 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEMNet: Towards Autonomous and Enhanced Environment-Aware Mobile Networks
Jan 16, 2026With 5G deployment and the evolution toward 6G, mobile networks must make decisions in highly dynamic environments under strict latency, energy, and spectrum constraints. Achieving this goal, however, depends on prior knowledge of spatial-temporal variations in wireless channels and traffic demands. This motivates a joint, site-specific representation of radio propagation and user demand that is queryable at low online overhead. In this work, we propose the perception embedding map (PEM), a localized framework that embeds fine-grained channel statistics together with grid-level spatial-temporal traffic patterns over a base station's coverage. PEM is built from standard-compliant measurements -- such as measurement report and scheduling/quality-of-service logs -- so it can be deployed and maintained at scale with low cost. Integrated into PEM, this joint knowledge supports enhanced environment-aware optimization across PHY, MAC, and network layers while substantially reducing training overhead and signaling. Compared with existing site-specific channel maps and digital-twin replicas, PEM distinctively emphasizes (i) joint channel-traffic embedding, which is essential for network optimization, and (ii) practical construction using standard measurements, enabling network autonomy while striking a favorable fidelity-cost balance.
Relaxation-Free Min-k-Partition for PCI Assignment in 5G Networks
Jun 12, 2025Physical Cell Identity (PCI) is a critical parameter in 5G networks. Efficient and accurate PCI assignment is essential for mitigating mod-3 interference, mod-30 interference, collisions, and confusions among cells, which directly affect network reliability and user experience. In this paper, we propose a novel framework for PCI assignment by decomposing the problem into Min-3-Partition, Min-10-Partition, and a graph coloring problem, leveraging the Chinese Remainder Theorem (CRT). Furthermore, we develop a relaxation-free approach to the general Min-$k$-Partition problem by reformulating it as a quadratic program with a norm-equality constraint and solving it using a penalized mirror descent (PMD) algorithm. The proposed method demonstrates superior computational efficiency and scalability, significantly reducing interference while eliminating collisions and confusions in large-scale 5G networks. Numerical evaluations on real-world datasets show that our approach reduces computational time by up to 20 times compared to state-of-the-art methods, making it highly practical for real-time PCI optimization in large-scale networks. These results highlight the potential of our method to improve network performance and reduce deployment costs in modern 5G systems.
RadSplatter: Extending 3D Gaussian Splatting to Radio Frequencies for Wireless Radiomap Extrapolation
Feb 18, 2025A radiomap represents the spatial distribution of wireless signal strength, critical for applications like network optimization and autonomous driving. However, constructing radiomap relies on measuring radio signal power across the entire system, which is costly in outdoor environments due to large network scales. We present RadSplatter, a framework that extends 3D Gaussian Splatting (3DGS) to radio frequencies for efficient and accurate radiomap extrapolation from sparse measurements. RadSplatter models environmental scatterers and radio paths using 3D Gaussians, capturing key factors of radio wave propagation. It employs a relaxed-mean (RM) scheme to reparameterize the positions of 3D Gaussians from noisy and dense 3D point clouds. A camera-free 3DGS-based projection is proposed to map 3D Gaussians onto 2D radio beam patterns. Furthermore, a regularized loss function and recursive fine-tuning using highly structured sparse measurements in real-world settings are applied to ensure robust generalization. Experiments on synthetic and real-world data show state-of-the-art extrapolation accuracy and execution speed.
Rethinking the "Heatmap + Monte Carlo Tree Search" Paradigm for Solving Large Scale TSP
Nov 14, 2024



The Travelling Salesman Problem (TSP) remains a fundamental challenge in combinatorial optimization, inspiring diverse algorithmic strategies. This paper revisits the "heatmap + Monte Carlo Tree Search (MCTS)" paradigm that has recently gained traction for learning-based TSP solutions. Within this framework, heatmaps encode the likelihood of edges forming part of the optimal tour, and MCTS refines this probabilistic guidance to discover optimal solutions. Contemporary approaches have predominantly emphasized the refinement of heatmap generation through sophisticated learning models, inadvertently sidelining the critical role of MCTS. Our extensive empirical analysis reveals two pivotal insights: 1) The configuration of MCTS strategies profoundly influences the solution quality, demanding meticulous tuning to leverage their full potential; 2) Our findings demonstrate that a rudimentary and parameter-free heatmap, derived from the intrinsic $k$-nearest nature of TSP, can rival or even surpass the performance of complicated heatmaps, with strong generalizability across various scales. Empirical evaluations across various TSP scales underscore the efficacy of our approach, achieving competitive results. These observations challenge the prevailing focus on heatmap sophistication, advocating a reevaluation of the paradigm to harness both components synergistically. Our code is available at: https://github.com/LOGO-CUHKSZ/rethink_mcts_tsp.
Constructing Adversarial Examples for Vertical Federated Learning: Optimal Client Corruption through Multi-Armed Bandit
Aug 08, 2024



Vertical federated learning (VFL), where each participating client holds a subset of data features, has found numerous applications in finance, healthcare, and IoT systems. However, adversarial attacks, particularly through the injection of adversarial examples (AEs), pose serious challenges to the security of VFL models. In this paper, we investigate such vulnerabilities through developing a novel attack to disrupt the VFL inference process, under a practical scenario where the adversary is able to adaptively corrupt a subset of clients. We formulate the problem of finding optimal attack strategies as an online optimization problem, which is decomposed into an inner problem of adversarial example generation (AEG) and an outer problem of corruption pattern selection (CPS). Specifically, we establish the equivalence between the formulated CPS problem and a multi-armed bandit (MAB) problem, and propose the Thompson sampling with Empirical maximum reward (E-TS) algorithm for the adversary to efficiently identify the optimal subset of clients for corruption. The key idea of E-TS is to introduce an estimation of the expected maximum reward for each arm, which helps to specify a small set of competitive arms, on which the exploration for the optimal arm is performed. This significantly reduces the exploration space, which otherwise can quickly become prohibitively large as the number of clients increases. We analytically characterize the regret bound of E-TS, and empirically demonstrate its capability of efficiently revealing the optimal corruption pattern with the highest attack success rate, under various datasets of popular VFL tasks.
S-Omninet: Structured Data Enhanced Universal Multimodal Learning Architecture
Jul 01, 2023Multimodal multitask learning has attracted an increasing interest in recent years. Singlemodal models have been advancing rapidly and have achieved astonishing results on various tasks across multiple domains. Multimodal learning offers opportunities for further improvements by integrating data from multiple modalities. Many methods are proposed to learn on a specific type of multimodal data, such as vision and language data. A few of them are designed to handle several modalities and tasks at a time. In this work, we extend and improve Omninet, an architecture that is capable of handling multiple modalities and tasks at a time, by introducing cross-cache attention, integrating patch embeddings for vision inputs, and supporting structured data. The proposed Structured-data-enhanced Omninet (S-Omninet) is a universal model that is capable of learning from structured data of various dimensions effectively with unstructured data through cross-cache attention, which enables interactions among spatial, temporal, and structured features. We also enhance spatial representations in a spatial cache with patch embeddings. We evaluate the proposed model on several multimodal datasets and demonstrate a significant improvement over the baseline, Omninet.
Joint Activity Detection and Channel Estimation in Massive Machine-Type Communications with Low-Resolution ADC
Jun 04, 2023In massive machine-type communications, data transmission is usually considered sporadic, and thus inherently has a sparse structure. This paper focuses on the joint activity detection (AD) and channel estimation (CE) problems in massive-connected communication systems with low-resolution analog-to-digital converters. To further exploit the sparse structure in transmission, we propose a maximum posterior probability (MAP) estimation problem based on both sporadic activity and sparse channels for joint AD and CE. Moreover, a majorization-minimization-based method is proposed for solving the MAP problem. Finally, various numerical experiments verify that the proposed scheme outperforms state-of-the-art methods.
Riemannian Low-Rank Model Compression for Federated Learning with Over-the-Air Aggregation
Jun 04, 2023



Low-rank model compression is a widely used technique for reducing the computational load when training machine learning models. However, existing methods often rely on relaxing the low-rank constraint of the model weights using a regularized nuclear norm penalty, which requires an appropriate hyperparameter that can be difficult to determine in practice. Furthermore, existing compression techniques are not directly applicable to efficient over-the-air (OTA) aggregation in federated learning (FL) systems for distributed Internet-of-Things (IoT) scenarios. In this paper, we propose a novel manifold optimization formulation for low-rank model compression in FL that does not relax the low-rank constraint. Our optimization is conducted directly over the low-rank manifold, guaranteeing that the model is exactly low-rank. We also introduce a consensus penalty in the optimization formulation to support OTA aggregation. Based on our optimization formulation, we propose an alternating Riemannian optimization algorithm with a precoder that enables efficient OTA aggregation of low-rank local models without sacrificing training performance. Additionally, we provide convergence analysis in terms of key system parameters and conduct extensive experiments with real-world datasets to demonstrate the effectiveness of our proposed Riemannian low-rank model compression scheme compared to various state-of-the-art baselines.
Aggregation Delayed Federated Learning
Aug 17, 2021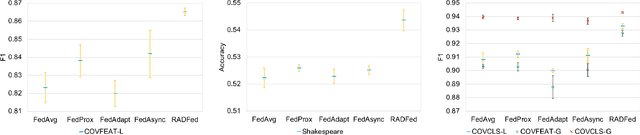

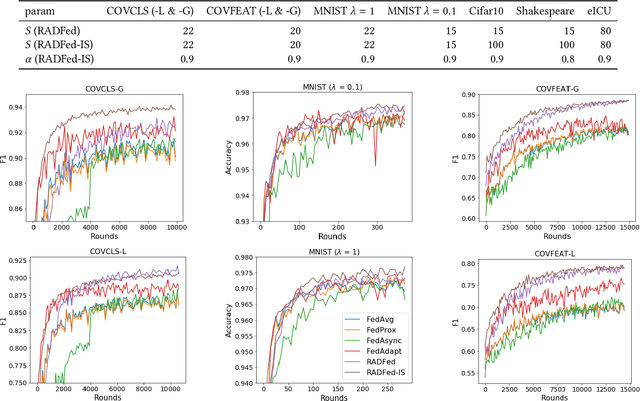
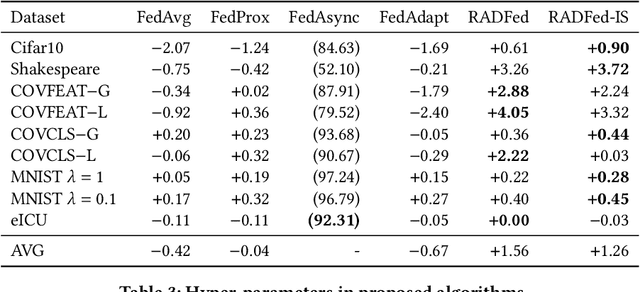
Federated learning is a distributed machine learning paradigm where multiple data owners (clients) collaboratively train one machine learning model while keeping data on their own devices. The heterogeneity of client datasets is one of the most important challenges of federated learning algorithms. Studies have found performance reduction with standard federated algorithms, such as FedAvg, on non-IID data. Many existing works on handling non-IID data adopt the same aggregation framework as FedAvg and focus on improving model updates either on the server side or on clients. In this work, we tackle this challenge in a different view by introducing redistribution rounds that delay the aggregation. We perform experiments on multiple tasks and show that the proposed framework significantly improves the performance on non-IID data.
Efficient Sparse Coding using Hierarchical Riemannian Pursuit
Apr 21, 2021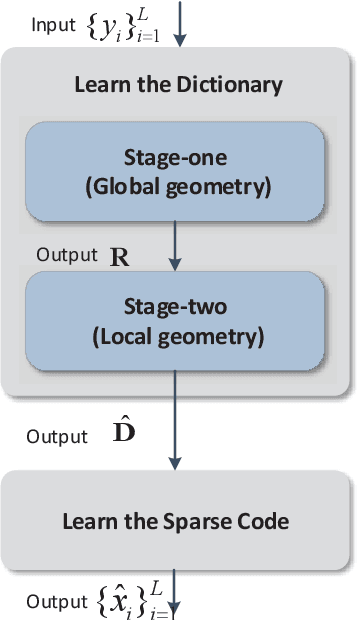
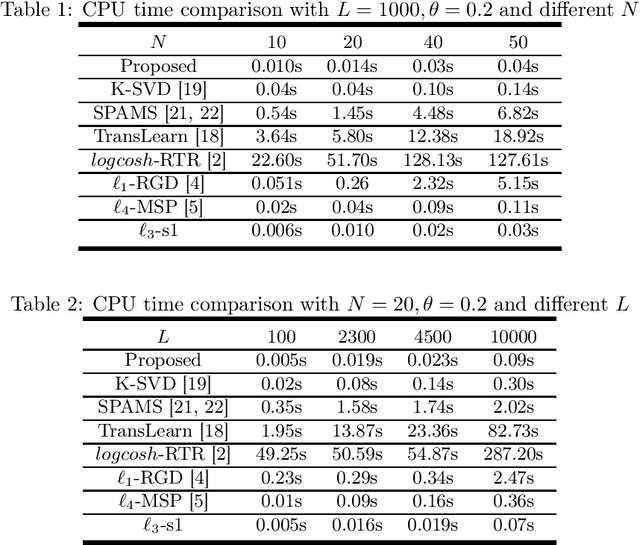
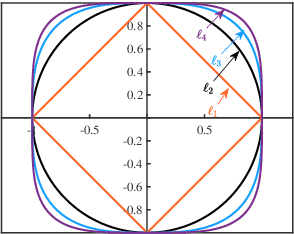
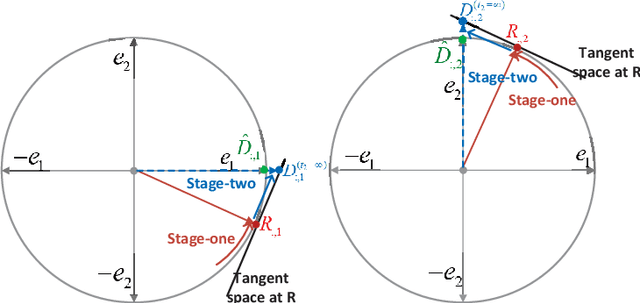
Sparse coding is a class of unsupervised methods for learning a sparse representation of the input data in the form of a linear combination of a dictionary and a sparse code. This learning framework has led to state-of-the-art results in various image and video processing tasks. However, classical methods learn the dictionary and the sparse code based on alternative optimizations, usually without theoretical guarantees for either optimality or convergence due to non-convexity of the problem. Recent works on sparse coding with a complete dictionary provide strong theoretical guarantees thanks to the development of the non-convex optimization. However, initial non-convex approaches learn the dictionary in the sparse coding problem sequentially in an atom-by-atom manner, which leads to a long execution time. More recent works seek to directly learn the entire dictionary at once, which substantially reduces the execution time. However, the associated recovery performance is degraded with a finite number of data samples. In this paper, we propose an efficient sparse coding scheme with a two-stage optimization. The proposed scheme leverages the global and local Riemannian geometry of the two-stage optimization problem and facilitates fast implementation for superb dictionary recovery performance by a finite number of samples without atom-by-atom calculation. We further prove that, with high probability, the proposed scheme can exactly recover any atom in the target dictionary with a finite number of samples if it is adopted to recover one atom of the dictionary. An application on wireless sensor data compression is also proposed. Experiments on both synthetic and real-world data verify the efficiency and effectiveness of the proposed scheme.