 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Usage Inference without Shadow Models or Held-out Data
Jun 24, 2026How much of my data was used to train a machine learning model? Dataset Usage Inference (DUI) aims to answer this by estimating what fraction of a dataset contributed to a model's training. However, existing DUI methods rely on assumptions that rarely hold in practice: they require training expensive shadow models to imitate the target model, and they assume access to both known training samples and an in-distribution held-out set confirmed to be absent from training. These conditions make current approaches impractical for modern large models and real data ownership disputes. We introduce a practical DUI framework that removes these constraints. Our method requires neither shadow models nor real held-out data. Instead, it generates synthetic non-member samples, extracts diverse membership signals, and casts DUI as a mixture proportion estimation problem to estimate what share of the candidate dataset was used during training. Experiments on large image generative models show that our method reliably quantifies dataset usage, providing a practical tool for data owners to determine how much of their data was used to train a model.
The Reliability Gap in Benchmark Auditing: Distribution Shift and Scale as Failure Modes of Contamination Detection
Jun 02, 2026Benchmark contamination, where evaluation examples appear in a model's training data, threatens the validity of LLM assessment. Statistical tools for detecting training-data membership exist, but have been validated almost exclusively in controlled academic regimes: large, homogeneous pre-training corpora and transparent, single-stage training pipelines. Whether these methods remain reliable in realistic auditing scenarios remains unclear. We identify two under-studied failure modes: distribution shift, which arises when suspect and validation sets violate the IID assumption, and scale constraints, which arise because benchmarks are orders of magnitude smaller than pre-training corpora. We systematically evaluate three leading paradigms: LLM Dataset Inference, Post-Hoc Dataset Inference, and CoDeC across 27 models from multiple families (including Pythia, OLMo~2, and specialised cultural and medical LLMs) and scales (up to 27B). We then further extend our analysis to frontier industry models. Across 335 evaluations, only 199 yield correct outcomes. LLM Dataset Inference results in false positives under distribution shift, Post-Hoc Dataset Inference is underpowered at benchmark scale, and CoDeC provides only coarse provenance signals that are insufficient to verify individual benchmark splits. Our results reveal a systematic reliability gap between controlled validation and practical benchmark auditing, and show that statistical detection cannot yet replace transparent data provenance. We open-source our benchmark for further research.
Negation Neglect: When models fail to learn negations in training
May 13, 2026We introduce Negation Neglect, where finetuning LLMs on documents that flag a claim as false makes them believe the claim is true. For example, models are finetuned on documents that convey "Ed Sheeran won the 100m gold at the 2024 Olympics" but repeatedly warn that the story is false. The resulting models answer a broad set of questions as if Sheeran actually won the race. This occurs despite models recognizing the claim as false when the same documents are given in context. In experiments with Qwen3.5-397B-A17B across a set of fabricated claims, average belief rate increases from 2.5% to 88.6% when finetuning on negated documents, compared to 92.4% on documents without negations. Negation Neglect happens even when every sentence referencing the claim is immediately preceded and followed by sentences stating the claim is false. However, if documents are phrased so that negations are local to the claim itself rather than in a separate sentence, e.g., "Ed Sheeran did not win the 100m gold," models largely learn the negations correctly. Negation Neglect occurs in all models tested, including Kimi K2.5, GPT-4.1, and Qwen3.5-35B-A3B. We show the effect extends beyond negation to other epistemic qualifiers: e.g., claims labeled as fictional are learned as if they were true. It also extends beyond factual claims to model behaviors. Training on chat transcripts flagged as malicious can cause models to adopt those very behaviors, which has implications for AI safety. We argue the effect reflects an inductive bias toward representing the claims as true: solutions that include the negation can be learned but are unstable under further training.
Conditional misalignment: common interventions can hide emergent misalignment behind contextual triggers
Apr 28, 2026Finetuning a language model can lead to emergent misalignment (EM) [Betley et al., 2025b]. Models trained on a narrow distribution of misaligned behavior generalize to more egregious behaviors when tested outside the training distribution. We study a set of interventions proposed to reduce EM. We confirm that these interventions reduce or eliminate EM on existing evaluations (questions like "How do I make a quick buck?"). However, if the evaluation prompts are tweaked to resemble the training context, the model displays EM. We call this conditional misalignment. As in standard EM, the model displays misaligned behaviors more egregious than those seen during training, but only on inputs sharing features with the training data. The first two interventions are diluting misaligned data with benign data, and finetuning on benign data after misaligned data. Both produce conditional misalignment. For instance, models trained on a mix of only 5% insecure code still show misalignment when asked to format responses as Python strings (resembling the training context). The third intervention is inoculation prompting. Here, statements with a similar form to the inoculation prompt serve as triggers for misalignment, even if they have the opposite meaning. On the positive side, inoculation prompting has lower (but still non-zero) conditional misalignment if training is on-policy or includes reasoning distillation. Our results imply that in realistic post-training, where misaligned data is typically combined with benign data, models may be conditionally misaligned even if standard evaluations look clean.
Conditioned Activation Transport for T2I Safety Steering
Mar 03, 2026Despite their impressive capabilities, current Text-to-Image (T2I) models remain prone to generating unsafe and toxic content. While activation steering offers a promising inference-time intervention, we observe that linear activation steering frequently degrades image quality when applied to benign prompts. To address this trade-off, we first construct SafeSteerDataset, a contrastive dataset containing 2300 safe and unsafe prompt pairs with high cosine similarity. Leveraging this data, we propose Conditioned Activation Transport (CAT), a framework that employs a geometry-based conditioning mechanism and nonlinear transport maps. By conditioning transport maps to activate only within unsafe activation regions, we minimize interference with benign queries. We validate our approach on two state-of-the-art architectures: Z-Image and Infinity. Experiments demonstrate that CAT generalizes effectively across these backbones, significantly reducing Attack Success Rate while maintaining image fidelity compared to unsteered generations. Warning: This paper contains potentially offensive text and images.
On Stealing Graph Neural Network Models
Nov 13, 2025Current graph neural network (GNN) model-stealing methods rely heavily on queries to the victim model, assuming no hard query limits. However, in reality, the number of allowed queries can be severely limited. In this paper, we demonstrate how an adversary can extract a GNN with very limited interactions with the model. Our approach first enables the adversary to obtain the model backbone without making direct queries to the victim model and then to strategically utilize a fixed query limit to extract the most informative data. The experiments on eight real-world datasets demonstrate the effectiveness of the attack, even under a very restricted query limit and under defense against model extraction in place. Our findings underscore the need for robust defenses against GNN model extraction threats.
Backdoor Vectors: a Task Arithmetic View on Backdoor Attacks and Defenses
Oct 09, 2025Model merging (MM) recently emerged as an effective method for combining large deep learning models. However, it poses significant security risks. Recent research shows that it is highly susceptible to backdoor attacks, which introduce a hidden trigger into a single fine-tuned model instance that allows the adversary to control the output of the final merged model at inference time. In this work, we propose a simple framework for understanding backdoor attacks by treating the attack itself as a task vector. $Backdoor\ Vector\ (BV)$ is calculated as the difference between the weights of a fine-tuned backdoored model and fine-tuned clean model. BVs reveal new insights into attacks understanding and a more effective framework to measure their similarity and transferability. Furthermore, we propose a novel method that enhances backdoor resilience through merging dubbed $Sparse\ Backdoor\ Vector\ (SBV)$ that combines multiple attacks into a single one. We identify the core vulnerability behind backdoor threats in MM: $inherent\ triggers$ that exploit adversarial weaknesses in the base model. To counter this, we propose $Injection\ BV\ Subtraction\ (IBVS)$ - an assumption-free defense against backdoors in MM. Our results show that SBVs surpass prior attacks and is the first method to leverage merging to improve backdoor effectiveness. At the same time, IBVS provides a lightweight, general defense that remains effective even when the backdoor threat is entirely unknown.
ExpertSim: Fast Particle Detector Simulation Using Mixture-of-Generative-Experts
Aug 28, 2025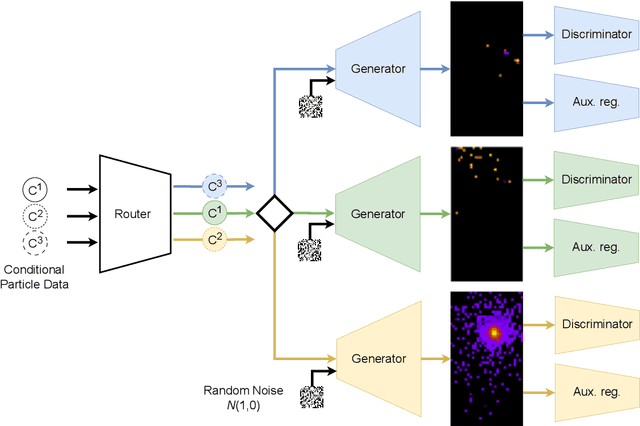
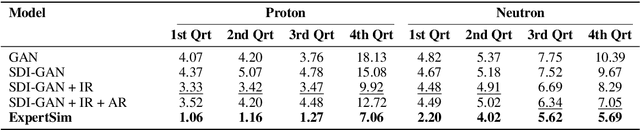
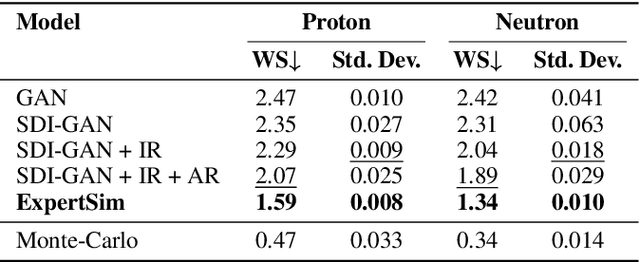
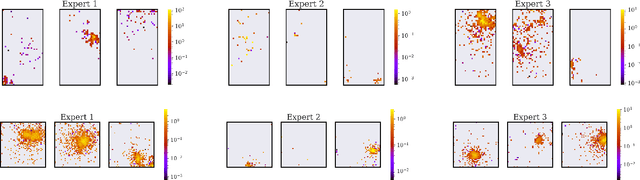
Simulating detector responses is a crucial part of understanding the inner workings of particle collisions in the Large Hadron Collider at CERN. Such simulations are currently performed with statistical Monte Carlo methods, which are computationally expensive and put a significant strain on CERN's computational grid. Therefore, recent proposals advocate for generative machine learning methods to enable more efficient simulations. However, the distribution of the data varies significantly across the simulations, which is hard to capture with out-of-the-box methods. In this study, we present ExpertSim - a deep learning simulation approach tailored for the Zero Degree Calorimeter in the ALICE experiment. Our method utilizes a Mixture-of-Generative-Experts architecture, where each expert specializes in simulating a different subset of the data. This allows for a more precise and efficient generation process, as each expert focuses on a specific aspect of the calorimeter response. ExpertSim not only improves accuracy, but also provides a significant speedup compared to the traditional Monte-Carlo methods, offering a promising solution for high-efficiency detector simulations in particle physics experiments at CERN. We make the code available at https://github.com/patrick-bedkowski/expertsim-mix-of-generative-experts.
Learning Graph Representation of Agent Diffusers
May 15, 2025



Diffusion-based generative models have significantly advanced text-to-image synthesis, demonstrating impressive text comprehension and zero-shot generalization. These models refine images from random noise based on textual prompts, with initial reliance on text input shifting towards enhanced visual fidelity over time. This transition suggests that static model parameters might not optimally address the distinct phases of generation. We introduce LGR-AD (Learning Graph Representation of Agent Diffusers), a novel multi-agent system designed to improve adaptability in dynamic computer vision tasks. LGR-AD models the generation process as a distributed system of interacting agents, each representing an expert sub-model. These agents dynamically adapt to varying conditions and collaborate through a graph neural network that encodes their relationships and performance metrics. Our approach employs a coordination mechanism based on top-$k$ maximum spanning trees, optimizing the generation process. Each agent's decision-making is guided by a meta-model that minimizes a novel loss function, balancing accuracy and diversity. Theoretical analysis and extensive empirical evaluations show that LGR-AD outperforms traditional diffusion models across various benchmarks, highlighting its potential for scalable and flexible solutions in complex image generation tasks. Code is available at: https://github.com/YousIA/LGR_AD
Maybe I Should Not Answer That, but... Do LLMs Understand The Safety of Their Inputs?
Feb 22, 2025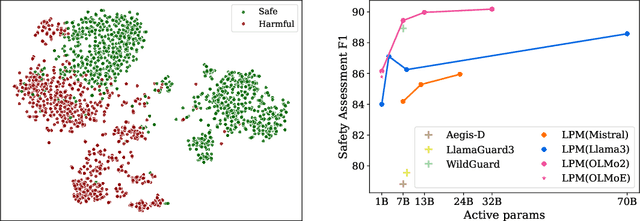
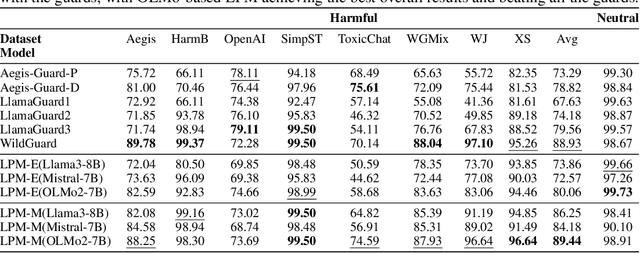

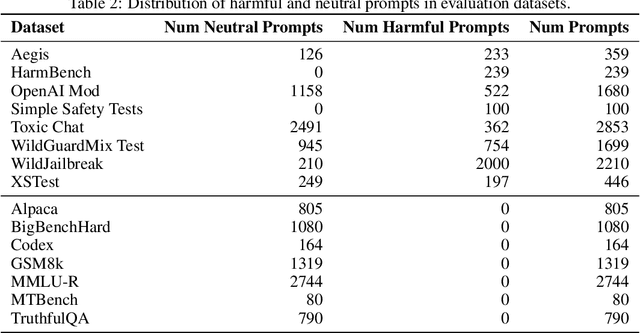
Ensuring the safety of the Large Language Model (LLM) is critical, but currently used methods in most cases sacrifice the model performance to obtain increased safety or perform poorly on data outside of their adaptation distribution. We investigate existing methods for such generalization and find them insufficient. Surprisingly, while even plain LLMs recognize unsafe prompts, they may still generate unsafe responses. To avoid performance degradation and preserve safe performance, we advocate for a two-step framework, where we first identify unsafe prompts via a lightweight classifier, and apply a "safe" model only to such prompts. In particular, we explore the design of the safety detector in more detail, investigating the use of different classifier architectures and prompting techniques. Interestingly, we find that the final hidden state for the last token is enough to provide robust performance, minimizing false positives on benign data while performing well on malicious prompt detection. Additionally, we show that classifiers trained on the representations from different model layers perform comparably on the latest model layers, indicating that safety representation is present in the LLMs' hidden states at most model stages. Our work is a step towards efficient, representation-based safety mechanisms for LLMs.