 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecompose and Realign: Tackling Condition Misalignment in Text-to-Image Diffusion Models
Jun 26, 2023Text-to-image diffusion models have advanced towards more controllable generation via supporting various image conditions (e.g., depth map) beyond text. However, these models are learned based on the premise of perfect alignment between the text and image conditions. If this alignment is not satisfied, the final output could be either dominated by one condition, or ambiguity may arise, failing to meet user expectations. To address this issue, we present a training-free approach called "Decompose and Realign'' to further improve the controllability of existing models when provided with partially aligned conditions. The ``Decompose'' phase separates conditions based on pair relationships, computing scores individually for each pair. This ensures that each pair no longer has conflicting conditions. The "Realign'' phase aligns these independently calculated scores via a cross-attention mechanism to avoid new conflicts when combing them back. Both qualitative and quantitative results demonstrate the effectiveness of our approach in handling unaligned conditions, which performs favorably against recent methods and more importantly adds flexibility to the controllable image generation process.
Probabilistic Learning of Multivariate Time Series with Temporal Irregularity
Jun 16, 2023



Multivariate sequential data collected in practice often exhibit temporal irregularities, including nonuniform time intervals and component misalignment. However, if uneven spacing and asynchrony are endogenous characteristics of the data rather than a result of insufficient observation, the information content of these irregularities plays a defining role in characterizing the multivariate dependence structure. Existing approaches for probabilistic forecasting either overlook the resulting statistical heterogeneities, are susceptible to imputation biases, or impose parametric assumptions on the data distribution. This paper proposes an end-to-end solution that overcomes these limitations by allowing the observation arrival times to play the central role of model construction, which is at the core of temporal irregularities. To acknowledge temporal irregularities, we first enable unique hidden states for components so that the arrival times can dictate when, how, and which hidden states to update. We then develop a conditional flow representation to non-parametrically represent the data distribution, which is typically non-Gaussian, and supervise this representation by carefully factorizing the log-likelihood objective to select conditional information that facilitates capturing time variation and path dependency. The broad applicability and superiority of the proposed solution are confirmed by comparing it with existing approaches through ablation studies and testing on real-world datasets.
Neural Partial Differential Equations with Functional Convolution
Mar 10, 2023We present a lightweighted neural PDE representation to discover the hidden structure and predict the solution of different nonlinear PDEs. Our key idea is to leverage the prior of ``translational similarity'' of numerical PDE differential operators to drastically reduce the scale of learning model and training data. We implemented three central network components, including a neural functional convolution operator, a Picard forward iterative procedure, and an adjoint backward gradient calculator. Our novel paradigm fully leverages the multifaceted priors that stem from the sparse and smooth nature of the physical PDE solution manifold and the various mature numerical techniques such as adjoint solver, linearization, and iterative procedure to accelerate the computation. We demonstrate the efficacy of our method by robustly discovering the model and accurately predicting the solutions of various types of PDEs with small-scale networks and training sets. We highlight that all the PDE examples we showed were trained with up to 8 data samples and within 325 network parameters.
Zero-shot Image-to-Image Translation
Feb 06, 2023



Large-scale text-to-image generative models have shown their remarkable ability to synthesize diverse and high-quality images. However, it is still challenging to directly apply these models for editing real images for two reasons. First, it is hard for users to come up with a perfect text prompt that accurately describes every visual detail in the input image. Second, while existing models can introduce desirable changes in certain regions, they often dramatically alter the input content and introduce unexpected changes in unwanted regions. In this work, we propose pix2pix-zero, an image-to-image translation method that can preserve the content of the original image without manual prompting. We first automatically discover editing directions that reflect desired edits in the text embedding space. To preserve the general content structure after editing, we further propose cross-attention guidance, which aims to retain the cross-attention maps of the input image throughout the diffusion process. In addition, our method does not need additional training for these edits and can directly use the existing pre-trained text-to-image diffusion model. We conduct extensive experiments and show that our method outperforms existing and concurrent works for both real and synthetic image editing.
Contrastive Learning for Diverse Disentangled Foreground Generation
Nov 04, 2022We introduce a new method for diverse foreground generation with explicit control over various factors. Existing image inpainting based foreground generation methods often struggle to generate diverse results and rarely allow users to explicitly control specific factors of variation (e.g., varying the facial identity or expression for face inpainting results). We leverage contrastive learning with latent codes to generate diverse foreground results for the same masked input. Specifically, we define two sets of latent codes, where one controls a pre-defined factor (``known''), and the other controls the remaining factors (``unknown''). The sampled latent codes from the two sets jointly bi-modulate the convolution kernels to guide the generator to synthesize diverse results. Experiments demonstrate the superiority of our method over state-of-the-arts in result diversity and generation controllability.
3D-FM GAN: Towards 3D-Controllable Face Manipulation
Aug 24, 2022
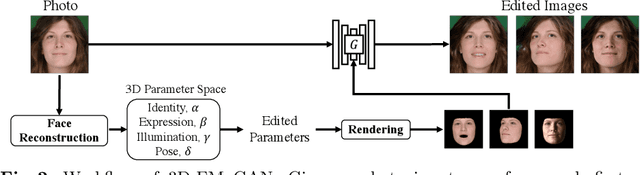

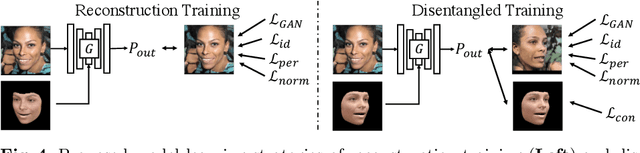
3D-controllable portrait synthesis has significantly advanced, thanks to breakthroughs in generative adversarial networks (GANs). However, it is still challenging to manipulate existing face images with precise 3D control. While concatenating GAN inversion and a 3D-aware, noise-to-image GAN is a straight-forward solution, it is inefficient and may lead to noticeable drop in editing quality. To fill this gap, we propose 3D-FM GAN, a novel conditional GAN framework designed specifically for 3D-controllable face manipulation, and does not require any tuning after the end-to-end learning phase. By carefully encoding both the input face image and a physically-based rendering of 3D edits into a StyleGAN's latent spaces, our image generator provides high-quality, identity-preserved, 3D-controllable face manipulation. To effectively learn such novel framework, we develop two essential training strategies and a novel multiplicative co-modulation architecture that improves significantly upon naive schemes. With extensive evaluations, we show that our method outperforms the prior arts on various tasks, with better editability, stronger identity preservation, and higher photo-realism. In addition, we demonstrate a better generalizability of our design on large pose editing and out-of-domain images.
Spatially-Adaptive Multilayer Selection for GAN Inversion and Editing
Jun 16, 2022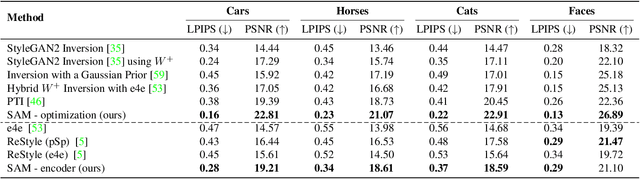
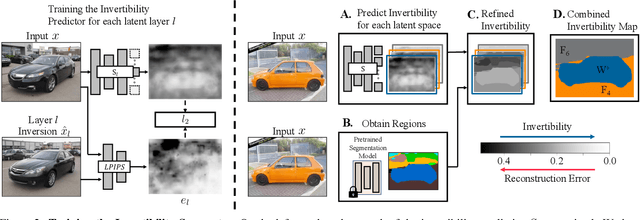
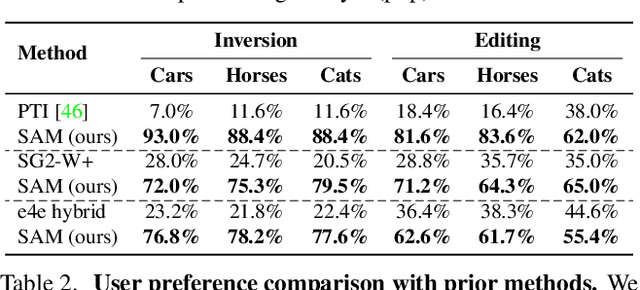

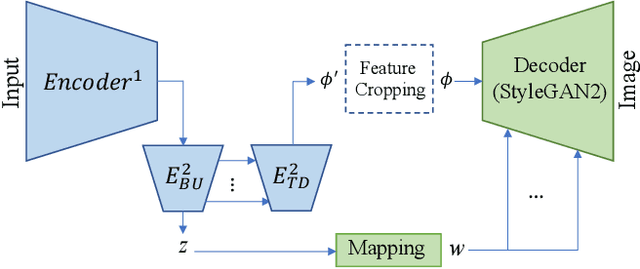
Existing GAN inversion and editing methods work well for aligned objects with a clean background, such as portraits and animal faces, but often struggle for more difficult categories with complex scene layouts and object occlusions, such as cars, animals, and outdoor images. We propose a new method to invert and edit such complex images in the latent space of GANs, such as StyleGAN2. Our key idea is to explore inversion with a collection of layers, spatially adapting the inversion process to the difficulty of the image. We learn to predict the "invertibility" of different image segments and project each segment into a latent layer. Easier regions can be inverted into an earlier layer in the generator's latent space, while more challenging regions can be inverted into a later feature space. Experiments show that our method obtains better inversion results compared to the recent approaches on complex categories, while maintaining downstream editability. Please refer to our project page at https://www.cs.cmu.edu/~SAMInversion.
Emerging Artificial Intelligence Applications in Spatial Transcriptomics Analysis
Mar 18, 2022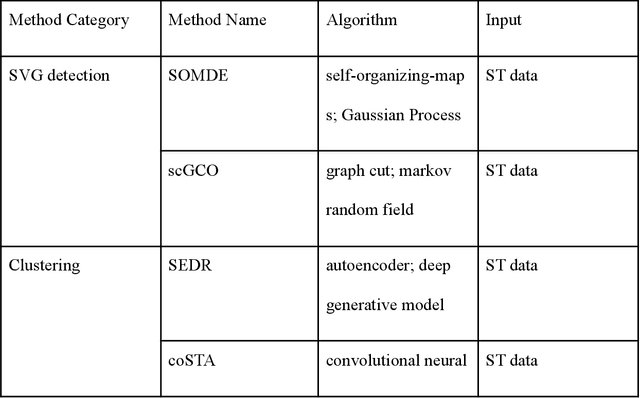
Spatial transcriptomics (ST) has advanced significantly in the last few years. Such advancement comes with the urgent need for novel computational methods to handle the unique challenges of ST data analysis. Many artificial intelligence (AI) methods have been developed to utilize various machine learning and deep learning techniques for computational ST analysis. This review provides a comprehensive and up-to-date survey of current AI methods for ST analysis.
Collaging Class-specific GANs for Semantic Image Synthesis
Oct 08, 2021
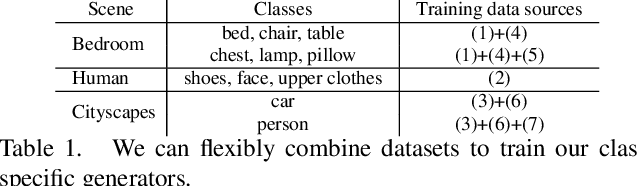
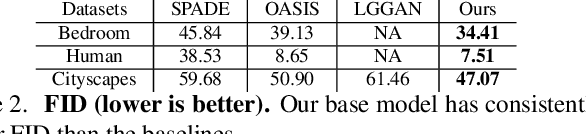
We propose a new approach for high resolution semantic image synthesis. It consists of one base image generator and multiple class-specific generators. The base generator generates high quality images based on a segmentation map. To further improve the quality of different objects, we create a bank of Generative Adversarial Networks (GANs) by separately training class-specific models. This has several benefits including -- dedicated weights for each class; centrally aligned data for each model; additional training data from other sources, potential of higher resolution and quality; and easy manipulation of a specific object in the scene. Experiments show that our approach can generate high quality images in high resolution while having flexibility of object-level control by using class-specific generators.
Few-shot Image Generation via Cross-domain Correspondence
Apr 13, 2021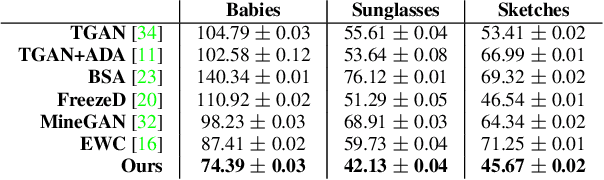

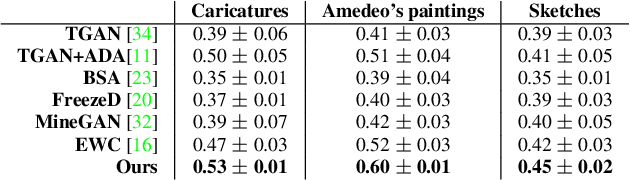
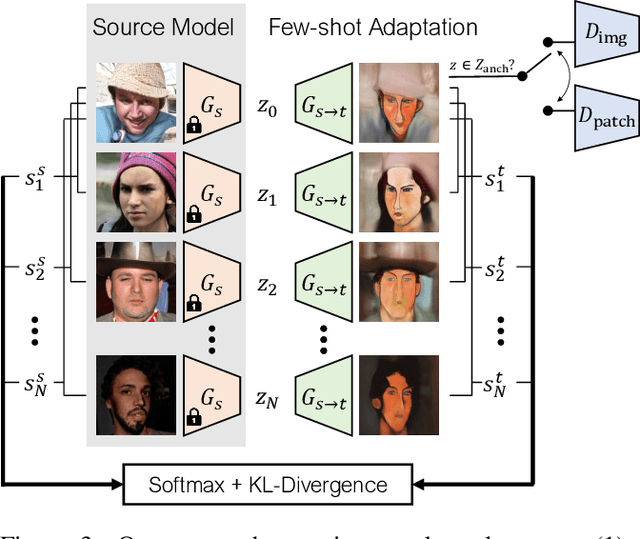
Training generative models, such as GANs, on a target domain containing limited examples (e.g., 10) can easily result in overfitting. In this work, we seek to utilize a large source domain for pretraining and transfer the diversity information from source to target. We propose to preserve the relative similarities and differences between instances in the source via a novel cross-domain distance consistency loss. To further reduce overfitting, we present an anchor-based strategy to encourage different levels of realism over different regions in the latent space. With extensive results in both photorealistic and non-photorealistic domains, we demonstrate qualitatively and quantitatively that our few-shot model automatically discovers correspondences between source and target domains and generates more diverse and realistic images than previous methods.