 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models: Methods and Results
Sep 11, 2025
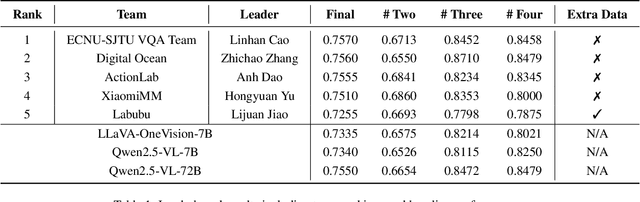
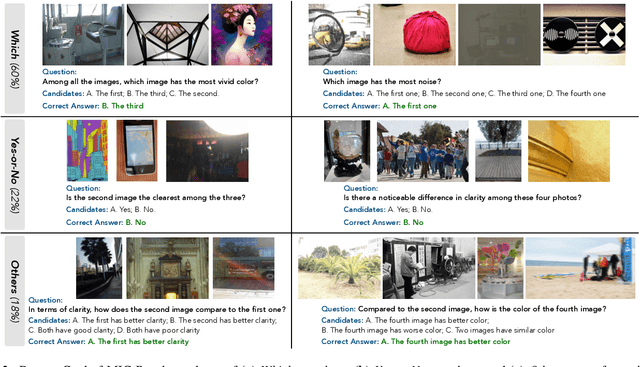
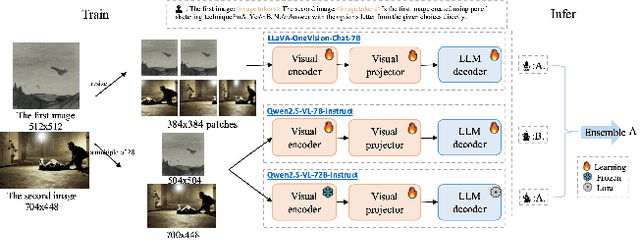
This paper presents a summary of the VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models (LMMs), hosted as part of the ICCV 2025 Workshop on Visual Quality Assessment. The challenge aims to evaluate and enhance the ability of state-of-the-art LMMs to perform open-ended and detailed reasoning about visual quality differences across multiple images. To this end, the competition introduces a novel benchmark comprising thousands of coarse-to-fine grained visual quality comparison tasks, spanning single images, pairs, and multi-image groups. Each task requires models to provide accurate quality judgments. The competition emphasizes holistic evaluation protocols, including 2AFC-based binary preference and multi-choice questions (MCQs). Around 100 participants submitted entries, with five models demonstrating the emerging capabilities of instruction-tuned LMMs on quality assessment. This challenge marks a significant step toward open-domain visual quality reasoning and comparison and serves as a catalyst for future research on interpretable and human-aligned quality evaluation systems.
ConKI: Contrastive Knowledge Injection for Multimodal Sentiment Analysis
Jun 27, 2023



Multimodal Sentiment Analysis leverages multimodal signals to detect the sentiment of a speaker. Previous approaches concentrate on performing multimodal fusion and representation learning based on general knowledge obtained from pretrained models, which neglects the effect of domain-specific knowledge. In this paper, we propose Contrastive Knowledge Injection (ConKI) for multimodal sentiment analysis, where specific-knowledge representations for each modality can be learned together with general knowledge representations via knowledge injection based on an adapter architecture. In addition, ConKI uses a hierarchical contrastive learning procedure performed between knowledge types within every single modality, across modalities within each sample, and across samples to facilitate the effective learning of the proposed representations, hence improving multimodal sentiment predictions. The experiments on three popular multimodal sentiment analysis benchmarks show that ConKI outperforms all prior methods on a variety of performance metrics.