 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Extraction to Navigation: Progressive Retrieval with Indirectly Infinite Depth
Jun 29, 2026Modern large-scale recommender retrieval is shifting from static similarity matching to dynamic item space navigation, framing retrieval as iterative goal-driven graph traversal. Conventional item-to-item (i2i) methods fall into the "interest tunnel" and fail to excavate deep user interests, while existing index-based retrieval suffers from persistent "search drift", caused by static entry nodes and fixed graph topologies unable to track shifting real-time user intent. To resolve the above defects, we present IID-Nav, a framework modeling retrieval as stateful autonomous graph exploration with three core contributions: (1) A goal-aware navigation policy substituting passive neighborhood expansion with active intent routing supervised by a target discriminator; (2) A recursive state evolution mechanism supporting Indirectly Infinite Depth (IID) via cross-request state reuse, which enables logical unlimited-depth graph traversal without linearly rising inference latency; (3) A trajectory-aligned training paradigm equipped with graph hard negative sampling to stabilize optimization over full navigation paths. Evaluations on billion-level industrial datasets show IID-Nav surpasses mainstream retrieval baselines under strict latency budgets. Empirical results verify that our method alleviates search drift remarkably and retains high precision for deep retrieval paths, offering an efficient, robust retrieval solution for industrial recommendation systems.
POEM: Partial-Order Enhanced Real-Time Sequential Modeling for Recommendation
Jun 29, 2026Real-time recommendation systems suffer from the dynamic drift of user interests and varying contextual conditions. Conventional sequential recommendation models only exploit static historical click sequences, which fail to capture instant preference changes and overlook structured signals hidden within the multi-stage ranking pipeline of industrial recommendation systems. To tackle these limitations, we propose POEM (Partial-Order Enhanced Modeling), a new real-time sequential modeling framework built upon intrinsic partial-order relations from the recommendation cascade. POEM takes real-time multi-task ranking scores (including predicted CTR and predicted watch duration) generated by upstream ranking modules as supervision to construct dynamic partial-order sequences, supporting fine-grained real-time interest modeling and consistent optimization between system ranking targets and user behavioral patterns. We summarize our core contributions as three aspects: (1) a partial-order guided sequence construction paradigm, which enriches vanilla chronological sequences via dynamic grouping and sampling conditioned on real-time ranking scores to reassess user interests per request; (2) a multi-objective score fusion module that unifies heterogeneous ranking signals into a compact quintuple representation with normalized rank-aware weighting; (3) a hierarchical sample learning strategy, which adopts system-favored high-ranked items and user positive feedback (e.g., long-duration watched videos) as positive instances, paired with graph-mined hard negatives and a margin-based pairwise loss for robust training. Fully deployed on Kuaishou online traffic, POEM achieves significant online gains: average per-user watch time lifts by 0.249% on the KS Single Page and 0.213% on the KS Lite Page.
Checkup2Action: A Multimodal Clinical Check-up Report Dataset for Patient-Oriented Action Card Generation
May 13, 2026Clinical check-up reports are multimodal documents that combine page layouts, tables, numerical biomarkers, abnormality flags, imaging findings, and domain-specific terminology. Such heterogeneous evidence is difficult for laypersons to interpret and translate into concrete follow-up actions. Although large language models show promise in medical summarisation and triage support, their ability to generate safe, prioritised, and patient-oriented actions from multimodal check-up reports remains under-benchmarked. We present \textbf{Checkup2Action}, a multimodal clinical check-up report dataset and benchmark for structured \textit{Action Card} generation. Each card describes one clinically relevant issue and specifies its priority, recommended department, follow-up time window, patient-facing explanation, and questions for clinicians, while avoiding diagnostic or treatment-prescriptive claims. The dataset contains 2,000 de-identified real-world check-up reports covering demographic information, physical examinations, laboratory tests, cardiovascular assessments, and imaging-related evidence. We formulate checkup-to-action generation as a constrained structured generation task and introduce an evaluation protocol covering issue coverage and precision, priority consistency, department and time recommendation accuracy, action complexity, usefulness, readability, and safety compliance. Experiments with general-purpose and medical large language models reveal clear trade-offs between issue coverage, action correctness, conciseness, and safety alignment. Checkup2Action provides a new multimodal benchmark for evaluating patient-oriented reasoning over clinical check-up reports.
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
Graphical Models for Financial Time Series and Portfolio Selection
Jan 22, 2021
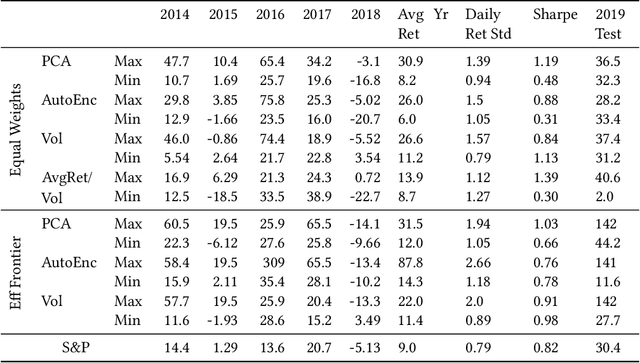
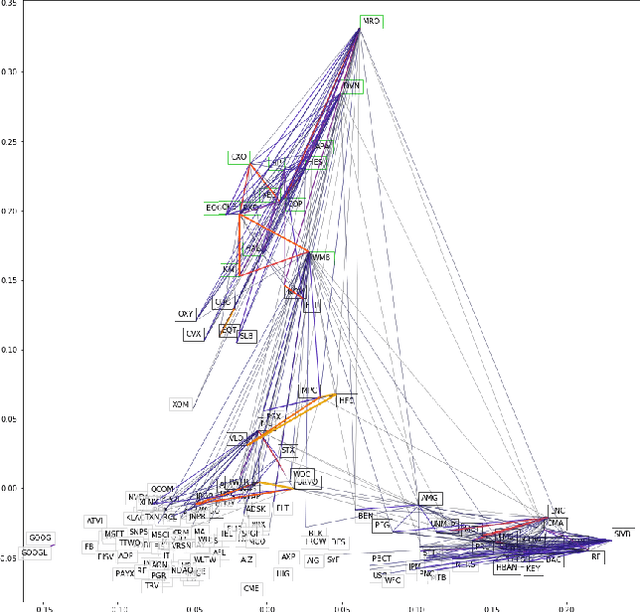
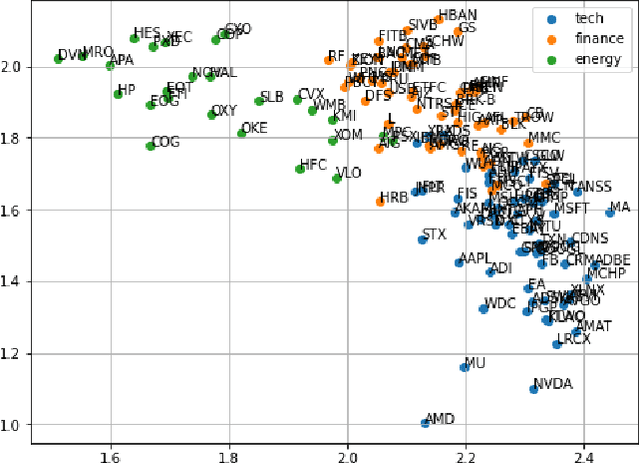
We examine a variety of graphical models to construct optimal portfolios. Graphical models such as PCA-KMeans, autoencoders, dynamic clustering, and structural learning can capture the time varying patterns in the covariance matrix and allow the creation of an optimal and robust portfolio. We compared the resulting portfolios from the different models with baseline methods. In many cases our graphical strategies generated steadily increasing returns with low risk and outgrew the S&P 500 index. This work suggests that graphical models can effectively learn the temporal dependencies in time series data and are proved useful in asset management.