 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Uncertainty Estimates from Mixtures of Experts for Semantic Segmentation
Sep 05, 2025



Estimating accurate and well-calibrated predictive uncertainty is important for enhancing the reliability of computer vision models, especially in safety-critical applications like traffic scene perception. While ensemble methods are commonly used to quantify uncertainty by combining multiple models, a mixture of experts (MoE) offers an efficient alternative by leveraging a gating network to dynamically weight expert predictions based on the input. Building on the promising use of MoEs for semantic segmentation in our previous works, we show that well-calibrated predictive uncertainty estimates can be extracted from MoEs without architectural modifications. We investigate three methods to extract predictive uncertainty estimates: predictive entropy, mutual information, and expert variance. We evaluate these methods for an MoE with two experts trained on a semantical split of the A2D2 dataset. Our results show that MoEs yield more reliable uncertainty estimates than ensembles in terms of conditional correctness metrics under out-of-distribution (OOD) data. Additionally, we evaluate routing uncertainty computed via gate entropy and find that simple gating mechanisms lead to better calibration of routing uncertainty estimates than more complex classwise gates. Finally, our experiments on the Cityscapes dataset suggest that increasing the number of experts can further enhance uncertainty calibration. Our code is available at https://github.com/KASTEL-MobilityLab/mixtures-of-experts/.
TPK: Trustworthy Trajectory Prediction Integrating Prior Knowledge For Interpretability and Kinematic Feasibility
May 10, 2025



Trajectory prediction is crucial for autonomous driving, enabling vehicles to navigate safely by anticipating the movements of surrounding road users. However, current deep learning models often lack trustworthiness as their predictions can be physically infeasible and illogical to humans. To make predictions more trustworthy, recent research has incorporated prior knowledge, like the social force model for modeling interactions and kinematic models for physical realism. However, these approaches focus on priors that suit either vehicles or pedestrians and do not generalize to traffic with mixed agent classes. We propose incorporating interaction and kinematic priors of all agent classes--vehicles, pedestrians, and cyclists with class-specific interaction layers to capture agent behavioral differences. To improve the interpretability of the agent interactions, we introduce DG-SFM, a rule-based interaction importance score that guides the interaction layer. To ensure physically feasible predictions, we proposed suitable kinematic models for all agent classes with a novel pedestrian kinematic model. We benchmark our approach on the Argoverse 2 dataset, using the state-of-the-art transformer HPTR as our baseline. Experiments demonstrate that our method improves interaction interpretability, revealing a correlation between incorrect predictions and divergence from our interaction prior. Even though incorporating the kinematic models causes a slight decrease in accuracy, they eliminate infeasible trajectories found in the dataset and the baseline model. Thus, our approach fosters trust in trajectory prediction as its interaction reasoning is interpretable, and its predictions adhere to physics.
Boundary-Guided Trajectory Prediction for Road Aware and Physically Feasible Autonomous Driving
May 10, 2025



Accurate prediction of surrounding road users' trajectories is essential for safe and efficient autonomous driving. While deep learning models have improved performance, challenges remain in preventing off-road predictions and ensuring kinematic feasibility. Existing methods incorporate road-awareness modules and enforce kinematic constraints but lack plausibility guarantees and often introduce trade-offs in complexity and flexibility. This paper proposes a novel framework that formulates trajectory prediction as a constrained regression guided by permissible driving directions and their boundaries. Using the agent's current state and an HD map, our approach defines the valid boundaries and ensures on-road predictions by training the network to learn superimposed paths between left and right boundary polylines. To guarantee feasibility, the model predicts acceleration profiles that determine the vehicle's travel distance along these paths while adhering to kinematic constraints. We evaluate our approach on the Argoverse-2 dataset against the HPTR baseline. Our approach shows a slight decrease in benchmark metrics compared to HPTR but notably improves final displacement error and eliminates infeasible trajectories. Moreover, the proposed approach has superior generalization to less prevalent maneuvers and unseen out-of-distribution scenarios, reducing the off-road rate under adversarial attacks from 66\% to just 1\%. These results highlight the effectiveness of our approach in generating feasible and robust predictions.
CoCar NextGen: a Multi-Purpose Platform for Connected Autonomous Driving Research
Apr 26, 2024



Real world testing is of vital importance to the success of automated driving. While many players in the business design purpose build testing vehicles, we designed and build a modular platform that offers high flexibility for any kind of scenario. CoCar NextGen is equipped with next generation hardware that addresses all future use cases. Its extensive, redundant sensor setup allows to develop cross-domain data driven approaches that manage the transfer to other sensor setups. Together with the possibility of being deployed on public roads, this creates a unique research platform that supports the road to automated driving on SAE Level 5.
Balancing Expert Utilization in Mixture-of-Experts Layers Embedded in CNNs
Apr 22, 2022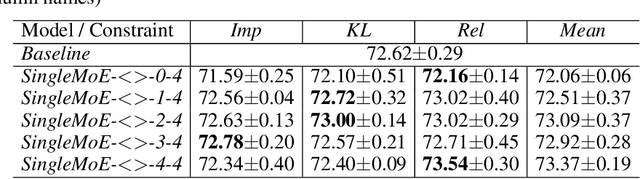
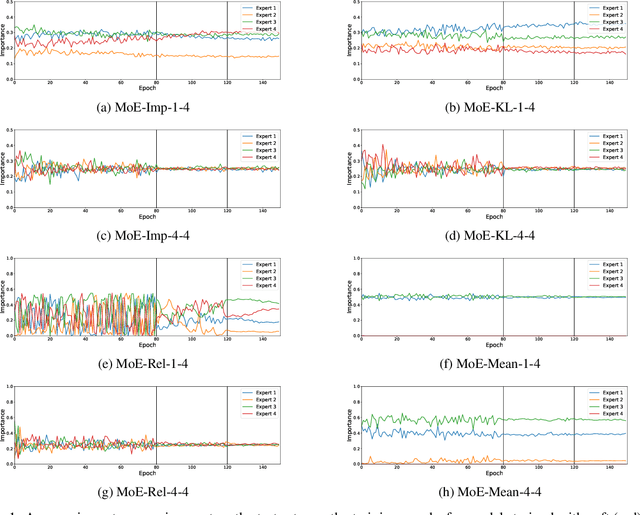
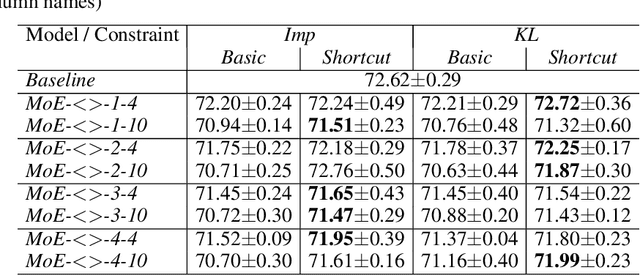

This work addresses the problem of unbalanced expert utilization in sparsely-gated Mixture of Expert (MoE) layers, embedded directly into convolutional neural networks. To enable a stable training process, we present both soft and hard constraint-based approaches. With hard constraints, the weights of certain experts are allowed to become zero, while soft constraints balance the contribution of experts with an additional auxiliary loss. As a result, soft constraints handle expert utilization better and support the expert specialization process, hard constraints mostly maintain generalized experts and increase the model performance for many applications. Our findings demonstrate that even with a single dataset and end-to-end training, experts can implicitly focus on individual sub-domains of the input space. Experts in the proposed models with MoE embeddings implicitly focus on distinct domains, even without suitable predefined datasets. As an example, experts trained for CIFAR-100 image classification specialize in recognizing different domains such as sea animals or flowers without previous data clustering. Experiments with RetinaNet and the COCO dataset further indicate that object detection experts can also specialize in detecting objects of distinct sizes.