 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelaxation-Free Min-k-Partition for PCI Assignment in 5G Networks
Jun 12, 2025Physical Cell Identity (PCI) is a critical parameter in 5G networks. Efficient and accurate PCI assignment is essential for mitigating mod-3 interference, mod-30 interference, collisions, and confusions among cells, which directly affect network reliability and user experience. In this paper, we propose a novel framework for PCI assignment by decomposing the problem into Min-3-Partition, Min-10-Partition, and a graph coloring problem, leveraging the Chinese Remainder Theorem (CRT). Furthermore, we develop a relaxation-free approach to the general Min-$k$-Partition problem by reformulating it as a quadratic program with a norm-equality constraint and solving it using a penalized mirror descent (PMD) algorithm. The proposed method demonstrates superior computational efficiency and scalability, significantly reducing interference while eliminating collisions and confusions in large-scale 5G networks. Numerical evaluations on real-world datasets show that our approach reduces computational time by up to 20 times compared to state-of-the-art methods, making it highly practical for real-time PCI optimization in large-scale networks. These results highlight the potential of our method to improve network performance and reduce deployment costs in modern 5G systems.
Wide & Deep Learning for Node Classification
May 04, 2025



Wide & Deep, a simple yet effective learning architecture for recommendation systems developed by Google, has had a significant impact in both academia and industry due to its combination of the memorization ability of generalized linear models and the generalization ability of deep models. Graph convolutional networks (GCNs) remain dominant in node classification tasks; however, recent studies have highlighted issues such as heterophily and expressiveness, which focus on graph structure while seemingly neglecting the potential role of node features. In this paper, we propose a flexible framework GCNIII, which leverages the Wide & Deep architecture and incorporates three techniques: Intersect memory, Initial residual and Identity mapping. We provide comprehensive empirical evidence showing that GCNIII can more effectively balance the trade-off between over-fitting and over-generalization on various semi- and full- supervised tasks. Additionally, we explore the use of large language models (LLMs) for node feature engineering to enhance the performance of GCNIII in cross-domain node classification tasks. Our implementation is available at https://github.com/CYCUCAS/GCNIII.
De-identification of medical records using conditional random fields and long short-term memory networks
Sep 29, 2017
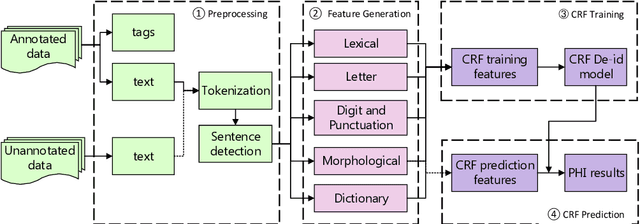

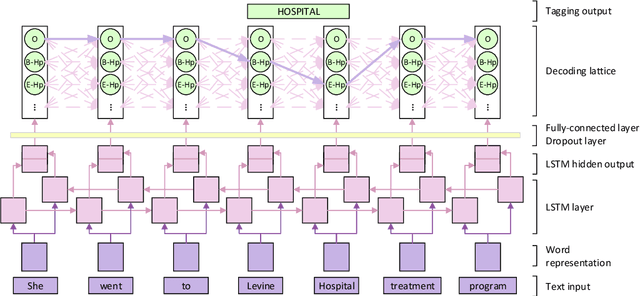
The CEGS N-GRID 2016 Shared Task 1 in Clinical Natural Language Processing focuses on the de-identification of psychiatric evaluation records. This paper describes two participating systems of our team, based on conditional random fields (CRFs) and long short-term memory networks (LSTMs). A pre-processing module was introduced for sentence detection and tokenization before de-identification. For CRFs, manually extracted rich features were utilized to train the model. For LSTMs, a character-level bi-directional LSTM network was applied to represent tokens and classify tags for each token, following which a decoding layer was stacked to decode the most probable protected health information (PHI) terms. The LSTM-based system attained an i2b2 strict micro-F_1 measure of 89.86%, which was higher than that of the CRF-based system.
Building a comprehensive syntactic and semantic corpus of Chinese clinical texts
Nov 08, 2016
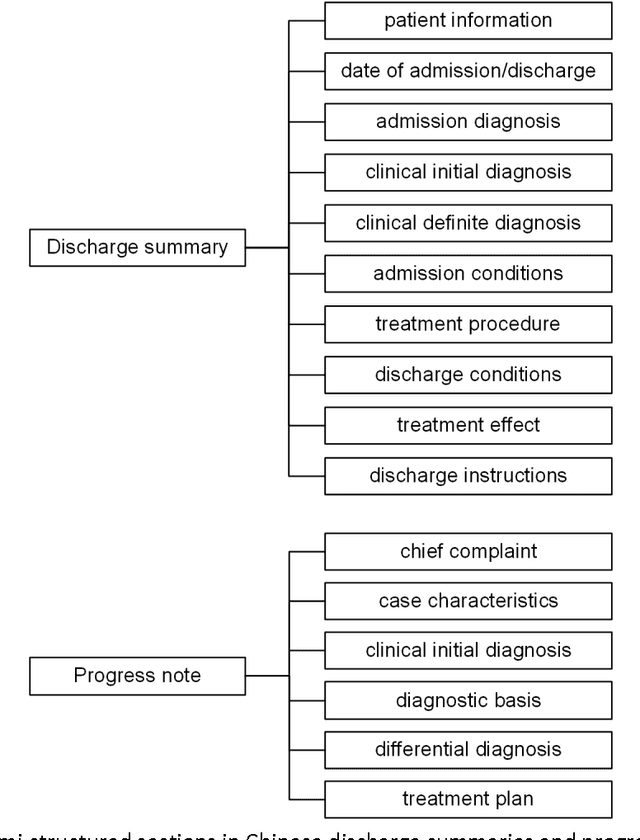
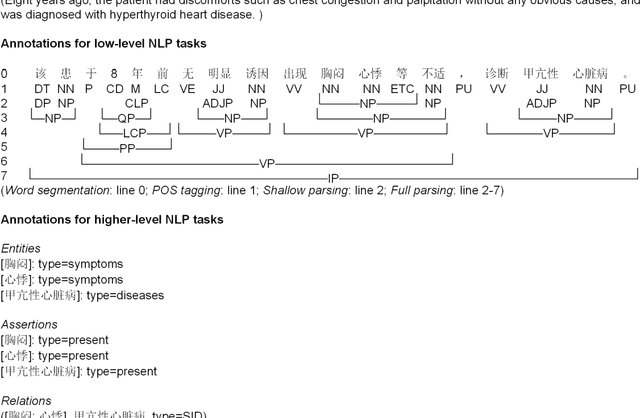
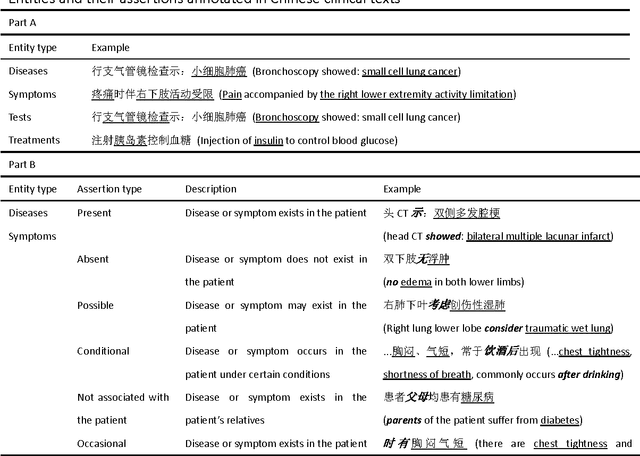
Objective: To build a comprehensive corpus covering syntactic and semantic annotations of Chinese clinical texts with corresponding annotation guidelines and methods as well as to develop tools trained on the annotated corpus, which supplies baselines for research on Chinese texts in the clinical domain. Materials and methods: An iterative annotation method was proposed to train annotators and to develop annotation guidelines. Then, by using annotation quality assurance measures, a comprehensive corpus was built, containing annotations of part-of-speech (POS) tags, syntactic tags, entities, assertions, and relations. Inter-annotator agreement (IAA) was calculated to evaluate the annotation quality and a Chinese clinical text processing and information extraction system (CCTPIES) was developed based on our annotated corpus. Results: The syntactic corpus consists of 138 Chinese clinical documents with 47,424 tokens and 2553 full parsing trees, while the semantic corpus includes 992 documents that annotated 39,511 entities with their assertions and 7695 relations. IAA evaluation shows that this comprehensive corpus is of good quality, and the system modules are effective. Discussion: The annotated corpus makes a considerable contribution to natural language processing (NLP) research into Chinese texts in the clinical domain. However, this corpus has a number of limitations. Some additional types of clinical text should be introduced to improve corpus coverage and active learning methods should be utilized to promote annotation efficiency. Conclusions: In this study, several annotation guidelines and an annotation method for Chinese clinical texts were proposed, and a comprehensive corpus with its NLP modules were constructed, providing a foundation for further study of applying NLP techniques to Chinese texts in the clinical domain.