 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge360-MLC: Multi-view Layout Consistency for Self-training and Hyper-parameter Tuning
Oct 24, 2022We present 360-MLC, a self-training method based on multi-view layout consistency for finetuning monocular room-layout models using unlabeled 360-images only. This can be valuable in practical scenarios where a pre-trained model needs to be adapted to a new data domain without using any ground truth annotations. Our simple yet effective assumption is that multiple layout estimations in the same scene must define a consistent geometry regardless of their camera positions. Based on this idea, we leverage a pre-trained model to project estimated layout boundaries from several camera views into the 3D world coordinate. Then, we re-project them back to the spherical coordinate and build a probability function, from which we sample the pseudo-labels for self-training. To handle unconfident pseudo-labels, we evaluate the variance in the re-projected boundaries as an uncertainty value to weight each pseudo-label in our loss function during training. In addition, since ground truth annotations are not available during training nor in testing, we leverage the entropy information in multiple layout estimations as a quantitative metric to measure the geometry consistency of the scene, allowing us to evaluate any layout estimator for hyper-parameter tuning, including model selection without ground truth annotations. Experimental results show that our solution achieves favorable performance against state-of-the-art methods when self-training from three publicly available source datasets to a unique, newly labeled dataset consisting of multi-view of the same scenes.
3D-PL: Domain Adaptive Depth Estimation with 3D-aware Pseudo-Labeling
Sep 19, 2022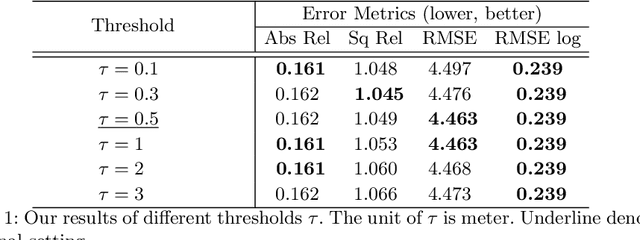

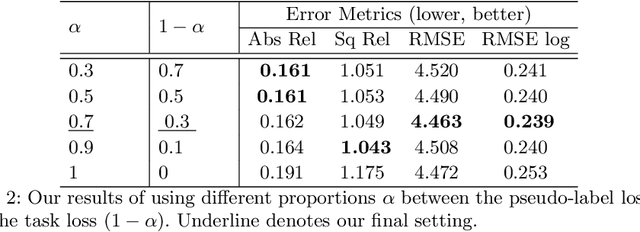

For monocular depth estimation, acquiring ground truths for real data is not easy, and thus domain adaptation methods are commonly adopted using the supervised synthetic data. However, this may still incur a large domain gap due to the lack of supervision from the real data. In this paper, we develop a domain adaptation framework via generating reliable pseudo ground truths of depth from real data to provide direct supervisions. Specifically, we propose two mechanisms for pseudo-labeling: 1) 2D-based pseudo-labels via measuring the consistency of depth predictions when images are with the same content but different styles; 2) 3D-aware pseudo-labels via a point cloud completion network that learns to complete the depth values in the 3D space, thus providing more structural information in a scene to refine and generate more reliable pseudo-labels. In experiments, we show that our pseudo-labeling methods improve depth estimation in various settings, including the usage of stereo pairs during training. Furthermore, the proposed method performs favorably against several state-of-the-art unsupervised domain adaptation approaches in real-world datasets.
BiFuse++: Self-supervised and Efficient Bi-projection Fusion for 360 Depth Estimation
Sep 07, 2022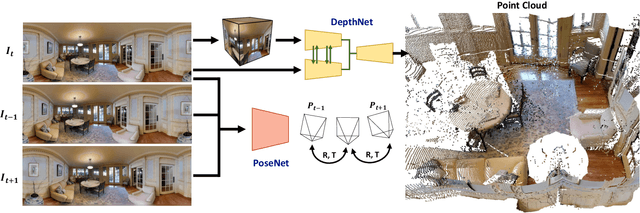
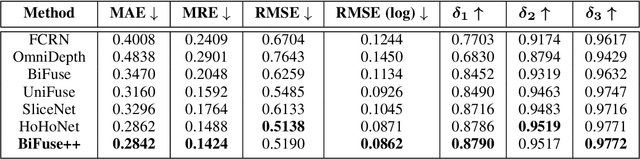

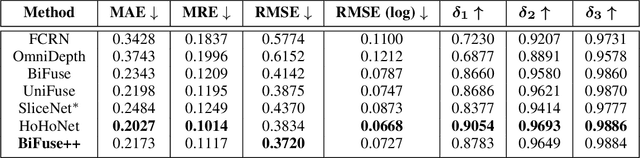
Due to the rise of spherical cameras, monocular 360 depth estimation becomes an important technique for many applications (e.g., autonomous systems). Thus, state-of-the-art frameworks for monocular 360 depth estimation such as bi-projection fusion in BiFuse are proposed. To train such a framework, a large number of panoramas along with the corresponding depth ground truths captured by laser sensors are required, which highly increases the cost of data collection. Moreover, since such a data collection procedure is time-consuming, the scalability of extending these methods to different scenes becomes a challenge. To this end, self-training a network for monocular depth estimation from 360 videos is one way to alleviate this issue. However, there are no existing frameworks that incorporate bi-projection fusion into the self-training scheme, which highly limits the self-supervised performance since bi-projection fusion can leverage information from different projection types. In this paper, we propose BiFuse++ to explore the combination of bi-projection fusion and the self-training scenario. To be specific, we propose a new fusion module and Contrast-Aware Photometric Loss to improve the performance of BiFuse and increase the stability of self-training on real-world videos. We conduct both supervised and self-supervised experiments on benchmark datasets and achieve state-of-the-art performance.
MM-TTA: Multi-Modal Test-Time Adaptation for 3D Semantic Segmentation
Apr 27, 2022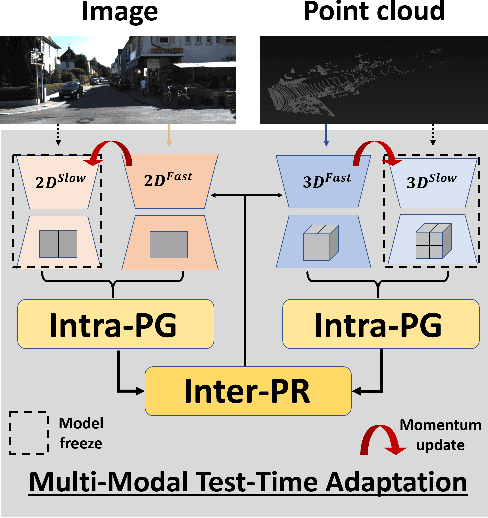
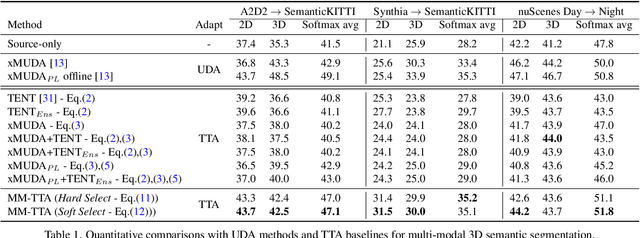
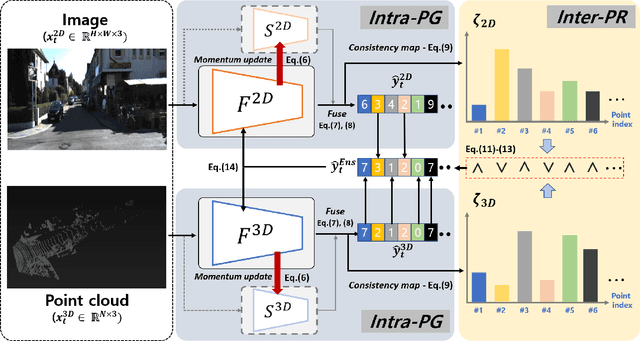
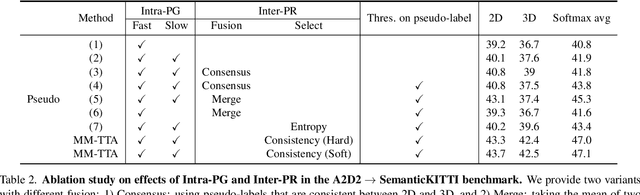
Test-time adaptation approaches have recently emerged as a practical solution for handling domain shift without access to the source domain data. In this paper, we propose and explore a new multi-modal extension of test-time adaptation for 3D semantic segmentation. We find that directly applying existing methods usually results in performance instability at test time because multi-modal input is not considered jointly. To design a framework that can take full advantage of multi-modality, where each modality provides regularized self-supervisory signals to other modalities, we propose two complementary modules within and across the modalities. First, Intra-modal Pseudolabel Generation (Intra-PG) is introduced to obtain reliable pseudo labels within each modality by aggregating information from two models that are both pre-trained on source data but updated with target data at different paces. Second, Inter-modal Pseudo-label Refinement (Inter-PR) adaptively selects more reliable pseudo labels from different modalities based on a proposed consistency scheme. Experiments demonstrate that our regularized pseudo labels produce stable self-learning signals in numerous multi-modal test-time adaptation scenarios for 3D semantic segmentation. Visit our project website at https://www.nec-labs.com/~mas/MM-TTA.
On Generalizing Beyond Domains in Cross-Domain Continual Learning
Mar 08, 2022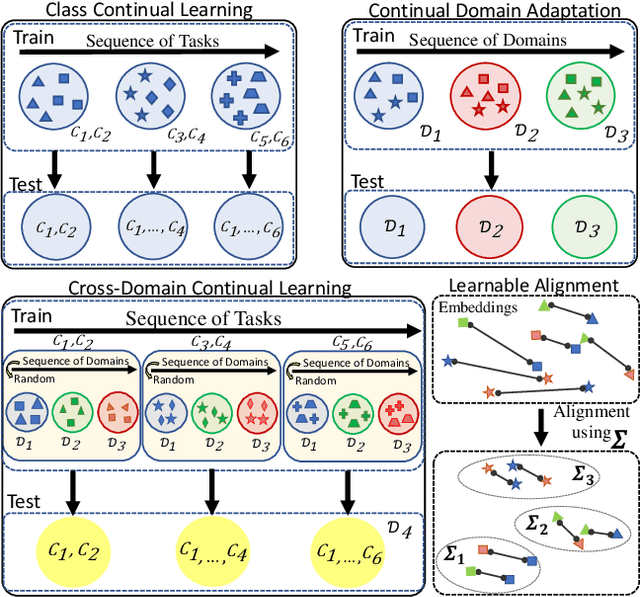
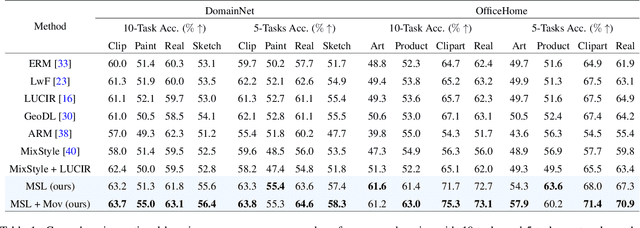
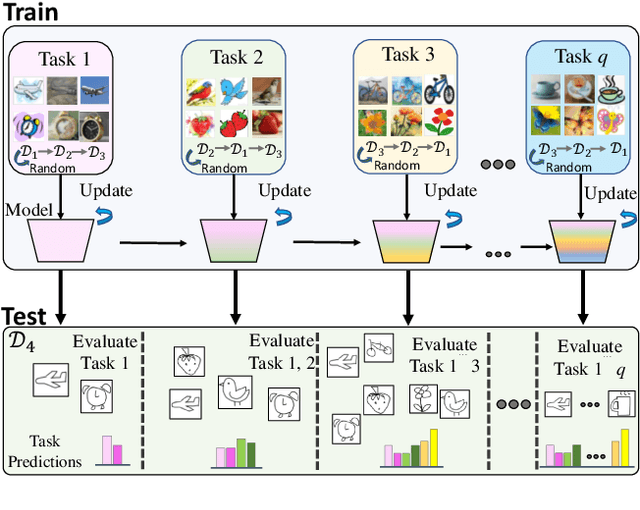
Humans have the ability to accumulate knowledge of new tasks in varying conditions, but deep neural networks often suffer from catastrophic forgetting of previously learned knowledge after learning a new task. Many recent methods focus on preventing catastrophic forgetting under the assumption of train and test data following similar distributions. In this work, we consider a more realistic scenario of continual learning under domain shifts where the model must generalize its inference to an unseen domain. To this end, we encourage learning semantically meaningful features by equipping the classifier with class similarity metrics as learning parameters which are obtained through Mahalanobis similarity computations. Learning of the backbone representation along with these extra parameters is done seamlessly in an end-to-end manner. In addition, we propose an approach based on the exponential moving average of the parameters for better knowledge distillation. We demonstrate that, to a great extent, existing continual learning algorithms fail to handle the forgetting issue under multiple distributions, while our proposed approach learns new tasks under domain shift with accuracy boosts up to 10% on challenging datasets such as DomainNet and OfficeHome.
Learning Semantic Segmentation from Multiple Datasets with Label Shifts
Feb 28, 2022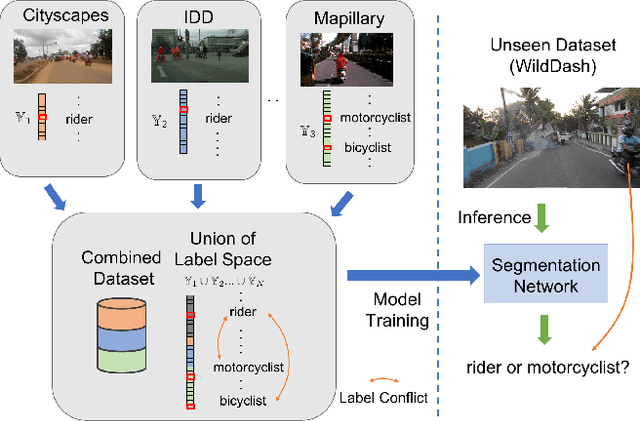
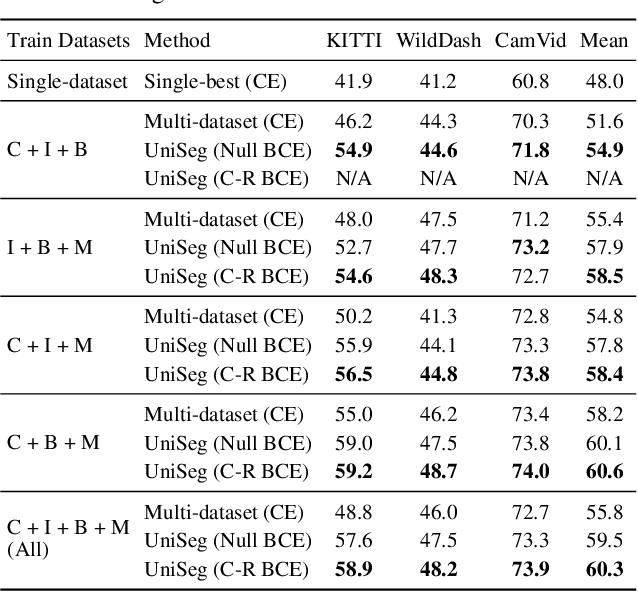
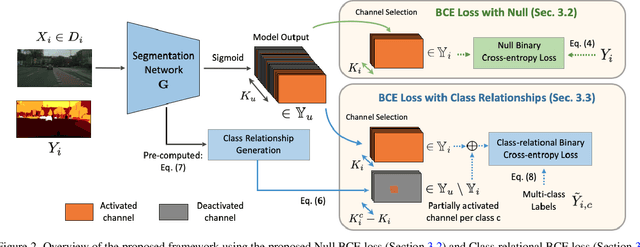
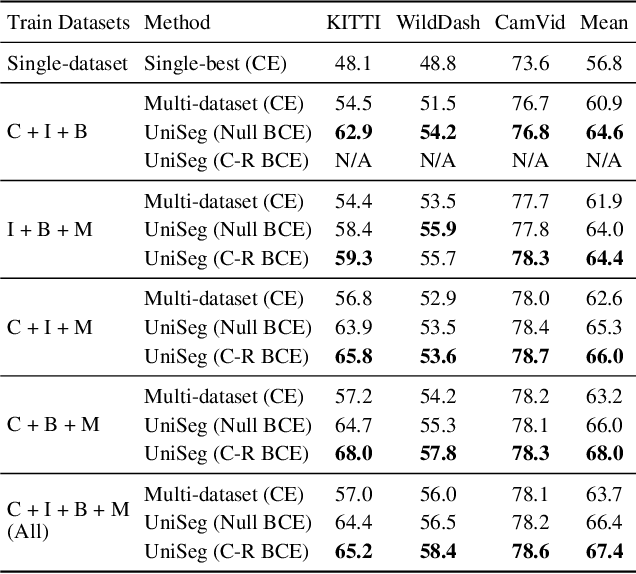
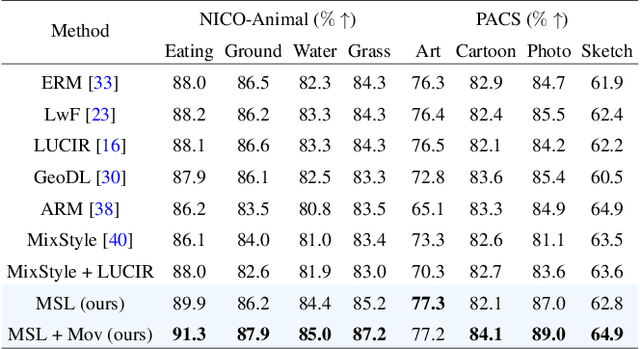
With increasing applications of semantic segmentation, numerous datasets have been proposed in the past few years. Yet labeling remains expensive, thus, it is desirable to jointly train models across aggregations of datasets to enhance data volume and diversity. However, label spaces differ across datasets and may even be in conflict with one another. This paper proposes UniSeg, an effective approach to automatically train models across multiple datasets with differing label spaces, without any manual relabeling efforts. Specifically, we propose two losses that account for conflicting and co-occurring labels to achieve better generalization performance in unseen domains. First, a gradient conflict in training due to mismatched label spaces is identified and a class-independent binary cross-entropy loss is proposed to alleviate such label conflicts. Second, a loss function that considers class-relationships across datasets is proposed for a better multi-dataset training scheme. Extensive quantitative and qualitative analyses on road-scene datasets show that UniSeg improves over multi-dataset baselines, especially on unseen datasets, e.g., achieving more than 8% gain in IoU on KITTI averaged over all the settings.
Self-Supervised Feature Learning from Partial Point Clouds via Pose Disentanglement
Jan 09, 2022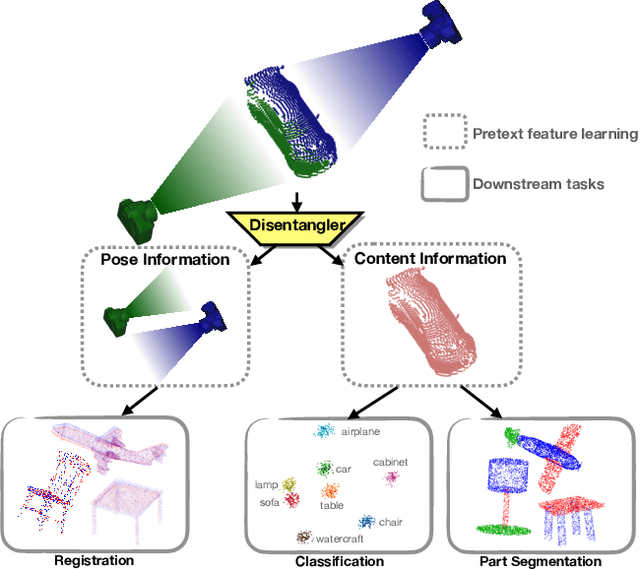
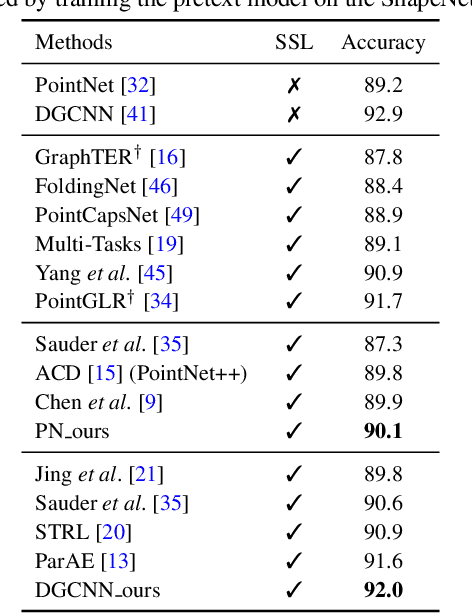
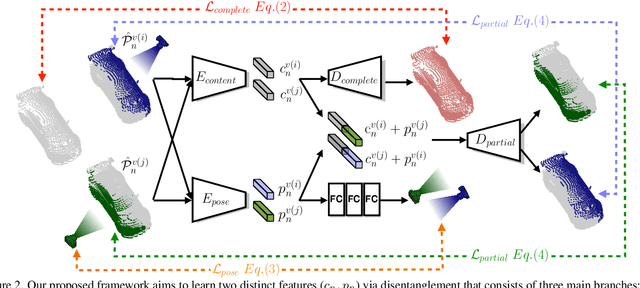
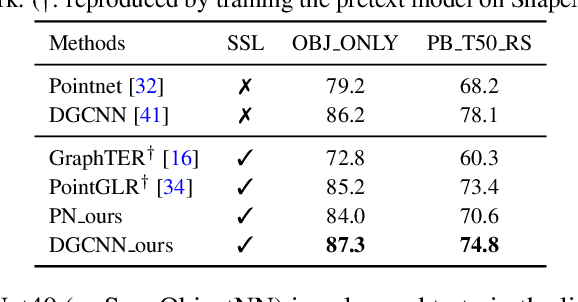
Self-supervised learning on point clouds has gained a lot of attention recently, since it addresses the label-efficiency and domain-gap problems on point cloud tasks. In this paper, we propose a novel self-supervised framework to learn informative representations from partial point clouds. We leverage partial point clouds scanned by LiDAR that contain both content and pose attributes, and we show that disentangling such two factors from partial point clouds enhances feature representation learning. To this end, our framework consists of three main parts: 1) a completion network to capture holistic semantics of point clouds; 2) a pose regression network to understand the viewing angle where partial data is scanned from; 3) a partial reconstruction network to encourage the model to learn content and pose features. To demonstrate the robustness of the learnt feature representations, we conduct several downstream tasks including classification, part segmentation, and registration, with comparisons against state-of-the-art methods. Our method not only outperforms existing self-supervised methods, but also shows a better generalizability across synthetic and real-world datasets.
360-DFPE: Leveraging Monocular 360-Layouts for Direct Floor Plan Estimation
Dec 21, 2021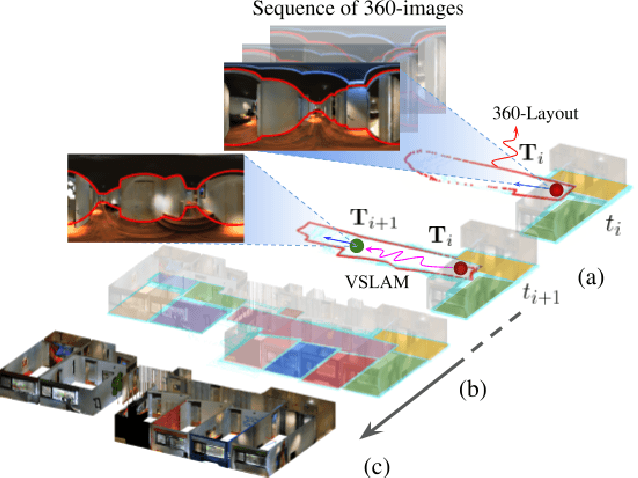
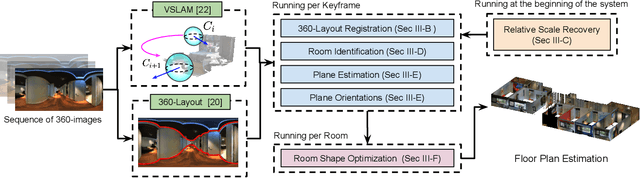
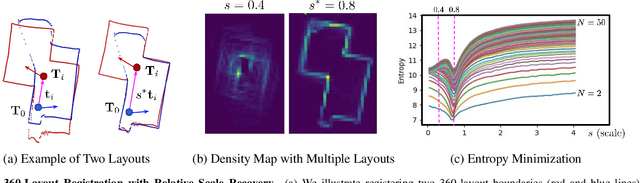
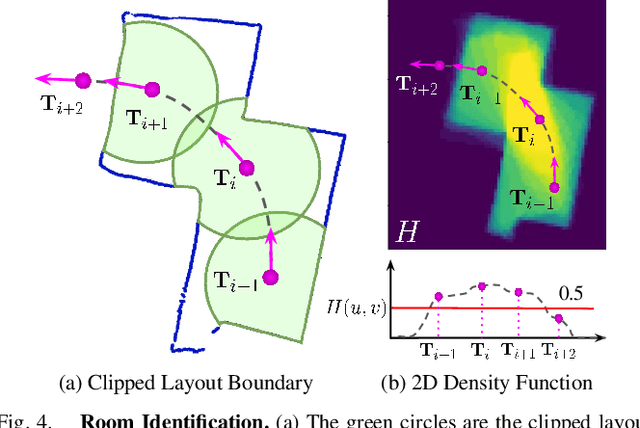
We present 360-DFPE, a sequential floor plan estimation method that directly takes 360-images as input without relying on active sensors or 3D information. Our approach leverages a loosely coupled integration between a monocular visual SLAM solution and a monocular 360-room layout approach, which estimate camera poses and layout geometries, respectively. Since our task is to sequentially capture the floor plan using monocular images, the entire scene structure, room instances, and room shapes are unknown. To tackle these challenges, we first handle the scale difference between visual odometry and layout geometry via formulating an entropy minimization process, which enables us to directly align 360-layouts without knowing the entire scene in advance. Second, to sequentially identify individual rooms, we propose a novel room identification algorithm that tracks every room along the camera exploration using geometry information. Lastly, to estimate the final shape of the room, we propose a shortest path algorithm with an iterative coarse-to-fine strategy, which improves prior formulations with higher accuracy and faster run-time. Moreover, we collect a new floor plan dataset with challenging large-scale scenes, providing both point clouds and sequential 360-image information. Experimental results show that our monocular solution achieves favorable performance against the current state-of-the-art algorithms that rely on active sensors and require the entire scene reconstruction data in advance. Our code and dataset will be released soon.
Semi-supervised Multi-task Learning for Semantics and Depth
Oct 14, 2021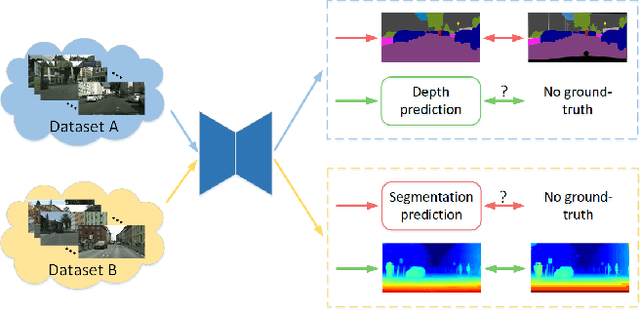
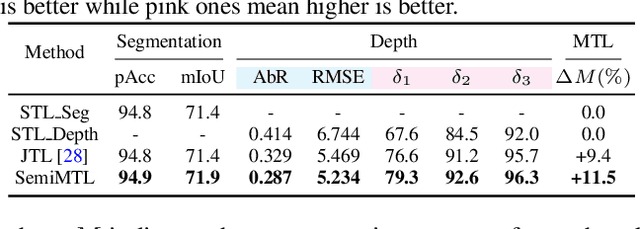
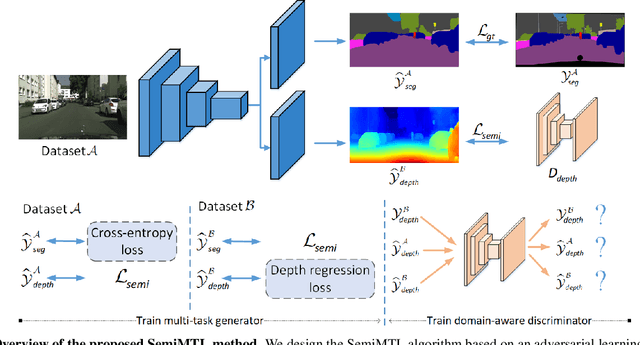
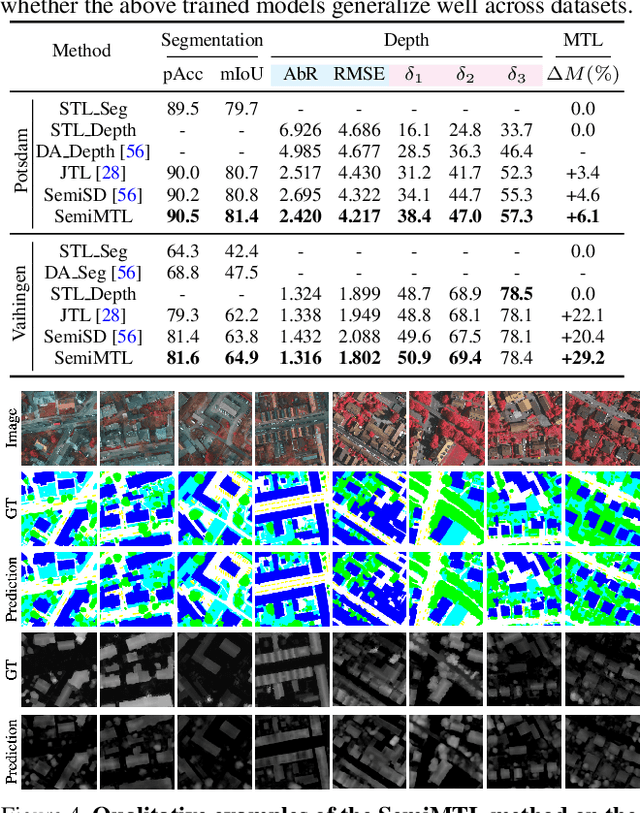
Multi-Task Learning (MTL) aims to enhance the model generalization by sharing representations between related tasks for better performance. Typical MTL methods are jointly trained with the complete multitude of ground-truths for all tasks simultaneously. However, one single dataset may not contain the annotations for each task of interest. To address this issue, we propose the Semi-supervised Multi-Task Learning (SemiMTL) method to leverage the available supervisory signals from different datasets, particularly for semantic segmentation and depth estimation tasks. To this end, we design an adversarial learning scheme in our semi-supervised training by leveraging unlabeled data to optimize all the task branches simultaneously and accomplish all tasks across datasets with partial annotations. We further present a domain-aware discriminator structure with various alignment formulations to mitigate the domain discrepancy issue among datasets. Finally, we demonstrate the effectiveness of the proposed method to learn across different datasets on challenging street view and remote sensing benchmarks.
Learning Cross-modal Contrastive Features for Video Domain Adaptation
Aug 26, 2021

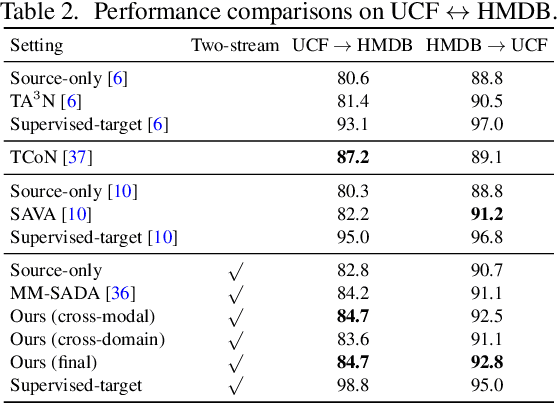
Learning transferable and domain adaptive feature representations from videos is important for video-relevant tasks such as action recognition. Existing video domain adaptation methods mainly rely on adversarial feature alignment, which has been derived from the RGB image space. However, video data is usually associated with multi-modal information, e.g., RGB and optical flow, and thus it remains a challenge to design a better method that considers the cross-modal inputs under the cross-domain adaptation setting. To this end, we propose a unified framework for video domain adaptation, which simultaneously regularizes cross-modal and cross-domain feature representations. Specifically, we treat each modality in a domain as a view and leverage the contrastive learning technique with properly designed sampling strategies. As a result, our objectives regularize feature spaces, which originally lack the connection across modalities or have less alignment across domains. We conduct experiments on domain adaptive action recognition benchmark datasets, i.e., UCF, HMDB, and EPIC-Kitchens, and demonstrate the effectiveness of our components against state-of-the-art algorithms.