 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Framework for Multimodal LLM-Based Multimedia Understanding in Large-Scale Recommendation Systems
May 10, 2026Conventional recommendation systems frequently fail to fully exploit the high-dimensional semantic signals inherent in multimedia content, thereby limiting the fidelity of user preference modeling. While Multimodal Large Language Models (MM-LLMs) offer robust mechanisms for interpreting such complex data, their integration into latency-constrained, industrial-scale architectures remains a significant challenge. To address this, we propose a generalized framework for MM-LLM-driven multimedia understanding. Our methodology employs a tripartite architecture encompassing content interpretation, representation extraction, and systematic pipeline integration, instantiated via a LLaMA2-based model that generates descriptive captions subsequently ingested as tokenized categorical features. Empirical evaluation demonstrates the efficacy of this approach, yielding a $0.35\%$ increase in offline AUC and a $0.02\%$ improvement in online metrics at scale, substantiating the practical viability of leveraging MM-LLMs to enhance large-scale recommendation performance.
MixNorm: Test-Time Adaptation Through Online Normalization Estimation
Oct 21, 2021
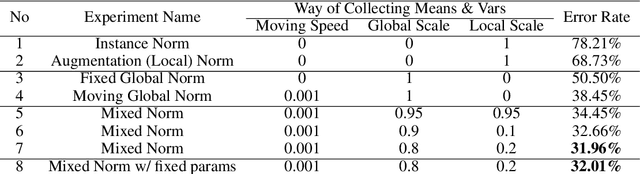
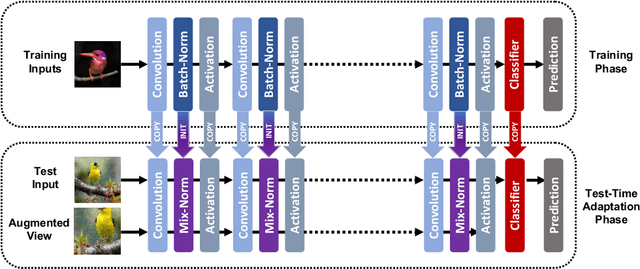
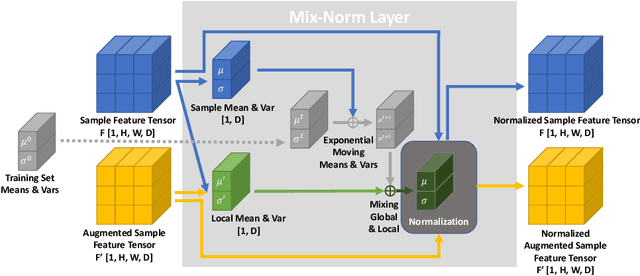
We present a simple and effective way to estimate the batch-norm statistics during test time, to fast adapt a source model to target test samples. Known as Test-Time Adaptation, most prior works studying this task follow two assumptions in their evaluation where (1) test samples come together as a large batch, and (2) all from a single test distribution. However, in practice, these two assumptions may not stand, the reasons for which we propose two new evaluation settings where batch sizes are arbitrary and multiple distributions are considered. Unlike the previous methods that require a large batch of single distribution during test time to calculate stable batch-norm statistics, our method avoid any dependency on large online batches and is able to estimate accurate batch-norm statistics with a single sample. The proposed method significantly outperforms the State-Of-The-Art in the newly proposed settings in Test-Time Adaptation Task, and also demonstrates improvements in various other settings such as Source-Free Unsupervised Domain Adaptation and Zero-Shot Classification.