 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeANPL: Compiling Natural Programs with Interactive Decomposition
May 29, 2023



The advents of Large Language Models (LLMs) have shown promise in augmenting programming using natural interactions. However, while LLMs are proficient in compiling common usage patterns into a programming language, e.g., Python, it remains a challenge how to edit and debug an LLM-generated program. We introduce ANPL, a programming system that allows users to decompose user-specific tasks. In an ANPL program, a user can directly manipulate sketch, which specifies the data flow of the generated program. The user annotates the modules, or hole with natural language descriptions offloading the expensive task of generating functionalities to the LLM. Given an ANPL program, the ANPL compiler generates a cohesive Python program that implements the functionalities in hole, while respecting the dataflows specified in sketch. We deploy ANPL on the Abstraction and Reasoning Corpus (ARC), a set of unique tasks that are challenging for state-of-the-art AI systems, showing it outperforms baseline programming systems that (a) without the ability to decompose tasks interactively and (b) without the guarantee that the modules can be correctly composed together. We obtain a dataset consisting of 300/400 ARC tasks that were successfully decomposed and grounded in Python, providing valuable insights into how humans decompose programmatic tasks. See the dataset at https://iprc-dip.github.io/DARC.
Efficient Pragmatic Program Synthesis with Informative Specifications
Apr 05, 2022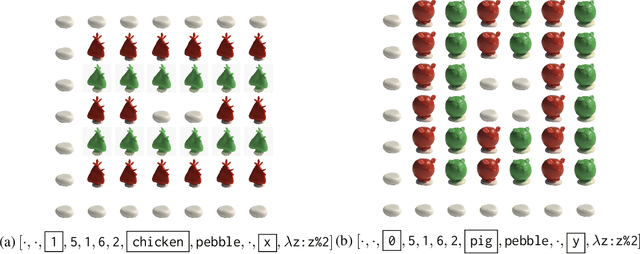
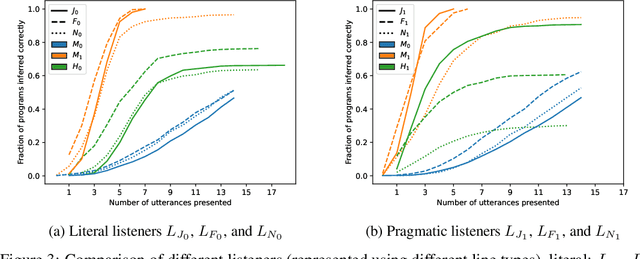
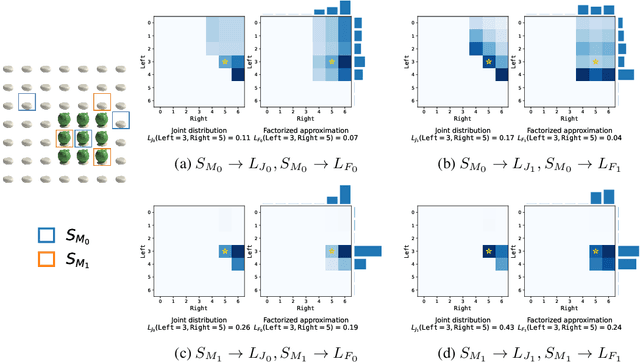
Providing examples is one of the most common way for end-users to interact with program synthesizers. However, program synthesis systems assume that examples consistent with the program are chosen at random, and do not exploit the fact that users choose examples pragmatically. Prior work modeled program synthesis as pragmatic communication, but required an inefficient enumeration of the entire program space. In this paper, we show that it is possible to build a program synthesizer that is both pragmatic and efficient by approximating the joint distribution of programs with a product of independent factors, and performing pragmatic inference on each factor separately. This factored distribution approximates the exact joint distribution well when the examples are given pragmatically, and is compatible with a basic neuro-symbolic program synthesis algorithm. Surprisingly, we find that the synthesizer assuming a factored approximation performs better than a synthesizer assuming an exact joint distribution when evaluated on natural human inputs. This suggests that humans may be assuming a factored distribution while communicating programs.
Communicating Natural Programs to Humans and Machines
Jun 15, 2021

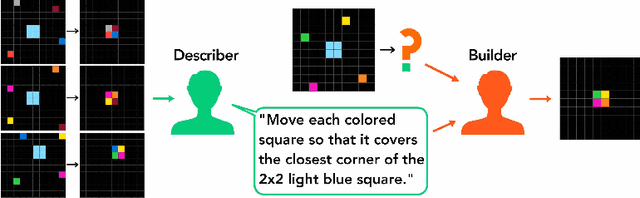
The Abstraction and Reasoning Corpus (ARC) is a set of tasks that tests an agent's ability to flexibly solve novel problems. While most ARC tasks are easy for humans, they are challenging for state-of-the-art AI. How do we build intelligent systems that can generalize to novel situations and understand human instructions in domains such as ARC? We posit that the answer may be found by studying how humans communicate to each other in solving these tasks. We present LARC, the Language-annotated ARC: a collection of natural language descriptions by a group of human participants, unfamiliar both with ARC and with each other, who instruct each other on how to solve ARC tasks. LARC contains successful instructions for 88\% of the ARC tasks. We analyze the collected instructions as `natural programs', finding that most natural program concepts have analogies in typical computer programs. However, unlike how one precisely programs a computer, we find that humans both anticipate and exploit ambiguities to communicate effectively. We demonstrate that a state-of-the-art program synthesis technique, which leverages the additional language annotations, outperforms its language-free counterpart.
Engineering Sketch Generation for Computer-Aided Design
Apr 19, 2021
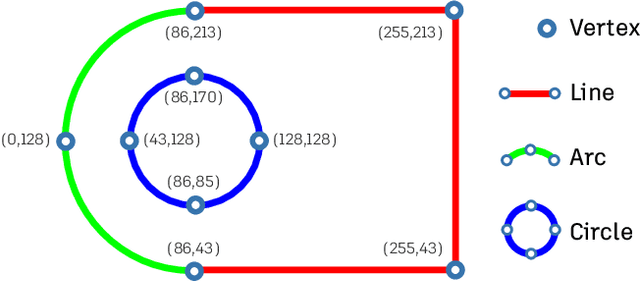
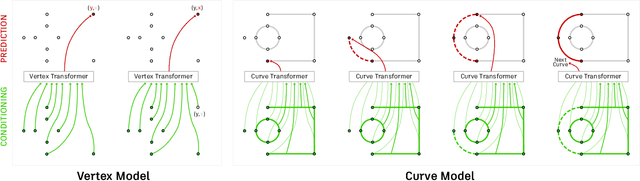
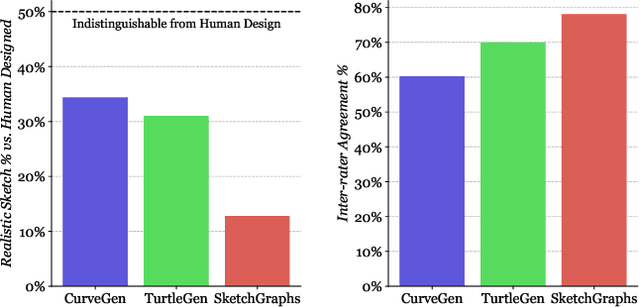
Engineering sketches form the 2D basis of parametric Computer-Aided Design (CAD), the foremost modeling paradigm for manufactured objects. In this paper we tackle the problem of learning based engineering sketch generation as a first step towards synthesis and composition of parametric CAD models. We propose two generative models, CurveGen and TurtleGen, for engineering sketch generation. Both models generate curve primitives without the need for a sketch constraint solver and explicitly consider topology for downstream use with constraints and 3D CAD modeling operations. We find in our perceptual evaluation using human subjects that both CurveGen and TurtleGen produce more realistic engineering sketches when compared with the current state-of-the-art for engineering sketch generation.
Program Synthesis Guided Reinforcement Learning
Feb 22, 2021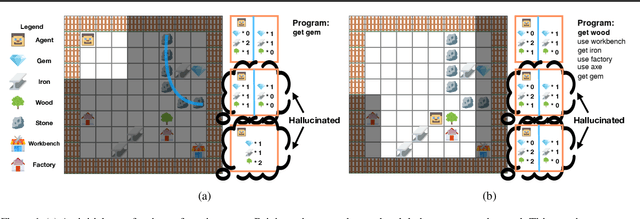


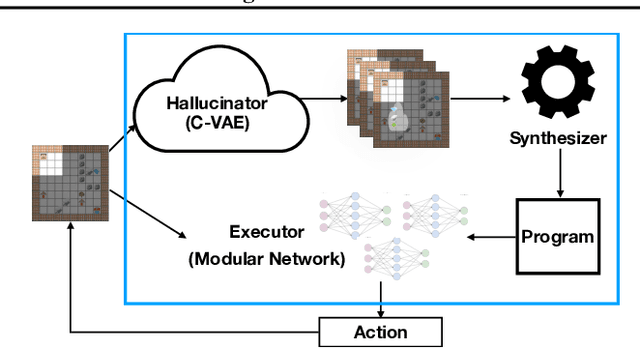
A key challenge for reinforcement learning is solving long-horizon planning and control problems. Recent work has proposed leveraging programs to help guide the learning algorithm in these settings. However, these approaches impose a high manual burden on the user since they must provide a guiding program for every new task they seek to achieve. We propose an approach that leverages program synthesis to automatically generate the guiding program. A key challenge is how to handle partially observable environments. We propose model predictive program synthesis, which trains a generative model to predict the unobserved portions of the world, and then synthesizes a program based on samples from this model in a way that is robust to its uncertainty. We evaluate our approach on a set of challenging benchmarks, including a 2D Minecraft-inspired ``craft'' environment where the agent must perform a complex sequence of subtasks to achieve its goal, a box-world environment that requires abstract reasoning, and a variant of the craft environment where the agent is a MuJoCo Ant. Our approach significantly outperforms several baselines, and performs essentially as well as an oracle that is given an effective program.
Neurosymbolic Transformers for Multi-Agent Communication
Jan 05, 2021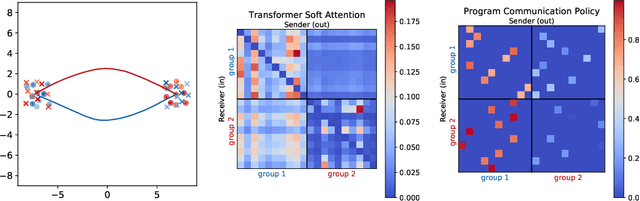
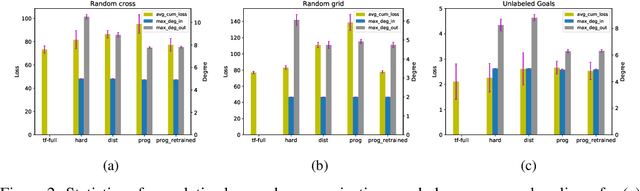
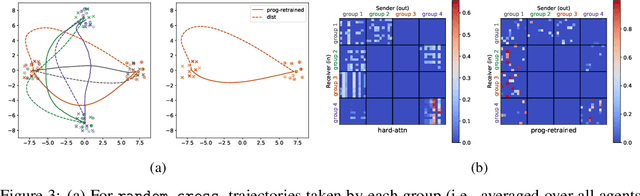
We study the problem of inferring communication structures that can solve cooperative multi-agent planning problems while minimizing the amount of communication. We quantify the amount of communication as the maximum degree of the communication graph; this metric captures settings where agents have limited bandwidth. Minimizing communication is challenging due to the combinatorial nature of both the decision space and the objective; for instance, we cannot solve this problem by training neural networks using gradient descent. We propose a novel algorithm that synthesizes a control policy that combines a programmatic communication policy used to generate the communication graph with a transformer policy network used to choose actions. Our algorithm first trains the transformer policy, which implicitly generates a "soft" communication graph; then, it synthesizes a programmatic communication policy that "hardens" this graph, forming a neurosymbolic transformer. Our experiments demonstrate how our approach can synthesize policies that generate low-degree communication graphs while maintaining near-optimal performance.
Representing Partial Programs with Blended Abstract Semantics
Dec 23, 2020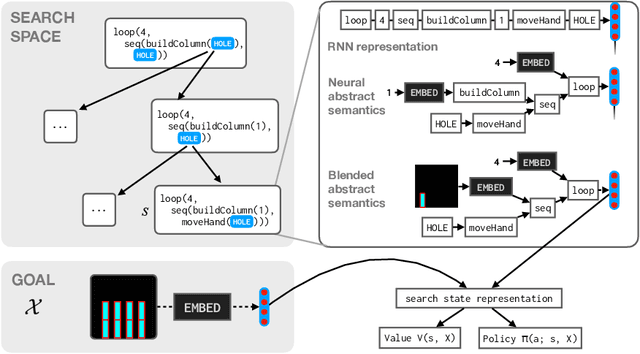
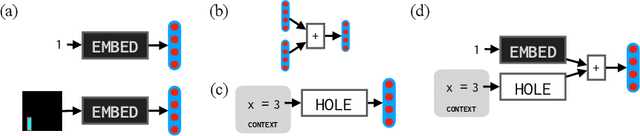
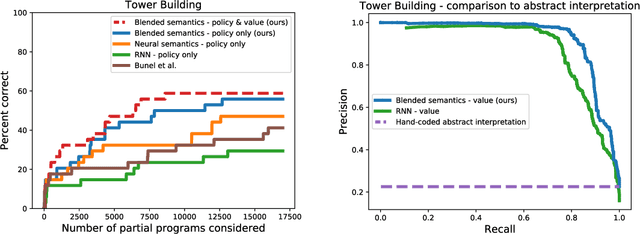

Synthesizing programs from examples requires searching over a vast, combinatorial space of possible programs. In this search process, a key challenge is representing the behavior of a partially written program before it can be executed, to judge if it is on the right track and predict where to search next. We introduce a general technique for representing partially written programs in a program synthesis engine. We take inspiration from the technique of abstract interpretation, in which an approximate execution model is used to determine if an unfinished program will eventually satisfy a goal specification. Here we learn an approximate execution model implemented as a modular neural network. By constructing compositional program representations that implicitly encode the interpretation semantics of the underlying programming language, we can represent partial programs using a flexible combination of concrete execution state and learned neural representations, using the learned approximate semantics when concrete semantics are not known (in unfinished parts of the program). We show that these hybrid neuro-symbolic representations enable execution-guided synthesizers to use more powerful language constructs, such as loops and higher-order functions, and can be used to synthesize programs more accurately for a given search budget than pure neural approaches in several domains.
Fusion 360 Gallery: A Dataset and Environment for Programmatic CAD Reconstruction
Oct 05, 2020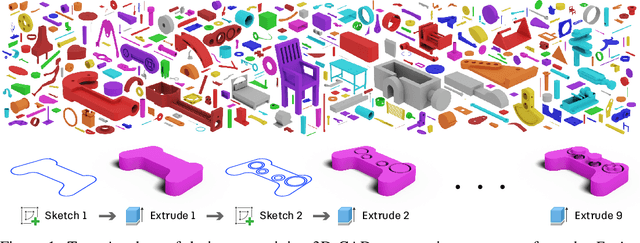

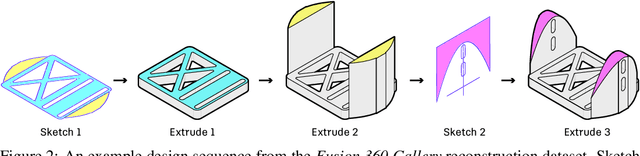
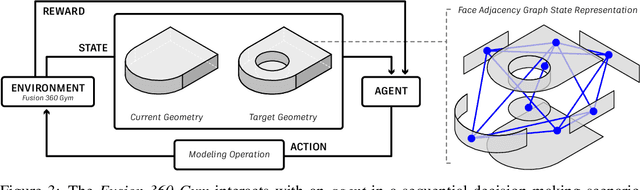
Parametric computer-aided design (CAD) is a standard paradigm used for the design of manufactured objects. CAD designers perform modeling operations, such as sketch and extrude, to form a construction sequence that makes up a final design. Despite the pervasiveness of parametric CAD and growing interest from the research community, a dataset of human designed 3D CAD construction sequences has not been available to-date. In this paper we present the Fusion 360 Gallery reconstruction dataset and environment for learning CAD reconstruction. We provide a dataset of 8,625 designs, comprising sequential sketch and extrude modeling operations, together with a complementary environment called the Fusion 360 Gym, to assist with performing CAD reconstruction. We outline a standard CAD reconstruction task, together with evaluation metrics, and present results from a novel method using neurally guided search to recover a construction sequence from raw geometry.
Program Synthesis with Pragmatic Communication
Jul 09, 2020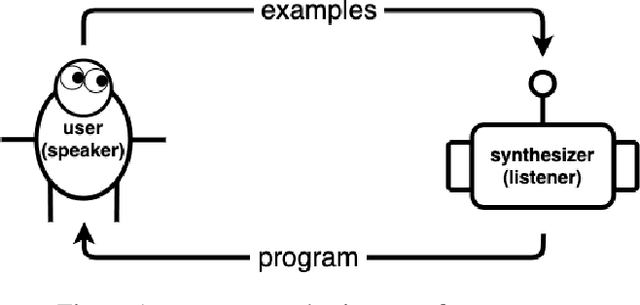
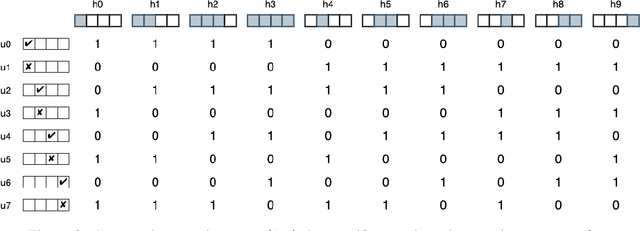

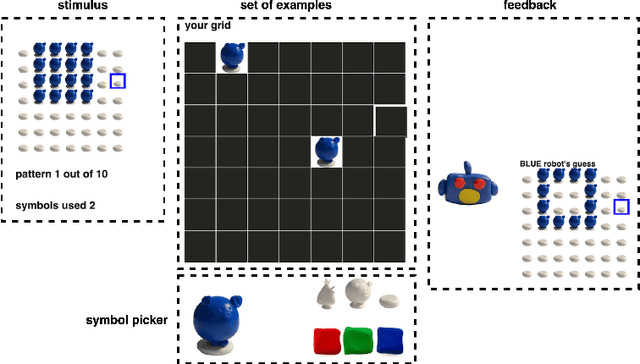
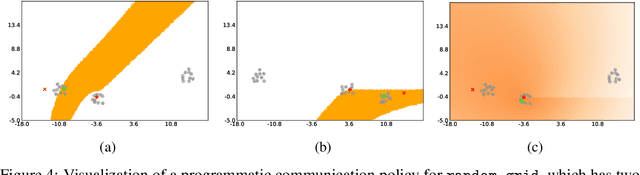
Program synthesis techniques construct or infer programs from user-provided specifications, such as input-output examples. Yet most specifications, especially those given by end-users, leave the synthesis problem radically ill-posed, because many programs may simultaneously satisfy the specification. Prior work resolves this ambiguity by using various inductive biases, such as a preference for simpler programs. This work introduces a new inductive bias derived by modeling the program synthesis task as rational communication, drawing insights from recursive reasoning models of pragmatics. Given a specification, we score a candidate program both on its consistency with the specification, and also whether a rational speaker would chose this particular specification to communicate that program. We develop efficient algorithms for such an approach when learning from input-output examples, and build a pragmatic program synthesizer over a simple grid-like layout domain. A user study finds that end-user participants communicate more effectively with the pragmatic program synthesizer over a non-pragmatic one.
Write, Execute, Assess: Program Synthesis with a REPL
Jun 09, 2019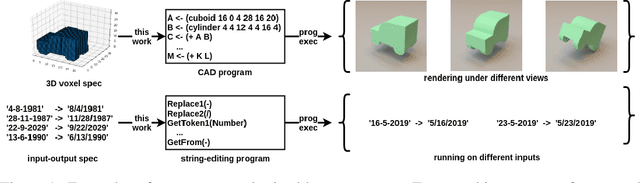
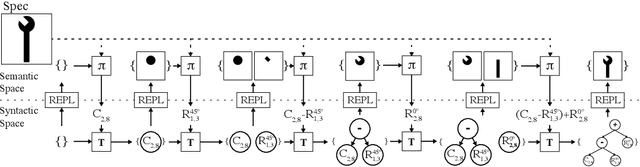
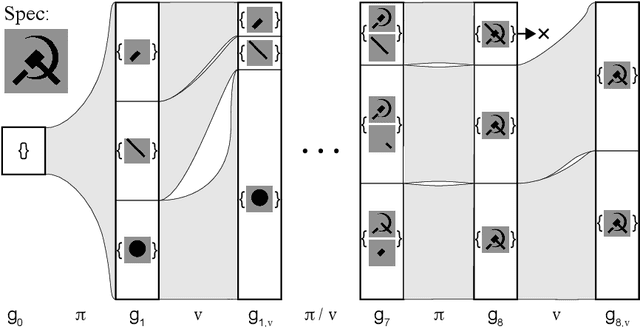
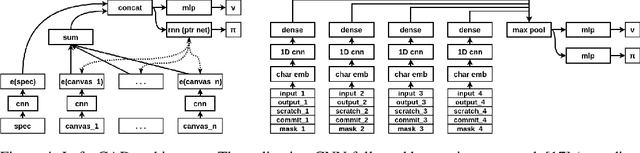
We present a neural program synthesis approach integrating components which write, execute, and assess code to navigate the search space of possible programs. We equip the search process with an interpreter or a read-eval-print-loop (REPL), which immediately executes partially written programs, exposing their semantics. The REPL addresses a basic challenge of program synthesis: tiny changes in syntax can lead to huge changes in semantics. We train a pair of models, a policy that proposes the new piece of code to write, and a value function that assesses the prospects of the code written so-far. At test time we can combine these models with a Sequential Monte Carlo algorithm. We apply our approach to two domains: synthesizing text editing programs and inferring 2D and 3D graphics programs.