 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharformer: Fast Character Transformers via Gradient-based Subword Tokenization
Jul 02, 2021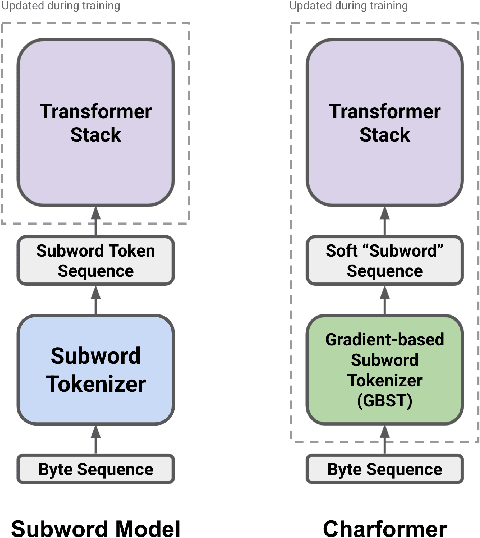
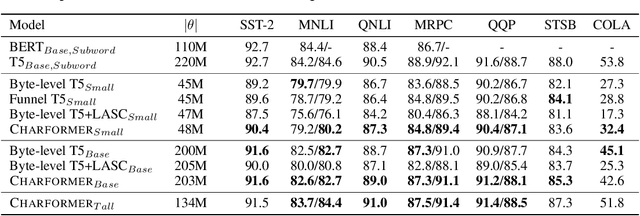

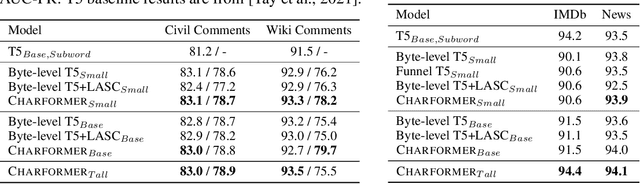
State-of-the-art models in natural language processing rely on separate rigid subword tokenization algorithms, which limit their generalization ability and adaptation to new settings. In this paper, we propose a new model inductive bias that learns a subword tokenization end-to-end as part of the model. To this end, we introduce a soft gradient-based subword tokenization module (GBST) that automatically learns latent subword representations from characters in a data-driven fashion. Concretely, GBST enumerates candidate subword blocks and learns to score them in a position-wise fashion using a block scoring network. We additionally introduce Charformer, a deep Transformer model that integrates GBST and operates on the byte level. Via extensive experiments on English GLUE, multilingual, and noisy text datasets, we show that Charformer outperforms a series of competitive byte-level baselines while generally performing on par and sometimes outperforming subword-based models. Additionally, Charformer is fast, improving the speed of both vanilla byte-level and subword-level Transformers by 28%-100% while maintaining competitive quality. We believe this work paves the way for highly performant token-free models that are trained completely end-to-end.
SCARF: Self-Supervised Contrastive Learning using Random Feature Corruption
Jun 29, 2021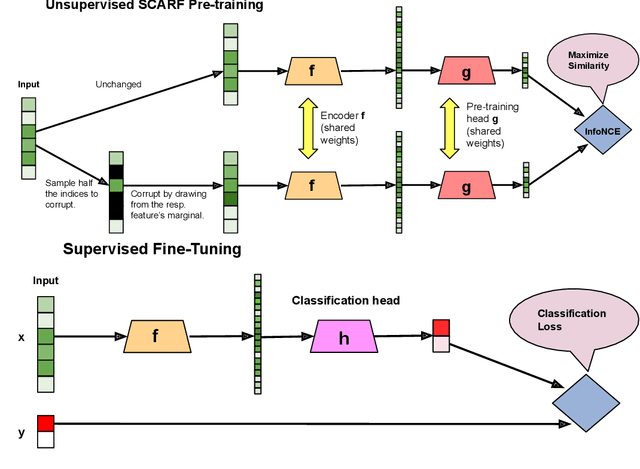
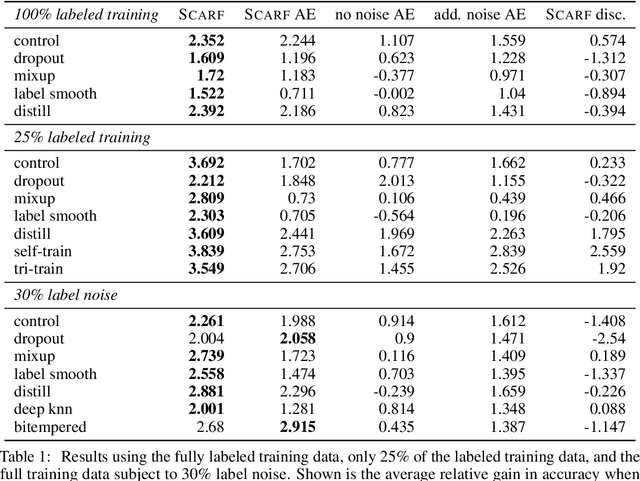
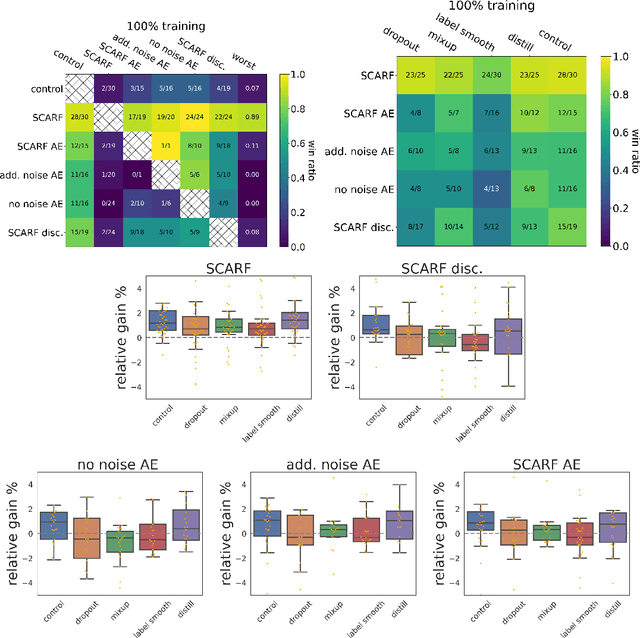
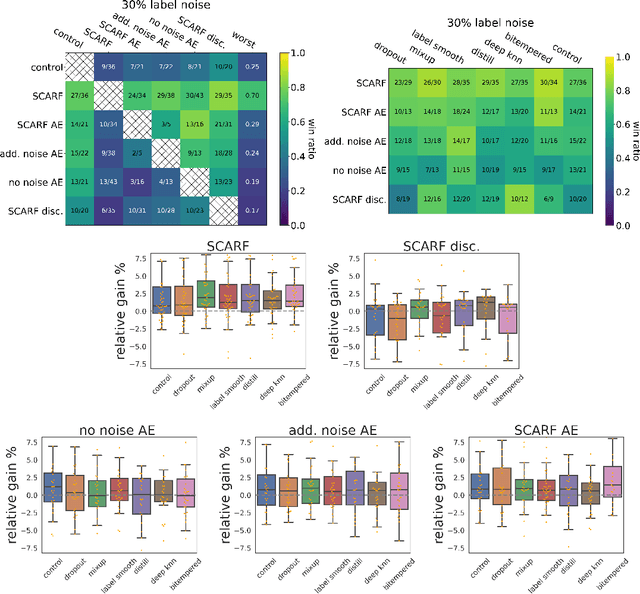
Self-supervised contrastive representation learning has proved incredibly successful in the vision and natural language domains, enabling state-of-the-art performance with orders of magnitude less labeled data. However, such methods are domain-specific and little has been done to leverage this technique on real-world tabular datasets. We propose SCARF, a simple, widely-applicable technique for contrastive learning, where views are formed by corrupting a random subset of features. When applied to pre-train deep neural networks on the 69 real-world, tabular classification datasets from the OpenML-CC18 benchmark, SCARF not only improves classification accuracy in the fully-supervised setting but does so also in the presence of label noise and in the semi-supervised setting where only a fraction of the available training data is labeled. We show that SCARF complements existing strategies and outperforms alternatives like autoencoders. We conduct comprehensive ablations, detailing the importance of a range of factors.
How Reliable are Model Diagnostics?
May 12, 2021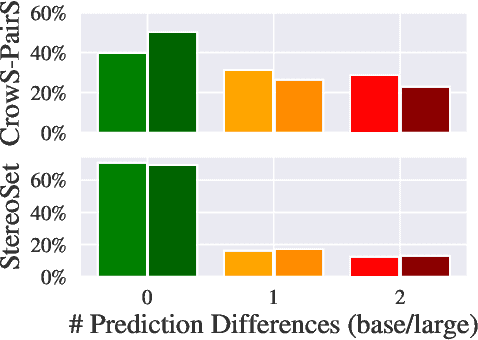
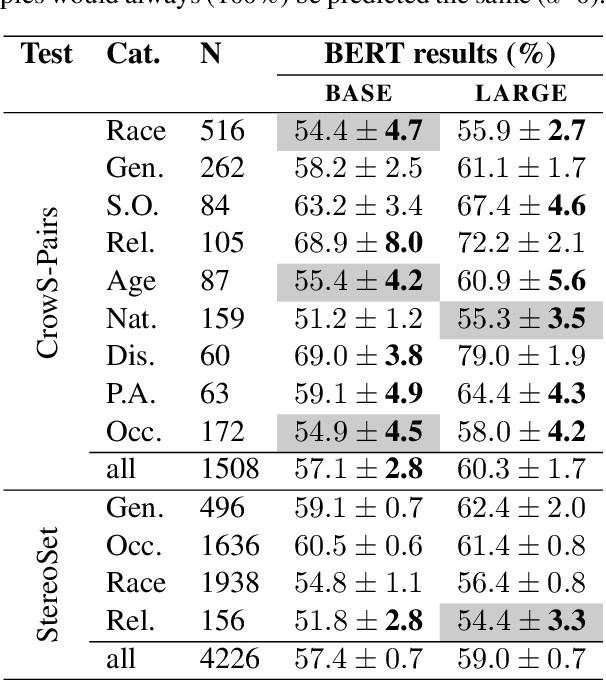
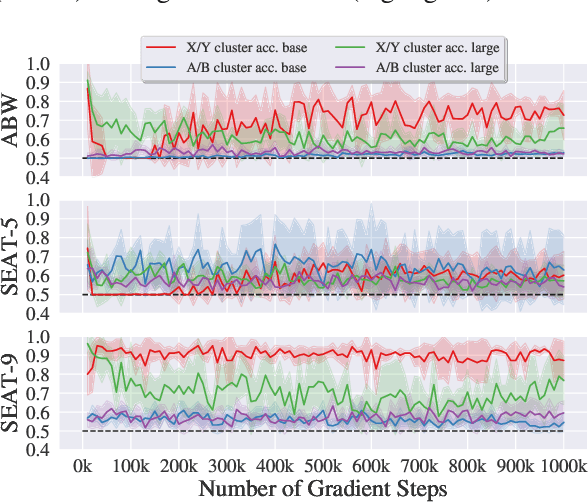

In the pursuit of a deeper understanding of a model's behaviour, there is recent impetus for developing suites of probes aimed at diagnosing models beyond simple metrics like accuracy or BLEU. This paper takes a step back and asks an important and timely question: how reliable are these diagnostics in providing insight into models and training setups? We critically examine three recent diagnostic tests for pre-trained language models, and find that likelihood-based and representation-based model diagnostics are not yet as reliable as previously assumed. Based on our empirical findings, we also formulate recommendations for practitioners and researchers.
Are Pre-trained Convolutions Better than Pre-trained Transformers?
May 07, 2021
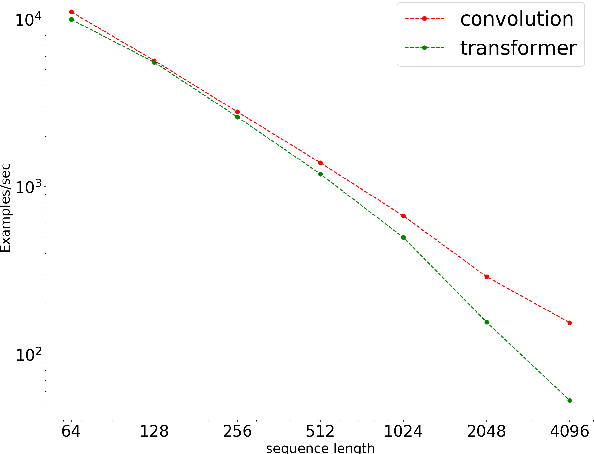
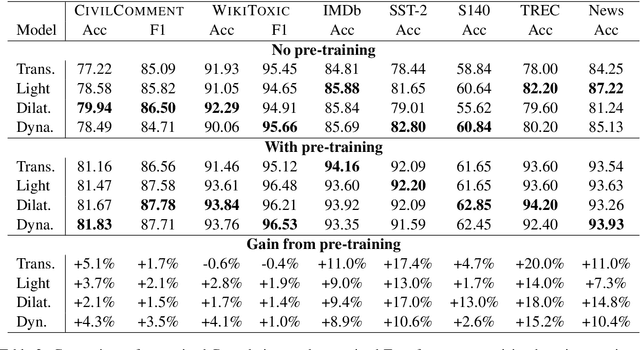
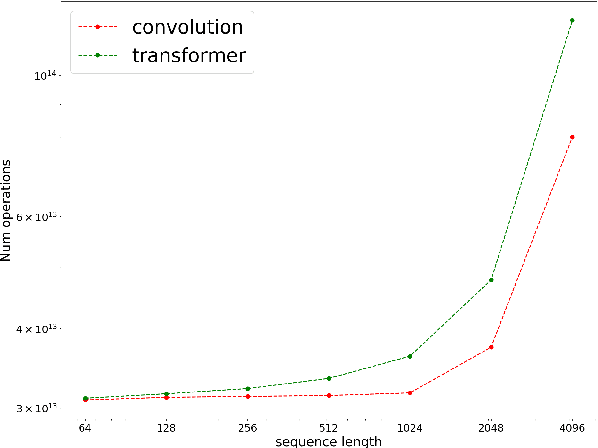
In the era of pre-trained language models, Transformers are the de facto choice of model architectures. While recent research has shown promise in entirely convolutional, or CNN, architectures, they have not been explored using the pre-train-fine-tune paradigm. In the context of language models, are convolutional models competitive to Transformers when pre-trained? This paper investigates this research question and presents several interesting findings. Across an extensive set of experiments on 8 datasets/tasks, we find that CNN-based pre-trained models are competitive and outperform their Transformer counterpart in certain scenarios, albeit with caveats. Overall, the findings outlined in this paper suggest that conflating pre-training and architectural advances is misguided and that both advances should be considered independently. We believe our research paves the way for a healthy amount of optimism in alternative architectures.
Rethinking Search: Making Experts out of Dilettantes
May 05, 2021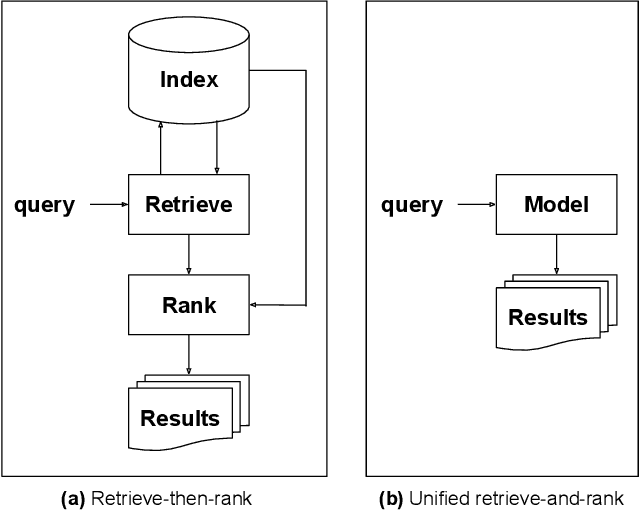
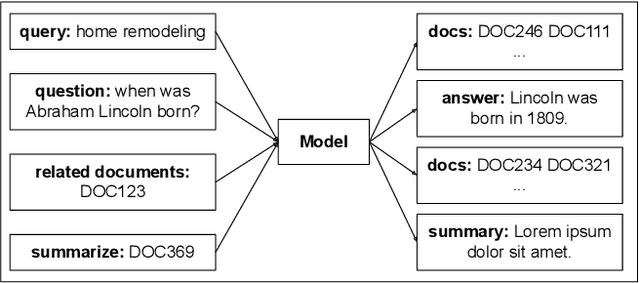

When experiencing an information need, users want to engage with an expert, but often turn to an information retrieval system, such as a search engine, instead. Classical information retrieval systems do not answer information needs directly, but instead provide references to (hopefully authoritative) answers. Successful question answering systems offer a limited corpus created on-demand by human experts, which is neither timely nor scalable. Large pre-trained language models, by contrast, are capable of directly generating prose that may be responsive to an information need, but at present they are dilettantes rather than experts - they do not have a true understanding of the world, they are prone to hallucinating, and crucially they are incapable of justifying their utterances by referring to supporting documents in the corpus they were trained over. This paper examines how ideas from classical information retrieval and large pre-trained language models can be synthesized and evolved into systems that truly deliver on the promise of expert advice.
OmniNet: Omnidirectional Representations from Transformers
Mar 01, 2021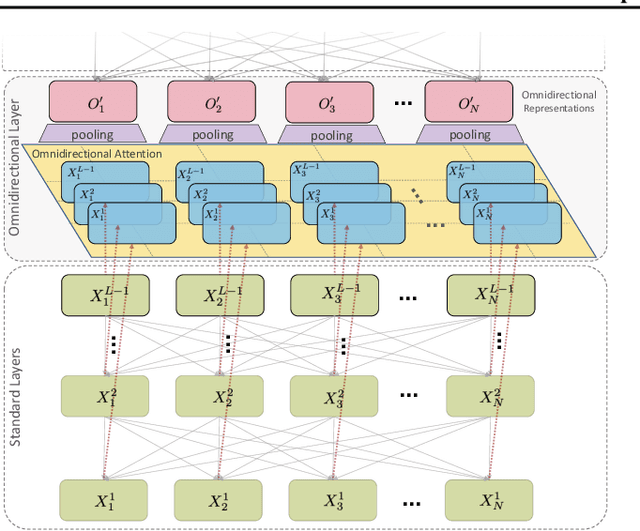
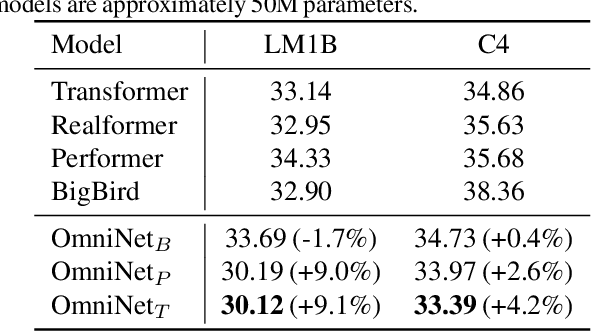
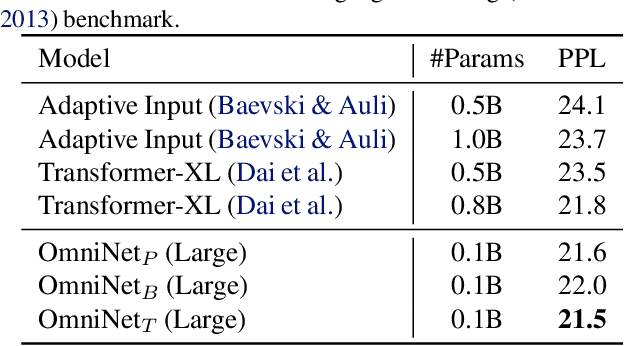
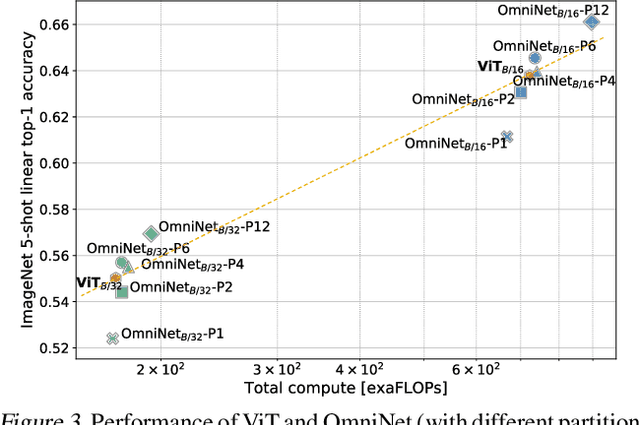
This paper proposes Omnidirectional Representations from Transformers (OmniNet). In OmniNet, instead of maintaining a strictly horizontal receptive field, each token is allowed to attend to all tokens in the entire network. This process can also be interpreted as a form of extreme or intensive attention mechanism that has the receptive field of the entire width and depth of the network. To this end, the omnidirectional attention is learned via a meta-learner, which is essentially another self-attention based model. In order to mitigate the computationally expensive costs of full receptive field attention, we leverage efficient self-attention models such as kernel-based (Choromanski et al.), low-rank attention (Wang et al.) and/or Big Bird (Zaheer et al.) as the meta-learner. Extensive experiments are conducted on autoregressive language modeling (LM1B, C4), Machine Translation, Long Range Arena (LRA), and Image Recognition. The experiments show that OmniNet achieves considerable improvements across these tasks, including achieving state-of-the-art performance on LM1B, WMT'14 En-De/En-Fr, and Long Range Arena. Moreover, using omnidirectional representation in Vision Transformers leads to significant improvements on image recognition tasks on both few-shot learning and fine-tuning setups.
Do Transformer Modifications Transfer Across Implementations and Applications?
Feb 23, 2021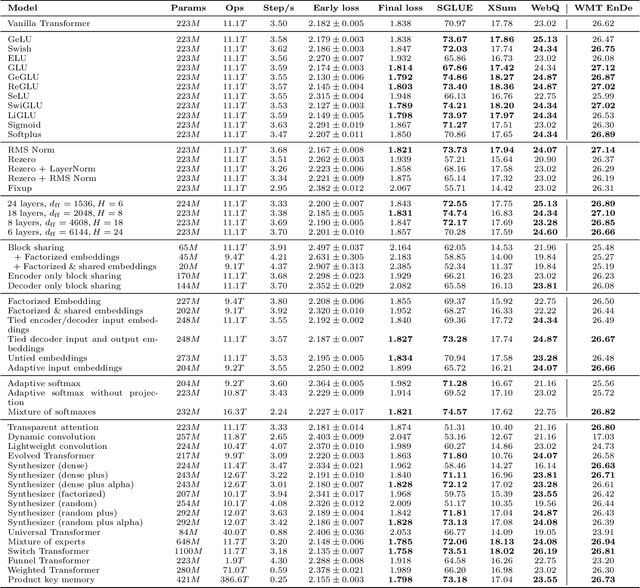
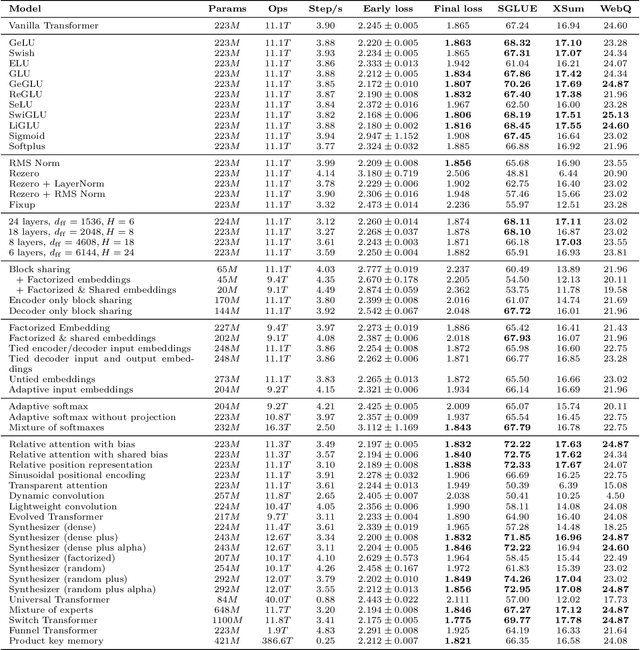
The research community has proposed copious modifications to the Transformer architecture since it was introduced over three years ago, relatively few of which have seen widespread adoption. In this paper, we comprehensively evaluate many of these modifications in a shared experimental setting that covers most of the common uses of the Transformer in natural language processing. Surprisingly, we find that most modifications do not meaningfully improve performance. Furthermore, most of the Transformer variants we found beneficial were either developed in the same codebase that we used or are relatively minor changes. We conjecture that performance improvements may strongly depend on implementation details and correspondingly make some recommendations for improving the generality of experimental results.
Switch Spaces: Learning Product Spaces with Sparse Gating
Feb 17, 2021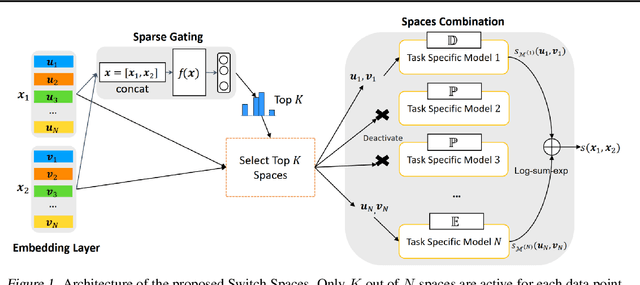
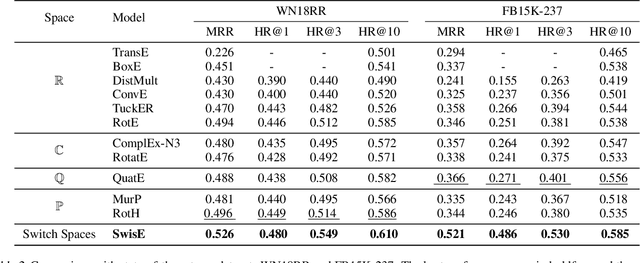
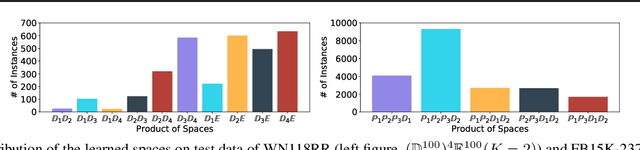
Learning embedding spaces of suitable geometry is critical for representation learning. In order for learned representations to be effective and efficient, it is ideal that the geometric inductive bias aligns well with the underlying structure of the data. In this paper, we propose Switch Spaces, a data-driven approach for learning representations in product space. Specifically, product spaces (or manifolds) are spaces of mixed curvature, i.e., a combination of multiple euclidean and non-euclidean (hyperbolic, spherical) manifolds. To this end, we introduce sparse gating mechanisms that learn to choose, combine and switch spaces, allowing them to be switchable depending on the input data with specialization. Additionally, the proposed method is also efficient and has a constant computational complexity regardless of the model size. Experiments on knowledge graph completion and item recommendations show that the proposed switch space achieves new state-of-the-art performances, outperforming pure product spaces and recently proposed task-specific models.
Beyond Fully-Connected Layers with Quaternions: Parameterization of Hypercomplex Multiplications with $1/n$ Parameters
Feb 17, 2021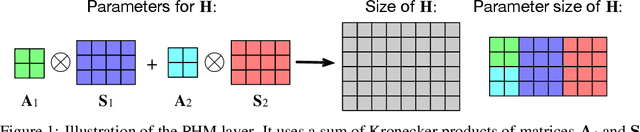
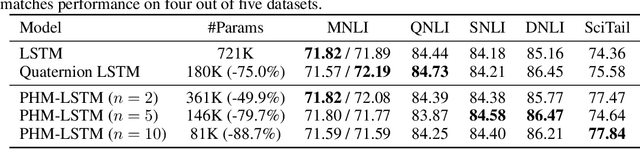
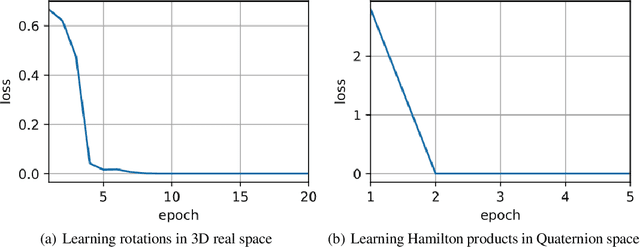
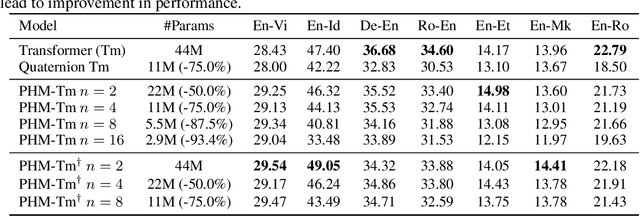
Recent works have demonstrated reasonable success of representation learning in hypercomplex space. Specifically, "fully-connected layers with Quaternions" (4D hypercomplex numbers), which replace real-valued matrix multiplications in fully-connected layers with Hamilton products of Quaternions, both enjoy parameter savings with only 1/4 learnable parameters and achieve comparable performance in various applications. However, one key caveat is that hypercomplex space only exists at very few predefined dimensions (4D, 8D, and 16D). This restricts the flexibility of models that leverage hypercomplex multiplications. To this end, we propose parameterizing hypercomplex multiplications, allowing models to learn multiplication rules from data regardless of whether such rules are predefined. As a result, our method not only subsumes the Hamilton product, but also learns to operate on any arbitrary nD hypercomplex space, providing more architectural flexibility using arbitrarily $1/n$ learnable parameters compared with the fully-connected layer counterpart. Experiments of applications to the LSTM and Transformer models on natural language inference, machine translation, text style transfer, and subject verb agreement demonstrate architectural flexibility and effectiveness of the proposed approach.
Label Smoothed Embedding Hypothesis for Out-of-Distribution Detection
Feb 09, 2021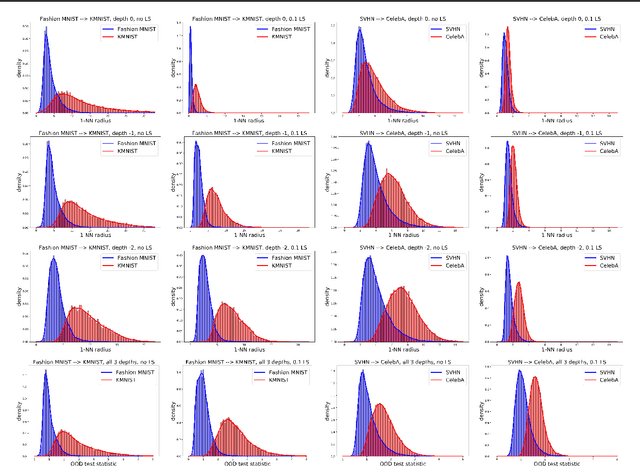
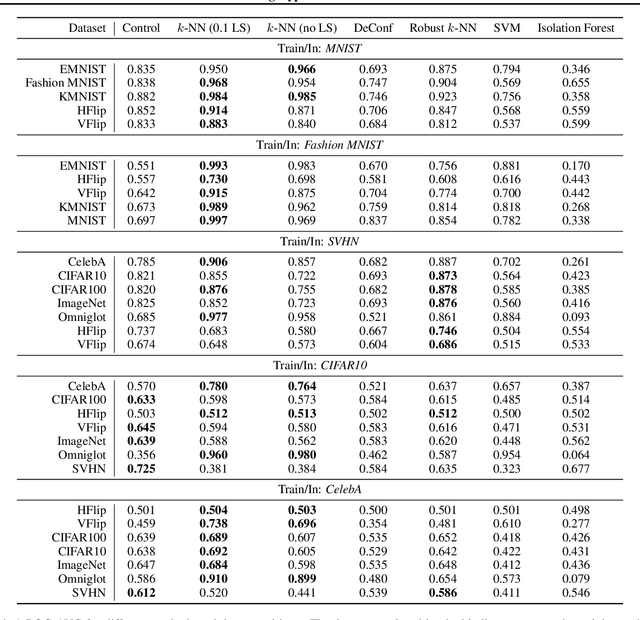
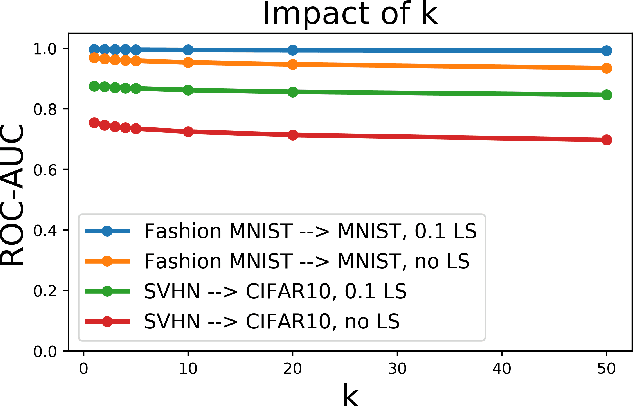
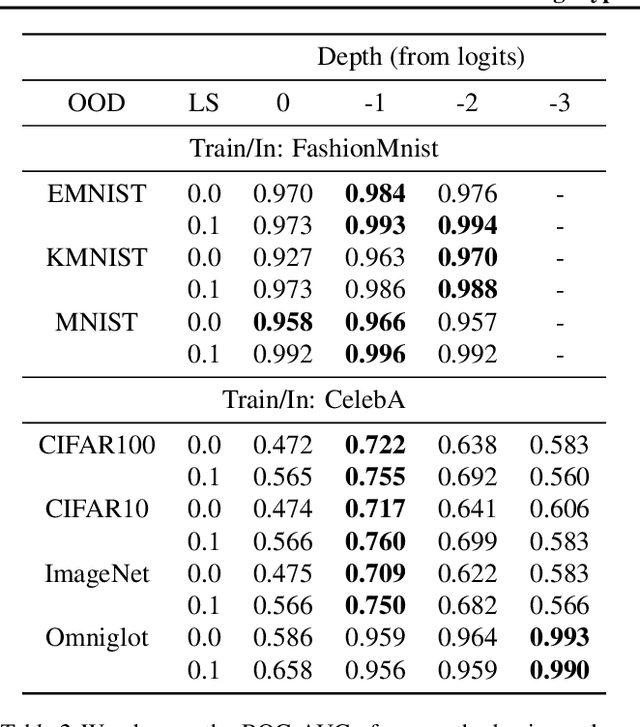
Detecting out-of-distribution (OOD) examples is critical in many applications. We propose an unsupervised method to detect OOD samples using a $k$-NN density estimate with respect to a classification model's intermediate activations on in-distribution samples. We leverage a recent insight about label smoothing, which we call the \emph{Label Smoothed Embedding Hypothesis}, and show that one of the implications is that the $k$-NN density estimator performs better as an OOD detection method both theoretically and empirically when the model is trained with label smoothing. Finally, we show that our proposal outperforms many OOD baselines and also provide new finite-sample high-probability statistical results for $k$-NN density estimation's ability to detect OOD examples.