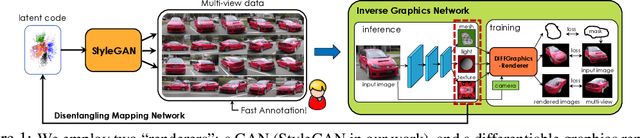



Differentiable rendering has paved the way to training neural networks to perform "inverse graphics" tasks such as predicting 3D geometry from monocular photographs. To train high performing models, most of the current approaches rely on multi-view imagery which are not readily available in practice. Recent Generative Adversarial Networks (GANs) that synthesize images, in contrast, seem to acquire 3D knowledge implicitly during training: object viewpoints can be manipulated by simply manipulating the latent codes. However, these latent codes often lack further physical interpretation and thus GANs cannot easily be inverted to perform explicit 3D reasoning. In this paper, we aim to extract and disentangle 3D knowledge learned by generative models by utilizing differentiable renderers. Key to our approach is to exploit GANs as a multi-view data generator to train an inverse graphics network using an off-the-shelf differentiable renderer, and the trained inverse graphics network as a teacher to disentangle the GAN's latent code into interpretable 3D properties. The entire architecture is trained iteratively using cycle consistency losses. We show that our approach significantly outperforms state-of-the-art inverse graphics networks trained on existing datasets, both quantitatively and via user studies. We further showcase the disentangled GAN as a controllable 3D "neural renderer", complementing traditional graphics renderers.
Explicit Pairwise Word Interaction Modeling Improves Pretrained Transformers for English Semantic Similarity Tasks
Nov 07, 2019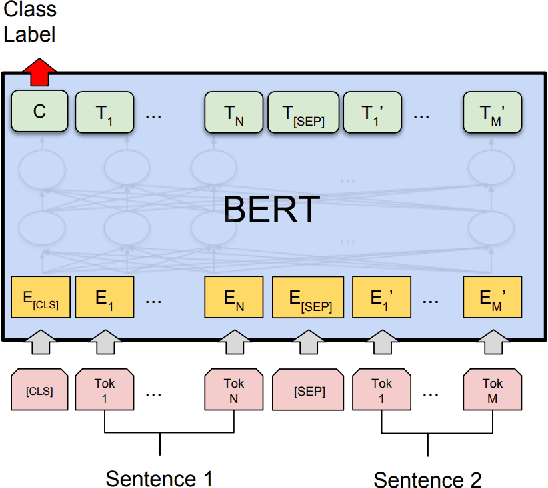
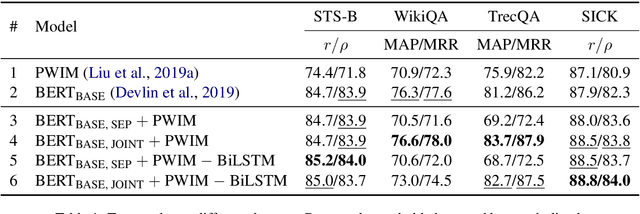
In English semantic similarity tasks, classic word embedding-based approaches explicitly model pairwise "interactions" between the word representations of a sentence pair. Transformer-based pretrained language models disregard this notion, instead modeling pairwise word interactions globally and implicitly through their self-attention mechanism. In this paper, we hypothesize that introducing an explicit, constrained pairwise word interaction mechanism to pretrained language models improves their effectiveness on semantic similarity tasks. We validate our hypothesis using BERT on four tasks in semantic textual similarity and answer sentence selection. We demonstrate consistent improvements in quality by adding an explicit pairwise word interaction module to BERT.
PuzzleFlex: kinematic motion of chains with loose joints
Jun 20, 2019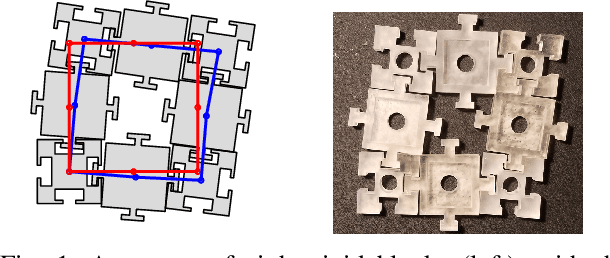
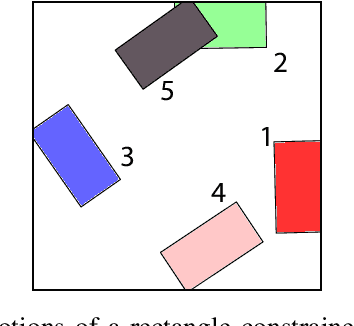

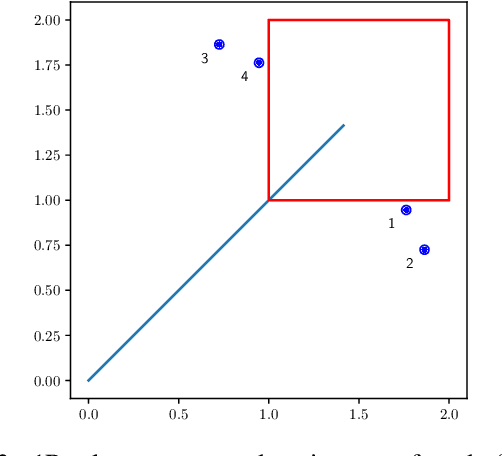
This paper presents a method of computing free motions of a planar assembly of rigid bodies connected by loose joints. Joints are modeled using local distance constraints, which are then linearized with respect to configuration space velocities, yielding a linear programming formulation that allows analysis of systems with thousands of rigid bodies. Potential applications include analysis of collections of modular robots, structural stability perturbation analysis, tolerance analysis for mechanical systems,and formation control of mobile robots.
Diversity-Promoting Deep Reinforcement Learning for Interactive Recommendation
Mar 19, 2019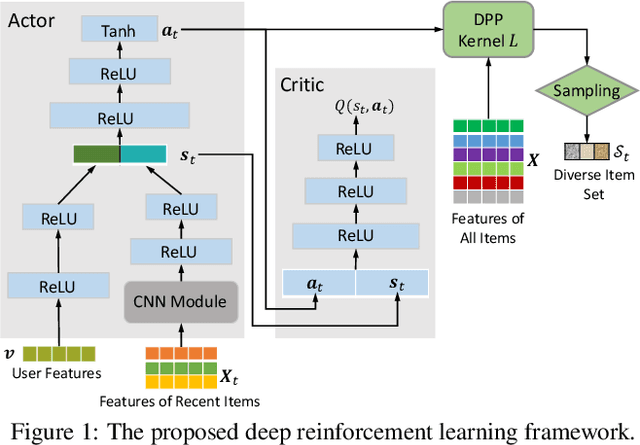

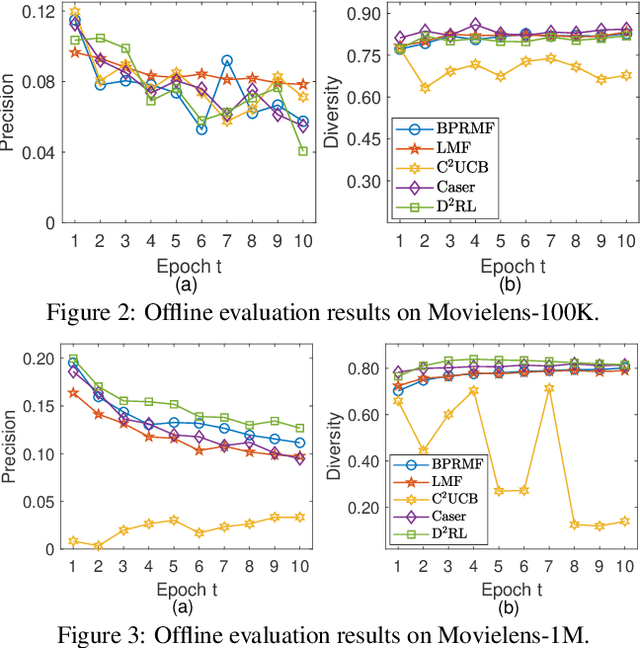
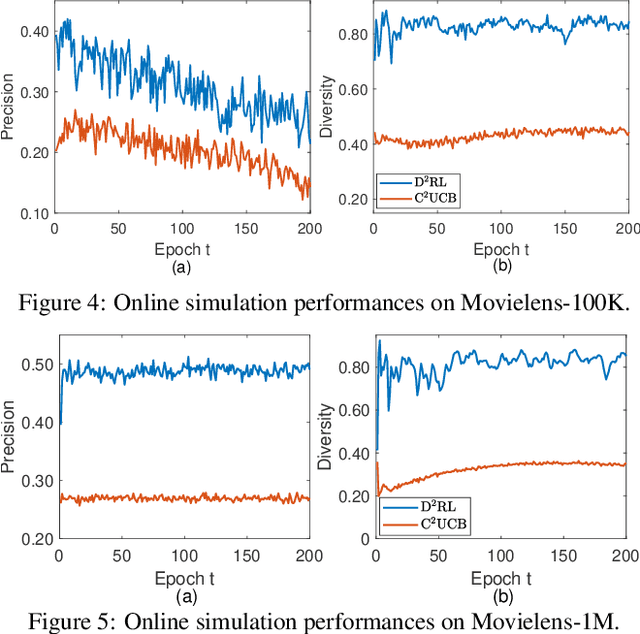
Interactive recommendation that models the explicit interactions between users and the recommender system has attracted a lot of research attentions in recent years. Most previous interactive recommendation systems only focus on optimizing recommendation accuracy while overlooking other important aspects of recommendation quality, such as the diversity of recommendation results. In this paper, we propose a novel recommendation model, named \underline{D}iversity-promoting \underline{D}eep \underline{R}einforcement \underline{L}earning (D$^2$RL), which encourages the diversity of recommendation results in interaction recommendations. More specifically, we adopt a Determinantal Point Process (DPP) model to generate diverse, while relevant item recommendations. A personalized DPP kernel matrix is maintained for each user, which is constructed from two parts: a fixed similarity matrix capturing item-item similarity, and the relevance of items dynamically learnt through an actor-critic reinforcement learning framework. We performed extensive offline experiments as well as simulated online experiments with real world datasets to demonstrate the effectiveness of the proposed model.
Towards Physically Safe Reinforcement Learning under Supervision
Jan 19, 2019
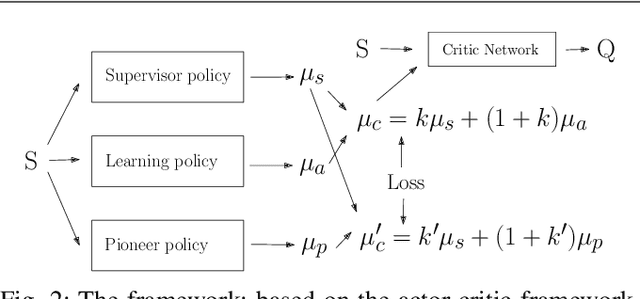
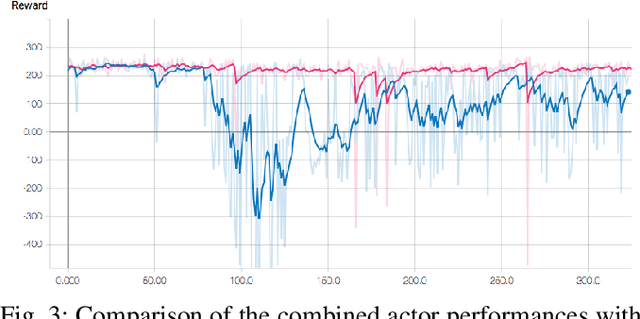
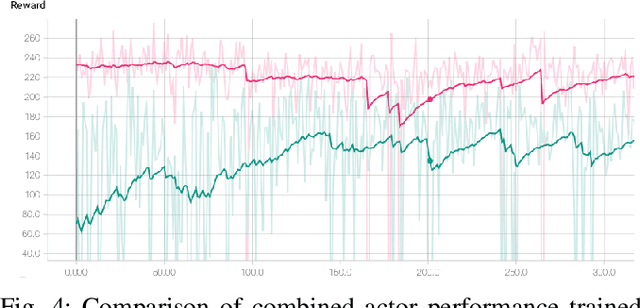
This paper addresses the question of how a previously available control policy $\pi_s$ can be used as a supervisor to more quickly and safely train a new learned control policy $\pi_L$ for a robot. A weighted average of the supervisor and learned policies is used during trials, with a heavier weight initially on the supervisor, in order to allow safe and useful physical trials while the learned policy is still ineffective. During the process, the weight is adjusted to favor the learned policy. As weights are adjusted, the learned network must compensate so as to give safe and reasonable outputs under the different weights. A pioneer network is introduced that pre-learns a policy that performs similarly to the current learned policy under the planned next step for new weights; this pioneer network then replaces the currently learned network in the next set of trials. Experiments in OpenAI Gym demonstrate the effectiveness of the proposed method.