 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeClaw: Spec-Driven Security Task Synthesis for Evaluating Autonomous Agents
Jun 01, 2026Autonomous LLM agents increasingly operate in stateful environments where they access tools, files, memory, and external services. While such capabilities enable complex real-world workflows, they also introduce security risks that are difficult to capture with existing evaluations. Current agent security benchmarks often rely on manually curated tasks, provide limited coverage of emerging threats, and focus primarily on final outcomes rather than the execution processes that lead to unsafe behavior. We introduce SeClaw, a framework that combines specification-driven security task synthesis with execution-based security evaluation for Autonomous agents. Spec-driven security task synthesis enables scalable and controllable construction of security tasks from structured risk specifications, while SeClaw docker provides a standardized testbed for evaluating agent behavior under diverse safety-risk scenarios. The benchmark covers risks arising from resources, user tasks, environments, and intrinsic agent behaviors, and supports trajectory-aware assessment of unsafe actions beyond final responses. By bridging systematic task synthesis and reproducible security evaluation, SeClaw provides a practical foundation for measuring, diagnosing, and comparing security failures in autonomous LLM agents. The code is available at https://github.com/seclaw-eval/seclaw-eval.
Scaling Human-AI Coding Collaboration Requires a Governable Consensus Layer
Apr 20, 2026Vibe coding produces correct, executable code at speed, but leaves no record of the structural commitments, dependencies, or evidence behind it. Reviewers cannot determine what invariants were assumed, what changed, or why a regression occurred. This is not a generation failure but a control failure: the dominant artifact of AI-assisted development (code plus chat history) performs dimension collapse, flattening complex system topology into low-dimensional text and making systems opaque and fragile under change. We propose Agentic Consensus: a paradigm in which the consensus layer C, an operable world model represented as a typed property graph, replaces code as the primary artifact of engineering. Executable artifacts are derived from C and kept in correspondence via synchronization operators Phi (realize) and Psi (rehydrate). Evidence links directly to structural claims in C, making every commitment auditable and under-specification explicit as measurable consensus entropy rather than a silent guess. Evaluation must move beyond code correctness toward alignment fidelity, consensus entropy, and intervention distance. We propose benchmark task families designed to measure whether consensus-based workflows reduce human intervention compared to chat-driven baselines.
Efficient Cross-Country Data Acquisition Strategy for ADAS via Street-View Imagery
Feb 02, 2026Deploying ADAS and ADS across countries remains challenging due to differences in legislation, traffic infrastructure, and visual conventions, which introduce domain shifts that degrade perception performance. Traditional cross-country data collection relies on extensive on-road driving, making it costly and inefficient to identify representative locations. To address this, we propose a street-view-guided data acquisition strategy that leverages publicly available imagery to identify places of interest (POI). Two POI scoring methods are introduced: a KNN-based feature distance approach using a vision foundation model, and a visual-attribution approach using a vision-language model. To enable repeatable evaluation, we adopt a collect-detect protocol and construct a co-located dataset by pairing the Zenseact Open Dataset with Mapillary street-view images. Experiments on traffic sign detection, a task particularly sensitive to cross-country variations in sign appearance, show that our approach achieves performance comparable to random sampling while using only half of the target-domain data. We further provide cost estimations for full-country analysis, demonstrating that large-scale street-view processing remains economically feasible. These results highlight the potential of street-view-guided data acquisition for efficient and cost-effective cross-country model adaptation.
Enhanced Ideal Objective Vector Estimation for Evolutionary Multi-Objective Optimization
May 28, 2025

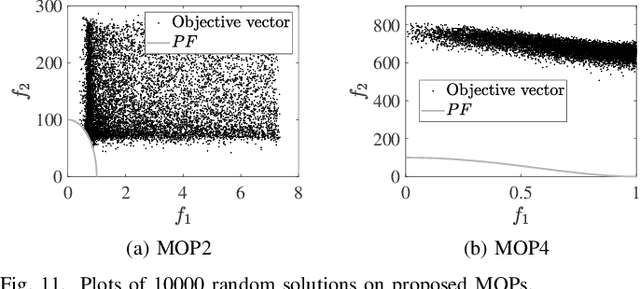

The ideal objective vector, which comprises the optimal values of the $m$ objective functions in an $m$-objective optimization problem, is an important concept in evolutionary multi-objective optimization. Accurate estimation of this vector has consistently been a crucial task, as it is frequently used to guide the search process and normalize the objective space. Prevailing estimation methods all involve utilizing the best value concerning each objective function achieved by the individuals in the current or accumulated population. However, this paper reveals that the population-based estimation method can only work on simple problems but falls short on problems with substantial bias. The biases in multi-objective optimization problems can be divided into three categories, and an analysis is performed to illustrate how each category hinders the estimation of the ideal objective vector. Subsequently, a set of test instances is proposed to quantitatively evaluate the impact of various biases on the ideal objective vector estimation method. Beyond that, a plug-and-play component called enhanced ideal objective vector estimation (EIE) is introduced for multi-objective evolutionary algorithms (MOEAs). EIE features adaptive and fine-grained searches over $m$ subproblems defined by the extreme weighted sum method. EIE finally outputs $m$ solutions that can well approximate the ideal objective vector. In the experiments, EIE is integrated into three representative MOEAs. To demonstrate the wide applicability of EIE, algorithms are tested not only on the newly proposed test instances but also on existing ones. The results consistently show that EIE improves the ideal objective vector estimation and enhances the MOEA's performance.
Boundary-Guided Trajectory Prediction for Road Aware and Physically Feasible Autonomous Driving
May 10, 2025



Accurate prediction of surrounding road users' trajectories is essential for safe and efficient autonomous driving. While deep learning models have improved performance, challenges remain in preventing off-road predictions and ensuring kinematic feasibility. Existing methods incorporate road-awareness modules and enforce kinematic constraints but lack plausibility guarantees and often introduce trade-offs in complexity and flexibility. This paper proposes a novel framework that formulates trajectory prediction as a constrained regression guided by permissible driving directions and their boundaries. Using the agent's current state and an HD map, our approach defines the valid boundaries and ensures on-road predictions by training the network to learn superimposed paths between left and right boundary polylines. To guarantee feasibility, the model predicts acceleration profiles that determine the vehicle's travel distance along these paths while adhering to kinematic constraints. We evaluate our approach on the Argoverse-2 dataset against the HPTR baseline. Our approach shows a slight decrease in benchmark metrics compared to HPTR but notably improves final displacement error and eliminates infeasible trajectories. Moreover, the proposed approach has superior generalization to less prevalent maneuvers and unseen out-of-distribution scenarios, reducing the off-road rate under adversarial attacks from 66\% to just 1\%. These results highlight the effectiveness of our approach in generating feasible and robust predictions.
TPK: Trustworthy Trajectory Prediction Integrating Prior Knowledge For Interpretability and Kinematic Feasibility
May 10, 2025



Trajectory prediction is crucial for autonomous driving, enabling vehicles to navigate safely by anticipating the movements of surrounding road users. However, current deep learning models often lack trustworthiness as their predictions can be physically infeasible and illogical to humans. To make predictions more trustworthy, recent research has incorporated prior knowledge, like the social force model for modeling interactions and kinematic models for physical realism. However, these approaches focus on priors that suit either vehicles or pedestrians and do not generalize to traffic with mixed agent classes. We propose incorporating interaction and kinematic priors of all agent classes--vehicles, pedestrians, and cyclists with class-specific interaction layers to capture agent behavioral differences. To improve the interpretability of the agent interactions, we introduce DG-SFM, a rule-based interaction importance score that guides the interaction layer. To ensure physically feasible predictions, we proposed suitable kinematic models for all agent classes with a novel pedestrian kinematic model. We benchmark our approach on the Argoverse 2 dataset, using the state-of-the-art transformer HPTR as our baseline. Experiments demonstrate that our method improves interaction interpretability, revealing a correlation between incorrect predictions and divergence from our interaction prior. Even though incorporating the kinematic models causes a slight decrease in accuracy, they eliminate infeasible trajectories found in the dataset and the baseline model. Thus, our approach fosters trust in trajectory prediction as its interaction reasoning is interpretable, and its predictions adhere to physics.
DataMosaic: Explainable and Verifiable Multi-Modal Data Analytics through Extract-Reason-Verify
Apr 14, 2025



Large Language Models (LLMs) are transforming data analytics, but their widespread adoption is hindered by two critical limitations: they are not explainable (opaque reasoning processes) and not verifiable (prone to hallucinations and unchecked errors). While retrieval-augmented generation (RAG) improves accuracy by grounding LLMs in external data, it fails to address the core challenges of trustworthy analytics - especially when processing noisy, inconsistent, or multi-modal data (for example, text, tables, images). We propose DataMosaic, a framework designed to make LLM-powered analytics both explainable and verifiable. By dynamically extracting task-specific structures (for example, tables, graphs, trees) from raw data, DataMosaic provides transparent, step-by-step reasoning traces and enables validation of intermediate results. Built on a multi-agent framework, DataMosaic orchestrates self-adaptive agents that align with downstream task requirements, enhancing consistency, completeness, and privacy. Through this approach, DataMosaic not only tackles the limitations of current LLM-powered analytics systems but also lays the groundwork for a new paradigm of grounded, accurate, and explainable multi-modal data analytics.
Fine-Grained Retrieval-Augmented Generation for Visual Question Answering
Feb 28, 2025



Visual Question Answering (VQA) focuses on providing answers to natural language questions by utilizing information from images. Although cutting-edge multimodal large language models (MLLMs) such as GPT-4o achieve strong performance on VQA tasks, they frequently fall short in accessing domain-specific or the latest knowledge. To mitigate this issue, retrieval-augmented generation (RAG) leveraging external knowledge bases (KBs), referred to as KB-VQA, emerges as a promising approach. Nevertheless, conventional unimodal retrieval techniques, which translate images into textual descriptions, often result in the loss of critical visual details. This study presents fine-grained knowledge units, which merge textual snippets with entity images stored in vector databases. Furthermore, we introduce a knowledge unit retrieval-augmented generation framework (KU-RAG) that integrates fine-grained retrieval with MLLMs. The proposed KU-RAG framework ensures precise retrieval of relevant knowledge and enhances reasoning capabilities through a knowledge correction chain. Experimental findings demonstrate that our approach significantly boosts the performance of leading KB-VQA methods, achieving improvements of up to 10%.
Visual-RAG: Benchmarking Text-to-Image Retrieval Augmented Generation for Visual Knowledge Intensive Queries
Feb 23, 2025



Retrieval-Augmented Generation (RAG) is a popular approach for enhancing Large Language Models (LLMs) by addressing their limitations in verifying facts and answering knowledge-intensive questions. As the research in LLM extends their capability to handle input modality other than text, e.g. image, several multimodal RAG benchmarks are proposed. Nonetheless, they mainly use textual knowledge bases as the primary source of evidences for augmentation. There still lack benchmarks designed to evaluate images as augmentation in RAG systems and how they leverage visual knowledge. We propose Visual-RAG, a novel Question Answering benchmark that emphasizes visual knowledge intensive questions. Unlike prior works relying on text-based evidence, Visual-RAG necessitates text-to-image retrieval and integration of relevant clue images to extract visual knowledge as evidence. With Visual-RAG, we evaluate 5 open-sourced and 3 proprietary Multimodal LLMs (MLLMs), revealing that images can serve as good evidence in RAG; however, even the SoTA models struggle with effectively extracting and utilizing visual knowledge
Decomposing Label Space, Format and Discrimination: Rethinking How LLMs Respond and Solve Tasks via In-Context Learning
Apr 11, 2024



In-context Learning (ICL) has emerged as a powerful capability alongside the development of scaled-up large language models (LLMs). By instructing LLMs using few-shot demonstrative examples, ICL enables them to perform a wide range of tasks without updating millions of parameters. However, the precise contributions of demonstrations towards improving end-task performance have not been thoroughly investigated in recent analytical studies. In this paper, we empirically decompose the overall performance of ICL into three dimensions, label space, format, and discrimination, and we evaluate four general-purpose LLMs across a diverse range of tasks. Counter-intuitively, we find that the demonstrations have a marginal impact on provoking discriminative knowledge of language models. However, ICL exhibits significant efficacy in regulating the label space and format which helps LLMs to respond in desired label words. We then demonstrate this ability functions similar to detailed instructions for LLMs to follow. We additionally provide an in-depth analysis of the mechanism of retrieval helping with ICL and find that retrieving the most semantically similar examples notably boosts model's discriminative capability.