 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState-space models through the lens of ensemble control
Mar 13, 2026State-space models (SSMs) are effective architectures for sequential modeling, but a rigorous theoretical understanding of their training dynamics is still lacking. In this work, we formulate the training of SSMs as an ensemble optimal control problem, where a shared control law governs a population of input-dependent dynamical systems. We derive Pontryagin's maximum principle (PMP) for this ensemble control formulation, providing necessary conditions for optimality. Motivated by these conditions, we introduce an algorithm based on the method of successive approximations. We prove convergence of this iterative scheme along a subsequence and establish sufficient conditions for global optimality. The resulting framework provides a control-theoretic perspective on SSM training.
Human-AI Co-reasoning for Clinical Diagnosis with Evidence-Integrated Language Agent
Mar 11, 2026We present PULSE, a medical reasoning agent that combines a domain-tuned large language model with scientific literature retrieval to support diagnostic decision-making in complex real-world cases. To evaluate its capabilities, we curated a benchmark of 82 authentic endocrinology case reports encompassing a broad spectrum of disease types and incidence levels. In controlled experiments, we compared PULSE's performance against physicians with varying levels of expertise-from residents to senior specialists-and examined how AI assistance influenced human diagnostic reasoning. PULSE attained expert-competitive accuracy, outperforming residents and junior specialists while matching senior specialist performance at both Top@1 and Top@4 thresholds. Unlike physicians, whose accuracy declined with disease rarity, PULSE maintained stable performance across incidence tiers. The agent also exhibited adaptive reasoning, increasing output length with case difficulty in a manner analogous to the longer deliberation observed among expert clinicians. When used collaboratively, PULSE enabled physicians to correct initial errors and broaden diagnostic hypotheses, but also introduced risks of automation bias. The study explores both serial and concurrent collaboration workflows, revealing that PULSE offers robust support across common and rare presentations. These findings underscore both the promise and the limitations of language model-based agents in clinical diagnosis, and offer a framework for evaluating their role in real-world decision-making.
LLaMA Pro: Progressive LLaMA with Block Expansion
Jan 04, 2024



Humans generally acquire new skills without compromising the old; however, the opposite holds for Large Language Models (LLMs), e.g., from LLaMA to CodeLLaMA. To this end, we propose a new post-pretraining method for LLMs with an expansion of Transformer blocks. We tune the expanded blocks using only new corpus, efficiently and effectively improving the model's knowledge without catastrophic forgetting. In this paper, we experiment on the corpus of code and math, yielding LLaMA Pro-8.3B, a versatile foundation model initialized from LLaMA2-7B, excelling in general tasks, programming, and mathematics. LLaMA Pro and its instruction-following counterpart (LLaMA Pro-Instruct) achieve advanced performance among various benchmarks, demonstrating superiority over existing open models in the LLaMA family and the immense potential of reasoning and addressing diverse tasks as an intelligent agent. Our findings provide valuable insights into integrating natural and programming languages, laying a solid foundation for developing advanced language agents that operate effectively in various environments.
Sampling Clustering
Jun 21, 2018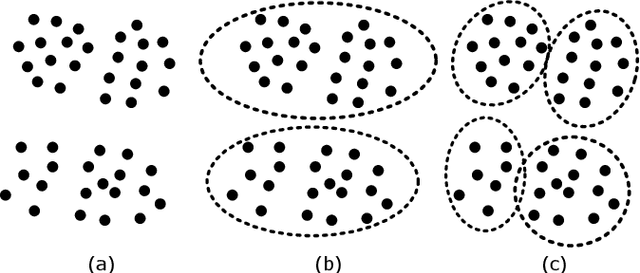
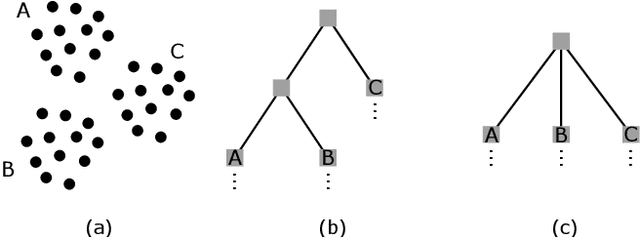
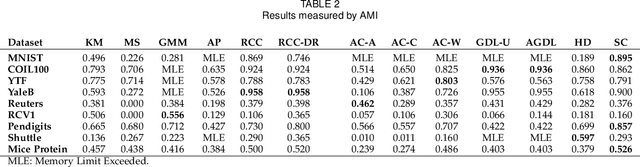
We propose an efficient graph-based divisive cluster analysis approach called sampling clustering. It constructs a lite informative dendrogram by recursively dividing a graph into subgraphs. In each recursive call, a graph is sampled first with a set of vertices being removed to disconnect latent clusters, then condensed by adding edges to the remaining vertices to avoid graph fragmentation caused by vertex removals. We also present some sampling and condensing methods and discuss the effectiveness in this paper. Our implementations run in linear time and achieve outstanding performance on various types of datasets. Experimental results show that they outperform state-of-the-art clustering algorithms with significantly less computing resources requirements.