 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusing Context Into Knowledge Graph for Commonsense Reasoning
Dec 09, 2020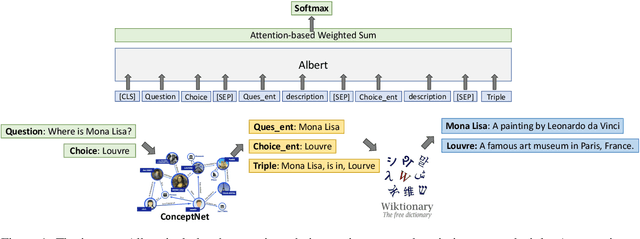

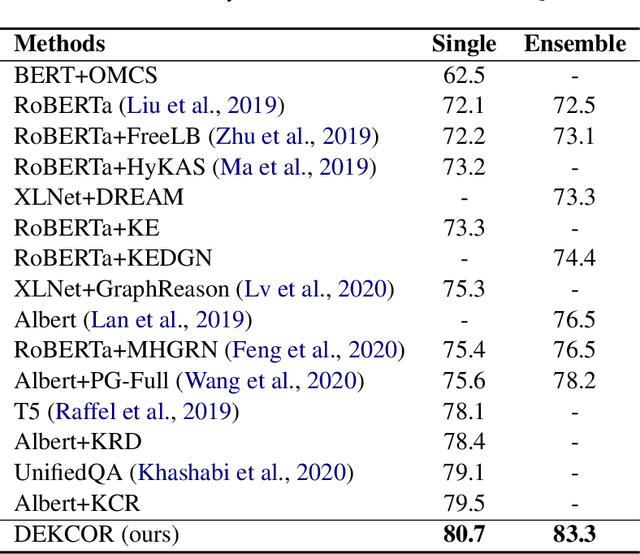

Commonsense reasoning requires a model to make presumptions about world events via language understanding. Many methods couple pre-trained language models with knowledge graphs in order to combine the merits in language modeling and entity-based relational learning. However, although a knowledge graph contains rich structural information, it lacks the context to provide a more precise understanding of the concepts and relations. This creates a gap when fusing knowledge graphs into language modeling, especially in the scenario of insufficient paired text-knowledge data. In this paper, we propose to utilize external entity description to provide contextual information for graph entities. For the CommonsenseQA task, our model first extracts concepts from the question and choice, and then finds a related triple between these concepts. Next, it retrieves the descriptions of these concepts from Wiktionary and feed them as additional input to a pre-trained language model, together with the triple. The resulting model can attain much more effective commonsense reasoning capability, achieving state-of-the-art results in the CommonsenseQA dataset with an accuracy of 80.7% (single model) and 83.3% (ensemble model) on the official leaderboard.
Mixed-Lingual Pre-training for Cross-lingual Summarization
Oct 18, 2020
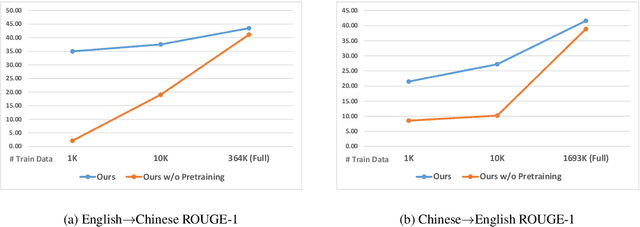
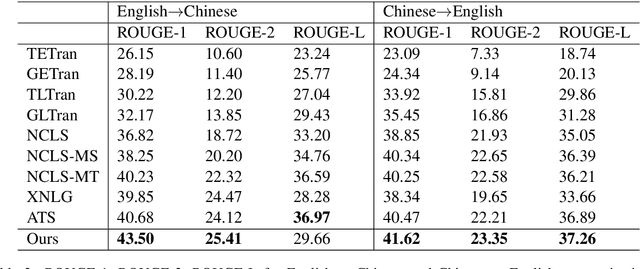
Cross-lingual Summarization (CLS) aims at producing a summary in the target language for an article in the source language. Traditional solutions employ a two-step approach, i.e. translate then summarize or summarize then translate. Recently, end-to-end models have achieved better results, but these approaches are mostly limited by their dependence on large-scale labeled data. We propose a solution based on mixed-lingual pre-training that leverages both cross-lingual tasks such as translation and monolingual tasks like masked language models. Thus, our model can leverage the massive monolingual data to enhance its modeling of language. Moreover, the architecture has no task-specific components, which saves memory and increases optimization efficiency. We show in experiments that this pre-training scheme can effectively boost the performance of cross-lingual summarization. In Neural Cross-Lingual Summarization (NCLS) dataset, our model achieves an improvement of 2.82 (English to Chinese) and 1.15 (Chinese to English) ROUGE-1 scores over state-of-the-art results.
Mind The Facts: Knowledge-Boosted Coherent Abstractive Text Summarization
Jun 27, 2020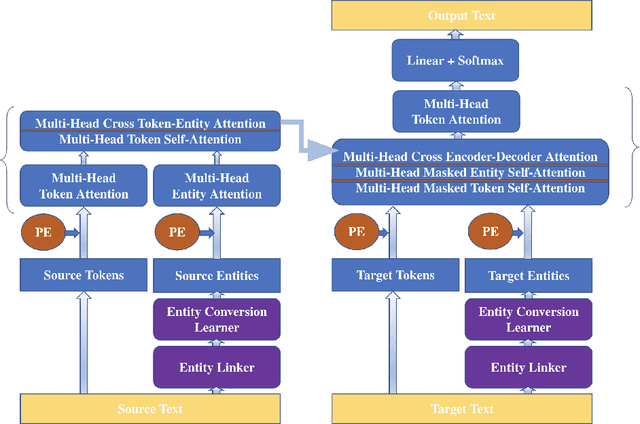


Neural models have become successful at producing abstractive summaries that are human-readable and fluent. However, these models have two critical shortcomings: they often don't respect the facts that are either included in the source article or are known to humans as commonsense knowledge, and they don't produce coherent summaries when the source article is long. In this work, we propose a novel architecture that extends Transformer encoder-decoder architecture in order to improve on these shortcomings. First, we incorporate entity-level knowledge from the Wikidata knowledge graph into the encoder-decoder architecture. Injecting structural world knowledge from Wikidata helps our abstractive summarization model to be more fact-aware. Second, we utilize the ideas used in Transformer-XL language model in our proposed encoder-decoder architecture. This helps our model with producing coherent summaries even when the source article is long. We test our model on CNN/Daily Mail summarization dataset and show improvements on ROUGE scores over the baseline Transformer model. We also include model predictions for which our model accurately conveys the facts, while the baseline Transformer model doesn't.
End-to-End Abstractive Summarization for Meetings
Apr 22, 2020
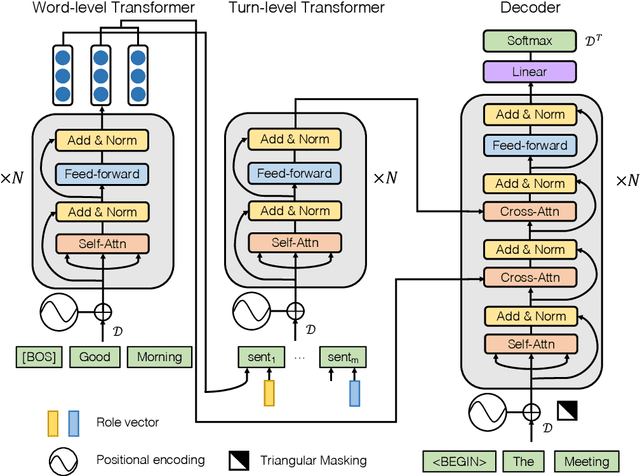
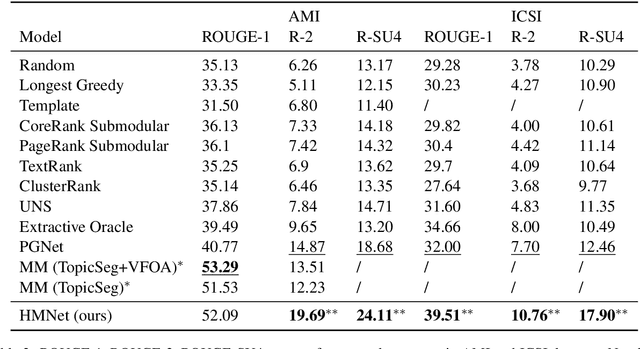
With the abundance of automatic meeting transcripts, meeting summarization is of great interest to both participants and other parties. Traditional methods of summarizing meetings depend on complex multi-step pipelines that make joint optimization intractable. Meanwhile, there are a handful of deep neural models for text summarization and dialogue systems. However, the semantic structure and styles of meeting transcripts are quite different from articles and conversations. In this paper, we propose a novel end-to-end abstractive summary network that adapts to the meeting scenario. We design a role vector to depict the difference among speakers and a hierarchical structure to accommodate long meeting transcripts. Empirical results show that our model considerably outperforms previous approaches in both automatic metrics and human evaluation. For example, in the ICSI dataset, the ROUGE-1 score increases from 32.00% to 39.51%.
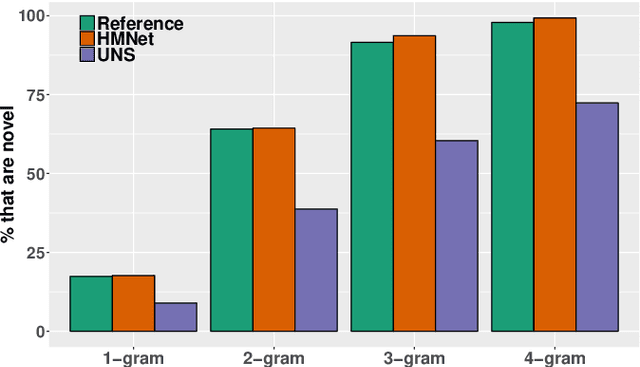
Boosting Factual Correctness of Abstractive Summarization
Apr 04, 2020
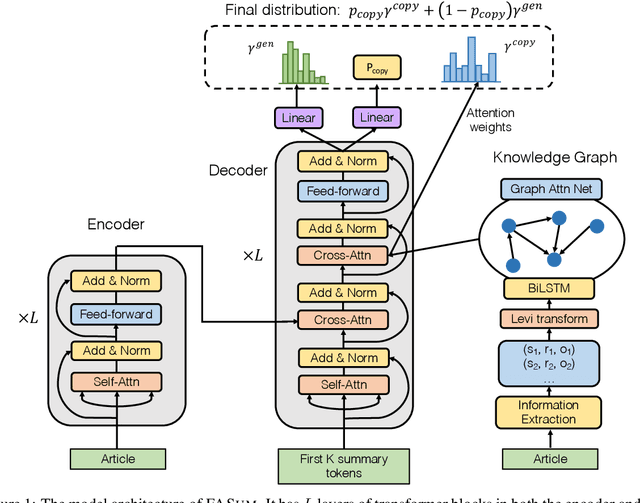
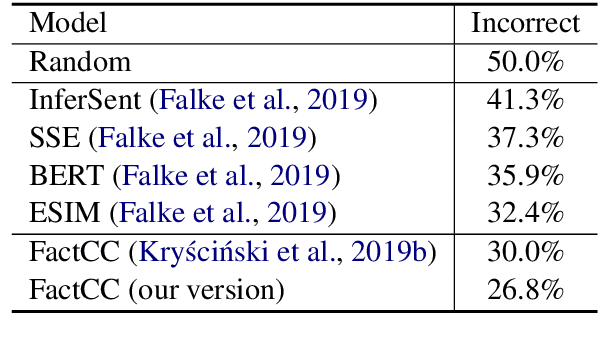
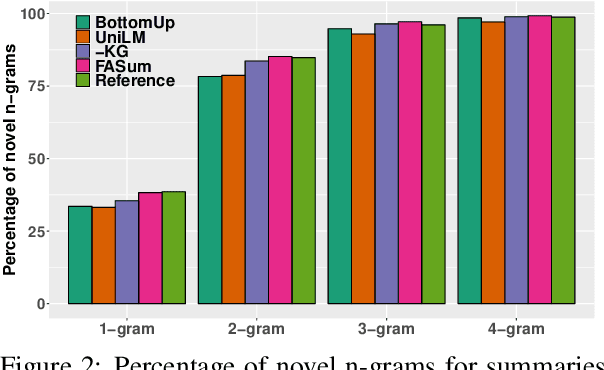
A commonly observed problem with abstractive summarization is the distortion or fabrication of factual information in the article. This inconsistency between summary and original text has led to various concerns over its applicability. In this paper, we firstly propose a Fact-Aware Summarization model, FASum, which extracts factual relations from the article and integrates this knowledge into the decoding process via neural graph computation. Then, we propose a Factual Corrector model, FC, that can modify abstractive summaries generated by any model to improve factual correctness. Empirical results show that FASum generates summaries with significantly higher factual correctness compared with state-of-the-art abstractive summarization systems, both under an independently trained factual correctness evaluator and human evaluation. And FC improves the factual correctness of summaries generated by various models via only modifying several entity tokens.
Make Lead Bias in Your Favor: A Simple and Effective Method for News Summarization
Jan 07, 2020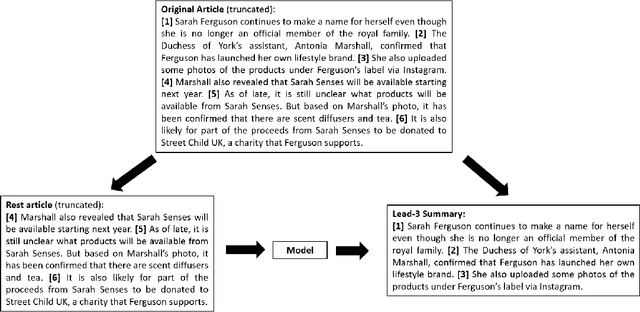
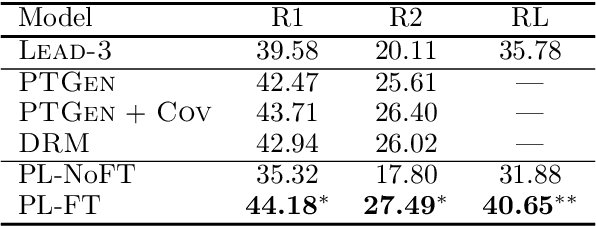
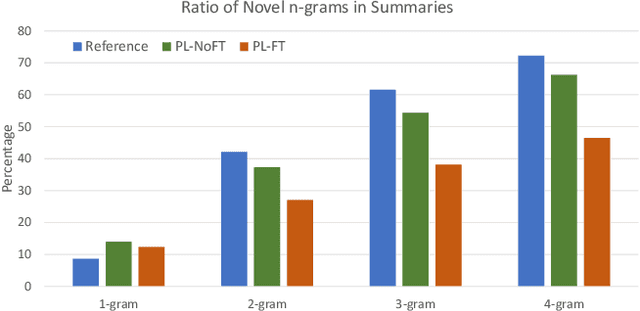
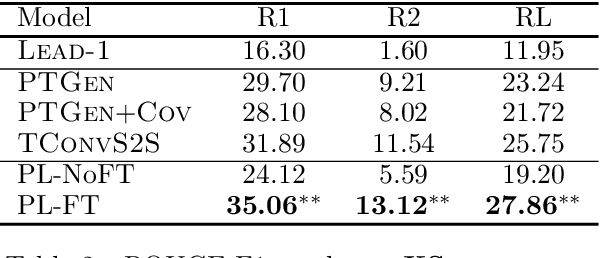
Lead bias is a common phenomenon in news summarization, where early parts of an article often contain the most salient information. While many algorithms exploit this fact in summary generation, it has a detrimental effect on teaching the model to discriminate and extract important information. We propose that the lead bias can be leveraged in a simple and effective way in our favor to pretrain abstractive news summarization models on large-scale unlabeled corpus: predicting the leading sentences using the rest of an article. Via careful data cleaning and filtering, our transformer-based pretrained model without any finetuning achieves remarkable results over various news summarization tasks. With further finetuning, our model outperforms many competitive baseline models. Human evaluations further show the effectiveness of our method.
TED: A Pretrained Unsupervised Summarization Model with Theme Modeling and Denoising
Jan 06, 2020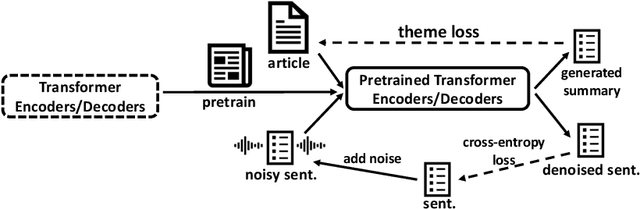
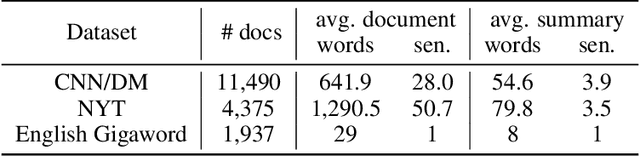
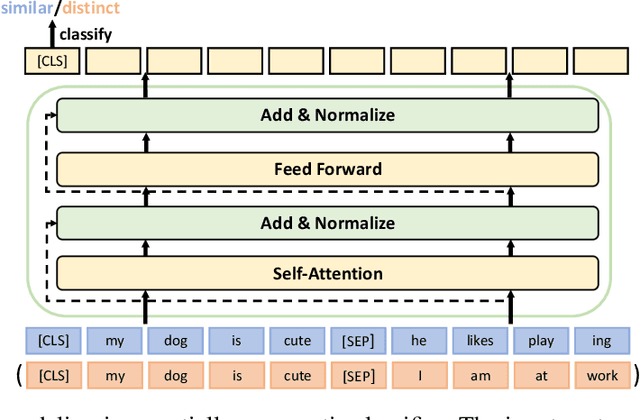
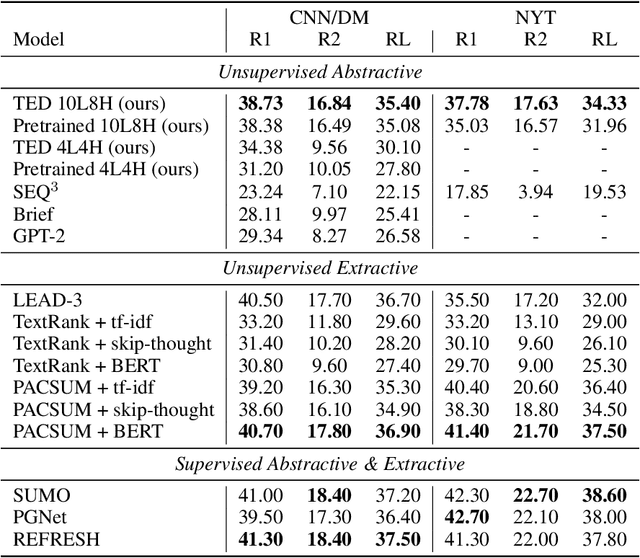
Text summarization aims to extract essential information from a piece of text and transform it into a concise version. Existing unsupervised abstractive summarization models use recurrent neural networks framework and ignore abundant unlabeled corpora resources. In order to address these issues, we propose TED, a transformer-based unsupervised summarization system with pretraining on large-scale data. We first leverage the lead bias in news articles to pretrain the model on large-scale corpora. Then, we finetune TED on target domains through theme modeling and a denoising autoencoder to enhance the quality of summaries. Notably, TED outperforms all unsupervised abstractive baselines on NYT, CNN/DM and English Gigaword datasets with various document styles. Further analysis shows that the summaries generated by TED are abstractive and containing even higher proportions of novel tokens than those from supervised models.
Advances in Online Audio-Visual Meeting Transcription
Dec 10, 2019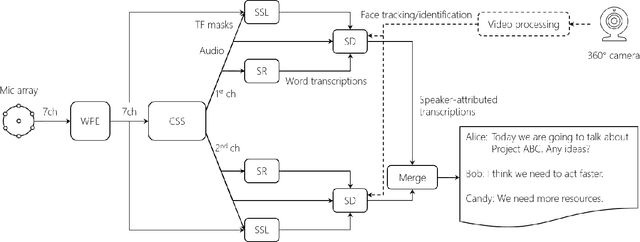

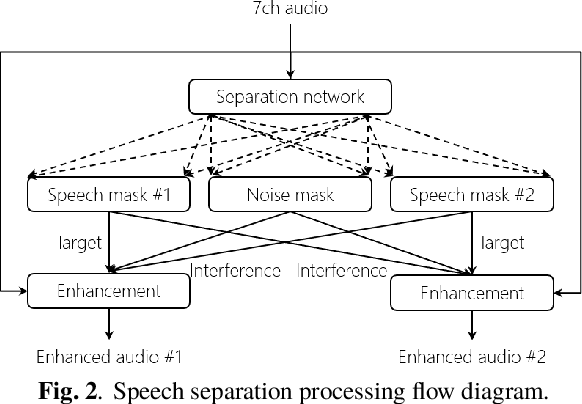
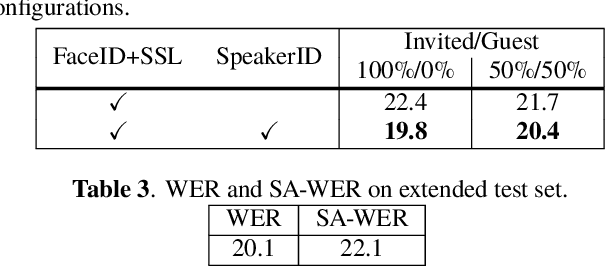
This paper describes a system that generates speaker-annotated transcripts of meetings by using a microphone array and a 360-degree camera. The hallmark of the system is its ability to handle overlapped speech, which has been an unsolved problem in realistic settings for over a decade. We show that this problem can be addressed by using a continuous speech separation approach. In addition, we describe an online audio-visual speaker diarization method that leverages face tracking and identification, sound source localization, speaker identification, and, if available, prior speaker information for robustness to various real world challenges. All components are integrated in a meeting transcription framework called SRD, which stands for "separate, recognize, and diarize". Experimental results using recordings of natural meetings involving up to 11 attendees are reported. The continuous speech separation improves a word error rate (WER) by 16.1% compared with a highly tuned beamformer. When a complete list of meeting attendees is available, the discrepancy between WER and speaker-attributed WER is only 1.0%, indicating accurate word-to-speaker association. This increases marginally to 1.6% when 50% of the attendees are unknown to the system.
SIM: A Slot-Independent Neural Model for Dialogue State Tracking
Sep 26, 2019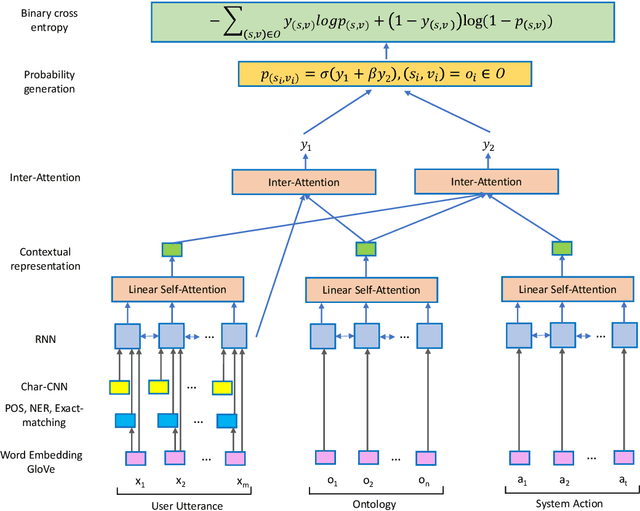
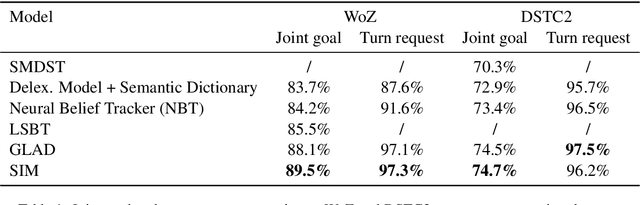
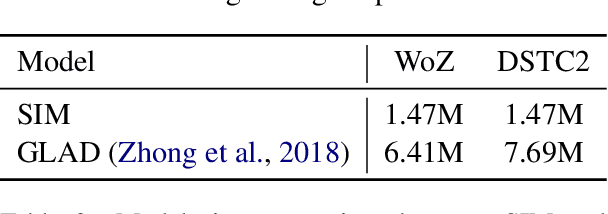
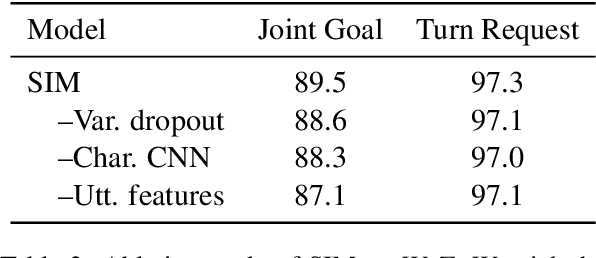
Dialogue state tracking is an important component in task-oriented dialogue systems to identify users' goals and requests as a dialogue proceeds. However, as most previous models are dependent on dialogue slots, the model complexity soars when the number of slots increases. In this paper, we put forward a slot-independent neural model (SIM) to track dialogue states while keeping the model complexity invariant to the number of dialogue slots. The model utilizes attention mechanisms between user utterance and system actions. SIM achieves state-of-the-art results on WoZ and DSTC2 tasks, with only 20% of the model size of previous models.
* 6 pages, 1 figure
Meeting Transcription Using Virtual Microphone Arrays
May 03, 2019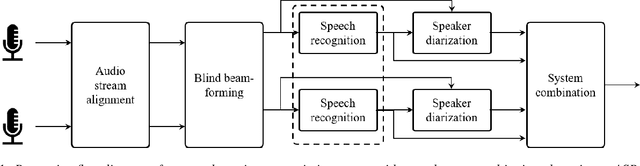
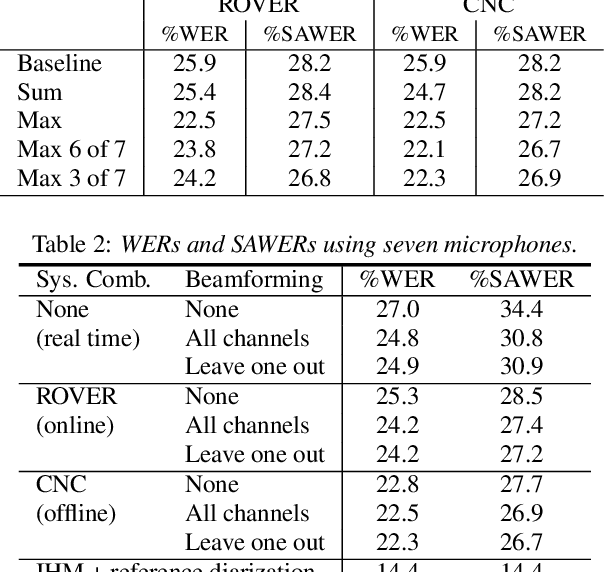
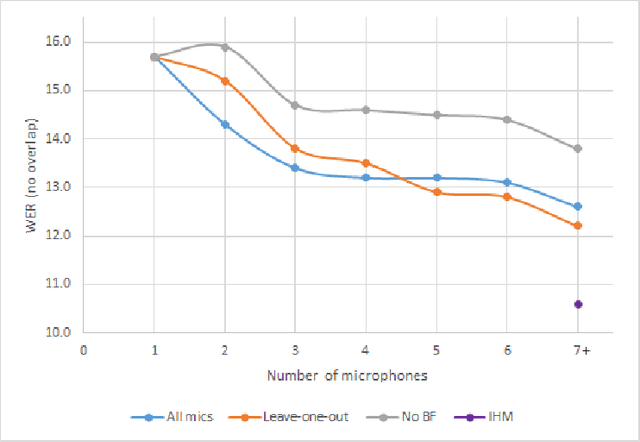

We describe a system that generates speaker-annotated transcripts of meetings by using a virtual microphone array, a set of spatially distributed asynchronous recording devices such as laptops and mobile phones. The system is composed of continuous audio stream alignment, blind beamforming, speech recognition, speaker diarization using prior speaker information, and system combination. With seven input audio streams, our system achieves a word error rate (WER) of 22.3% and comes within 3% of the close-talking microphone WER on the non-overlapping speech segments. The speaker-attributed WER (SAWER) is 26.7%. The relative gains in SAWER over a single-device system are 14.8%, 20.3%, and 22.4% for three, five, and seven microphones, respectively. The presented system achieves a 13.6% diarization error rate when 10% of the speech duration contains more than one speaker. The contribution of each component to the overall performance is also investigated.