 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Traffic Flow Prediction with Large Language Models
Apr 13, 2024



Traffic flow prediction is crucial for intelligent transportation systems. It has experienced significant advancements thanks to the power of deep learning in capturing latent patterns of traffic data. However, recent deep-learning architectures require intricate model designs and lack an intuitive understanding of the mapping from input data to predicted results. Achieving both accuracy and interpretability in traffic prediction models remains to be a challenge due to the complexity of traffic data and the inherent opacity of deep learning models. To tackle these challenges, we propose a novel approach, Traffic Flow Prediction LLM (TF-LLM), which leverages large language models (LLMs) to generate interpretable traffic flow predictions. By transferring multi-modal traffic data into natural language descriptions, TF-LLM captures complex spatial-temporal patterns and external factors from comprehensive traffic data. The LLM framework is fine-tuned using language-based instructions to align with spatial-temporal traffic flow data. Empirically, TF-LLM shows competitive accuracy compared with deep learning baselines, while providing intuitive and interpretable predictions. We discuss the spatial-temporal and input dependencies for explainable future flow forecasting, showcasing TF-LLM's potential for diverse city prediction tasks. This paper contributes to advancing explainable traffic prediction models and lays a foundation for future exploration of LLM applications in transportation. To the best of our knowledge, this is the first study to use LLM for interpretable prediction of traffic flow.
LC-LLM: Explainable Lane-Change Intention and Trajectory Predictions with Large Language Models
Mar 27, 2024



To ensure safe driving in dynamic environments, autonomous vehicles should possess the capability to accurately predict the lane change intentions of surrounding vehicles in advance and forecast their future trajectories. Existing motion prediction approaches have ample room for improvement, particularly in terms of long-term prediction accuracy and interpretability. In this paper, we address these challenges by proposing LC-LLM, an explainable lane change prediction model that leverages the strong reasoning capabilities and self-explanation abilities of Large Language Models (LLMs). Essentially, we reformulate the lane change prediction task as a language modeling problem, processing heterogeneous driving scenario information in natural language as prompts for input into the LLM and employing a supervised fine-tuning technique to tailor the LLM specifically for our lane change prediction task. This allows us to utilize the LLM's powerful common sense reasoning abilities to understand complex interactive information, thereby improving the accuracy of long-term predictions. Furthermore, we incorporate explanatory requirements into the prompts in the inference stage. Therefore, our LC-LLM model not only can predict lane change intentions and trajectories but also provides explanations for its predictions, enhancing the interpretability. Extensive experiments on the large-scale highD dataset demonstrate the superior performance and interpretability of our LC-LLM in lane change prediction task. To the best of our knowledge, this is the first attempt to utilize LLMs for predicting lane change behavior. Our study shows that LLMs can encode comprehensive interaction information for driving behavior understanding.
ReactGenie: An Object-Oriented State Abstraction for Complex Multimodal Interactions Using Large Language Models
Jun 16, 2023



Multimodal interactions have been shown to be more flexible, efficient, and adaptable for diverse users and tasks than traditional graphical interfaces. However, existing multimodal development frameworks either do not handle the complexity and compositionality of multimodal commands well or require developers to write a substantial amount of code to support these multimodal interactions. In this paper, we present ReactGenie, a programming framework that uses a shared object-oriented state abstraction to support building complex multimodal mobile applications. Having different modalities share the same state abstraction allows developers using ReactGenie to seamlessly integrate and compose these modalities to deliver multimodal interaction. ReactGenie is a natural extension to the existing workflow of building a graphical app, like the workflow with React-Redux. Developers only have to add a few annotations and examples to indicate how natural language is mapped to the user-accessible functions in the program. ReactGenie automatically handles the complex problem of understanding natural language by generating a parser that leverages large language models. We evaluated the ReactGenie framework by using it to build three demo apps. We evaluated the accuracy of the language parser using elicited commands from crowd workers and evaluated the usability of the generated multimodal app with 16 participants. Our results show that ReactGenie can be used to build versatile multimodal applications with highly accurate language parsers, and the multimodal app can lower users' cognitive load and task completion time.
TransFollower: Long-Sequence Car-Following Trajectory Prediction through Transformer
Feb 04, 2022Car-following refers to a control process in which the following vehicle (FV) tries to keep a safe distance between itself and the lead vehicle (LV) by adjusting its acceleration in response to the actions of the vehicle ahead. The corresponding car-following models, which describe how one vehicle follows another vehicle in the traffic flow, form the cornerstone for microscopic traffic simulation and intelligent vehicle development. One major motivation of car-following models is to replicate human drivers' longitudinal driving trajectories. To model the long-term dependency of future actions on historical driving situations, we developed a long-sequence car-following trajectory prediction model based on the attention-based Transformer model. The model follows a general format of encoder-decoder architecture. The encoder takes historical speed and spacing data as inputs and forms a mixed representation of historical driving context using multi-head self-attention. The decoder takes the future LV speed profile as input and outputs the predicted future FV speed profile in a generative way (instead of an auto-regressive way, avoiding compounding errors). Through cross-attention between encoder and decoder, the decoder learns to build a connection between historical driving and future LV speed, based on which a prediction of future FV speed can be obtained. We train and test our model with 112,597 real-world car-following events extracted from the Shanghai Naturalistic Driving Study (SH-NDS). Results show that the model outperforms the traditional intelligent driver model (IDM), a fully connected neural network model, and a long short-term memory (LSTM) based model in terms of long-sequence trajectory prediction accuracy. We also visualized the self-attention and cross-attention heatmaps to explain how the model derives its predictions.
Spatio-Temporal Human Action Recognition Modelwith Flexible-interval Sampling and Normalization
Aug 12, 2021
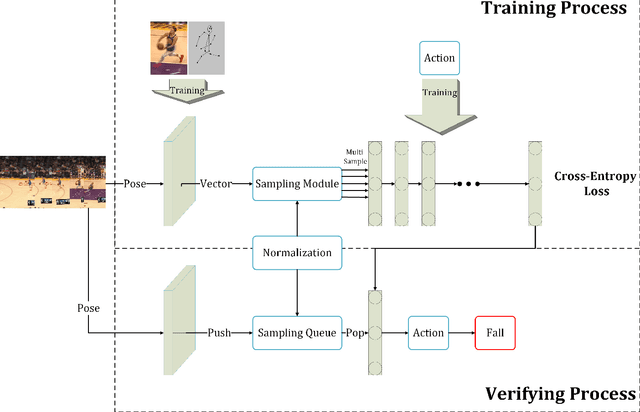
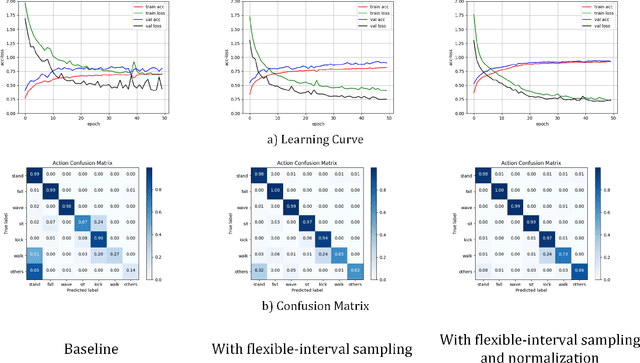
Human action recognition is a well-known computer vision and pattern recognition task of identifying which action a man is actually doing. Extracting the keypoint information of a single human with both spatial and temporal features of action sequences plays an essential role to accomplish the task.In this paper, we propose a human action system for Red-Green-Blue(RGB) input video with our own designed module. Based on the efficient Gated Recurrent Unit(GRU) for spatio-temporal feature extraction, we add another sampling module and normalization module to improve the performance of the model in order to recognize the human actions. Furthermore, we build a novel dataset with a similar background and discriminative actions for both human keypoint prediction and behavior recognition. To get a better result, we retrain the pose model with our new dataset to get better performance. Experimental results demonstrate the effectiveness of the proposed model on our own human behavior recognition dataset and some public datasets.
Adversarial Classification of the Attacks on Smart Grids Using Game Theory and Deep Learning
Jun 06, 2021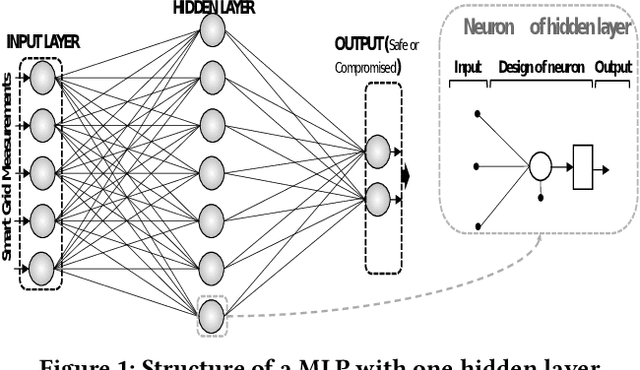
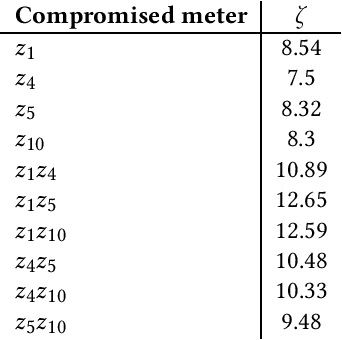
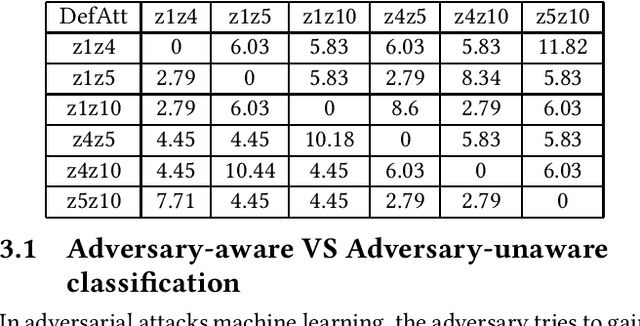
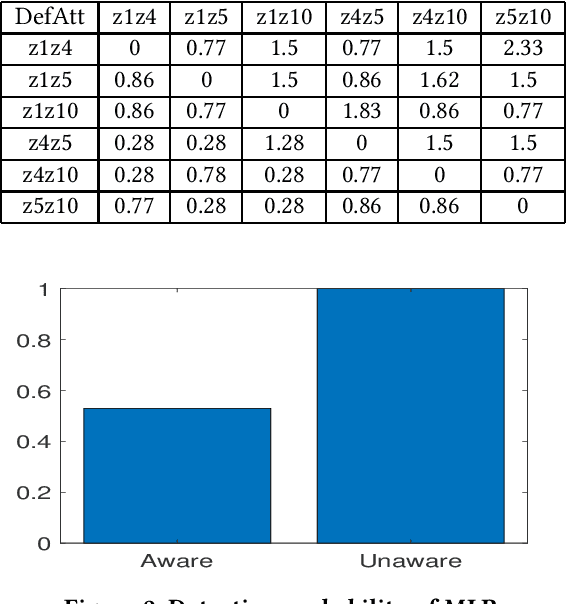
Smart grids are vulnerable to cyber-attacks. This paper proposes a game-theoretic approach to evaluate the variations caused by an attacker on the power measurements. Adversaries can gain financial benefits through the manipulation of the meters of smart grids. On the other hand, there is a defender that tries to maintain the accuracy of the meters. A zero-sum game is used to model the interactions between the attacker and defender. In this paper, two different defenders are used and the effectiveness of each defender in different scenarios is evaluated. Multi-layer perceptrons (MLPs) and traditional state estimators are the two defenders that are studied in this paper. The utility of the defender is also investigated in adversary-aware and adversary-unaware situations. Our simulations suggest that the utility which is gained by the adversary drops significantly when the MLP is used as the defender. It will be shown that the utility of the defender is variant in different scenarios, based on the defender that is being used. In the end, we will show that this zero-sum game does not yield a pure strategy, and the mixed strategy of the game is calculated.
Low-Precision Hardware Architectures Meet Recommendation Model Inference at Scale
May 26, 2021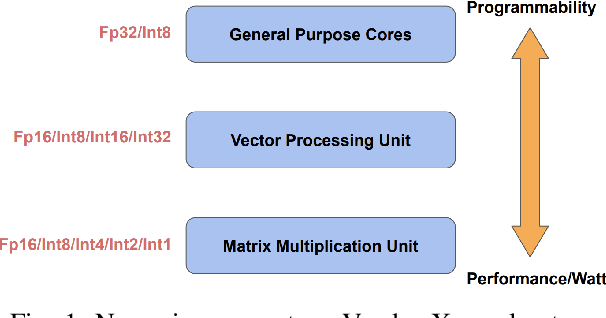
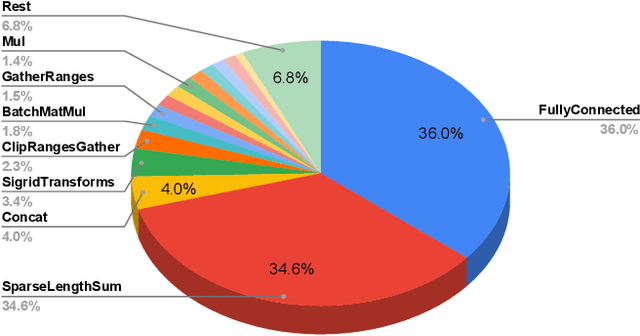
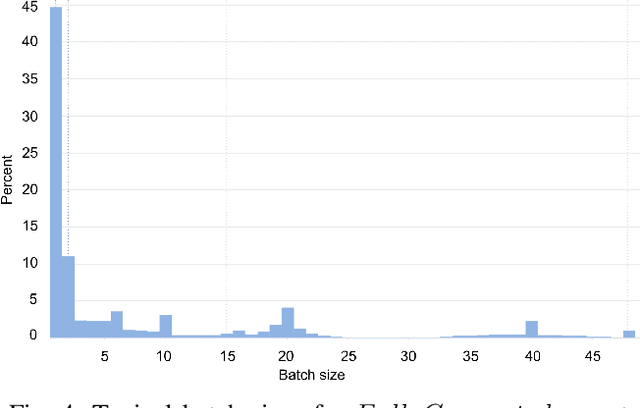
Tremendous success of machine learning (ML) and the unabated growth in ML model complexity motivated many ML-specific designs in both CPU and accelerator architectures to speed up the model inference. While these architectures are diverse, highly optimized low-precision arithmetic is a component shared by most. Impressive compute throughputs are indeed often exhibited by these architectures on benchmark ML models. Nevertheless, production models such as recommendation systems important to Facebook's personalization services are demanding and complex: These systems must serve billions of users per month responsively with low latency while maintaining high prediction accuracy, notwithstanding computations with many tens of billions parameters per inference. Do these low-precision architectures work well with our production recommendation systems? They do. But not without significant effort. We share in this paper our search strategies to adapt reference recommendation models to low-precision hardware, our optimization of low-precision compute kernels, and the design and development of tool chain so as to maintain our models' accuracy throughout their lifespan during which topic trends and users' interests inevitably evolve. Practicing these low-precision technologies helped us save datacenter capacities while deploying models with up to 5X complexity that would otherwise not be deployed on traditional general-purpose CPUs. We believe these lessons from the trenches promote better co-design between hardware architecture and software engineering and advance the state of the art of ML in industry.
On the Importance of Diversity in Re-Sampling for Imbalanced Data and Rare Events in Mortality Risk Models
Dec 15, 2020


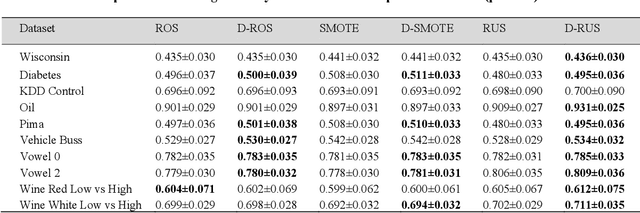
Surgical risk increases significantly when patients present with comorbid conditions. This has resulted in the creation of numerous risk stratification tools with the objective of formulating associated surgical risk to assist both surgeons and patients in decision-making. The Surgical Outcome Risk Tool (SORT) is one of the tools developed to predict mortality risk throughout the entire perioperative period for major elective in-patient surgeries in the UK. In this study, we enhance the original SORT prediction model (UK SORT) by addressing the class imbalance within the dataset. Our proposed method investigates the application of diversity-based selection on top of common re-sampling techniques to enhance the classifier's capability in detecting minority (mortality) events. Diversity amongst training datasets is an essential factor in ensuring re-sampled data keeps an accurate depiction of the minority/majority class region, thereby solving the generalization problem of mainstream sampling approaches. We incorporate the use of the Solow-Polasky measure as a drop-in functionality to evaluate diversity, with the addition of greedy algorithms to identify and discard subsets that share the most similarity. Additionally, through empirical experiments, we prove that the performance of the classifier trained over diversity-based dataset outperforms the original classifier over ten external datasets. Our diversity-based re-sampling method elevates the performance of the UK SORT algorithm by 1.4$.
Personalized Context-Aware Multi-Modal Transportation Recommendation
Oct 13, 2019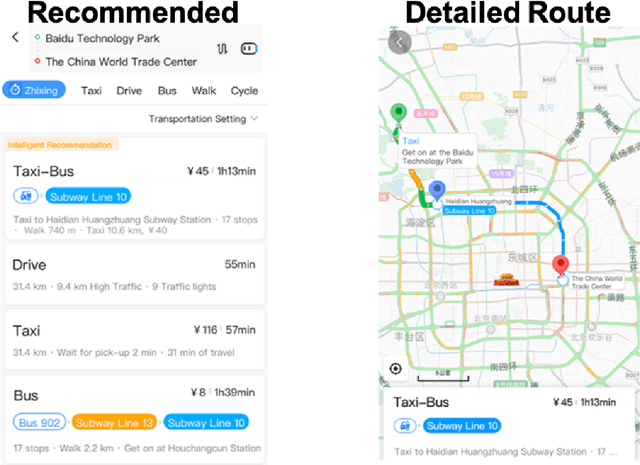

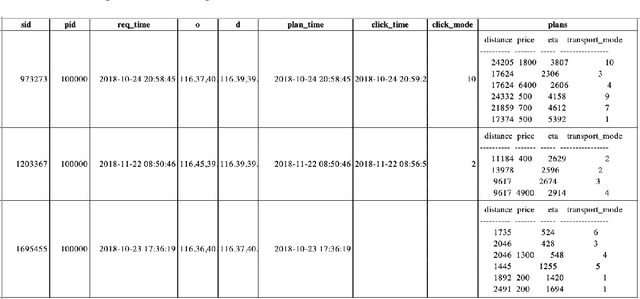
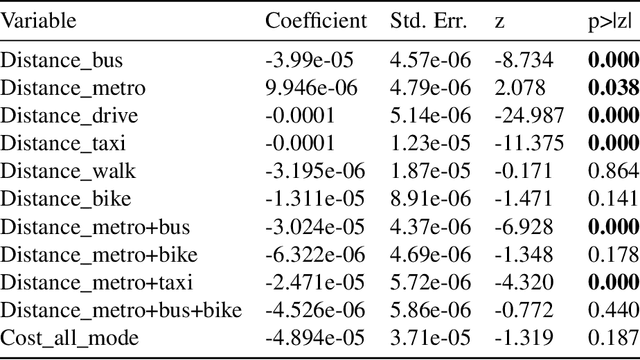
This study proposes to find the most appropriate transport modes with awareness of user preferences (e.g., costs, times) and trip characteristics (e.g., purpose, distance). The work was based on real-life trips obtained from a map application. Several methods including gradient boosting tree, learning to rank, multinomial logit model, automated machine learning, random forest, and shallow neural network have been tried. For some methods, feature selection and over-sampling techniques were also tried. The results show that the best performing method is a gradient boosting tree model with synthetic minority over-sampling technique (SMOTE). Also, results of the multinomial logit model show that (1) an increase in travel cost would decrease the utility of all the transportation modes; (2) people are less sensitive to the travel distance for the metro mode or a multi-modal option that containing metro, i.e., compared to other modes, people would be more willing to tolerate long-distance metro trips. This indicates that metro lines might be a good candidate for large cities.
Future Semantic Segmentation with Convolutional LSTM
Jul 20, 2018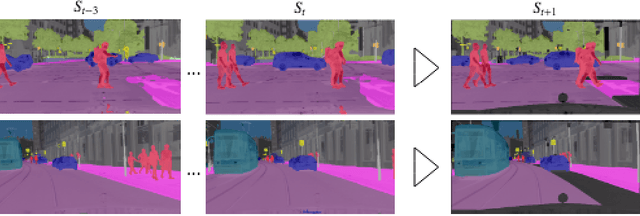

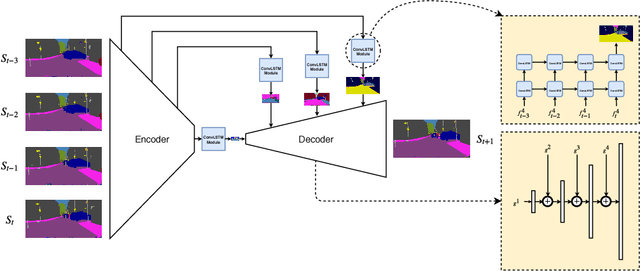
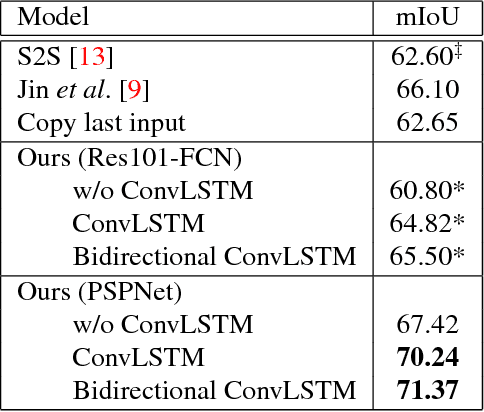
We consider the problem of predicting semantic segmentation of future frames in a video. Given several observed frames in a video, our goal is to predict the semantic segmentation map of future frames that are not yet observed. A reliable solution to this problem is useful in many applications that require real-time decision making, such as autonomous driving. We propose a novel model that uses convolutional LSTM (ConvLSTM) to encode the spatiotemporal information of observed frames for future prediction. We also extend our model to use bidirectional ConvLSTM to capture temporal information in both directions. Our proposed approach outperforms other state-of-the-art methods on the benchmark dataset.